分享嘉宾:张鸿志博士 美团 算法专家
编辑整理:廖媛媛 美的集团
出品平台:DataFunTalk
导读:美团作为中国最大的在线本地生活服务平台,连接着数亿用户和数千万商户,其背后蕴含着丰富的与日常生活相关的知识。美团知识图谱团队从2018年开始着力于图谱构建和利用知识图谱赋能业务,改善用户体验。具体来说,“美团大脑”是通过对美团业务中千万数量级的商家、十亿级别的商品和菜品、数十亿的用户评论和百万级别的场景进行深入的理解来构建用户、商户、商品和场景之间的知识关联,进而形成的生活服务领域的知识大脑。目前,“美团大脑”已经覆盖了数十亿实体、数百亿的三元组,在餐饮、外卖、酒店、到综等领域验证了知识图谱的有效性。今天我们介绍美团大脑中生活服务知识图谱的构建及应用,主要围绕以下3个方面展开:
--
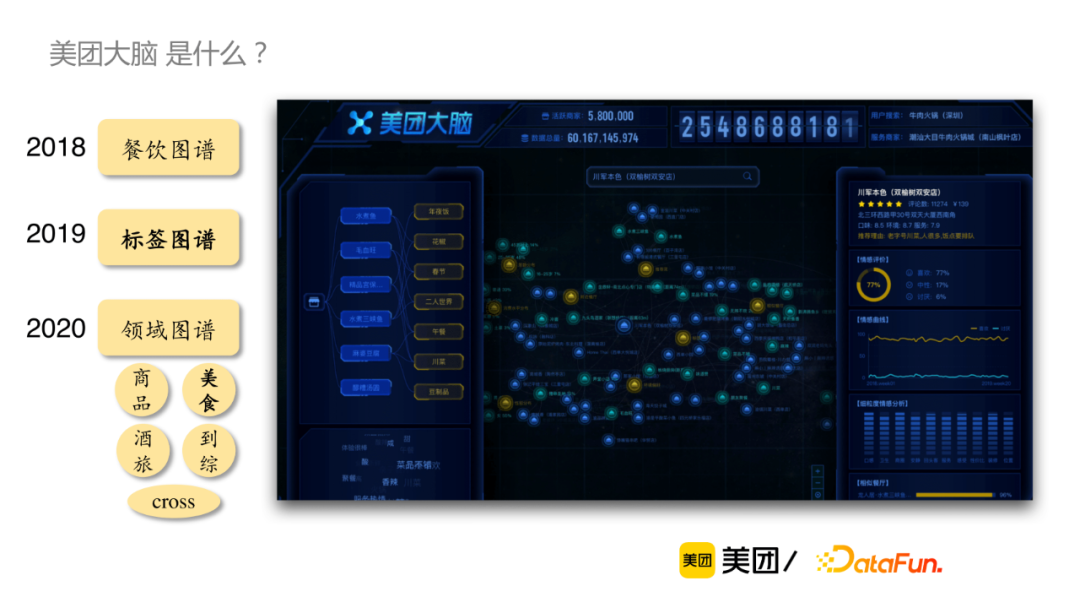
“美团大脑”是什么?
以下是“美团大脑”构建的整体RoadMap,最先是2018年开始餐饮知识图谱构建,对美团丰富的结构化数据和用户行为数据进行初步挖掘,并在一些重要的数据维度上进行深入挖掘,比如说对到餐的用户评论进行情感分析。2019年,以标签图谱为代表,重点对非结构化的用户评论进行深入挖掘。2020年以后,开始结合各领域特点,逐个领域展开深度数据挖掘和建设,包括商品、美食、酒旅和到综和cross图谱等。
--
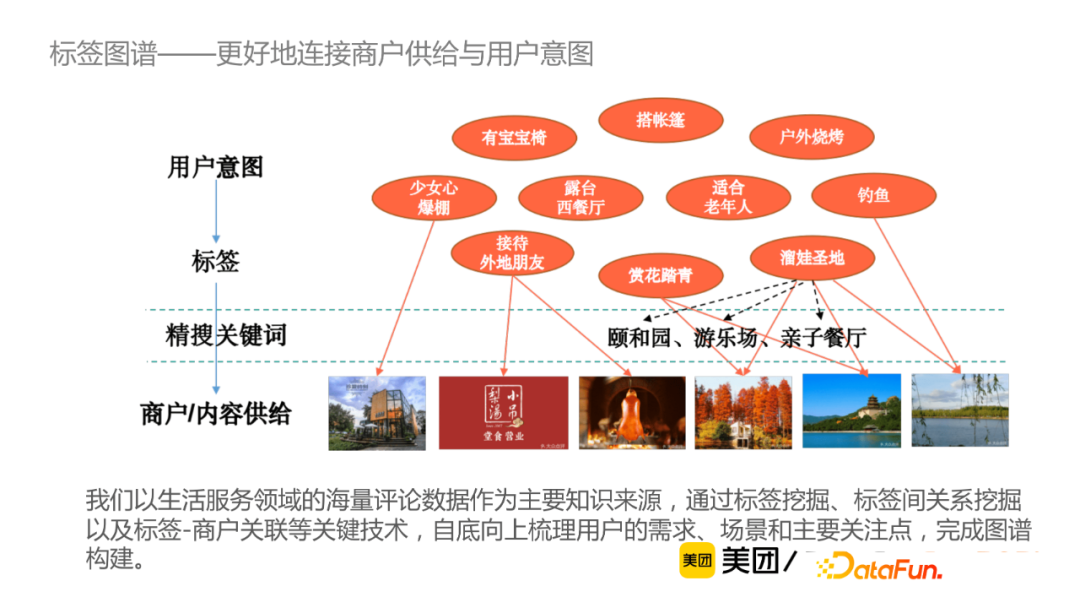
在搜索中,通常用户需要将其意图抽象为搜索引擎能够支持的一系列精搜关键词。标签知识图谱则是通过“标签”来承载用户需求,从而提升用户搜索体验。例如,通过标签知识图谱,用户可直接搜索“带孩子”或者“情侣约会”,就可返回合适的商户/内容供给。从信息增益角度来说,用户评论这种非结构化文本蕴含了大量的知识(比如某个商户适合的场景、人群、环境等),通过对非结构化数据的挖掘实现信息增益。该团队以生活服务领域的海量评论数据作为主要知识来源,通过标签挖掘、标签间关系挖掘以及标签-商户关联等关键技术,自下而上梳理用户需求,场景及主要关注点完成图谱构建。
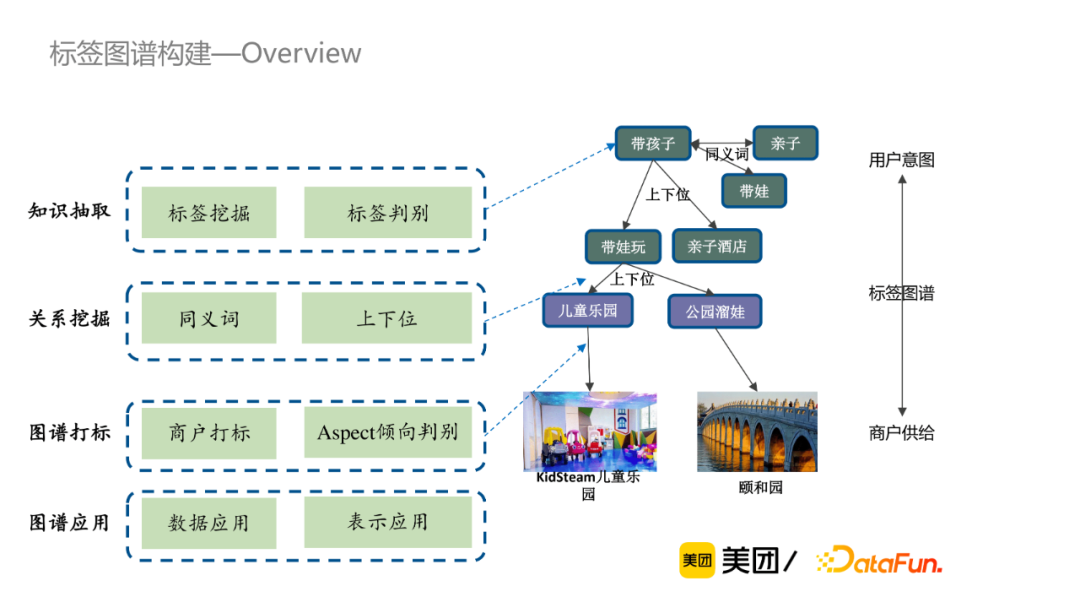
标签知识图谱构建分为以下四个部分:知识抽取、关系挖掘、图谱打标和图谱应用。
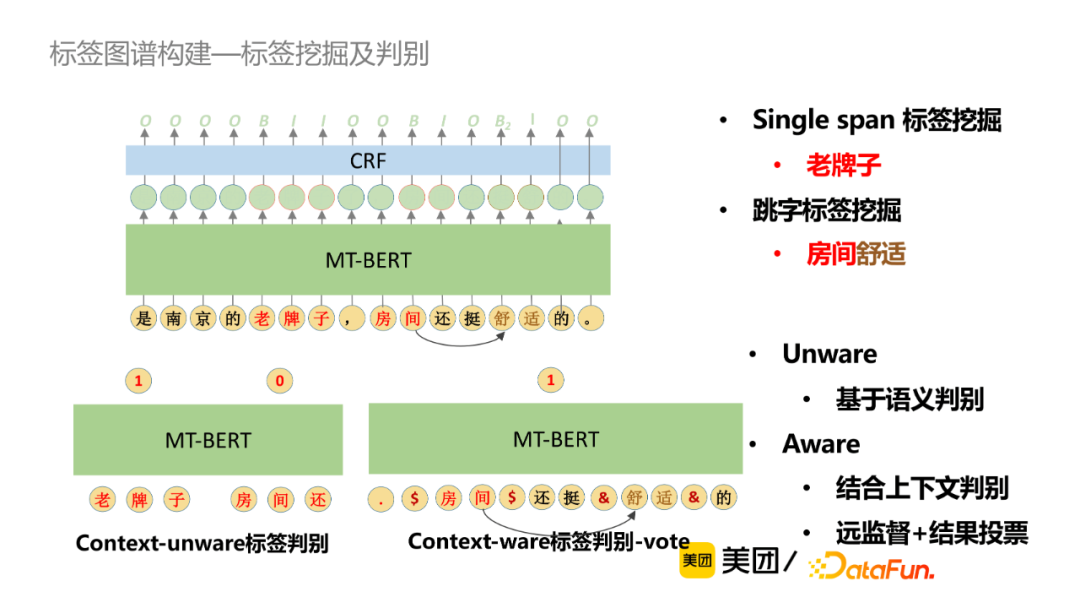
① 知识抽取
标签挖掘采用简单的序列标注架构,包括Single span标签挖掘和跳字标签挖掘,此外还会结合语义判别或者上下文判别,采用远监督学习+结果投票方式获取更精准的标签。
② 关系挖掘
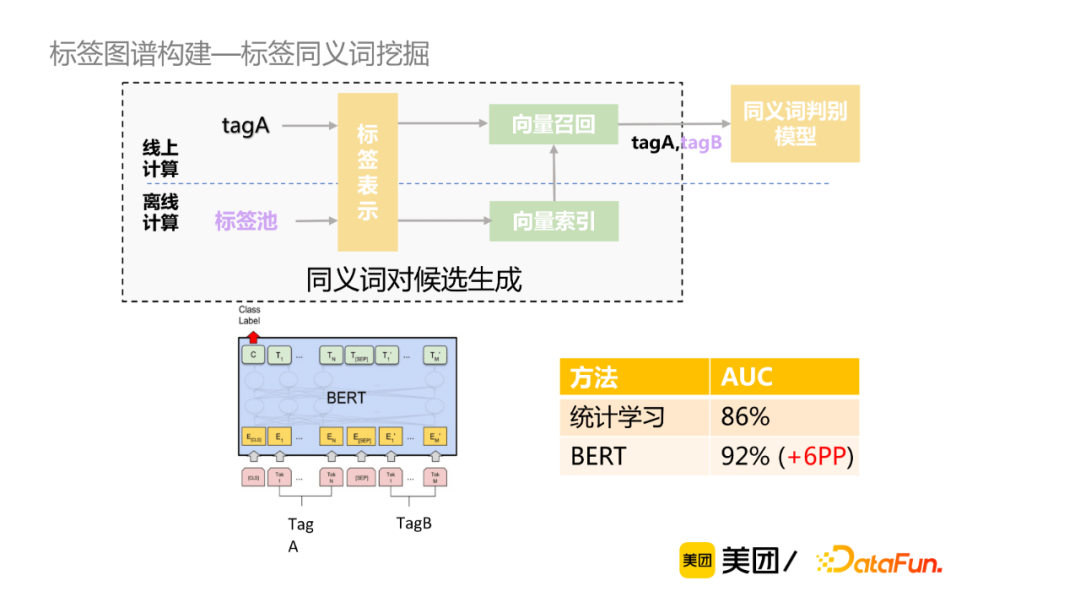
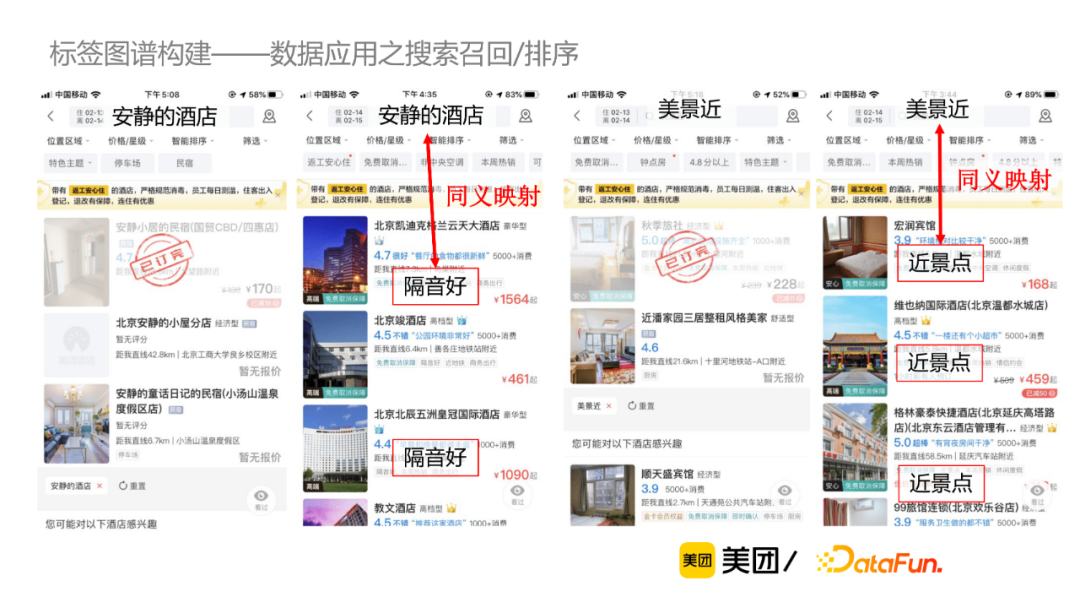
同义词挖掘:同义词挖掘被定义为给定包含N个词的池子,M个业务标签词,查找M中每个词在N中的同义词。现有的同义词挖掘方法包括搜索日志挖掘、百科数据抽取、基于规则的相似度计算等,缺乏一定的通用性。当前我们的目标是寻找通用性强,可广泛应用到大规模数据集的标签同义词挖掘方法。
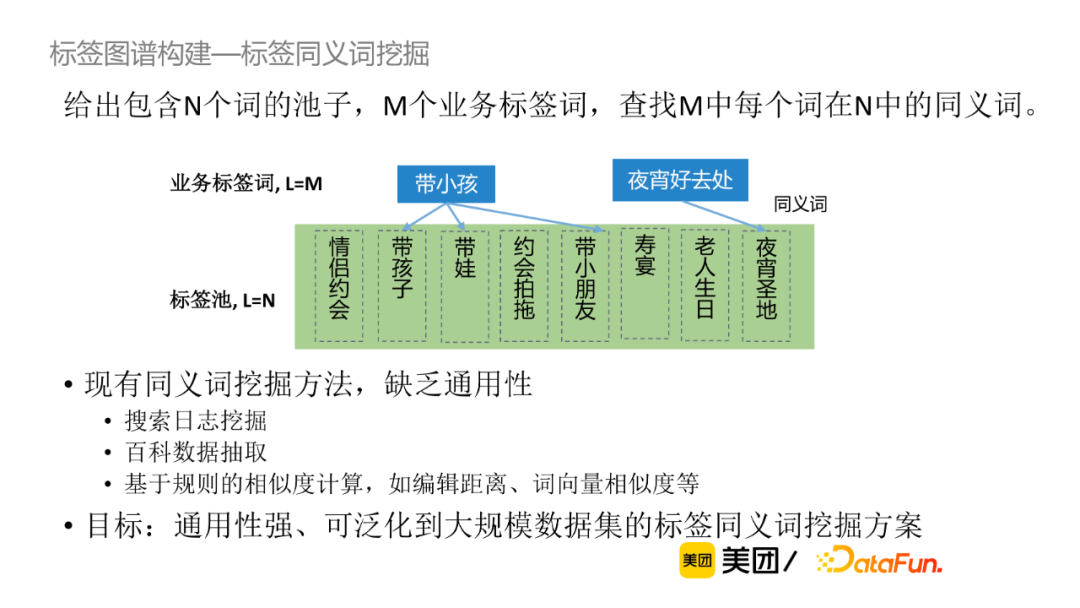
以下是作者给出的同义词挖掘的具体方案,首先将离线标签池或者线上查询标签进行向量表示获取向量索引,再进行向量哈希召回,进一步生成该标签的TopN的同义词对候选,最后使用同义词判别模型。该方案的优势在于降低了计算复杂度,提升了运算效率;对比倒排索引候选生成,可召回字面无overlap的同义词,准确率高,参数控制简单。
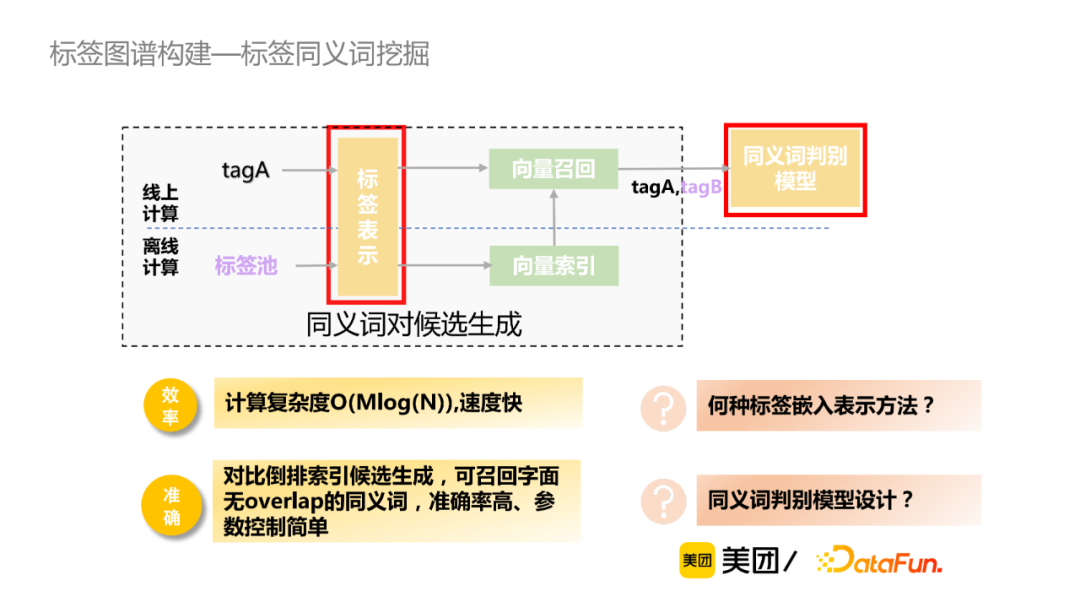
对于有标注数据,主流的标签词嵌入表示方法有word2vec、BERT等。word2vec方法实现较为简单,词向量取均值,忽略了词的顺序;BERT通过预训练过程中能捕捉到更为丰富的语义表示,但是直接取[CLS]标志位向量,其效果与word2vec相当。Sentence-Bert对于Bert模型做了相应的改进,通过双塔的预训练模型分别获取标签tagA和tagB表征向量,然后通过余弦相似性度量这两个向量的相似性,由此获取两个标签的语义相似性。
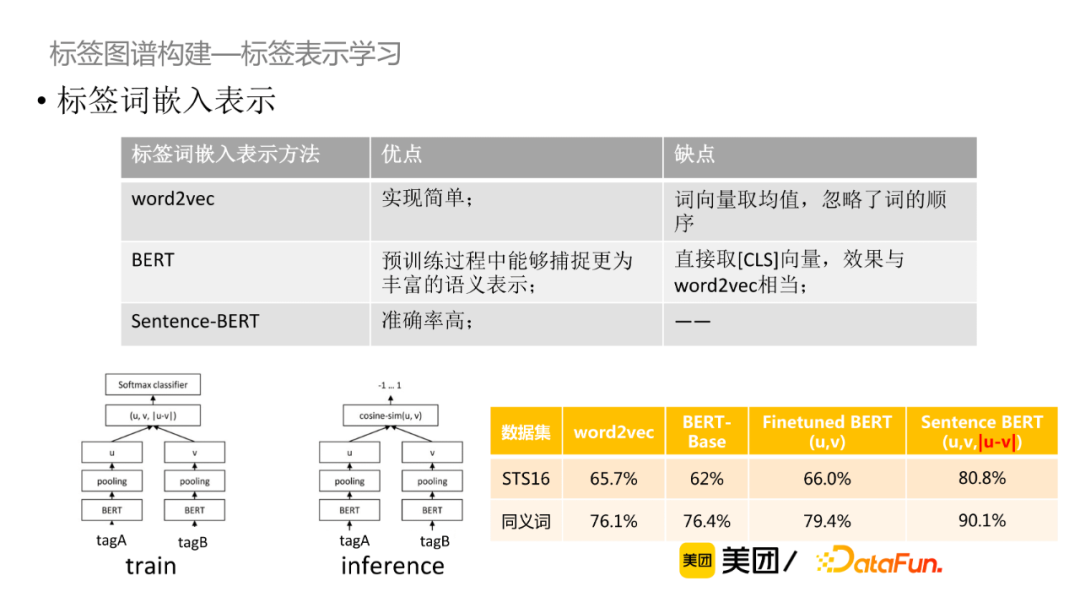
对于无标注数据来说,可以通过对比学习的方法获取句子的表示。如图所示,Bert原始模型对于不同相似度的句子的向量相似度都很高,经过对比学习的调整之后,向量的相似度能够较好地体现出文本相似度。
对比学习模型设计:首先给定一个sentence,对这个样本做扰动产生样本pair,常规来说,在embedding层加上Adversarial Attack、在词汇级别做Shuffling或者丢掉一些词等构成pair;在训练的过程中,最大化batch内同一样本的相似度,最小化batch内其他样本的相似度。最终结果显示,无监督学习在一定程度上能达到监督学习的效果,同时无监督学习+监督学习相对于监督学习效果有显著提升。
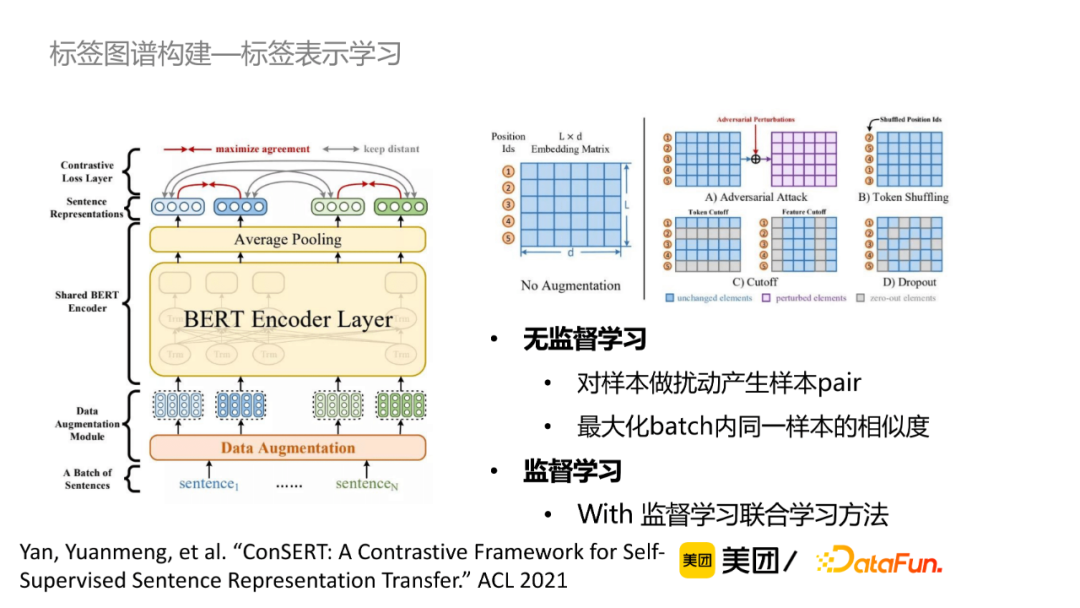
同义词判别模型设计:将两个标签词拼接到Bert模型中,通过多层语义交互获取标签。
标签上下位挖掘:词汇包含关系是最重要的上下位关系挖掘来源,此外也可通过结合语义或统计的挖掘方法。但当前的难点是上下位的标准较难统一,通常需要结合领域需求,对算法挖掘结果进行修正。

③ 图谱打标:如何构建标签和商户供给的关联关系?
给定一个标签集合,通过标签及其同义词在商户UGC/团单里出现的频率,卡一个阈值从而获取候选tag-POI。这样会出现一个问题是,即使是频率很高但不一定有关联,因此需要通过一个商户打标判别模块去过滤bad case。
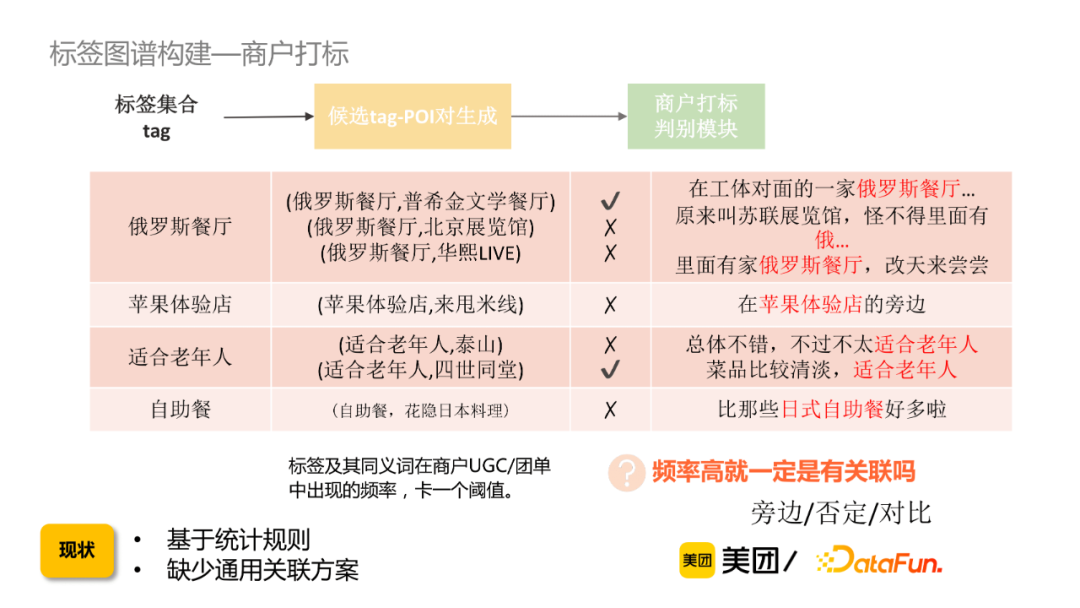
商户打标考虑标签与商户、用户评论、商户Taxonomy等三个层次的信息。具体来讲,标签-商户粒度,将标签与商户信息(商户名、商户三级类目、商户top标签)做拼接输入到Bert模型中做判别。
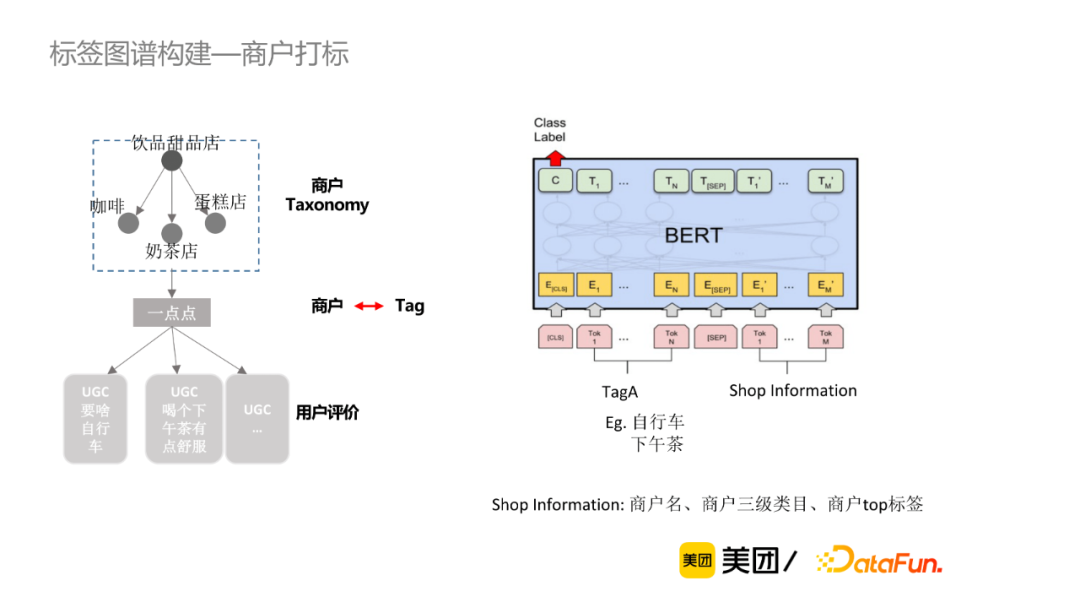
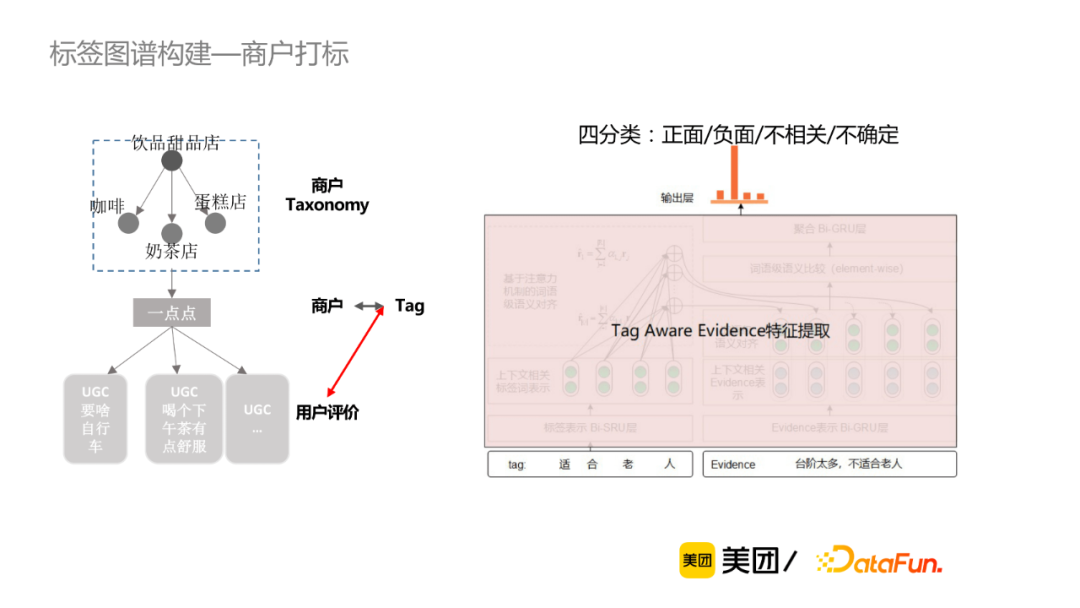
微观的用户评论粒度,判断每一个标签与提到该标签的评论(称为evidence)之间是正面、负面、不相关还是不确定的关系,因此可当作四分类的判别模型。我们有两种方案可选择,第一种是基于多任务学习的方法, 该方法的缺点在于新增标签成本较高,比如新增一个标签,必须为该标签新增一些训练数据。笔者最终采用的是基于语义交互的判别模型,将标签作为参数输入,使该模型能够基于语义判别,从而支持动态新增标签。
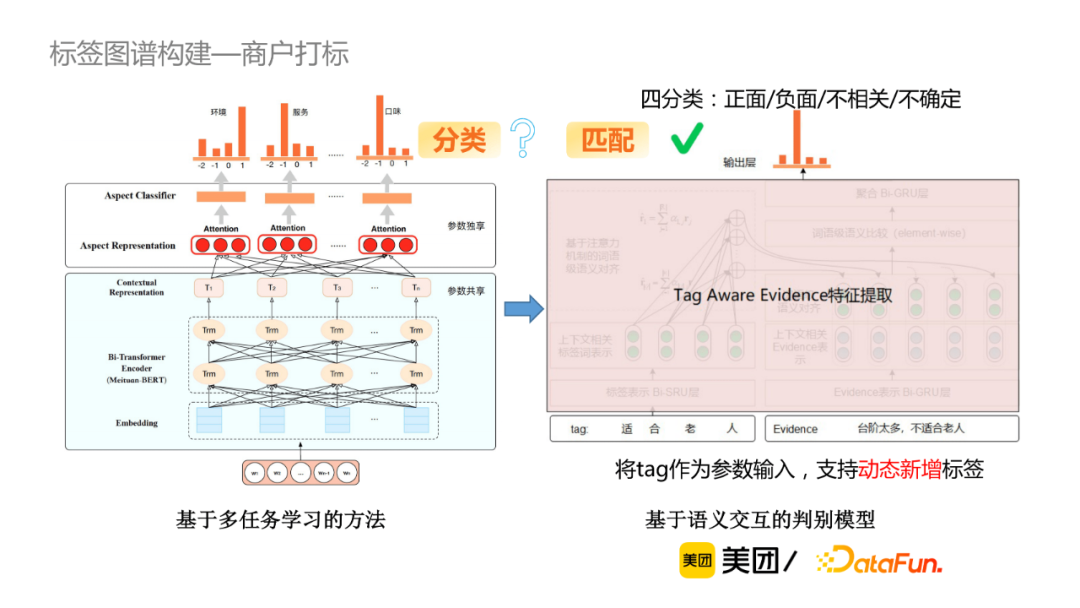
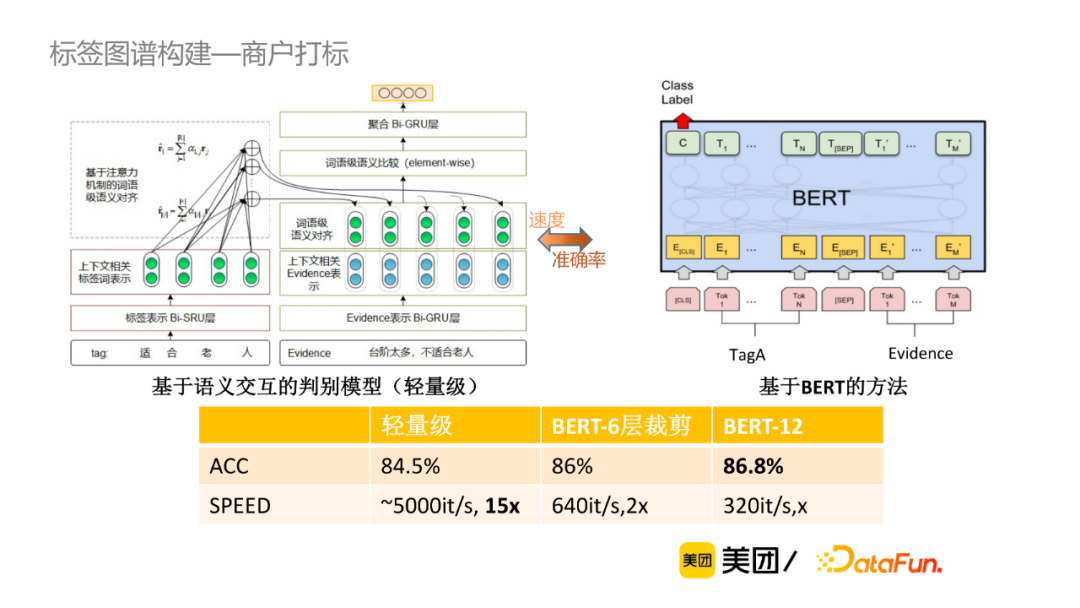
基于语义交互的判别模型,首先做向量表示,然后是交互,最终聚合比较结果,该方法的计算速度较快,而基于BERT的方法,计算量大但准确率较高。我们在准确率和速度上取balance,例如当POI有30多条的evidence,倾向于使用轻量级的方式;如果POI只有几条evidence,可以采用准确率较高的方式进行判别。
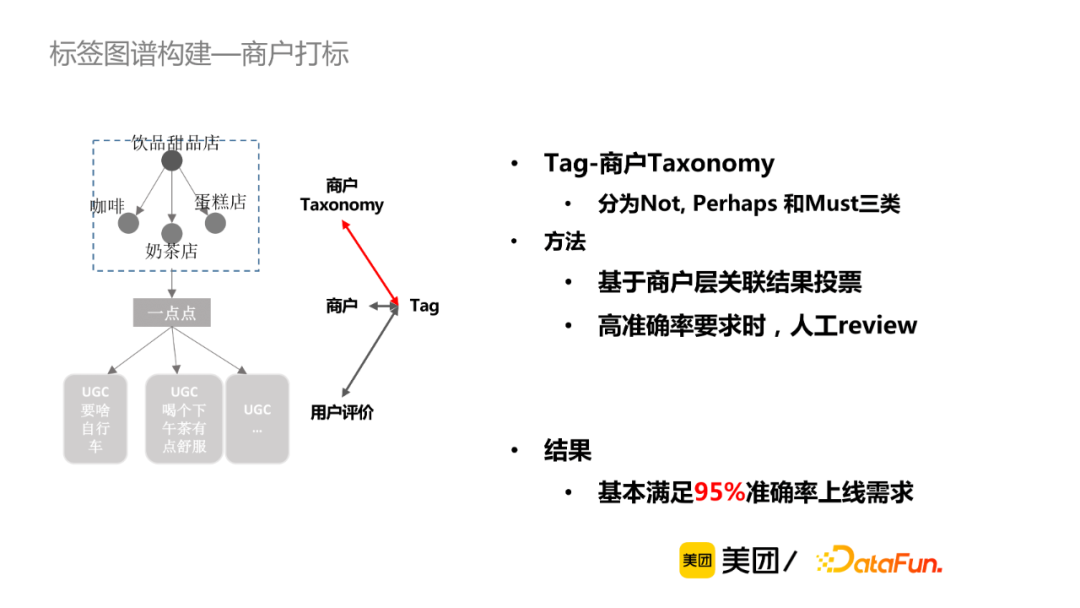
从宏观角度,主要看标签和类目是否匹配,主要有三种关系:一定不会,可能会,一定会。一般通过商户层关联结果进行投票结果,同时会增加一些规则,对于准确率要求较高时,可进行人工review。
④ 图谱应用:所挖掘数据的直接应用或者知识向量表示应用
在商户知识问答相关的场景,我们基于商户打标结果以及标签对应的evidence回答用户问题。
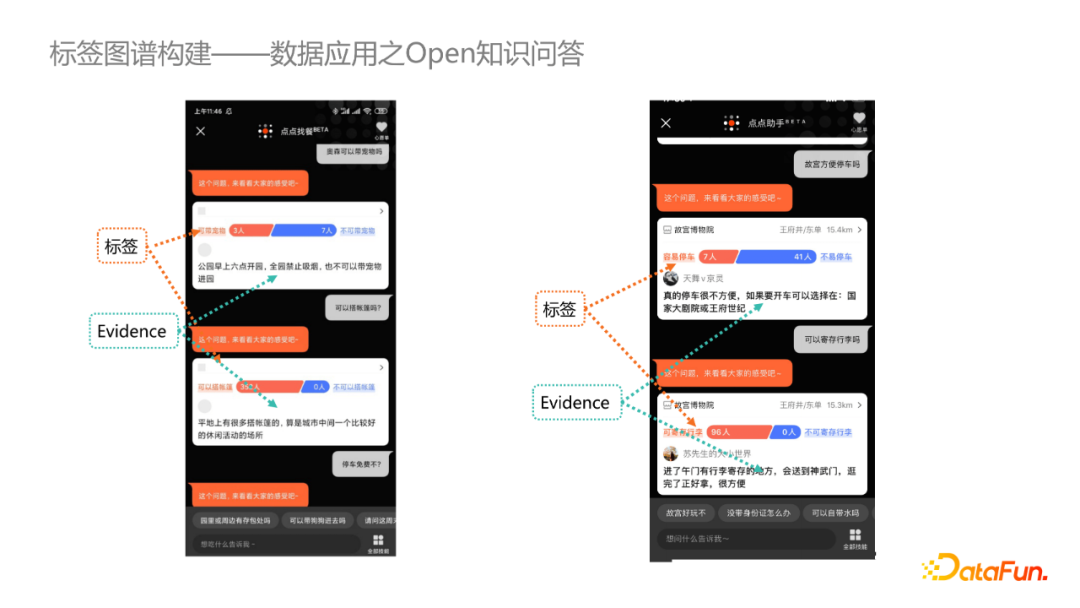
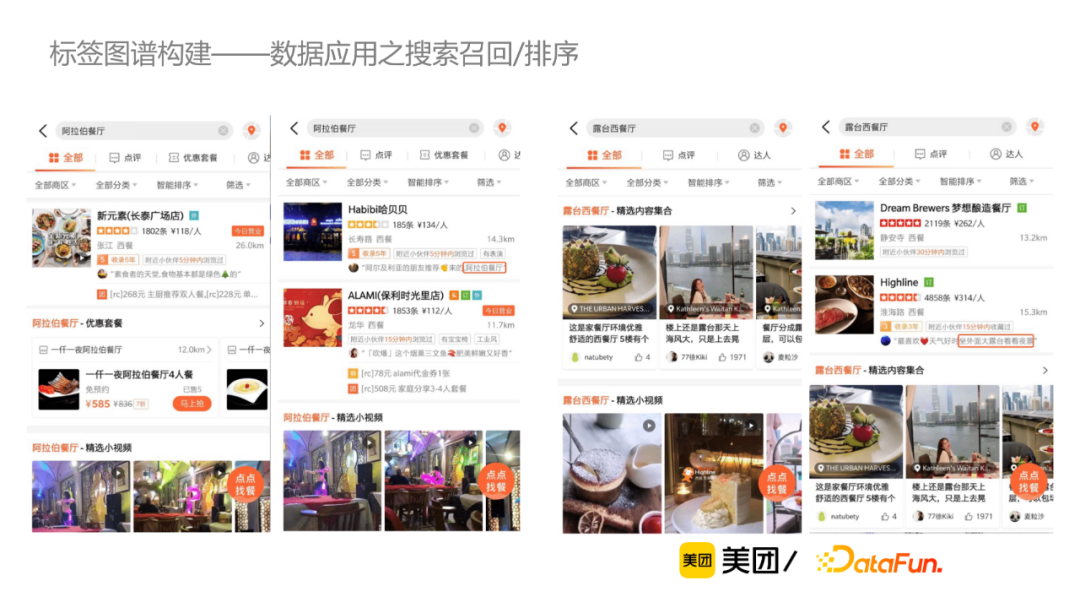
首先识别用户query中的标签并映射为id,然后通过搜索召回或者排序层透传给索引层,从而召回出有打标结果的商户,并展示给C端用户。A/B实验表明,用户的长尾需求搜索体验得到显著提升。此外,也在酒店搜索领域做了一些上线实验,通过同义词映射等补充召回手段,搜索结果有明显改善。
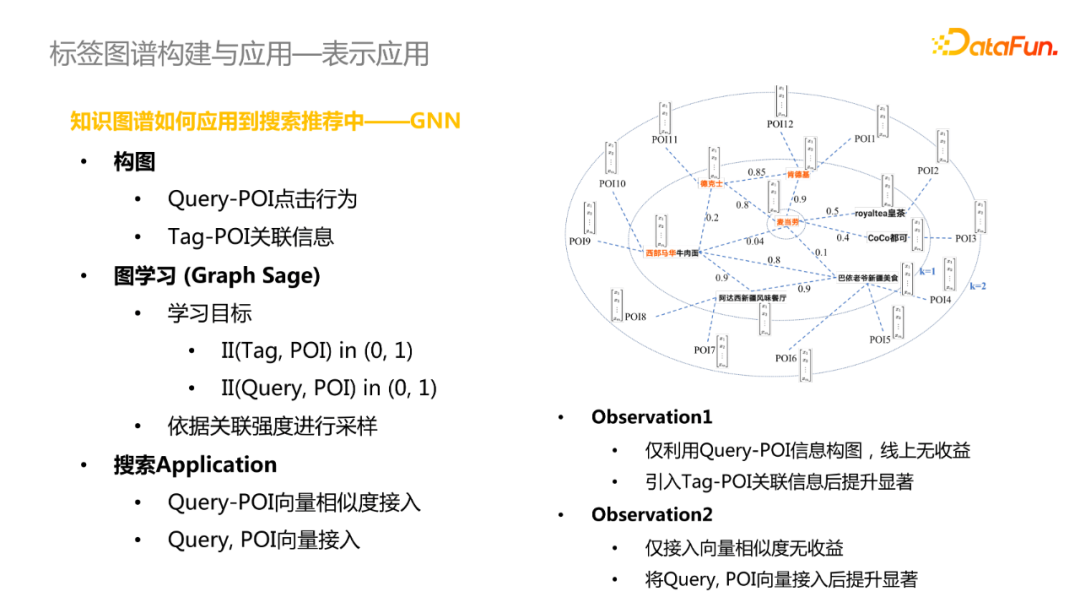
主要采用GNN模型实现,在构图中构建了两种边,Query-POI点击行为和Tag-POI关联信息;采用Graph Sage进行图学习,学习的目标是判断Tag和POI是否有关联关系或者Query和POI是否点击关系,进一步依据关联强度进行采样。上线后结果显示,在仅利用Query-POI信息构图时,线上无收益,在引入Tag-POI关联信息后线上效果得到显著提升。这可能是因为排序模型依赖于Query-POI点击行为信息去学习,引入Graph Sage学习相当于换了一种学习的方式,信息增益相对较少;引入Tag-POI信息相当于引入了新的知识信息,所以会带来显著提升。
此外,仅接入Query-POI向量相似度线上效果提升不佳,将Query和POI向量接入后效果得到显著提升。这可能是因为搜索的特征维度较高,容易忽略掉向量相似度特征,因此将Query和POI向量拼接进去后提升了特征维度。
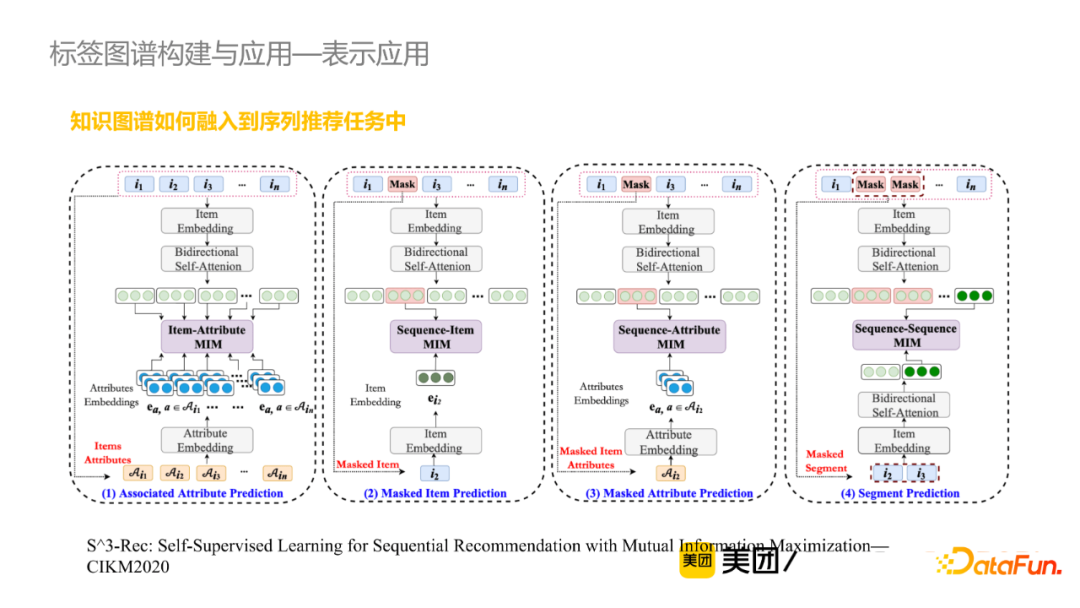
该任务通过当前已知的Item去预测用户点击的Masked Item。比如说获取Item的上下文表征的时候,将相关的Attribute信息也进行向量表征,从而去判断Item是否有Attribute信息。
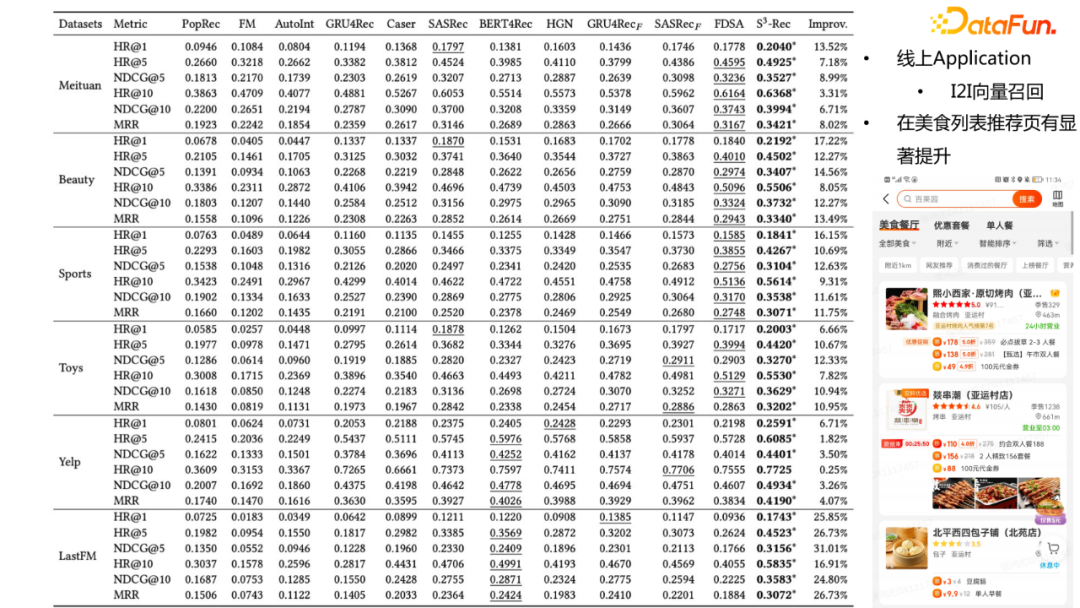
此外,还可以做Masked Item Attribute 预测,从而将标签的知识图谱信息融入到序列推荐任务中去。实验结果表明,引入知识信息后的准确率在不同的数据集上均有数量级的提升。同时,我们也做了线上转化的工作,将Item表征做向量召回;具体来说,基于用户历史上点击过的Item去召回topN相似的Item,从而补充线上推荐结果,在美食列表推荐页有显著提升。
--
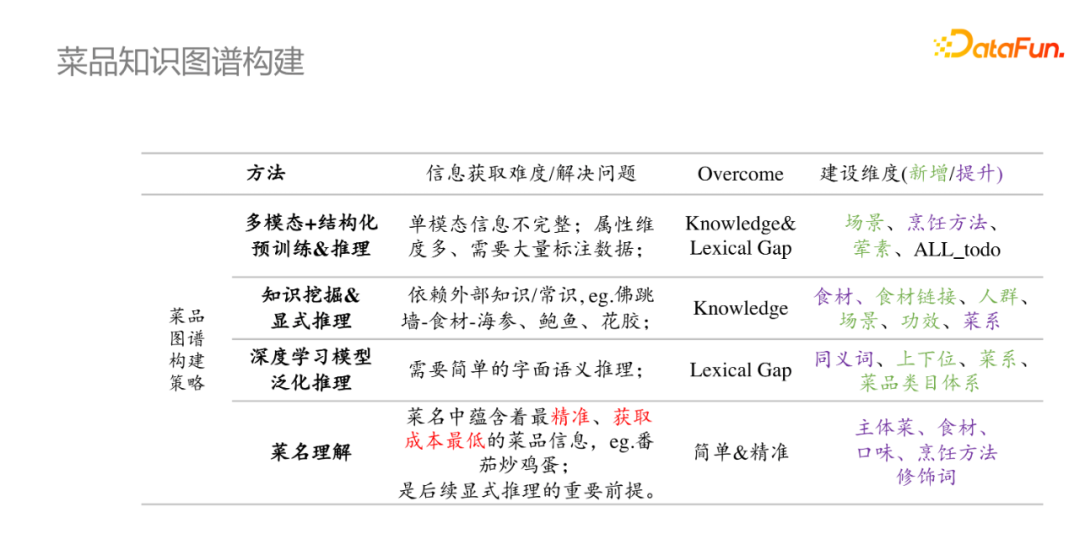
菜品知识图谱的构建目标,一方面是构建对菜品的系统理解能力,另一方面是构建较为完备的菜品知识图谱,这里从不同的层次来说明菜品知识图谱的构建策略。
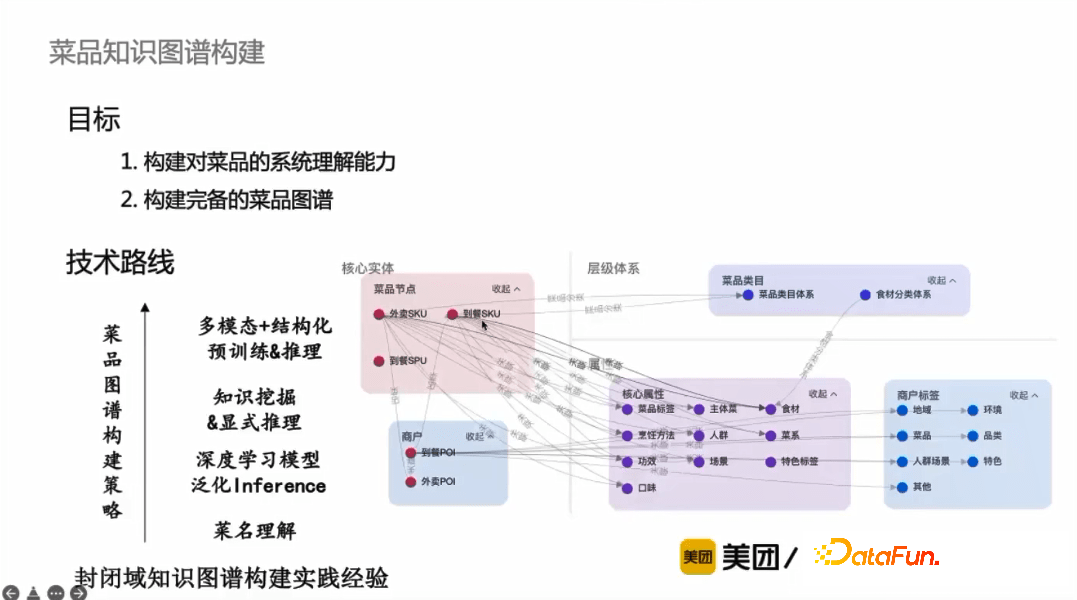
** * 菜名理解**
菜名中蕴含着最精准、获取成本最低的菜品信息,同时对菜名的理解也是后续显式知识推理泛化能力的前提。首先是抽取菜名的本质词/主体菜,然后序列标注去识别菜名中的每个成分。针对两种场景设计了不同的模型,对于有分词情况,将分词符号作为特殊符号添加到模型中,第一个模型是识别每个token对应的类型;对于无分词情况,需要先做Span-Trans的任务,然后再复用有分词情况的模块。

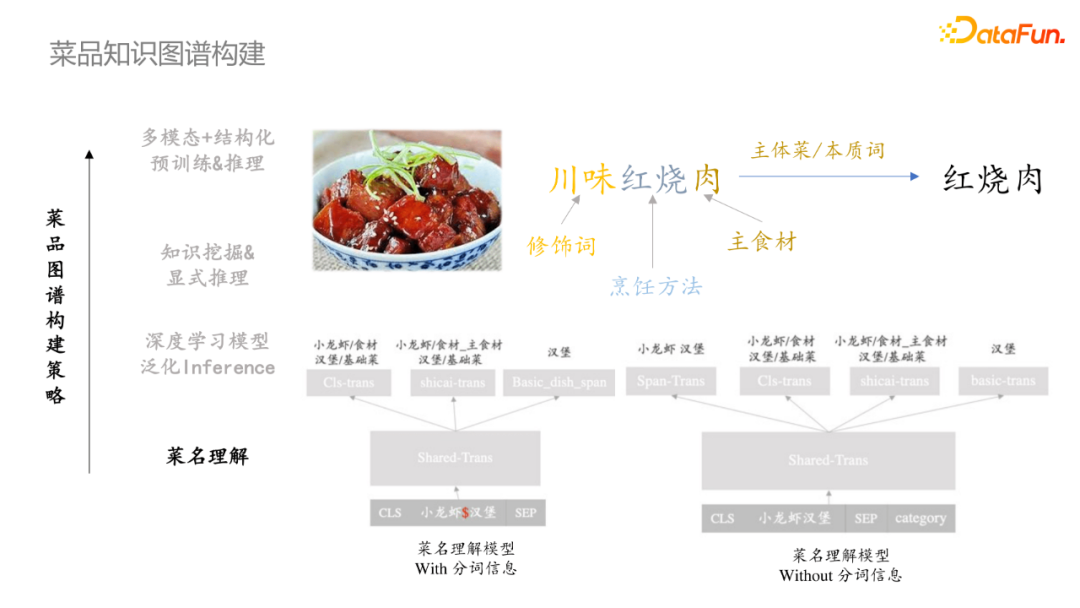
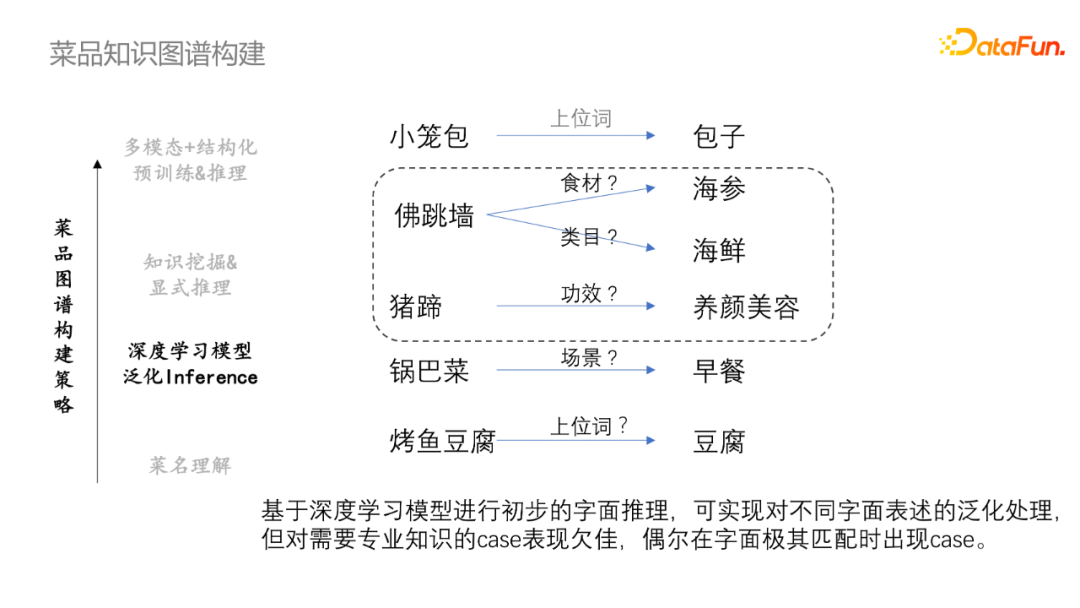
菜名理解是一个较为重要的信息来源,但是所蕴含的知识相对有限,从而提出了基于深度学习模型进行初步字符推断,可实现对不同字面表述的泛化处理。但是对需要专业知识的case表现欠佳,偶尔在字面极其匹配时出现case。
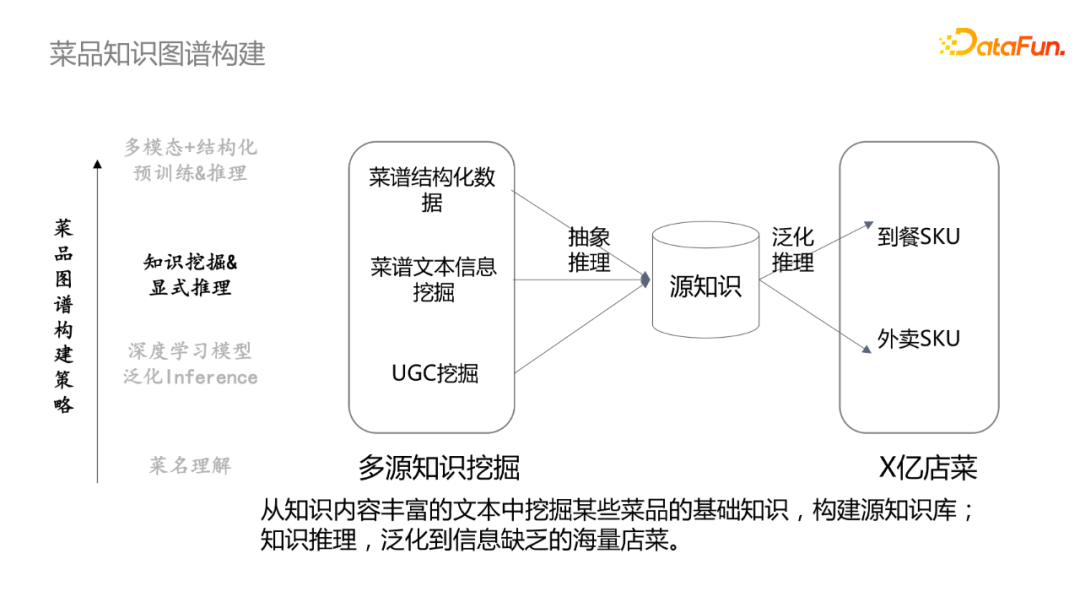
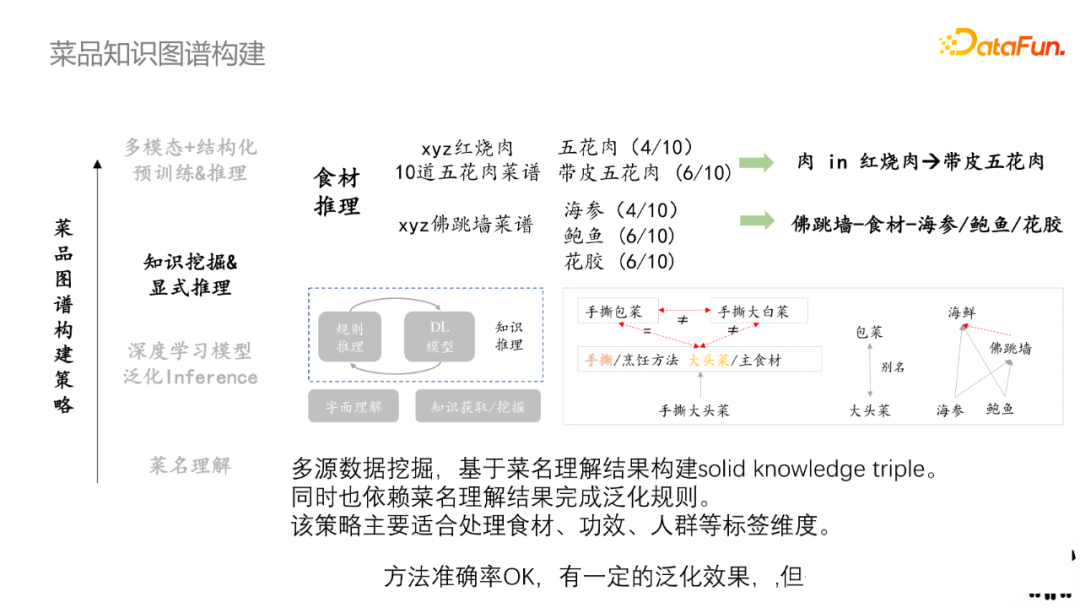
从知识内容丰富的文本中挖掘某些菜谱的基础知识,来构建源知识库;然后通过泛化推理去映射到具体SKU中。在食材推理中,比如菜品种有多道红烧肉,统计10道五花肉中有4道是指五花肉,6道是指带皮五花肉,因此肉就转化为带皮五花肉。对应地,佛跳墙有多道菜谱,先通过统计每种食材出现的概率,可以卡一个阈值,然后表明该菜谱的食谱是什么。
多源数据挖掘,基于菜名理解结果构建solid knowledge triple,同时也依赖菜名理解结果泛化规则。该策略主要适用于处理食材、功效、人群等标签。该方法准确率OK,有一定泛化能力,但覆盖率偏低。
业务内有一些比较好用的训练数据,例如1000万商户编辑自洽的店内分类树。基于该数据可产生5亿的 positive pairs 和 30G corpus。在模型训练中,会随机替换掉菜谱分类的 tab/shop,模型判断 tab/shop 是否被替换;50%的概率drop shop name,使得模型仅输入菜名时表现鲁棒。同时,对模型做了实体化改进,将分类标签作为bert的词进行训练,将该方法应用到下游模型中,在10w标注数据下,菜谱上下位/同义词模型准确率提升了1.8%。


首先使用ReseNet对菜谱图片进行编,使用Bert模型对菜谱文本信息做编码,通过对比学习loss去学习文本和店菜的匹配信息。这里采用双塔模型,一方面是下游应用较为方便,单塔模型可独立使用,也可inference出菜品图片的表示并缓存下来;另一方面是图片内容单纯,暂无交互式建模的必要。训练目标分别是图片与店菜匹配、图片与菜名对齐,图片与Tab对齐。
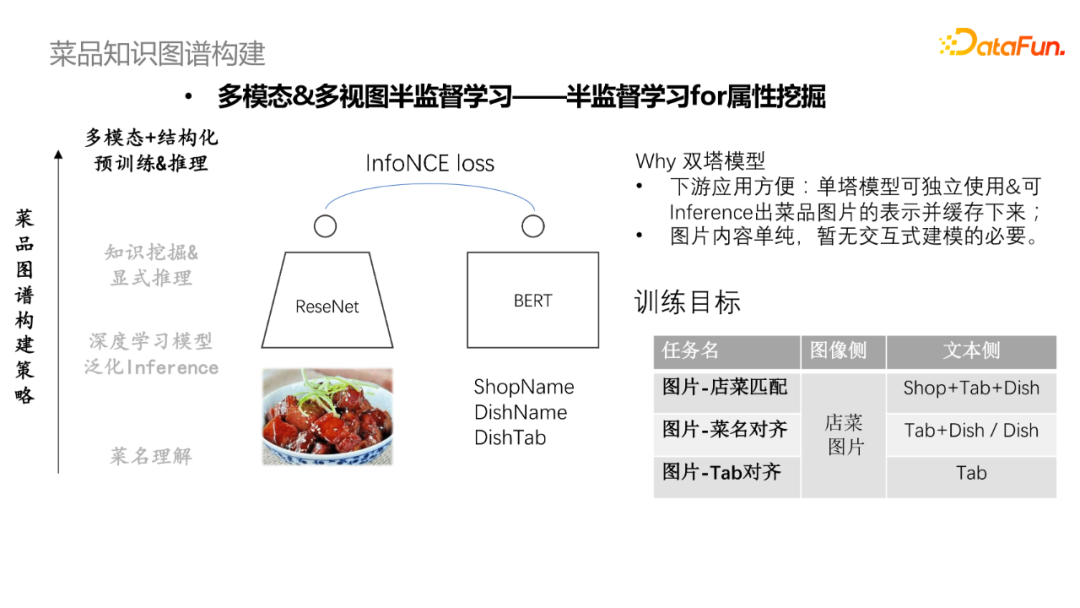
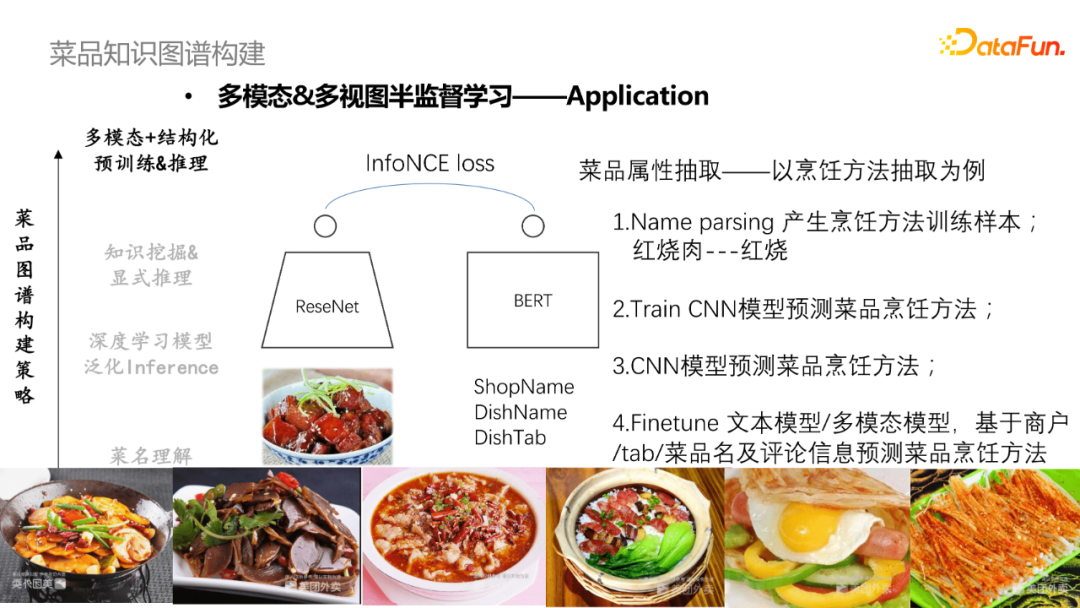
可基于多模态信息做菜品品类预测或者菜谱信息补全。比如,预测“猪肉白菜”加上了图片信息将更加直观和准确。基于文本和视图模态信息进行多视图半监督的菜谱属性抽取,以烹饪方式抽取为例,首先通过产生烹饪方法训练样本(红烧肉-红烧);然后采用CNN模型去训练预测菜谱烹饪方法,指导Bert模型Finetune文本模型或者多模态模型,基于商户/tab/菜品及评论信息预测菜品烹饪方法;最终对两个模型进行投票或者将两个特征拼接做预测。
综上,我们对菜品知识图谱构建进行相应的总结。菜品理解比较适合SKU的初始化;深度学习推理模型和显式推理模型比较适合做同义词、上下位、菜系等;最终是想通过多模态+结构化预训练和推理来解决单模态信息不完整、属性维度多、需要大量标注数据等问题,因此该方法被应用到几乎所有的场景中。
今天的分享就到这里,谢谢大家。
分享嘉宾:

本文首发于微信公众号“DataFunTalk”。
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt