作者:vivo 互联网服务器团队- Chen Dongxing、Li Haoxuan、Chen Jinxia
随着业务的日渐复杂,性能优化俨然成为了每一位技术人的必修课。性能优化从何着手?如何从问题表象定位到性能瓶颈?如何验证优化措施是否有效?本文将介绍分享 vivo push 推荐项目中的性能调优实践,希望给大家提供一些借鉴和参考。
在 Push 推荐中,线上服务从 Kafka 接收需要触达用户的事件,之后为这些目标用户选出最合适的文章进行推送。服务由 Java 开发,CPU 密集计算型。
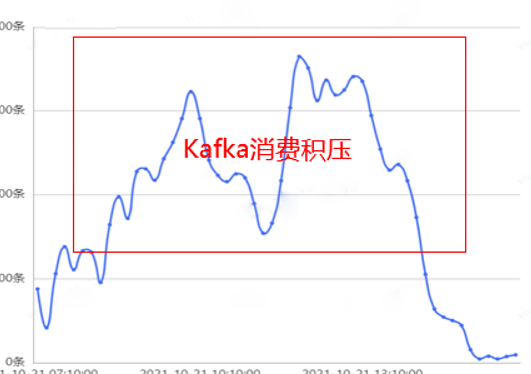
随着业务的不断发展,请求并发及模型计算量越来越大,导致工程上遇到了性能瓶颈,Kafka 消费出现严重的积压现象,无法及时完成目标用户的分发,业务增长诉求得不到满足,故亟需进行性能专项优化。
我们的性能衡量指标是吞吐量 TPS ,由经典公式 TPS = 并发数 / 平均响应时间RT 可以知道,若需提高 TPS,可以有 2 种方式:
提高并发数,比如提升单机的并行线程数,或者横向扩容机器数;
降低平均响应时间 RT,包括应用线程(业务逻辑)执行时间,以及 JVM 本身的 GC 耗时。
实际情况中,我们的机器 CPU 利用率已经很高,达到 80% 以上,提升单机并发数的预期收益有限,故把主要精力投入到降低 RT 上。
下面将从 热点代码 和 JVM GC 两个方面进行详解,我们如何分析定位到性能瓶颈点,并使用 3 招将吞吐量提升 100% 。
如何快速找到应用中最耗时的热点代码呢?借助阿里巴巴开源的 arthas 工具,我们获取到线上服务的 CPU 火焰图。
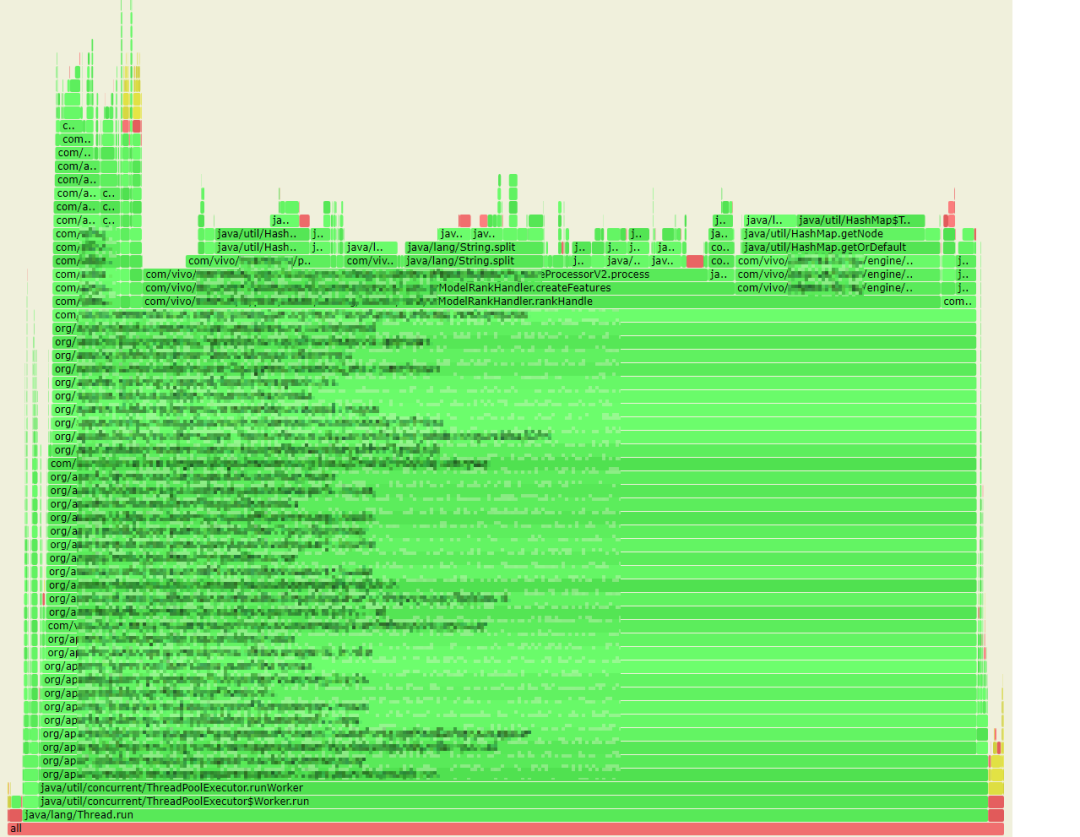
火焰图说明:火焰图是基于 perf 结果产生的 SVG 图片,用来展示 CPU 的调用栈。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有“平顶”(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
从火焰图中,我们首先发现了有 13% 的 CPU 时间花在了 java.lang.String.split 方法上。
熟悉性能优化的同学会知道,原生 split 方法是性能杀手,效率比较低,频繁调用时会耗费大量资源。
不过业务上特征处理时确实需要频繁地 split,如何优化呢?
通过分析 split 源码,以及项目的使用场景,我们发现了 3 个优化点:
(1)业务中未使用正则表达式,而原生 split 在处理分隔符为 2 个及以上字符时,默认按正则表达式方式处理;众所周知,正则表达式的效率是低下的。
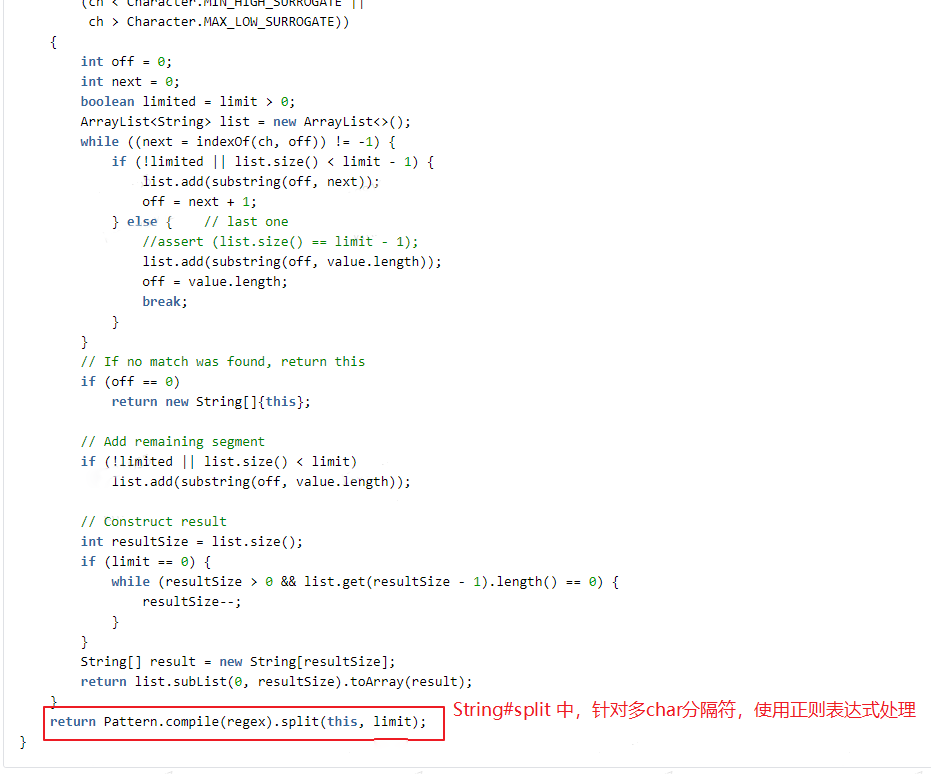
(2)当分隔符为单个字符(且不为正则表达式字符)时,原生 String.split 进行了性能优化处理,但中间有些内部转换处理,在我们的实际业务场景中反而是多余的、消耗性能的。
其具体实现是:通过 String.indexOf 及 String.substring 方法来实现分割处理,将分割结果存入 ArrayList 中,最后将 ArrayList 转换为 string[] 输出。而我们业务中,其实很多时候需要 list 型结果,多了 2 次 list 和 string[] 的互转。
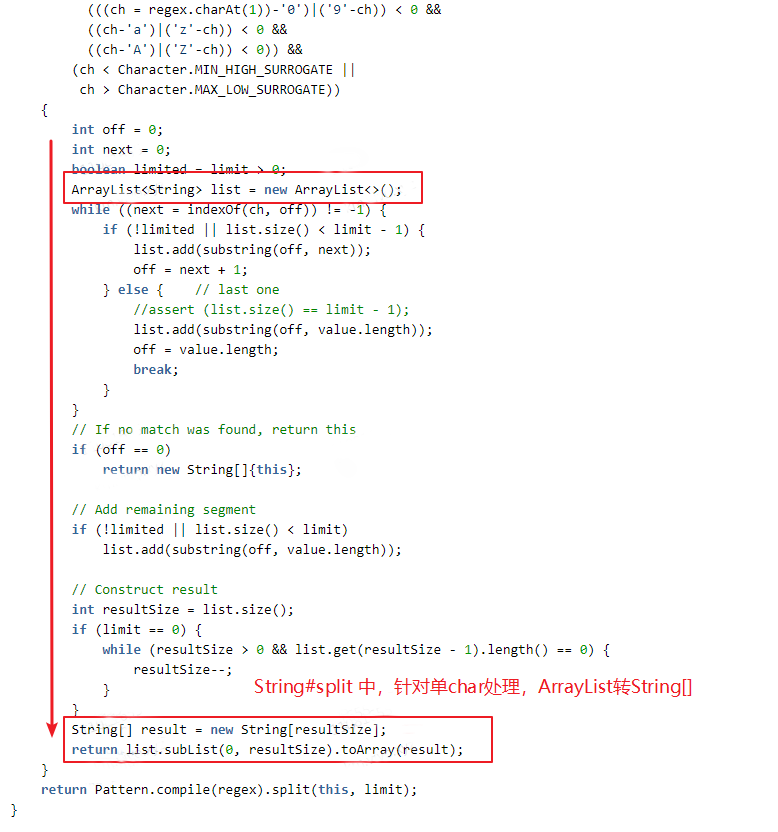
(3)业务中调用 split 最频繁的地方,其实只需要 split 后的第 1 个结果;原生 split 方法或其它工具类有重载优化方法,可以指定 limit 参数,满足 limit 数量后可以提前返回;但业务代码中,使用 str.split(delim)[0] 方式,非性能最佳。
针对业务场景,我们自定义实现了性能优化版的 split 实现。
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
/**
* 自定义split工具
*/
public class SplitUtils {
/**
* 自定义分割函数,返回第一个
*
* @param str 待分割的字符串
* @param delim 分隔符
* @return 分割后的第一个字符串
*/
public static String splitFirst(final String str, final String delim) {
if (null == str || StringUtils.isEmpty(delim)) {
return str;
}
int index = str.indexOf(delim);
if (index < 0) {
return str;
}
if (index == 0) {
// 一开始就是分隔符,返回空串
return "";
}
return str.substring(0, index);
}
/**
* 自定义分割函数,返回全部
*
* @param str 待分割的字符串
* @param delim 分隔符
* @return 分割后的返回结果
*/
public static List<String> split(String str, final String delim) {
if (null == str) {
return new ArrayList<>(0);
}
if (StringUtils.isEmpty(delim)) {
List<String> result = new ArrayList<>(1);
result.add(str);
return result;
}
final List<String> stringList = new ArrayList<>();
while (true) {
int index = str.indexOf(delim);
if (index < 0) {
stringList.add(str);
break;
}
stringList.add(str.substring(0, index));
str = str.substring(index + delim.length());
}
return stringList;
}
}
相比原生 String.split ,主要有几方面的改动:
放弃正则表达式的支持,仅支持按分隔符进行 split;
出参直接返回 list。分割处理实现,与原生实现中针对单字符的处理类似,使用 string.indexOf 及 string.substring 方法,分割结果放入 list 中,出参直接返回 list,减少数据转换处理;
提供 splitFirst 方法,业务场景只需要分隔符前第一段字符串时,进一步提升性能。
如何验证我们的优化效果呢?首先选用 jmh 作为微基准测试工具,对照选用 原生 String.split 以及 apache 的 StringUtils.split方法,测试结果如下:
选用单字符作为分隔符
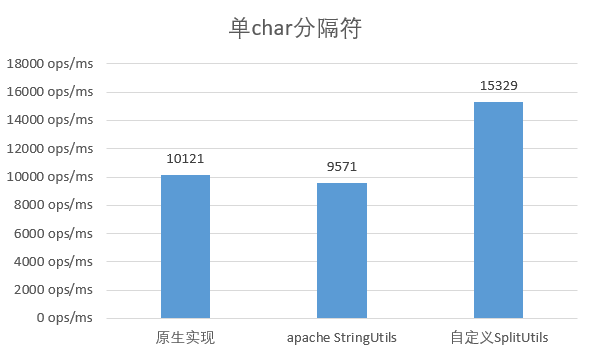
可以看出,原生实现与apache的工具类性能差不多,而自定义实现性能提升了约 50%。
选用多字符作为分隔符
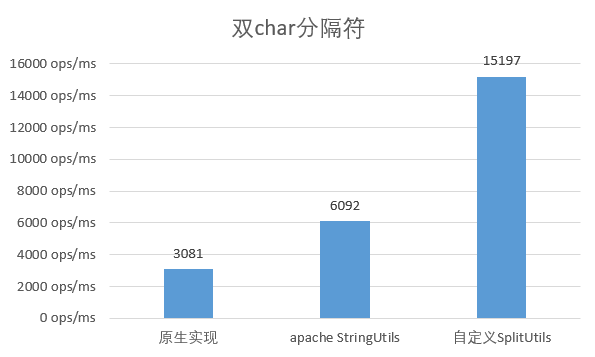
当分隔符使用 2 个长度的字符时,原始实现的性能大幅降低,只有单 char 时的 1/3 ;而apache的实现也降低至原来的 2/3 ,而自定义实现与原来基本保持一致。
选用单字符作为分隔符,只需返回第 1 个分割结果
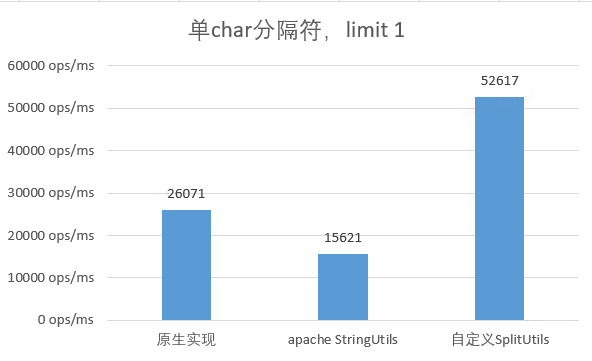
选用单字符作为分隔符,并只需第 1 个分割结果时,自定义实现的性能是原生实现的 2 倍,并是取原生实现完整结果的 5 倍。
经微基准测试验证收益后,我们将优化部署到在线服务中,验证端到端整体的性能收益;
重新使用arthas采集火焰图,split 方法耗时降低至 2% 左右;端到端整体耗时下降了 31.77% ,吞吐量上涨了 45.24% ,性能收益特别明显。
从火焰图中,我们发现 HashMap.getOrDefault 方法耗时占比也特别多,达到了 20%,主要在查询权重 map 上,这是因为:
业务中确实需高频调用,特征交叉处理后数量膨胀,单机的调用并发达到了约 1000w ops/s。
权重 map 本身也很大,存储了 1000 万多的 entry,占用了很大一块内存;同时 hash 碰撞的概率也增大,碰撞时的查询效率由 O(1) 降低成了 O(n) (链表) 或 O(logn) (红黑树)。
Hashmap 本身是非常高效的 map 实现,起初我们尝试了调整加载因子 loadFactor 或 换用其它 map 实现,均未取得明显收益。
如何才能提升 get 方法的性能呢?
分析过程中我们发现查询 map 的 key(交叉处理后的特征 key )是字符串型,且平均长度在 20 以上;我们知道 string 的 equals 方法其实是遍历比对 char[] 中的字符,key 越长则比对效率越低。
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
是否可以将 key 的长度缩短,或者甚至换成数值型?通过简单的微基准测试,我们发现思路应该是可行的。
于是与算法同学沟通,巧的是算法同学正好也有相同诉求,他们在切换新训练框架过程中发现 string 的效率特别低,需要把特征换成数值型。
一拍即合,方案很快确定:
算法同学将特征 key 映射成 long 型数值,映射方法为自定义的 hash 实现,尽量减少 hash 碰撞概率;
算法同学训练输出新模型的权重 map ,可以保留更多 entry ,以打平基线模型的效果指标;
打平基线模型的效果指标后,在线服务端灰度新模型,权重 map 的 key 改用 long 型,验证性能指标。
在增加了 30% 的特征 entry 数下(模型效果超过基线),工程上的性能也达到了明显收益;
端到端整体耗时下降了 20.67%,吞吐量上涨了 26.09%;此外内存使用上也取得了良好收益,权重map的内存大小下降了30%。
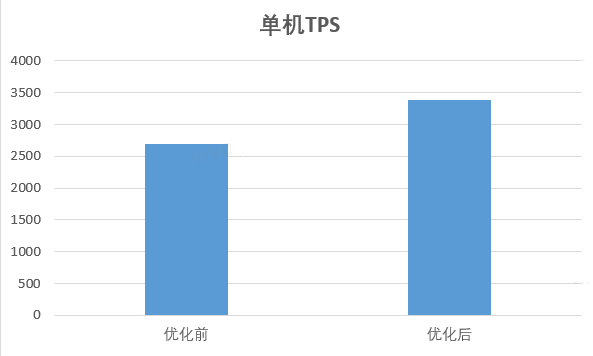
Java 设计垃圾自动回收的目的是将应用程序开发人员从手动动态内存管理中解放出来。开发人员无需关心内存的分配与回收,也不用关注分配的动态内存的生存期。这完全消除了一些与内存管理相关的错误,代价是增加了一些运行时开销。
在小型系统上开发时,GC 的性能开销可以忽略,但扩展到大型系统(尤其是那些具有大量数据、许多线程和高事务率的应用程序)时,GC 的开销不可忽视,甚至可能成为重要的性能瓶颈。
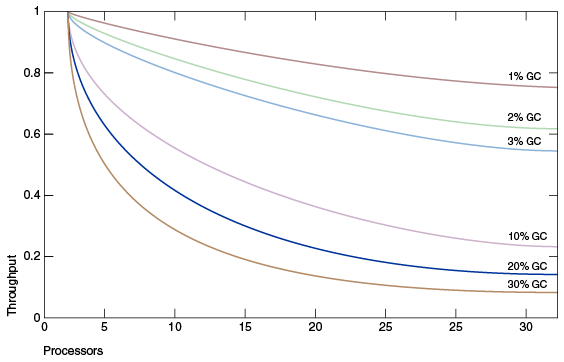
上图 模拟了一个理想的系统,除了垃圾收集之外,它是完全可伸缩的。红线表示在单处理器系统上只花费 1% 时间进行垃圾收集的应用程序。这意味着在拥有 32 个处理器的系统上,吞吐量损失超过 20% 。洋红色线显示,对于垃圾收集时间为 10% 的应用程序(在单处理器应用程序中,垃圾收集时间不算太长),当扩展到 32 个处理器时,会损失 75% 以上的吞吐量。
故 JVM GC 也是很重要的性能优化措施。
我们的推荐服务使用高配计算资源(64核256G),GC的影响因素挺可观;通过采集监控在线服务 GC 数据,发现我们的服务 GC 情况挺糟糕的,每分钟YGC累计耗时约 10s。
GC 开销为何这么大,如何降低 GC 的耗时呢?
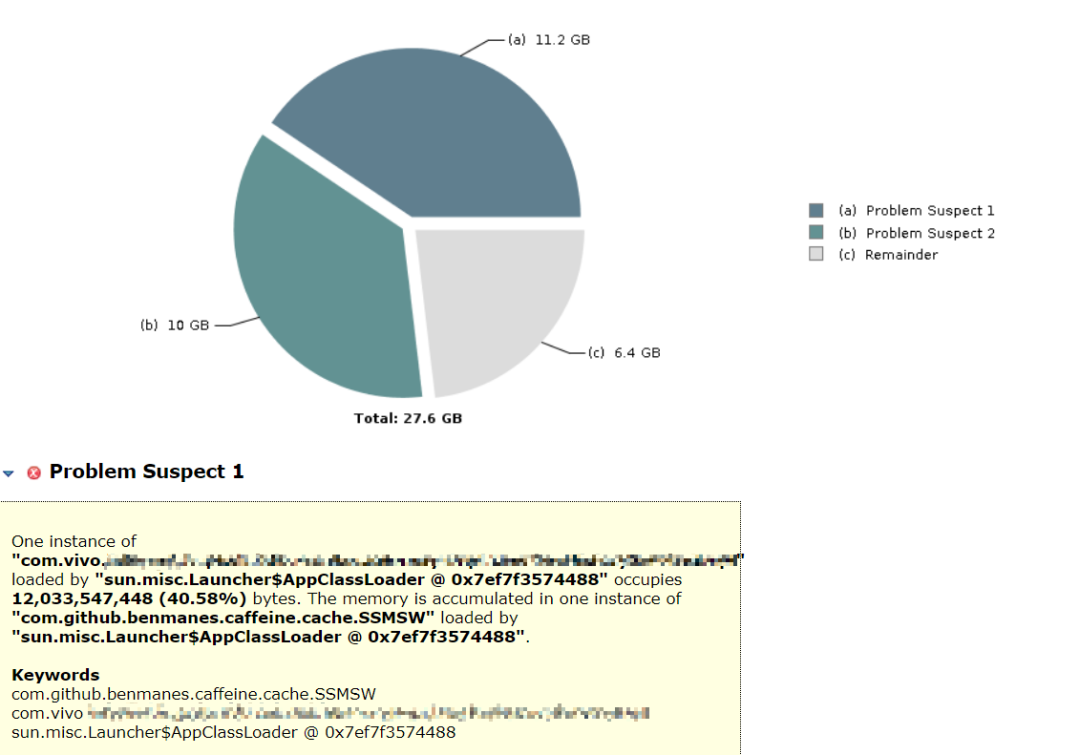
我们 dump 了服务的存活堆对象,使用 mat 工具进行内存分析,发现有 2 个对象特别巨大,占了总存活堆内存的 76.8%。其中:
第 1 大对象是本地缓存,存储了细粒度级别的常用数据,每台机器千万级别数据量;使用 caffine 缓存组件,缓存自动刷新周期设定 1 小时;目的是尽量减少 IO 查询次数;
第 2 大对象是模型权重 map 本身,常驻内存中,不会 update,等新模型载入后被作为旧模型进行卸载。
如何能尽量缓存较多的数据,同时避免过大的 GC 压力呢?
我们想到了把缓存对象移到堆外,这样可以不受堆内内存大小的限制;并且堆外内存,并不受 JVM GC 的管控,避免了缓存过大对 GC 的影响。经过调研,我们决定采用成熟的开源堆外缓存组件 OHC 。
(1)OHC 介绍
简介
OHC 全称为 off-heap-cache,即堆外缓存,是 2015 年针对 Apache Cassandra 开发的缓存框架,后来从 Cassandra 项目中独立出来,成为单独的类库,其项目地址为https://github.com/snazy/ohc 。
特性
数据存储在堆外,只有少量元数据存储堆内,不影响 GC
支持为每个缓存项设置过期时间
支持配置 LRU、W_TinyLFU 驱逐策略
能够维护大量的缓存条目
支持异步加载缓存
读写速度在微秒级别
(2)OHC 用法
快速开始:
OHCache ohCache = OHCacheBuilder.newBuilder().
keySerializer(yourKeySerializer)
.valueSerializer(yourValueSerializer)
.build();可选配置项:
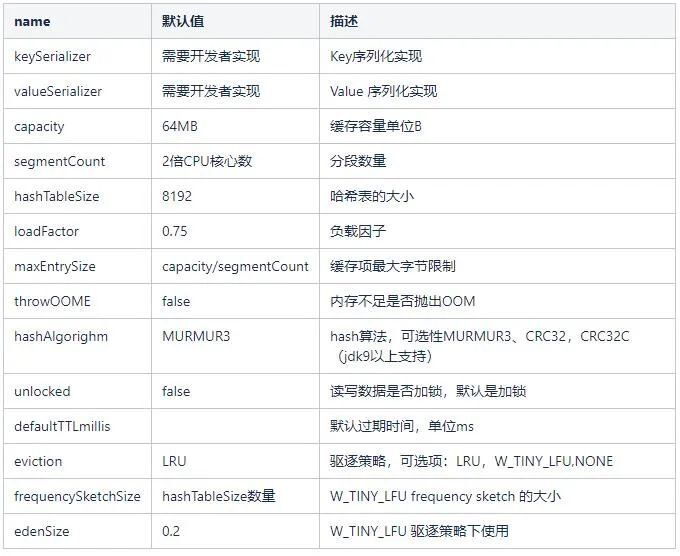
在我们的服务中,设置 capacity 容量 12G,segmentCount 分段数 1024,序列化协议使用 kryo。
切换到堆外缓存后,服务 YGC 降低到了 800ms / 每分钟,端到端的整体吞吐量上涨了约 20%。
在Java GC优化中,我们把本地缓存对象从Java堆内移到了堆外,取得了不错的性能收益。 还记得上文提到的另一个巨型对象, 模型权重 map 吗 ?模型权重 map 能否也从 Java 堆内移除?
答案是可以的。我们使用C++改写了模型推理计算部分,包括权重map的存储与检索、排序得分计算等逻辑;然后将C++代码输出为 so 库文件,Java程序通过 native 方式调用,实现将权重map从 Jvm 堆内移出,获得了很好的性能收益。
通过上文介绍的 3 个措施,我们从 热点代码优化 与 Jvm GC两方面改善了服务负载与性能,整体吞吐量翻了 1 倍,达到了阶段性的预期目标。
不过性能调优是永无止境的,而且每个业务场景、每个系统的实际情况也都是千差万别,很难用1篇文章去涵盖介绍所有的优化场景。希望本文介绍的一些调优实战经验,比如如何确定优化方向、如何着手分析以及如何验证收益,能给大家一些借鉴和参考。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我