摘要:本文重点介绍单个SQL语句持续执行慢的场景。
本文分享自华为云社区《GaussDB(DWS) SQL性能问题案例集》,作者:黎明的风。
本文重点介绍单个SQL语句持续执行慢的场景。我们可以对执行慢的SQL进行单独分析,SELECT、INSERT、UPDATE等语句都可以使用explain verbose + SQL语句输出查询计划来进行分析,这样只输出查询计划,语句不会被实际的执行。
如果查询计划只出现__REMOTE_FQS_QUERY__或__REMOTE_LIGHT_QUERY__,看不到具体的计划,可以先执行set enable_fast_query_shipping to off; 然后再重新打印执行计划。
经常遇到的问题有以下几个:
检查查询计划中是否包含_REMOTE_TABLE_QUERY_关键字, 如果有则表示语句没有下推,数据需要从DN上收取到CN上,然后语句在CN上执行。语句不下推原因,要从CN的日志中查找,搜索的关键字为:SQL can’t be shipped,以下为函数造成的不下推例子:
LOG: SQL can't be shipped, reason: Function Fun1() can not be shipped
此外如果出现以下几种不下推的关键字:__REMOTE_GROUP_QUERY__、__REMOTE_LIMIT_QUERY__、
__REMOTE_SORT_QUERY__。这种需要检查enable_stream_operator参数是否处于关闭状态,一般来说打开STREAM开关后,语句就可以下推执行了。
如果出现以下两种关键字,表示语句可以下推执行:
__REMOTE_FQS_QUERY__:表明语句走了Fast Query Shipping(FQS),SQL语句会下发到DN上执行,并且各DN之间没有数据交互,常见的场景有过滤条件为等值查询(where id = 1),或者关联的列是表的分布列的查询(where t1.id = t2.id)。
__REMOTE_LIGHT_QUERY__:表明语句走了Light Proxy(CN轻量化),将语句下发给了单个DN去处理,常见的场景过滤条件是分布列的等值查询(where id = 1),或者向一个DN插入数据的INSERT语句。
从查询计划中可以看到Seq Scan或CStore Scan这样的关键字,如下所示:
对于行存表:-> Seq Scan on t1
对于列存表:-> CStore Scan on col_t1
出现这种问题通常有以下几种情况:
没有对所查询的表收集统计信息
如果表的实际行数很大,而估算行数很小,查询时可能会走全表顺序扫描,造成执行速度慢。此时通过analyze表更新统计信息,让优化器选择最佳的查询计划,一般就可以解决执行慢的问题。
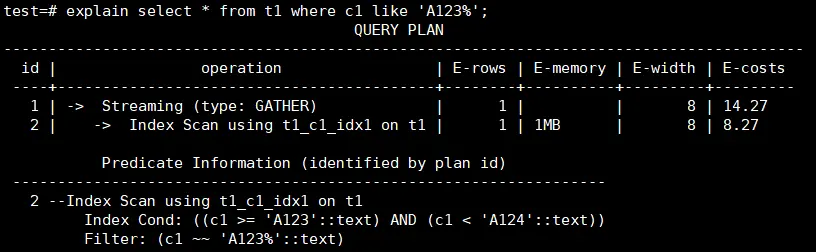
后模糊匹配查询可以通过建立一个BTREE索引来实现,需要根据数据类型设置索引的operator,对于text,varchar和char分别设置和text_pattern_ops,varchar_pattern_ops和bpchar_pattern_ops。
例如c1列的类型为text,创建索引时增加text_pattern_ops。
CREATE INDEX ON t1 (c1 text_pattern_ops);
创建索引后,可以看到语句执行时会使用到前面创建的索引,执行速度会变快。
多列复合索引的组织结构与单列字段索引结构类似,按索引内表达式指定的顺序编排。当创建多列复合索引时,选择什么样的列的顺序,对查询性能会带来一定的影响。
例如按照c_date,c1和c2列的顺序建立检索,如果符合c_date条件的数据很多,通过这个索引扫描的数据就很会很多,造成执行时间长。

