nn.CrossEntropyLoss()函数是PyTorch中用于计算交叉熵损失的函数。其中reduction参数用于控制输出损失的形式。当reduction='none'时,函数会输出一个形状为(batch_size,num_classes)的矩阵,表示每个样本的每个类别的损失。当reduction='sum'时,函数会对矩阵求和,输出一个标量,表示所有样本的损失之和。当reduction='elementwise_mean'时,函数会对矩阵求平均,输出一个标量,表示所有样本的平均损失。在您的例子中,在使用reduction='none'时无法训练,是因为需要一个标量来表示整个训练集的损失
文章目录前言解决方案前言最近在学习elasticsearch时在购买的阿里云linux服务器进行docker安装运行时报错解决方案我这里是把dockerrun--nameelasticsearch-p9200:9200-p9300:9300\-e"discovery.type=single-node"\-eES_JAVA_OPTS="-Xms64m-Xmx512m"\-v/mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml\-v/mydata/elasti
51单片机的运行内存分前128字节和后128字节。前面128个字节好像cpu里的寄存器,读写非常快。后面的128字节只能用指针访问。单片机可以外扩运行内存条,外扩的这部分内存叫xdata。我对单片机运行机制的理解就像搭建积木。以乐高积木举例:单片机是玩家,code区是说明书,data是积木块,单片机看着说明书把积木块拼装成汽车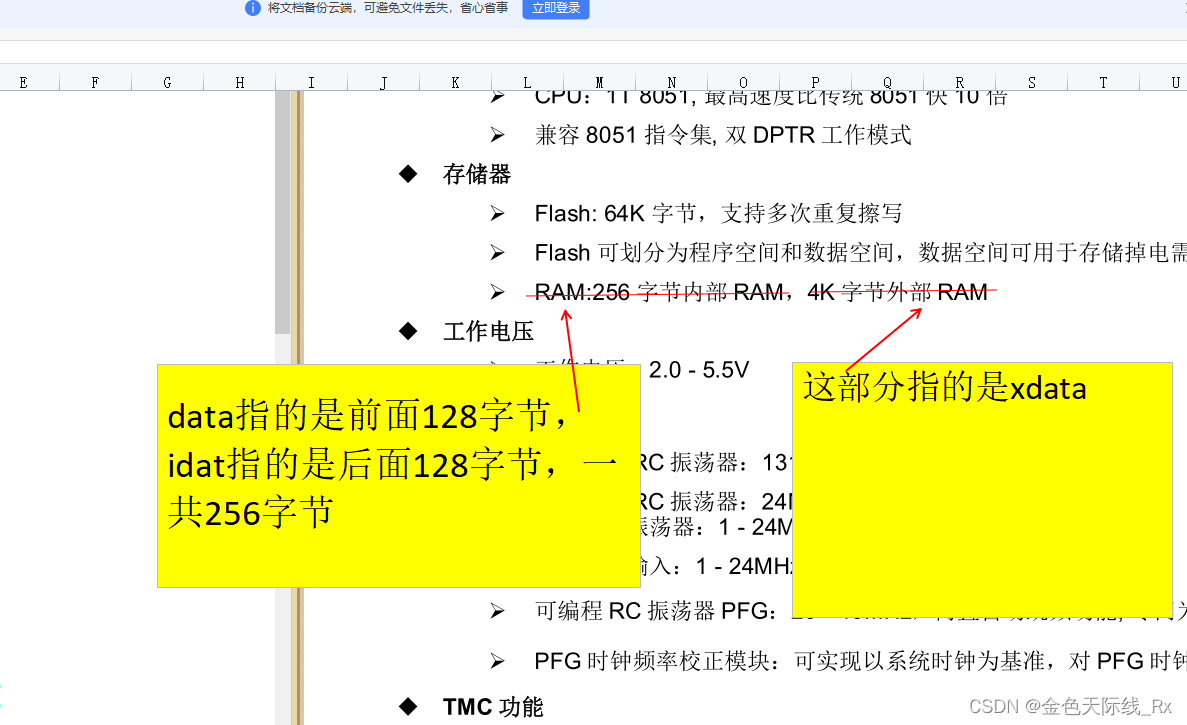区,和data(数据)区,code区在运行的时
2023年11月6日,周一下午目录POD类型的定义标量类型POD类型的特点POD类型的例子整数类型:C风格的结构体:数组:C风格的字符串:std::array:使用memcpy对POD类型进行复制把POD类型存储到文件中,并从文件中再次读取POD类型的定义只包含标量类型(如整数、浮点数、指针等)或者其他POD类型的成员。没有用户自定义的构造函数、析构函数或拷贝控制成员没有虚函数或虚继承可以通过 memset 和 memcpy 进行内存的简单复制和初始化。这些标准在C++03标准中被定义。根据这个定义,POD类型可以被视为简单的、平凡的数据类型,可以进行一些底层的操作,如内存复制、比较和序列化等
我无法安装compass。我想在我的项目上安装compass,所以当我尝试更新时,我得到了这个:c:\wamp\www\danjasnowski.com>geminstallcompassERROR:Couldnotfindavalidgem'compass'(>=0),hereiswhy:Unabletodownloaddatafromhttps://rubygems.org/-SSL_connectreturned=1errno=0state=SSLv3readservercertificateB:certificateverifyfailed(https://api.rubyge
自定义loss函数和微分运算过程的神经网络,训练时loss先缓缓下降,后又上升,摇摆不定,可能的原因有哪些?此处尽可能多的列出可能的原因。注意:计算图首先要是通的,可以BP1、梯度消失或爆炸:神经网络层数较深,可能出现梯度消失或爆炸的情况,导致无法正确更新网络参数,从而导致loss函数的摆动。2、学习率过大或过小:学习率过大会导致训练过程中震荡,而学习率过小会导致训练速度过慢,可能需要通过调整学习率来解决这个问题。3、过拟合或欠拟合:过拟合或欠拟合都可能导致训练后期的loss值波动较大。过拟合指模型在训练集上表现良好但在测试集上表现不佳,可能需要增加正则化项或减小模型复杂度;欠拟合指模型在训练
刚开始接触spring和springboot,现在正在使用springdataredis。我有这样一个模型@Entity@Table(name="users")publicclassUser{privateLongid;@Id@javax.persistence.Column(name="id",nullable=false,insertable=true,updatable=true)privateStringemail;@Basic@javax.persistence.Column(name="email",nullable=false,insertable=true,updata
我已经在单个REDIS实例中成功地使用multi和exec功能在Redis中实现(并测试)了事务操作。但是,在集群设置中运行的相同代码会出错并显示以下异常消息。我正在使用spring-data-redis-1.8.1.RELEASE和jedis-2.9.0。Exceptioninthread"main"org.springframework.dao.InvalidDataAccessApiUsageException:MUTLIiscurrentlynotsupportedinclustermode.atorg.springframework.data.redis.connection
框架代码中出现这个空指针的原因是什么?我最近开始将我们的一些应用程序堆栈从带有JGroups的ehcache迁移到Redis。作为其中的一部分,我们将继续使用ehcache作为某些功能的二级缓存。在一些集成测试(约900个)期间,我在客户端库(Jedis或Lettuce)的连接代码中得到了一致的NullPointerExceptions。但是,缓存机制在正常应用程序运行期间确实起作用,并且缓存在某些集成测试期间正常工作。现有的应用程序代码使用了@Cacheable,这对我来说效果很好。我使用以下gradle依赖项和缓存配置进行了集成:compile'org.springframewor
我正在尝试查找有关使用SpringData在Redis上创建和搜索文本索引的文档。我看到@Indexed但没有找到@TextIndexed,就像Spring数据MongoDB一样。https://github.com/RedisLabs/JRediSearch 最佳答案 SpringDataRedis中不支持Redis模块,我们也不打算添加对Redis模块的支持。 关于spring-使用SpringDataRedis进行文本搜索,我们在StackOverflow上找到一个类似的问题: