文章目录
hadoop的启动模式有三种,一个是本地模式,一个是伪分布式模式,还有一个是集群模式。为了学习hadoop,这里需要搭建一个完全分布式的集群。希望你先把准备工作给看一下,因为我们的配置都是前后一致的。本文因为想让大家学习一下集群分发脚本,所以在模板虚拟机里面少放了很多东西,以后会写一个快速搭建集群的教程。
首先我们需要多台虚拟机,需要做的工作请看下面这篇博文。
配置hadoop模板虚拟机
找到我们上面配置好的模板虚拟机,打开它,然后右键——》管理——》克隆
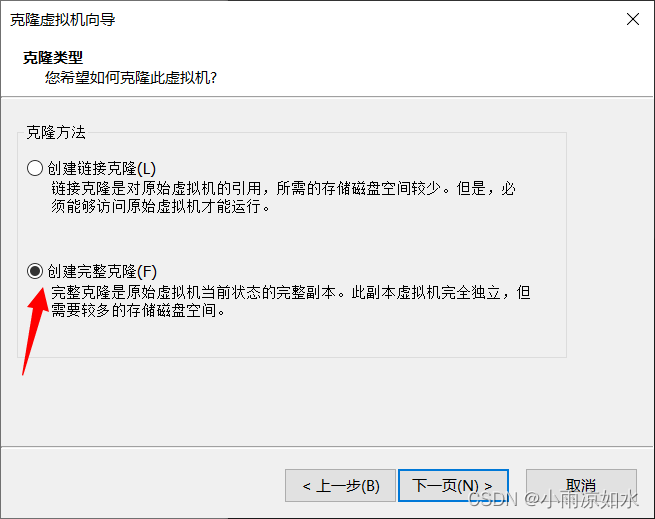
在引导的时候,我只说两件事
第一,要选择创建完整克隆
第二,在命名的时候,建议命名成hadoop102,hadoop103,hadoop104
原因有两点:一般hadoop101是用来做伪分布式安装的
第二点,我们的hosts已经修改成了hadoop101~hadoop108
所以,我建议三台虚拟机命名成hadoop102,hadoop103,hadoop104
让我们开机hadoop102,hadoop103,hadoop104
以管理员的身份登录
首先要强调一点,我们的配置都是前后一致的,一一对应的。
hadoop102 对应的ip地址末尾是102 hostname也是hadoop102
hadoop103 对应的ip地址末尾是103 hostname也是hadoop103
hadoop104 对应的ip地址末尾是104 hostname也是hadoop104
看明白了吗?这些在准备工作里面都配置过,下面的修改也不过是进行了一致性修改。
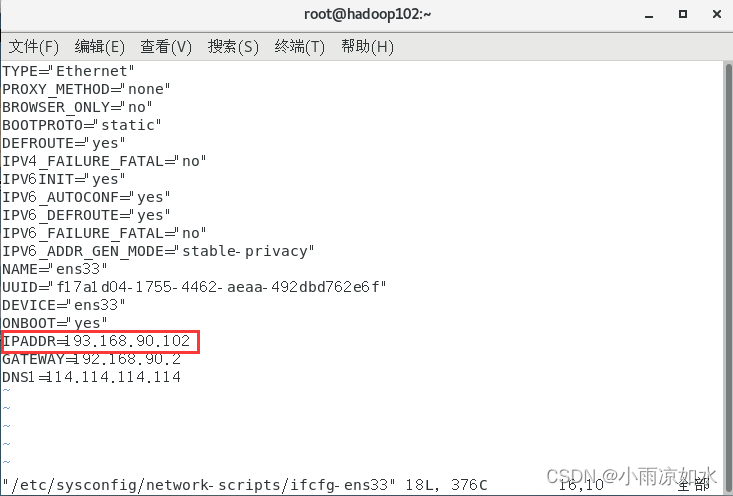
首先,修改ip地址
输入下面的命令
vim /etc/sysconfig/network-scripts/ifcfg-ens33
把 ip地址与名字对应(hadoop102的ip末尾修改成102就行,hadoop103同理)保存退出就行了,毕竟之前我们已经配置了模板虚拟机。
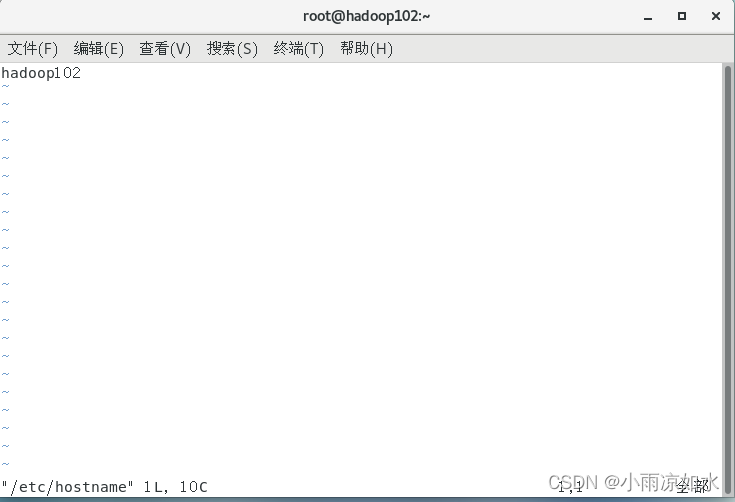
修改hostname
vim /etc/hostname
hadoop102的hostname修改成hadoop102
hadoop103同理
保存退出。输入“ :wq”
让我们
ping www.baidu.com
打开我们的xshell,
连接这三台虚拟机。(这里不再演示了)
注:这里在hadoop102安装就行了
(这里主要是为了学习一下分发脚本,不然直接在模板机直接把这些配置好岂不是妙哉?)
在下一大点,我们用了一个分发脚本。
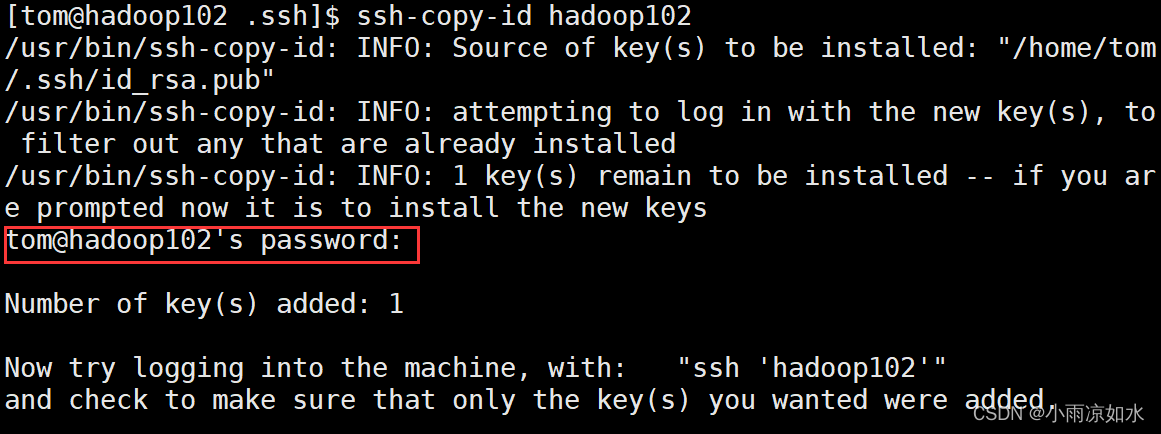
在使用分发脚本传输文件时,必不可少的一项流程是登录到目标机器,也就是要输入密码(可以先试一试第五点的集群分发脚本来体会为什么要设置ssh免密登录),
并且每次传文件都要输密码,所以配置了ssh免密登录,集群之间的机器再传输文件就不需要密码了。
本节使用的是手动配置ssh免密登录(学习一下,知道ssh免密登录怎么配置),
后续可以使用shell脚本来快速配置集群的免密登录
(假设你有n台机器,你要配置n*n次的免密登录,非常的麻烦)
首先,来到hadoop102,使用tom登录(ssh免密登录是分用户的,假设你使用了root管理员来进行免密登录配置,那你只能使用root来免密登录其他的已经配置过免密登录的机器,而本机器上的其他用户是无法进行免密登录的,登录到其他机器还是要输入密码的)
在tom的家目录(/home/tom)输入ls -lah,你会看到.ssh

如果你没有这个.ssh,也没有关系,可以输入
ssh localhost
然后输入密码就行了,再输入上面的命令,你就会看到这个.ssh的目录了。
进入.ssh目录
输入
ssh-keygen -t rsa
然后回车三次,生成了公钥和私钥
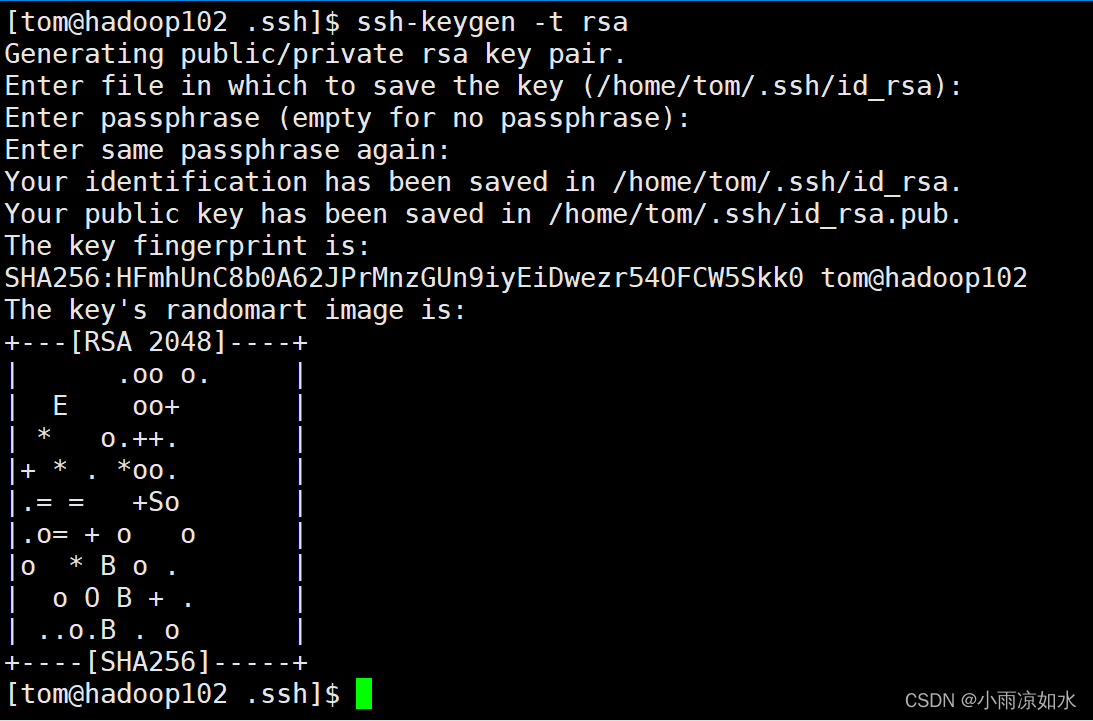
id_rsa 是私钥,id_rsa.pub是公钥

依次输入(每次输入的命令需要对应机器的密码)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
上面的做完了,开始验证是否配置成功
现在我们在hadoop102这台机器上面,我们输入
ssh hadoop102
看看需不需要输密码,如果不需要输密码,就说明我们已经配置成功了

我们还是使用tom登录hadoop102
我们已经在模板虚拟机的时候就已经安装了rsync(因为每个模板虚拟机都需要这个)
如果你的虚拟机没有rsync
sudo yum install rsync
请在用户的家目录下创建一个bin目录,然后输入
vim xsync
下面就是集群分发脚本
(记得先输入 i 进入编辑的模式再复制粘贴脚本代码)
#!/bin/bash
# 1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
# 2.遍历机器所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ================== $host ===============
# 3.遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
# 5.获取父目录
pdir=$(cd -P $(dirname $file);pwd)
# 6.获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本权限
chmod 777 xsync
xsync的执行方式就是
xsync 跟上文件或目录的路径就行了
首先
cd ..
让我随便的创建一个文件
touch a.txt
然后
xsync a.txt
说明,这个时候大概率可能是不能用的,我试了好几次。
我们需要把这个脚本文件移动到一个全部变量的目录里面
sudo cp /home/tom/bin/xsynv /bin
我们在/home/tom 的目录下创建了一个 a.txt 文件,现在试一试能不能使用这个东西
cd /home/tom
xsync a.txt
然后登录root账户
su root
mkdir aaa
xsync aaa
如果能执行,就说明我们的分发脚本配置成功了。
我们要按照这张图来配置集群

注意 NameNode 和 SecondaryNameNode 不要安装在同一台服务器上
ReourceManager 也很消耗内存,不要和NameNode,secondaryNameNode 配置在同一台机器上。
那么应该怎么配置呢?
需要修改相应的配置文件
所有需要修改的文件都在$HADOOP_HOME/etc/hadoop里面
**注意!!!**如果用tom不能修改,大概率是因为你使用的是root来创建了目录,使用了root来解压文件等原因,执行下面的代码修改
sudo chown -R tom:tom /opt
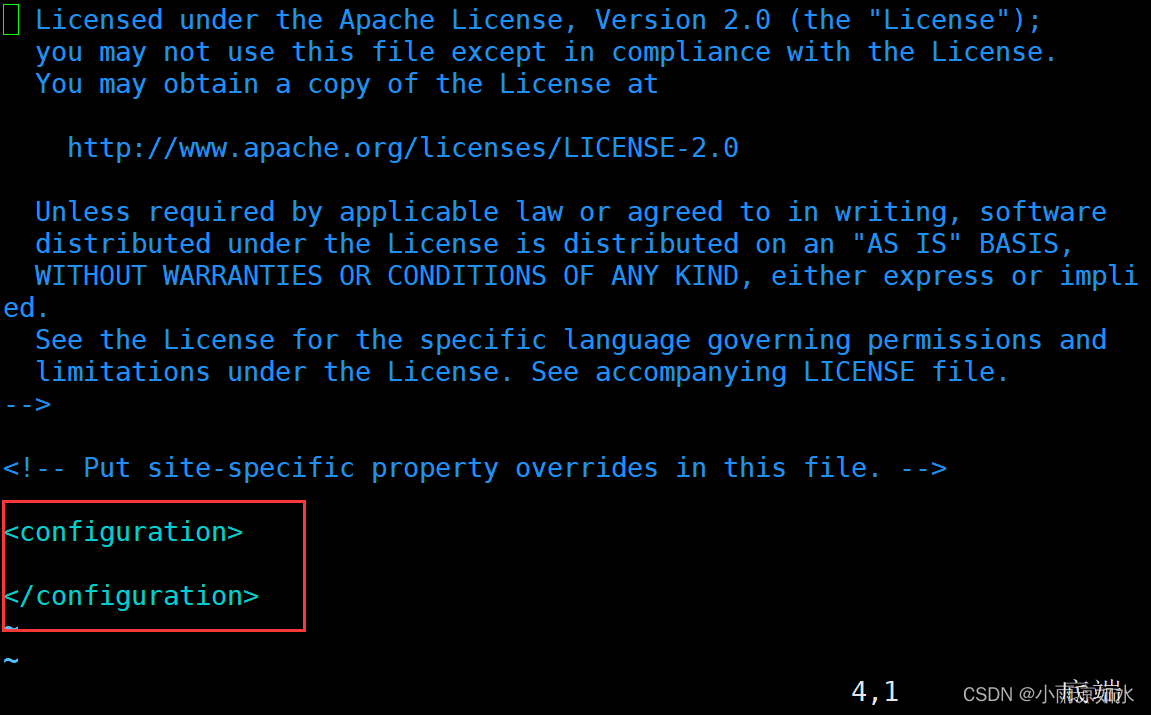
首先修改hadoop102的core-site.xml
下面是需要修改的内容(不要复制粘贴错位置了,xml不再多说了,学过html就很容易懂这种格式)
<configuration>
<!--指定NameNode 的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.4/data</value>
</property>
</configuration>
这个是修改的位置
其次修改hadoop102的hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!--2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
然后修改hadoop102的yarn-site.xml
<configuration>
<!--指定mapreduce走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.nodemanager.env-whitelsit</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
再次修改hadoop102的mapred-site.xml
<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
最后修改workers(2.x版本叫slaves)

修改hadoop-env.sh
这里主要是添加一下java_home
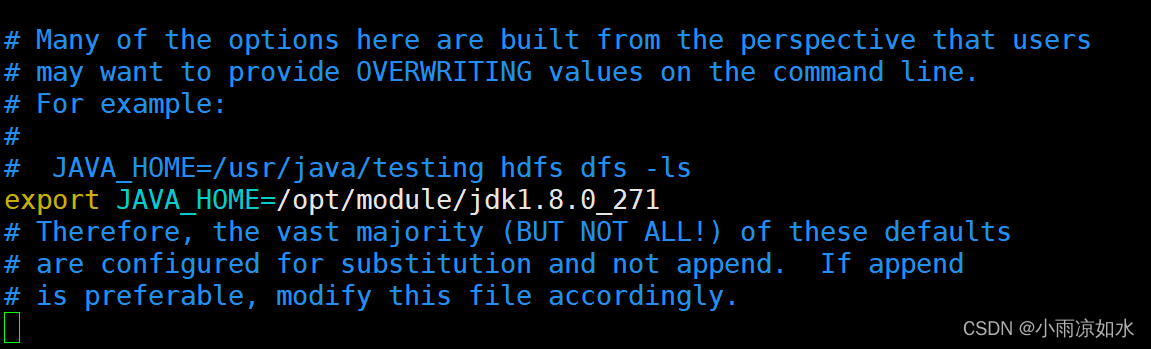
在$HADOOP_HOME/etc/ 目录下执行下面的代码
xsync hadoop/
经过了重重的配置,我们终于要来启动集群了,在启动集群之前,我们还要进行一定的配置
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意,格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往的数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化)
这个要在hadoop102上运行
hdfs namenode -format
cd /opt/module/hadoop-3.3.4/sbin