新建多列复合索引,将查询条件里的等值条件的列放到索引列的前面,先使用等值进行过滤,需要扫描的数据变少,查询变快。

问题背景:XSYX局点使用MERGE INTO语句将每天的数据入库到表里,目标表为分区表,业务上线运行一段时间后发现MERGE INTO速度逐渐变慢。
原因分析:MERGE INTO语句的源表和目标表都是分区表,当前仅对源表增加了时间的过滤条件,可以进行分区剪枝。目标表由于没有指定时间过滤条件,进行的是全表扫描,随着每日的入库业务运行,目标表的数据量越来越大,造成执行速度越来越慢。
解决方案:由于源表的数据在MERGE INTO时会导入到目标表的对应分区里,可以对目标表增加时间的过滤条件进行分区剪枝。
业务修改前的查询计划:
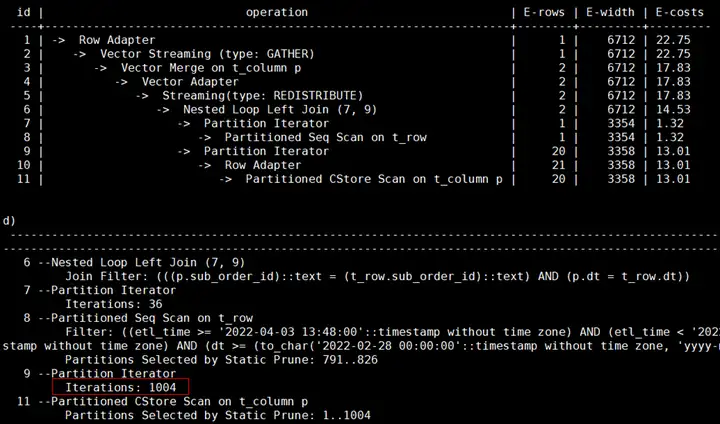
对目标表增加了时间过滤条件后的计划显示可以走分区剪枝:

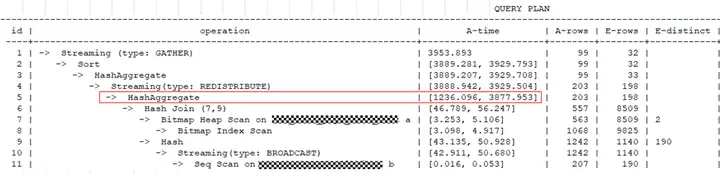
从查询计划中的A-time可以看到最长和最短的执行时间相差很大,说明在不同DN上扫描数据的时间不同。

在查询计划的DN信息中,通过rows可以看出在datanode1上扫描的数据量明显多于datanode2,说明有存储倾斜,这种情况建议对表进行合理的设计,选择合适的分布列,将数据均匀分布到所有的DN上。

问题现象:查询语句比较简单,两个表做关联后输出了其中一列的值,在输出前增加了一个自定义函数对数据进行了处理。
原因分析:自定义函数里逻辑相对复杂,包含了对表的查询及数据计算逻辑,造成执行变慢。
解决方案;业务上对自定义函数进行性能优化。
问题现象:某YD局点从C80版本迁移数据到8.1.1版本后,查询PG_STAT_USER_TABLES视图的时间由几分钟变成半个小时都不出结果。
原因分析:8.1.1版本中的PG_STAT_USER_TABLES视图在获取插入、更新、删除的行数的字段数值时,每一条记录都涉及到CN和DN的交互,在数据量和集群规模大的情况下耗时较多。
解决方案:建议根据应用的实际需要,将视图定义中不需要的函数注释掉以提升查询效率。
问题现象: 查询计划中显示走了Index Scan,通过索引查询出的数据量比较大,速度慢。
原因分析:由于使用索引扫描时无法使用并行查询,当索引访问的数据量大时执行速度较慢。
解决方案:将enable_indexscan和enable_bitmapscan参数关闭,设置query_dop后走并行查询。
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g