《图解HTTP》阅读总结(上)
文章目录
如同译者所说,讲HTTP协议的书籍确实很少:
在我的印象中,讲解网络协议的书仅有两本。一本是《HTTP 权威指南》,但其厚度令人望而生畏;另一本是《TCP/IP 详解,卷 1》,内容艰涩难懂,学习难度较大。
确实如此,《HTTP 权威指南》我也看过一小部分,真是从入门到放弃,不是书写的不好,真的很棒,也很细致。但对于我来说太枯燥了。
这本《图解HTTP》,本书图文并茂,大量图片穿插文中,生动形象地向读者介绍每一个应用案例,减少了读者阅读时的枯燥感。哈哈,很适合我,我的文章也非常喜欢用“图解XXX”的方式,但真心没有这本书用图用的这么彻底。
虽然是一本2014年的“老书”,但其实很多知识还是沿用至今的,HTTP版本为1.1,推荐阅读一下。
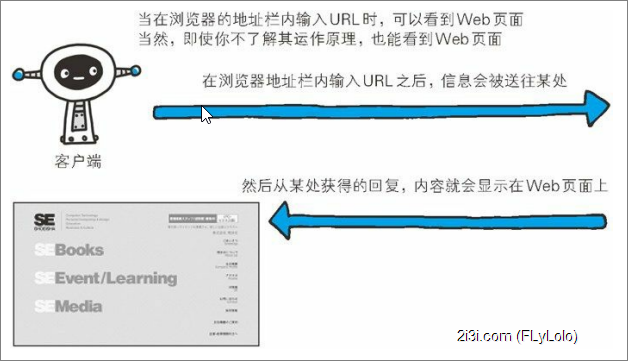
当你通过浏览器查看网页的时候实际发生了什么?通过一幅图、一个问题开篇。
1990年,HTTP/0.9
1996 年的 5 月,HTTP/1.0
1997 年 1 月,HTTP/1.1
本书在2014年出版,书中写到“新 一代 HTTP/2.0 正在制订中,但要达到较高的使用覆盖率,仍需假以时日。”
实际上2015年,HTTP/2 发布,但真如作者所说,2.0普及真是**“没那么快”**。
TCP/IP 是互联网相关的各类协议族的总称, 包含了好多协议
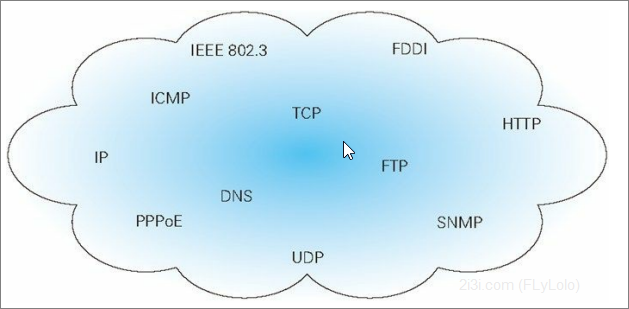
可见,HTTP是TCP/IP协议中的一个
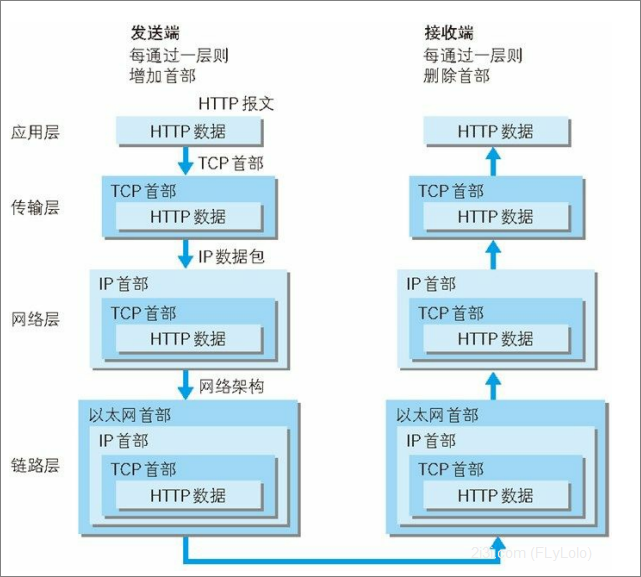
TCP/IP 协议族各层的作用如下:
应用层
应用层决定了向用户提供应用服务时通信的活动。 TCP/IP 协议族内预存了各类通用的应用服务。比如,FTP(File Transfer Protocol,文件传输协议)和 DNS(Domain Name System,域 名系统)服务就是其中两类。 HTTP 协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据 传输。 在传输层有两个性质不同的协议:TCP(Transmission Control Protocol,传输控制协议)和 UDP(User Data Protocol,用户数据报 协议)。
网络层(又名网络互连层)
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数 据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计 算机,并把数据包传送给对方。 与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所 起的作用就是在众多的选项内选择一条传输路线。
链路层(又名数据链路层,网络接口层)
用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱 动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等 物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在 链路层的作用范围之内。

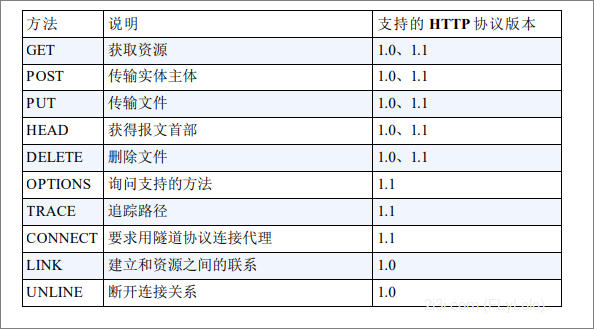
一个图表示一个简单的HTTP请求:
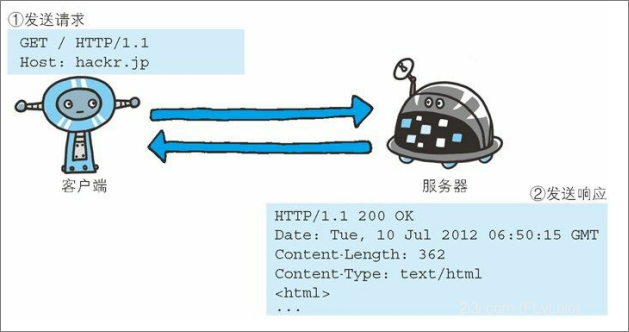
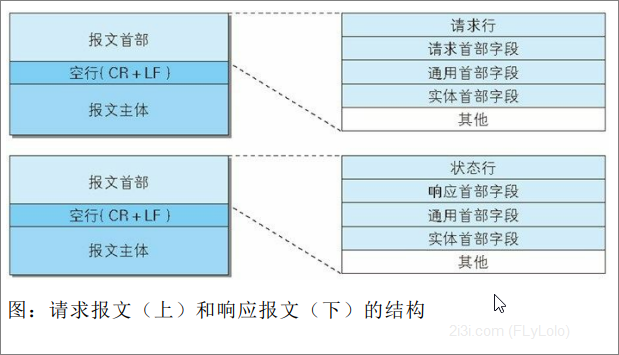
实际上,一个请求报文的组成如下:
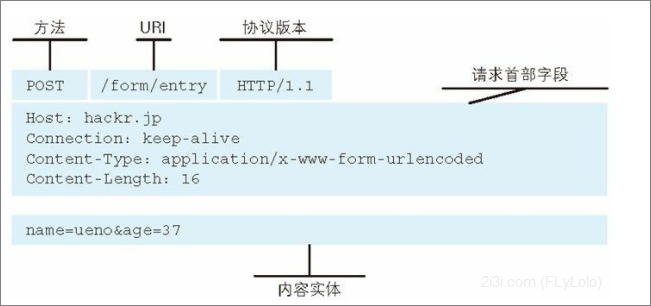
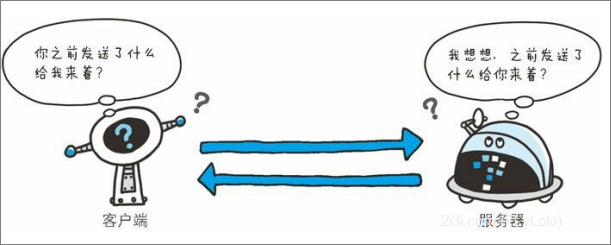
HTTP 是一种不保存状态,即无状态(stateless)协议。HTTP 协议自 身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个 级别,协议对于发送过的请求或响应都不做持久化处理。
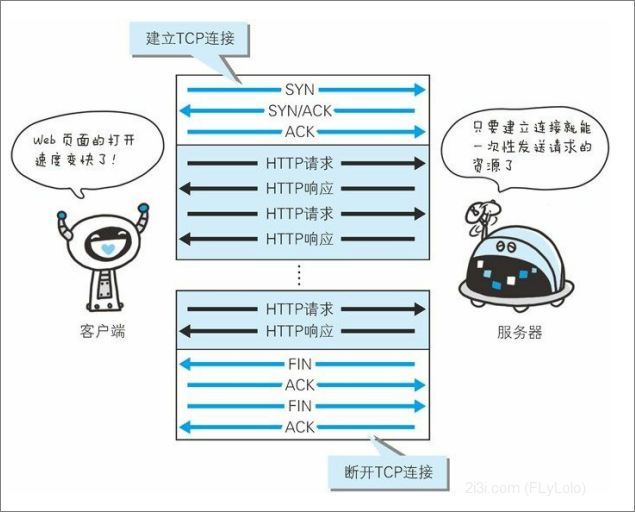
HTTP 协议的初始版本中,每进行一次 HTTP 通信就要断开一次 TCP 连接。每次的请求都会造成无谓的 TCP 连接建立和断 开,增加通信量的开销。
为解决上述 TCP 连接的问题,HTTP/1.1 和一部分的 HTTP/1.0 想出了 持久连接(HTTP Persistent Connections,也称为 HTTP keep-alive 或 HTTP connection reuse)的方法。持久连接的特点是,只要任意一端 没有明确提出断开连接,则保持 TCP 连接状态。
持久连接使得多数请求以管线化(pipelining)方式发送成为可能。从 前发送请求后需等待并收到响应,才能发送下一个请求。管线化技术 出现后,不用等待响应亦可直接发送下一个请求。
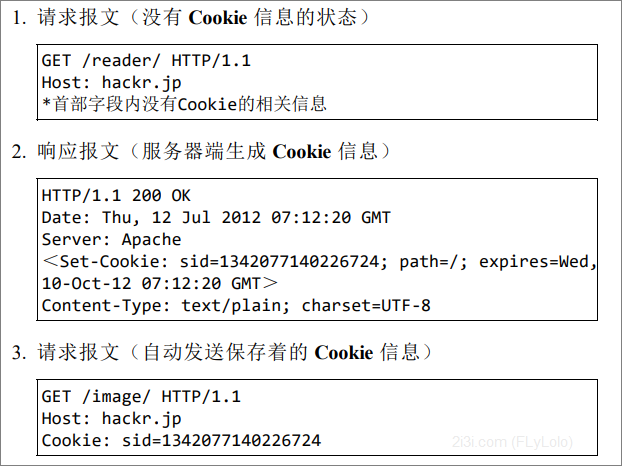
保留无状态协议这个特征的同时又要解决类似的矛盾问题,于是引入 了 Cookie 技术。Cookie 技术通过在请求和响应报文中写入 Cookie 信 息来控制客户端的状态。 Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的 首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器 发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出 去。 服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一 个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前 的状态信息。
**压缩数据方式:**HTTP 在传输数据时可以按照数据原貌直接传输,但也可以在传输过 程中通过编码提升传输速率。通过在传输时编码,能有效地处理大量 的访问请求。但是,编码的操作需要计算机来完成,因此会消耗更多 的 CPU 等资源。
常用的内容编码有以下几种。
gzip(GNU zip)
compress(UNIX 系统的标准压缩)
deflate(zlib)
identity(不进行编码)
**分割发送方式:**在 HTTP 通信过程中,请求的编码实体资源尚未全部传输完成之前, 浏览器无法显示请求页面。在传输大容量数据时,通过把数据分割成 多块,能够让浏览器逐步显示页面。
HTTP/1.1 中存在一种称为传输编码(Transfer Coding)的机制,它可 以在通信时按某种编码方式传输,但只定义作用于分块传输编码中。
内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然 后提供给客户端最为适合的资源。内容协商会以响应资源的语言、字 符集、编码方式等作为判断的基准。
包含在请求报文中的某些首部字段(如下)就是判断的基准。这些首 部字段的详细说明请参考下一章。
Accept
Accept-Charset
Accept-Encoding
Accept-Language
Content-Language
内容协商技术有以下 3 种类型。
服务器驱动协商(Server-driven Negotiation)
由服务器端进行内容协商。以请求的首部字段为参考,在服务器端自动处理。但对用户来说,以浏览器发送的信息作为判定的依据,并不 一定能筛选出最优内容。
客户端驱动协商(Agent-driven Negotiation)
由客户端进行内容协商的方式。用户从浏览器显示的可选项列表中手 动选择。还可以利用 JavaScript 脚本在 Web 页面上自动进行上述选 择。比如按 OS 的类型或浏览器类型,自行切换成 PC 版页面或手机 版页面。
透明协商(Transparent Negotiation)
是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进 行内容协商的一种方法。
HTTP 状态码负责表示客户端 HTTP 请求的返回结果、标记服务器端 的处理是否正常、通知出现的错误等工作。
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结 果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出 现了错误。
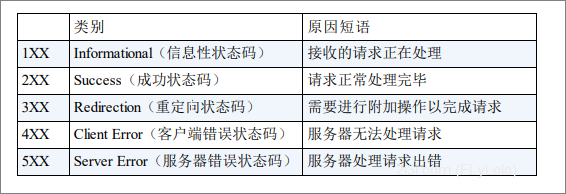
400 Bad Request 该状态码表示请求报文中存在语法错误。
401 Unauthorized 该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、 DIGEST 认证)的认证信息。
403 Forbidden 该状态码表明对请求资源的访问被服务器拒绝了。
404 Not Found 该状态码表明服务器上无法找到请求的资源。
通过阅读前四章,将以前关于HTTP的散碎知识串起来了,虽然大部分知识之前都知道,但感觉通过系统学习一下,了解的更清晰了,知识需要形成体系。下一篇争取下周发出。
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)