start-dfs.sh
没有error就算是启动成功了

一定注意:是在103上面
cd /opt/module/hadoop-3.3.4/sbin
start-yarn.sh

验证方式一

输入
jps
各个虚拟机的节点如果和上面对应出说明启动成功了
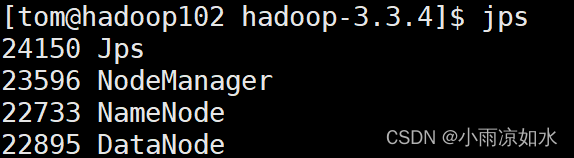
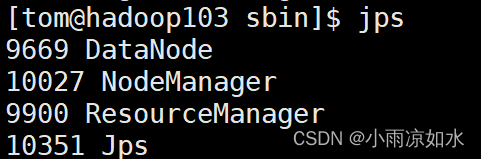
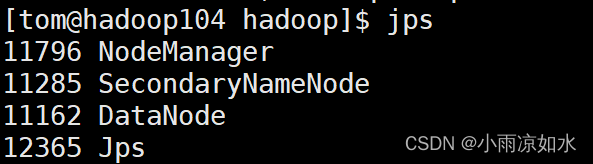
验证方式二
让我们来到浏览器
在框框的地方输入
http://hadoop102:9870
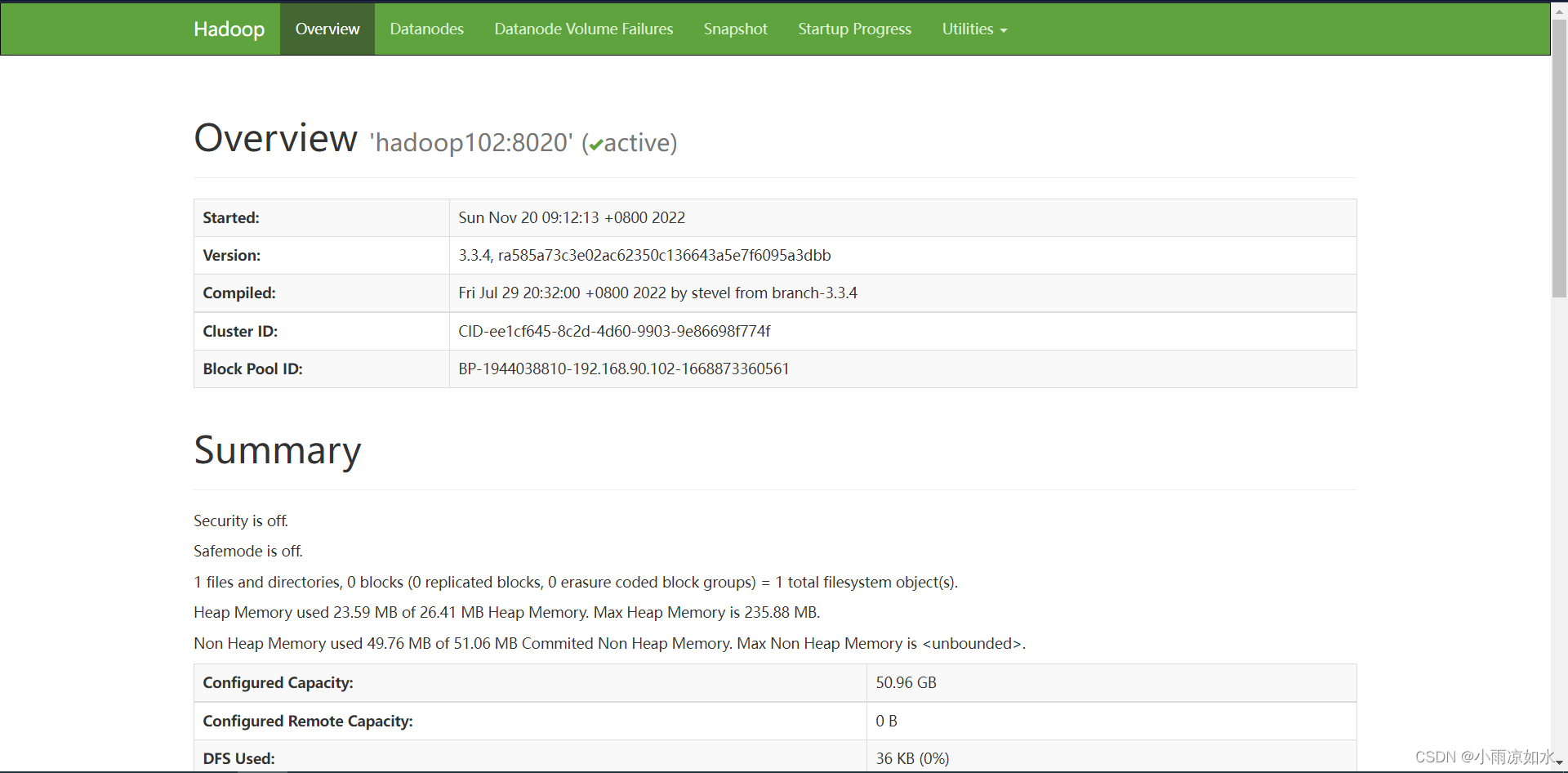
修改hadoop102的mapred-site.xml
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory-address</name>
<value>hadoop102:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
分发配置
xsync mapred-site.xml
在hadoop102启动历史服务器
启动之前,先把hadoop103上面的yarn给重启了
[tom@hadoop102 hadoop]$ mapred --daemon start historyserver
验证
jps
查看一下是否有
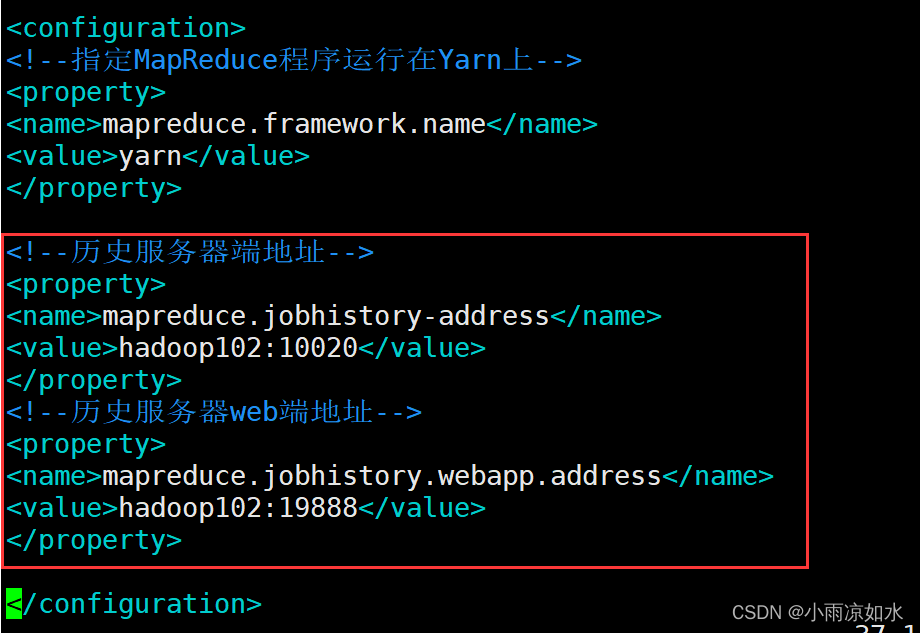
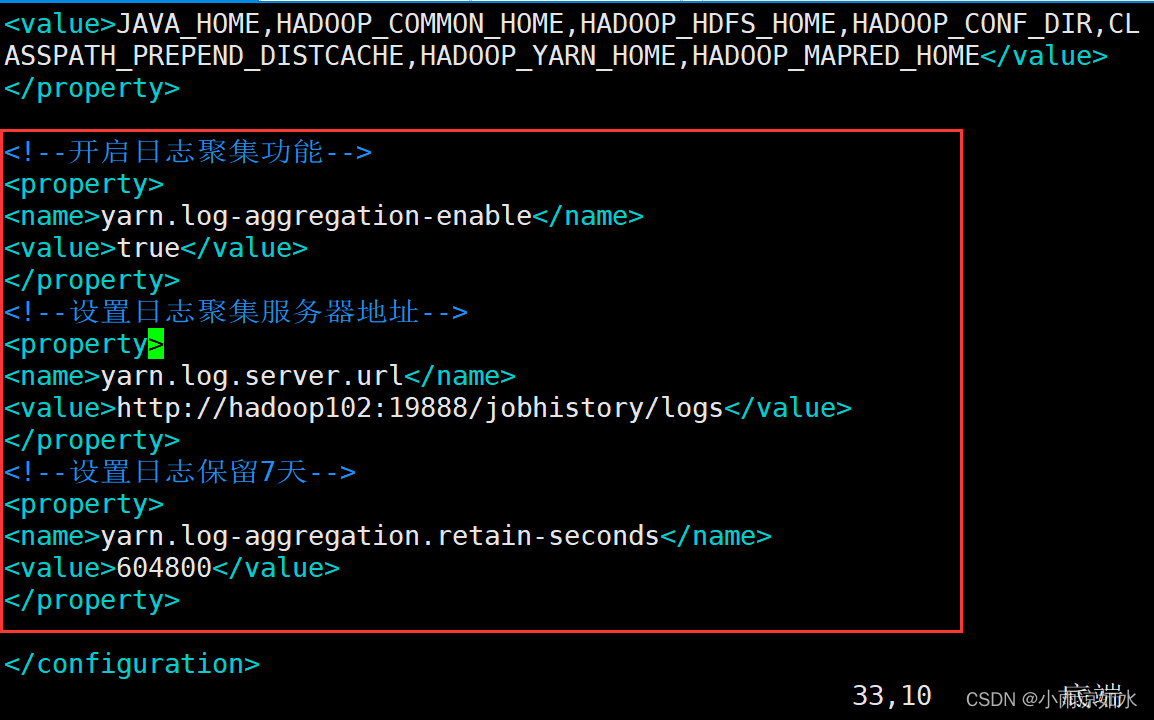
修改hadoop102下面的yarn-site.xml
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!--设置日志保留7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置
xsync yarn-site.xml
注意:开启日志聚集功能,需要重新启动NodeManager、RescourceManager和HistoryServer
在hadoop102上面
mapred --daemon stop historyserver
在hadoop103上(停止命令是在$HADOOP_HOME/sbin)
sbin/stop-yarn.sh
sbin/start-yarn.sh
然后重启历史服务器
回到hadoop102
mapred --daemon start historyserver
我们的日志聚集功能就算开启了
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
背景here.在上面的链接中,给出了以下示例:classauthor.id)endend除了这种语法对于像我这样的初学者来说很陌生——我一直认为类方法是用defself.my_class_method定义的——我在哪里可以找到关于类的文档RubyonRails中的方法?据我所知,类方法总是在类本身(MyClass.my_class_method)上调用,但如果Rails中的类方法是可链接的,似乎必须进行其他操作在这里!编辑:我想我通过对类方法的语法发表评论有点被骗了。我真的想问Rails如何使类方法可链接—我了解方法链接的工作原理,但不知道Rails如何允许您链接类方法而无需实际返
有没有办法快速将表格格式的ruby哈希打印到文件中?如:keyAkeyBkeyC...1232343451253474456...其中散列的值是不同大小的数组。还是使用双循环是唯一的方法?谢谢 最佳答案 试试我写的这个gem(在表中打印散列、ruby对象、ActiveRecord对象):http://github.com/arches/table_print 关于ruby-如何以表格格式快速打印Ruby哈希值?,我们在StackOverflow上找到一个类似的问题:
首先,关于我们系统的一些信息,它基本上是建筑行业的电子招标解决方案。所以:列表项我们的系统有多家公司每个公司都有多个用户每家公司可以创建多个拍卖然后其他公司可以为可用的拍卖提交他们的出价。一个出价包含数百或数千个单独的项目,我们只需要加密这些记录的“价格”部分。我们面临的问题是,我们的大客户不希望我们知道投标价格,至少在投标过程中是这样,这是完全可以理解的。现在,我们只是通过对称加密对价格进行加密,因此即使价格在数据库中有效加密,他们担心的是我们拥有解密价格的key。因此,我们正在研究某种形式的公钥加密系统。以下是我们对解决方案的初步想法:当一家公司注册时,我们会使用OpenSSL为其
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
电脑启动出现显示器黑屏是一个相当常见的问题。如果您遇到了这个问题,不要惊慌,因为它有很多可能的原因,可以采取一些简单的措施来解决它。在本文中,小编将介绍下面4种常见的电脑启动后显示器黑屏的原因,排查这些原因,快速解决! 演示机型:联想Ideapad700-15ISK-ISE系统版本:Windows10一、显示器问题如果出现电脑启动后显示器黑屏的情况。那么首先您需要检查一下显示器是否正常工作。您可以通过更换另一个显示器或将当前显示器连接到另一台计算机来检查显示器是否存在问题。如果问题仍然存在,那么您可以排除显示器故障的可能性。 二、显卡问题如果您的电脑配备了独立显卡,那么显卡故障也可能是导致电脑
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva