目录分类模型的评估模型优化与选择1.交叉验证2.网格搜索【分类】K近邻算法【分类】朴素贝叶斯——文本分类实例:新闻数据分类【分类】决策树和随机森林1.决策树2.决策树的算法3.代码实现实例:泰坦尼克号预测生死【集成学习】随机森林1.集成学习2.随机森林3.学习算法4.代码实现5.优点【分类】逻辑回归——二分类实例:良/恶性乳腺癌肿数据【分类】SVM模型分类模型的评估模型优化与选择1.交叉验证交叉验证:为了让被评估的模型更加准确可信交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平
1KNN算法介绍KNN算法又叫做K近邻算法,是众多机器学习算法里面最基础入门的算法。KNN算法是最简单的分类算法之一,同时,它也是最常用的分类算法之一。KNN算法是有监督学习中的分类算法,它看起来和Kmeans相似(Kmeans是无监督学习算法),但却是有本质区别的。KNN算法基于实例之间的相似性进行分类或回归预测。在KNN算法中,要解决的问题是将新的数据点分配给已知类别中的某一类。该算法的核心思想是通过比较距离来确定最近邻的数据点,然后利用这些邻居的类别信息来决定待分类数据点的类别。其核心思想为:“近朱者赤近墨者黑”1.1KNN算法三要素距离度量算法:一般使用的是欧氏距离。也可以使用其他距离
目录1.基本定义2.算法原理2.1算法优缺点2.2算法参数2.3变种3.算法中的距离公式4.案例实现4.1导入相关库4.2读取数据4.3读取变量名4.4定义X,Y数据 4.5分离训练集和测试集4.6计算欧式距离4.7 可视化距离矩阵4.8预测样本4.9查看正确率4.10交叉验证5. scikit-learn的算法实现5.1对上述的再次实现:5.2另一种实现方式1.基本定义 k最近邻(k-NearestNeighbor)算法是比较简单的机器学习算法。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的多个最近邻(最相似〉的样本中的大多数都属于某一个
目录一.K-近邻算法(KNN)概述 二、KNN算法实现三、MATLAB实现四、实战一.K-近邻算法(KNN)概述 K-近邻算法(KNN)是一种基本的分类算法,它通过计算数据点之间的距离来进行分类。在KNN算法中,当我们需要对一个未知数据点进行分类时,它会与训练集中的各个数据点进行特征比较,并找到与之最相似的前K个数据点。然后根据这K个数据点的类别来确定未知数据点所属的类别。 KNN算法的步骤非常简单:1)计算未知数据点与训练集中各个数据点之间的距离。常用的距离度量包括欧氏距离和曼哈顿距离。2)按照距离递增的顺序对数据点进行排序。3)选择距离最小的K
机器学习是人工智能(ArtificialIntelligence,简称AI)的一个重要组成部分。它是一种通过数据和模型自动化推理、预测和决策的技术。在机器学习中,算法是核心。算法是计算机根据数据和任务要求自动推断出来的规则和方法。本文将详细介绍AI人工智能最常见的机器学习算法。线性回归线性回归是最简单的机器学习算法之一。它用于预测一个连续的输出值。它的主要思想是根据输入变量(或称为特征)和已知输出值之间的关系来预测未知的输出值。线性回归假设输入和输出之间存在线性关系。因此,它可以用一个线性方程来表示。线性回归的应用场景包括房价预测、销售预测等。逻辑回归逻辑回归是一种用于分类问题的机器学习算法。
k-近邻涉及到的参数不多,也容易玩,因此我们来看下最为关键的参数k,对结果的影响。之前我们都是把结果设置成了3,如数字识别,3的结果是1.06%的错误率。我们来看看其他的:1:最靠近哪个就是哪个,1.37%的错误率,也很不错嘛!看来你和闺蜜/兄弟的性格很接近啊。2:1.37%,也挺好;5:1.79%,开始下滑了;10:2% 20:2.75% 50:5.18% 100:7.18%至此可以看出,k大到一定程度(在这个数据集里,5就开始有点下滑了),结果就会变差。所以,k并非是越大越好。你可能要多次跑数据后,才能找到最合适的值。像这个数据集里,3这样小的数字
「作者主页」:士别三日wyx「作者简介」:CSDNtop100、阿里云博客专家、华为云享专家、网络安全领域优质创作者「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》K-近邻算法1、什么是K-近邻算法?2、K-近邻算法API3、K-近邻算法实际应用3.1、获取数据集3.2、划分数据集3.3、特征标准化3.4、KNN处理并评估1、什么是K-近邻算法?K-近邻算法的核心思想是根据「邻居」来「推断」你的类别。K-近邻算法的思路其实很简单,比如我在北京市,想知道自己在北京的哪个区。K-近邻算法就会找到和我距离最近的‘邻居’,邻居在朝阳区,就认为我大概率也在朝阳区。其中K是邻居个数的意思邻居个数
一、K-近邻算法1.介绍K-近邻算法(KNearestNeighbor)又叫KNN算法,指如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。也就是对于新输入的实例,从数据集中找到于该实例最邻近的k个实例,那么这k个实例大多数属于某一个类,那么就把该实例放到该类中。KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。举个栗子:若已经对一部分人标明皮肤白还是黑,当新加入一个人时,若要对其判定皮肤是黑还是白,那么就可以看其皮肤颜色与已判定黑或者白的人群皮肤颜色进行对比,与哪方
K平均算法的介绍k平均聚类发明于1956年,是一个聚类算法,把n的对象根据他们的属性分为k个分割,kk近邻算法的案例介绍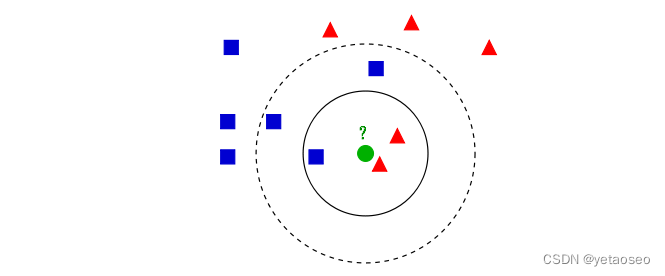如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。我们常说,物以类聚,人以群分,判别
「作者主页」:士别三日wyx「作者简介」:CSDNtop100、阿里云博客专家、华为云享专家、网络安全领域优质创作者「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》K-近邻算法1、什么是K-近邻算法?2、K-近邻算法API3、K-近邻算法实际应用3.1、获取数据集3.2、划分数据集3.3、特征标准化3.4、KNN处理并评估1、什么是K-近邻算法?K-近邻算法的核心思想是根据「邻居」来「推断」你的类别。K-近邻算法的思路其实很简单,比如我在北京市,想知道自己在北京的哪个区。K-近邻算法就会找到和我距离最近的‘邻居’,邻居在朝阳区,就认为我大概率也在朝阳区。其中K是邻居个数的意思邻居个数