hadoop中常问的就三块,第一:分布式存储(HDFS);第二:分布式计算框架(MapReduce);第三:资源调度框架(YARN)。
HDFS是hadoop的存储系统,包括客户端(client)、元数据节点(nameNode)、备份节点(secondary nameNode)和数据存储节点(dataNode)
并不是nameNode的热备,当nameNode挂掉后,不会立马替换nameNode并提供服务
注:Hadoop在设计时考虑到数据的安全与高效, 数据文件默认在HDFS上存放三份, 存储策略为本地一份,同机架内其它某一节点上一份, 不同机架的某一节点上一份。

(1)Read阶段:读取目标文件,从目标文件中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:数据被map处理完之后交给OutputCollect收集器,对其结果key进行分区(默认使用的hashPartitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝数据,如果数据大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:对所有数据进行一次归并排序即
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
所谓Shuffle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,Shuffle过程分为Map端的操作和Reduce端的操作。
Map的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件并清空缓存。当启动溢写操作时,首先需要把缓存中的数据进行分区,然后对每个分区的数据进行排序和合并,之后再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并成一个大的磁盘文件,然后通知相应的Reduce任务来领取属于自己处理的数据。
Reduce任务从Map端的不同Map机器领回属于自己处理的那部分数据,然后对数据进行归并后交给Reduce处理。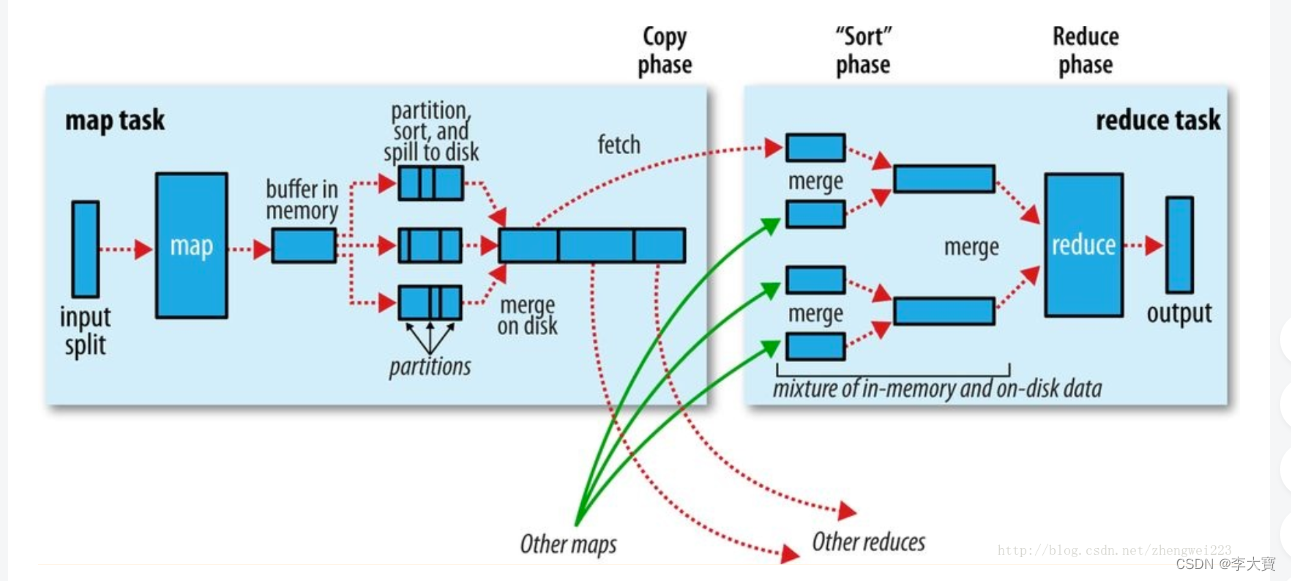
Hadoop上大量HDFS元数据信息存储在NameNode内存中,因此过多的小文件必定会压垮NameNode的内存。
针对HDFS而言,每一个小文件在namenode中都会占用150字节的内存空间,所以如果有1千万个小文件,每个文件占用一个block,则NameNode大约需要2G空间。如果存储1亿个文件,则NameNode需要20G空间。
针对MapReduce而言,每一个小文件都是一个Block,最终每一个小文件都会产生一个map任务,这样会导致同时启动太多的map任务,Map任务的启动是非常消耗性的,但是启动了以后执行了很短时间就停止了,因为小文件的数据量太小了,这样就会造成任务执行消耗的时间还没有启动任务消耗的时间多,这样也会影响MapReduce执行的效率。
HDFS提供了两种类型的容器,分别是SequenceFile 和 MapFile
sequence file由一系列的二进制key/value组成,key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
可以参考:Hadoop之小文件问题及解决方案_李大寶的博客-CSDN博客
提前在map进行combine,相当提前reduce,即把一个mapper中的相同的key进行聚合,减少shuffle过程中传输的数据量
局部聚合加全局聚合
第一次在map阶段对那些导致了数据倾斜的key 加上随机前缀,这样之前相同的key 也会被分到不同的reduce中,进行聚合,这样的话就那些倾斜的key进行局部聚合的数量就会大大降低。然后再进行第二次mapreduce这样的话去掉随机前缀,进行全局聚合。这样就可以有效地降低mapreduce了
NameNode数据存储在内存和本地磁盘,本地磁盘数据存储在fsimage镜像文件和edits编辑日志文件。
首次启动NameNode:
第二次启动NameNode:
客户端读取完DataNode上的块之后会进行checksum验证,也就是把客户端读取到本地的块与HDFS上的原始块进行校验,如果发现校验结果不一致,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读。
客户端上传文件时与DataNode建立管道通讯,管道的正方向是客户端向DataNode发送的数据包,管道反向是DataNode向客户端发送ack确认,也就是正确接收到数据包之后发送一个已确认接收到的应答。
当DataNode突然挂掉了,客户端接收不到这个DataNode发送的ack确认,客户端会通知NameNode,NameNode检查该块的副本与原来的不符,NameNode会通知DataNode去复制副本,并将挂掉的DataNode作下线处理,不再让它参与文件上传与下载。
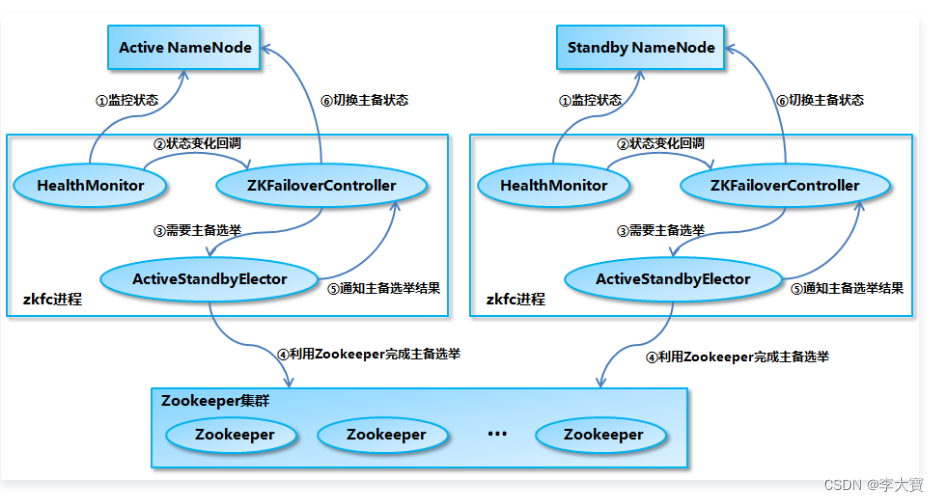
NameNode 的高可用架构主要分为下面几个部分:
Active NameNode 和 Standby(休眠) NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换
元数据信息同步在 HA 方案中采用的是“共享存储”,两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。每次NameNode写EditLog的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向JournalNode集群之中的每一个JournalNode发送写请求,只要大多数的JournalNode节点返回成功就认为向JournalNode集群写入EditLog成功
当Active NN故障时,Zookeeper创建的临时节点ActiveStandbyElectorLock将要被删除,其他NN节点注册的Watcher 来监听到该变化,NN节点的ZKFailoverController 会马上再次进入到创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
新当选的Active NN将确保从QJM(Quorum Journal Manager)同步完所有的元数据文件EditLog文件,然后切换为主节点,并向外提供服务。
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
?作者主页:静Yu?简介:CSDN全栈优质创作者、华为云享专家、阿里云社区博客专家,前端知识交流社区创建者?社区地址:前端知识交流社区?博主的个人博客:静Yu的个人博客?博主的个人笔记本:前端面试题个人笔记本只记录前端领域的面试题目,项目总结,面试技巧等等。接下来会更新蓝桥杯官方系统基础练习的VIP试题,依然包括解题思路,源代码等等。问题描述:给定当前的时间,请用英文的读法将它读出来。时间用时h和分m表示,在英文的读法中,读一个时间的方法是: 如果m为0,则将时读出来,然后加上“o’clock”,如3:00读作“threeo’clock”。 如果m不为0,则将时读出来,然后将分读出来,如5
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
最近更新的博客华为OD机试-卡片组成的最大数字(Python)|机试题算法思路华为OD机试-网上商城优惠活动(一)(Python)|机试题算法思路华为OD机试-统计匹配的二元组个数(Python)|机试题算法思路华为OD机试-找到它(Python)|机试题算法思路华为OD机试-九宫格按键输入(Python)|机试算法备考思路华为OD机试-身高排序(Python)|备考思路使用说明参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。华为OD清单查看地址:blog.csdn.net/hihell/catego
云计算实验中要求我们在Linux系统安装Hadoop,故来做一个简单的记录。· 注:我的操作系统环境是Ubuntu-20.04.3,安装的JDK版本为jdk1.8.0_301,安装的Hadoop版本为hadoop2.7.1。(不确定其他版本是否会出现版本兼容问题)Hadoop安装步骤如下: 一、更新apt和安装vim编辑器 二、配置本机无密码登录SSH 三、安装JAVA环境 四、下载安装Hadoop 五、伪分布式搭建一、更新apt和安装vim编辑器1、更新aptsudoapt-getupdate2、安装vim
前言介绍了网络安全岗位常见的面试题,仅供参考!一、常识部分1.Linux服务器种用户关键信息存储在那个文件中?启动、停止、重启、开机自启mysql服务命令?如何查找/etc/test.txt文件中"password"关键字信息?如何精确查找80端口?/etc/passwdsystemctlstartmysqld或systemmysqldstart 启动systemctlstopmysqld或systemmysqldstop 停止systemctlrestartmysqld或systemmysqldrestart 重启systemctlenablemysqld或systemmysqldenabl
一、设置免密登录1、系统偏好设置-----共享----勾选远程登录,所有用户2、打开终端,输入命令ssh-keygen-trsa,一直回车即可2.查看生成的公钥和私钥 cd~/.ssh ls会看到~/.ssh目录下有两个文件:①私钥:id_rsa②公钥:id_rsa.pub3.将公钥内容写入到~/.ssh/authorized_keys中 cat~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys4.测试在terminal终端输入 sshlocalhost如果出现以下询问输入yes,不需要输入密码就能登录,说明配置成功Areyousureyouw
我在之前的面试中遇到了这个问题,但做不到,知道吗?这是做什么的:`$=`;$_=\%!;($_)=/(.)/;$==++$|;($.,$/,$,,$\,$",$;,$^,$#,$~,$*,$:,@%)=($!=~/(.)(.).(.)(.)(.)(.)..(.)(.)(.)..(.)......(.)/,$"),$=++;$.++;$.++;$_++;$_++;($_,$\,$,)=($~.$"."$;$/$%[$?]$_$\$,$:$%[$?]",$"&$~,$#,);$,++;$,++;$^|=$";`$_$\$,$/$:$;$~$*$%[$?]$.$~$*${#}$%[$?]$;
最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理已参加机试人员的实战技巧本篇题解:贪心的商人or最大利润题目描述商人经营一家店铺,有number种商品,由于仓库限制每件商品的最大持有数量是item[index],每种商品的价格在每天是item_price[item_index][day],通过对商品的买进和卖出获取利润,请给出商人在days天内能获取到的最大的利润;注:同一件商品可以反复买进和卖出;输入描述3//输入商品的数量nu