UPerNet:《Unified Perceptual Parsing for Scene Understanding》
发布于2018ECCV。
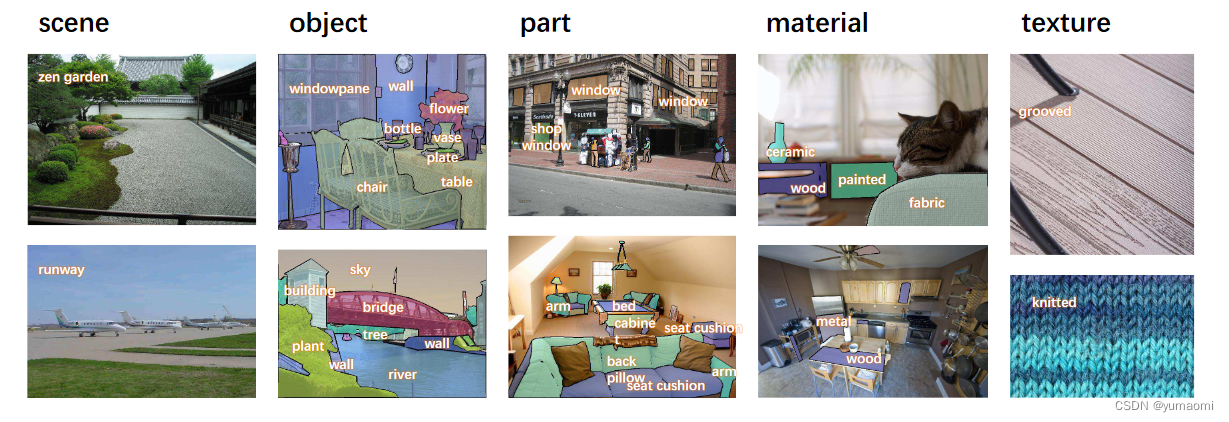
人类在识别物体上往往是通过多角度多层次的观察来得出物体类别的,包括物体的形状、纹理、位于什么环境背景中、其中包含了什么等等。比如,一扇窗,材质是玻璃,位于墙上,形状为矩形,综合这一堆结论,我们得出:哦!这是一扇窗。
在CV界,有做场景分析的、做材质识别的、做目标检测的、做语义分割的等等,但是很少有将这些任务集成在一个model上的研究,也就是Multi-task任务。
而Multi-task learning的数据集较少,同时制作也较为困难,因为对于不同任务的数据标签是异质的。比如,对于场景分析的ADE20K数据集来说,所有注释都是像素级别的对象,而对于描述纹理信息的数据集DTD(Describe Texture Dataset),标注都是图像级别的。这成为了数据集建立的瓶颈所在。
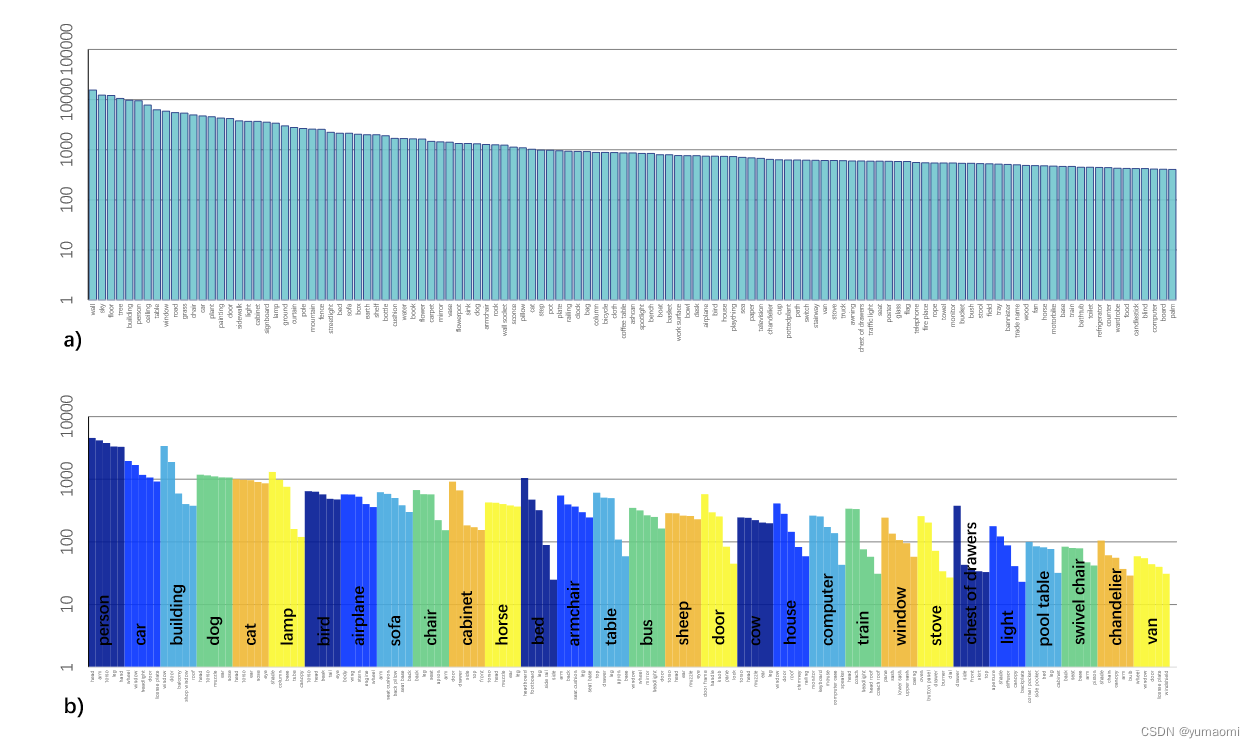
为了解决缺乏Multi-task 数据集的问题,作者使用Broadly and Densely Labeled Dataset (Broden)来统一了ADE20K、Pascal-Context、Pascal-Part、OpenSurfaces、和Describable Textures Dataset (DTD)这几个数据集。这些数据集中包含了各种场景、对象、对象的部分组成件和材料。接着,作者对类别不均衡问题做了进一步处理,包括删除出现次数少于50张图像的类别、删除像素数少于50000的类别。总之,作者构建了一个十分宏大的Multi-task数据集,总共62,262张图像。
UPerNet的模型设计总体基于FPN(Feature Pyramid Network)和PPM(Pyramid Pooling Module),如下图。
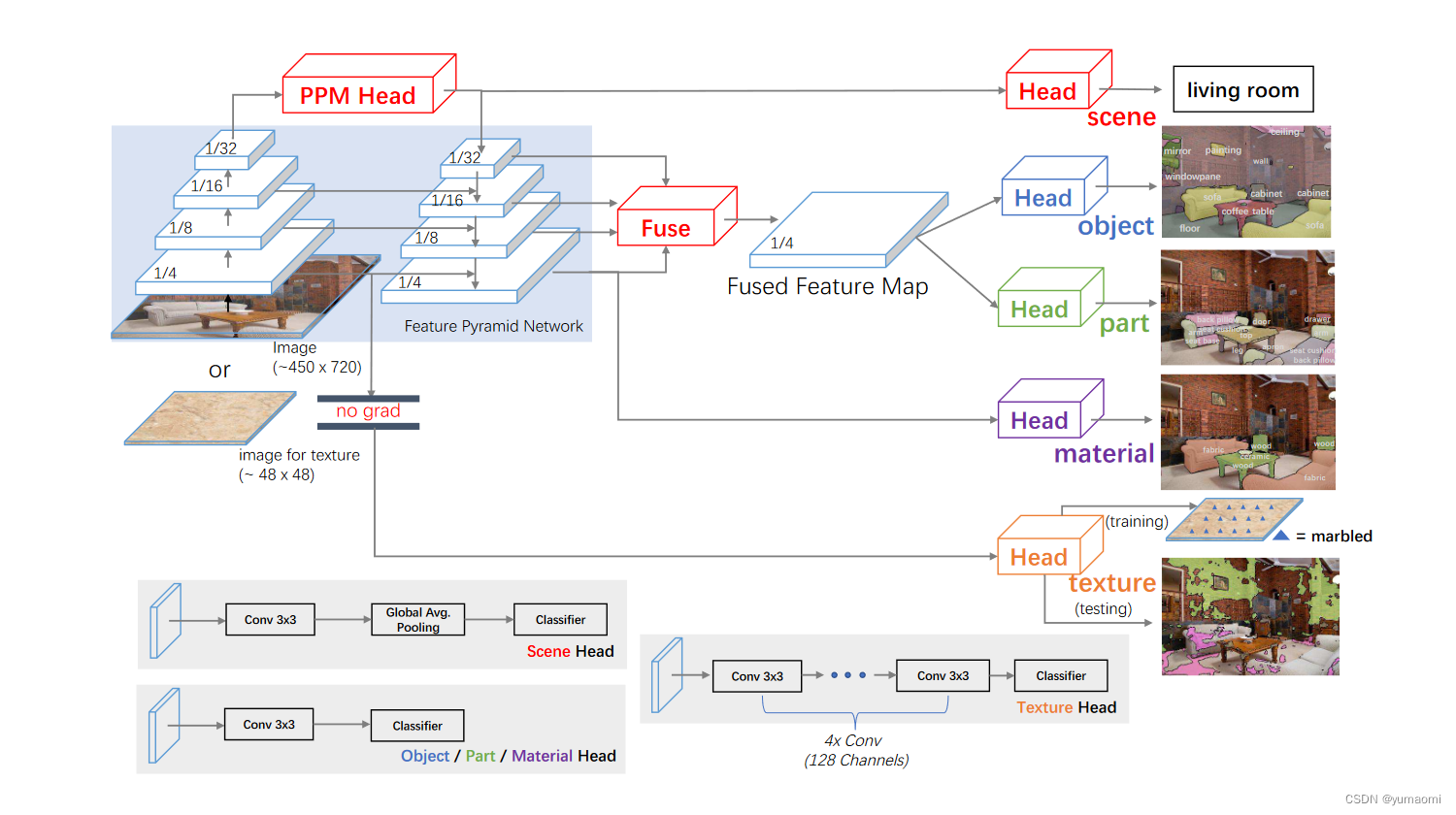
作者为每一个task设计了不同的检测头。
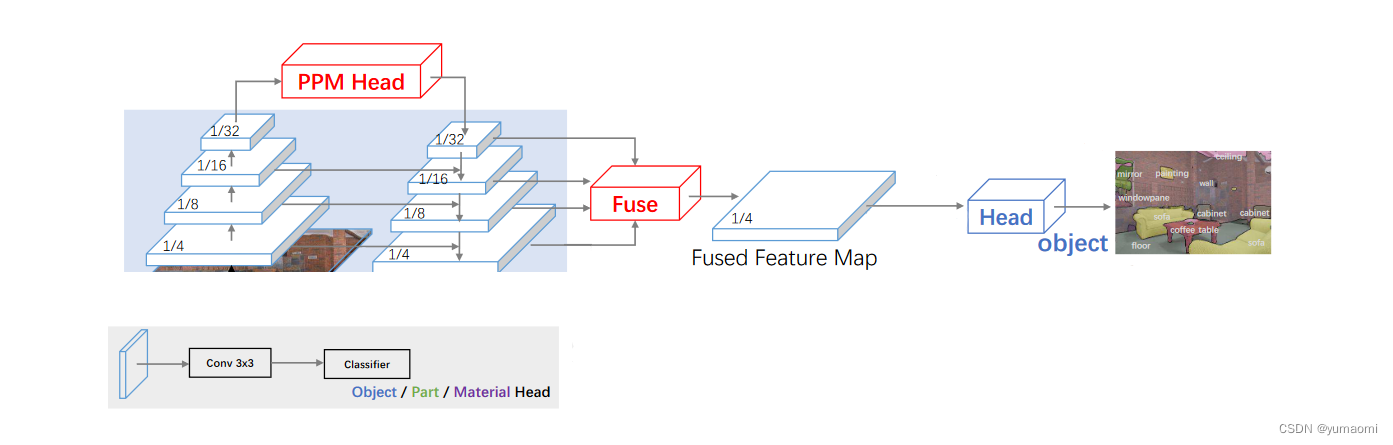
当然,本文题名为语义分割系列,作者对于UPerNet的使用也主要局限在语义分割部分,因此,可以对UPerNet的其他分支进行剪枝,删去其他分支的检测头,只保留语义分割部分的检测头即可。也就是下图这样:
Multi-task Learning的分割、分类结果:

场景中内容物的关系可视化结果:
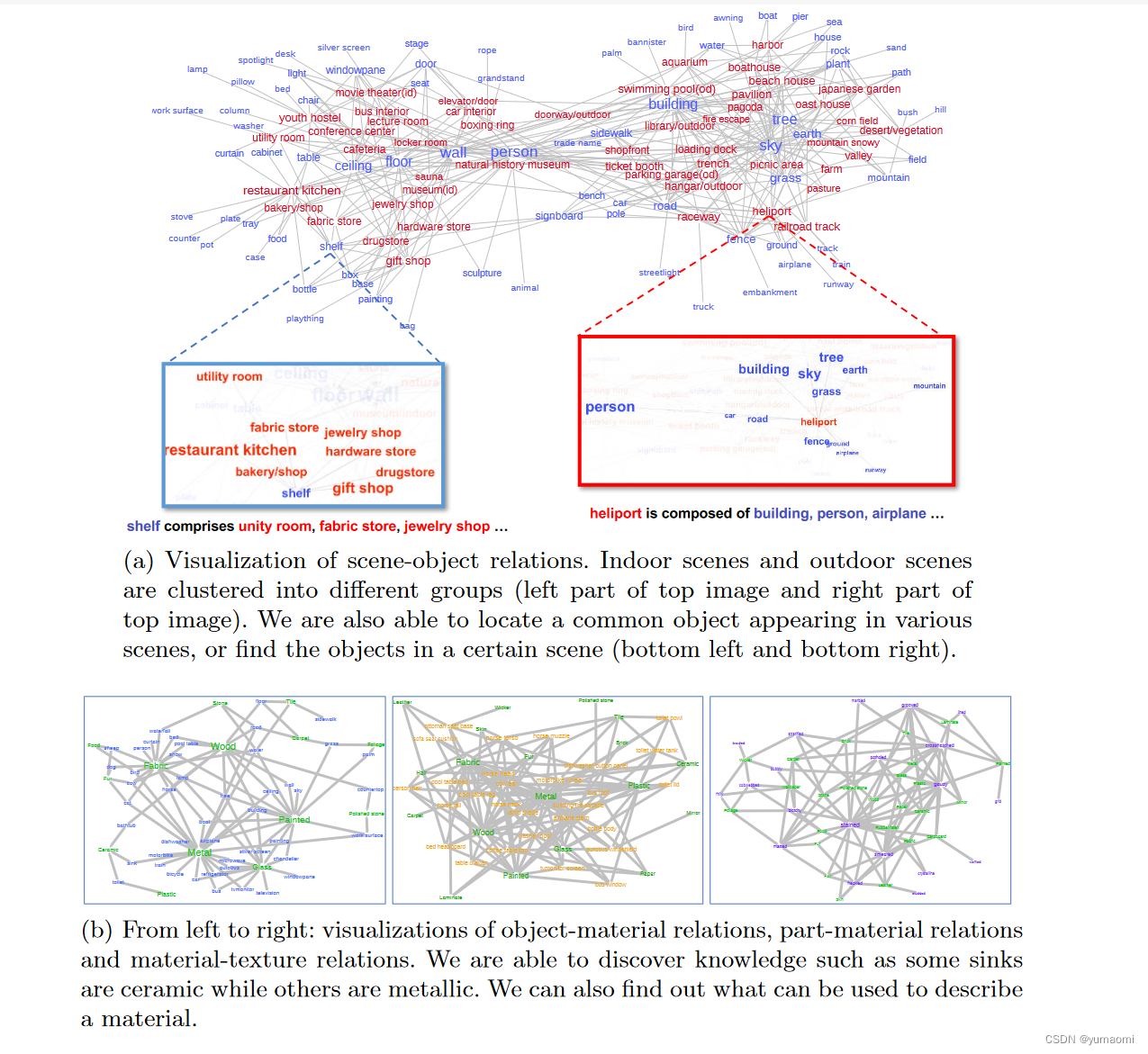
UPerNet做了一个Multi-task learning的任务示范,创建了一个多任务的数据集。合理设计了UPerNet的主干部分和检测头部分用于不同任务的分类。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion: int = 4
def __init__(self, inplanes, planes, stride = 1, downsample = None, groups = 1,
base_width = 64, dilation = 1, norm_layer = None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = nn.Conv2d(inplanes, planes ,kernel_size=3, stride=stride,
padding=dilation,groups=groups, bias=False,dilation=dilation)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes ,kernel_size=3, stride=stride,
padding=dilation,groups=groups, bias=False,dilation=dilation)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample= None,
groups = 1, base_width = 64, dilation = 1, norm_layer = None,):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, stride=1, bias=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, bias=False, padding=dilation, dilation=dilation)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2d(width, planes * self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(
self,block, layers,num_classes = 1000, zero_init_residual = False, groups = 1,
width_per_group = 64, replace_stride_with_dilation = None, norm_layer = None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block,
planes,
blocks,
stride = 1,
dilate = False,
):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = stride
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
norm_layer(planes * block.expansion))
layers = []
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
return nn.Sequential(*layers)
def _forward_impl(self, x):
out = []
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
out.append(x)
x = self.layer2(x)
out.append(x)
x = self.layer3(x)
out.append(x)
x = self.layer4(x)
out.append(x)
return out
def forward(self, x) :
return self._forward_impl(x)
def _resnet(block, layers, pretrained_path = None, **kwargs,):
model = ResNet(block, layers, **kwargs)
if pretrained_path is not None:
model.load_state_dict(torch.load(pretrained_path), strict=False)
return model
def resnet50(pretrained_path=None, **kwargs):
return ResNet._resnet(Bottleneck, [3, 4, 6, 3],pretrained_path,**kwargs)
def resnet101(pretrained_path=None, **kwargs):
return ResNet._resnet(Bottleneck, [3, 4, 23, 3],pretrained_path,**kwargs)class PPM(nn.ModuleList):
def __init__(self, pool_sizes, in_channels, out_channels):
super(PPM, self).__init__()
self.pool_sizes = pool_sizes
self.in_channels = in_channels
self.out_channels = out_channels
for pool_size in pool_sizes:
self.append(
nn.Sequential(
nn.AdaptiveMaxPool2d(pool_size),
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1),
)
)
def forward(self, x):
out_puts = []
for ppm in self:
ppm_out = nn.functional.interpolate(ppm(x), size=(x.size(2), x.size(3)), mode='bilinear', align_corners=True)
out_puts.append(ppm_out)
return out_puts
class PPMHEAD(nn.Module):
def __init__(self, in_channels, out_channels, pool_sizes = [1, 2, 3, 6],num_classes=31):
super(PPMHEAD, self).__init__()
self.pool_sizes = pool_sizes
self.num_classes = num_classes
self.in_channels = in_channels
self.out_channels = out_channels
self.psp_modules = PPM(self.pool_sizes, self.in_channels, self.out_channels)
self.final = nn.Sequential(
nn.Conv2d(self.in_channels + len(self.pool_sizes)*self.out_channels, self.out_channels, kernel_size=1),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(),
)
def forward(self, x):
out = self.psp_modules(x)
out.append(x)
out = torch.cat(out, 1)
out = self.final(out)
return out
class FPNHEAD(nn.Module):
def __init__(self, channels=2048, out_channels=256):
super(FPNHEAD, self).__init__()
self.PPMHead = PPMHEAD(in_channels=channels, out_channels=out_channels)
self.Conv_fuse1 = nn.Sequential(
nn.Conv2d(channels//2, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.Conv_fuse1_ = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.Conv_fuse2 = nn.Sequential(
nn.Conv2d(channels//4, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.Conv_fuse2_ = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.Conv_fuse3 = nn.Sequential(
nn.Conv2d(channels//8, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.Conv_fuse3_ = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.fuse_all = nn.Sequential(
nn.Conv2d(out_channels*4, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.conv_x1 = nn.Conv2d(out_channels, out_channels, 1)
def forward(self, input_fpn):
# b, 512, 7, 7
x1 = self.PPMHead(input_fpn[-1])
x = nn.functional.interpolate(x1, size=(x1.size(2)*2, x1.size(3)*2),mode='bilinear', align_corners=True)
x = self.conv_x1(x) + self.Conv_fuse1(input_fpn[-2])
x2 = self.Conv_fuse1_(x)
x = nn.functional.interpolate(x2, size=(x2.size(2)*2, x2.size(3)*2),mode='bilinear', align_corners=True)
x = x + self.Conv_fuse2(input_fpn[-3])
x3 = self.Conv_fuse2_(x)
x = nn.functional.interpolate(x3, size=(x3.size(2)*2, x3.size(3)*2),mode='bilinear', align_corners=True)
x = x + self.Conv_fuse3(input_fpn[-4])
x4 = self.Conv_fuse3_(x)
x1 = F.interpolate(x1, x4.size()[-2:],mode='bilinear', align_corners=True)
x2 = F.interpolate(x2, x4.size()[-2:],mode='bilinear', align_corners=True)
x3 = F.interpolate(x3, x4.size()[-2:],mode='bilinear', align_corners=True)
x = self.fuse_all(torch.cat([x1, x2, x3, x4], 1))
return xclass UPerNet(nn.Module):
def __init__(self, num_classes):
super(UPerNet, self).__init__()
self.num_classes = num_classes
self.backbone = ResNet.resnet50(replace_stride_with_dilation=[1,2,4])
self.in_channels = 2048
self.channels = 256
self.decoder = FPNHEAD()
self.cls_seg = nn.Sequential(
nn.Conv2d(self.channels, self.num_classes, kernel_size=3, padding=1),
)
def forward(self, x):
x = self.backbone(x)
x = self.decoder(x)
x = nn.functional.interpolate(x, size=(x.size(2)*4, x.size(3)*4),mode='bilinear', align_corners=True)
x = self.cls_seg(x)
return x# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)
model = UPerNet(num_classes=33).cuda()
#model.load_state_dict(torch.load(r"checkpoints/resnet101-5d3b4d8f.pth"), strict=False)from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5, last_epoch=-1)
#训练50轮
epochs_num = 100
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/UPerNet_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/UPerNet_{epoch+1}.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)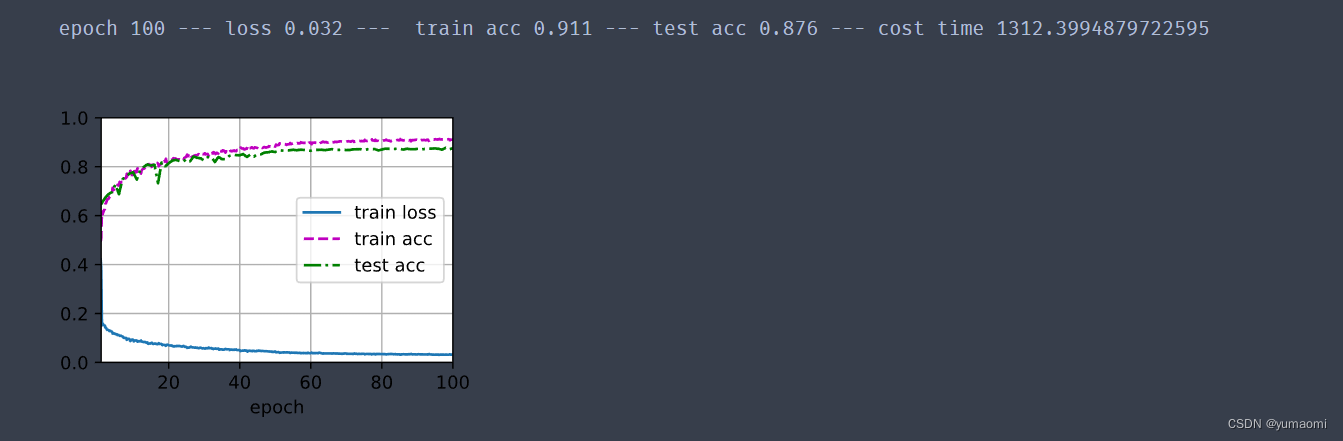
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复