ref:《KVM实战 原理、进阶与性能调优》
目的:将客户机迁移到另一台物理机器上,增强系统的可维护性
种类:静态迁移和动态迁移
静态迁移有一段明显时间客户机中的服务不可用, 而动态迁移则没有明显的服务暂停时间。
虚拟化环境中的静态迁移也可以分为两种, 一种是关闭客户机后, 将其硬盘镜
像复制到另一台宿主机上然后恢复启动起来, 这种迁移不能保留客户机中运行的工作负 载; 另一种是两台宿主机共享存储系统, 只需在暂停(而不是完全关闭) 客户机后, 复制 其内存镜像到另一台宿主机中恢复启动即可, 这种迁移可以保持客户机迁移前的内存状态和系统运行的工作负载。
动态迁移是指在保证客户机上应用服务正常运行的同时, 让客户机在不同的宿主机之间进行迁移, 有硬盘存储和内存都复制的动态迁移, 也有仅复制内存镜像的动态迁移。
ps:工作负载:在集群上的运行程序 【后续用到再进行补充】
workloads分为pod与controllers
pod通过控制器实现应用的运行,如何伸缩,升级等
controllers 在集群中管理pod
pod与控制器之间通过label-selector相关联,是唯一的关联方式
静态迁移的应用场景:对服务可用性要求不高的场景
动态迁移的应用场景:
KVM迁移的原理
静态迁移:
动态迁移:
-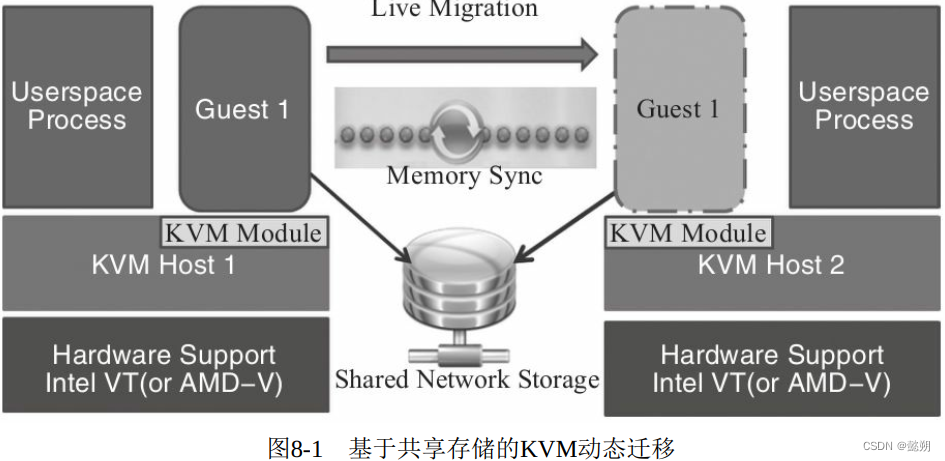
动态迁移的一些注意事项:
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在创建一个新的Rails3.1应用程序。我希望这个新应用程序重用现有数据库(由以前的Rails2应用程序创建)。我创建了新的应用程序定义模型,它重用了数据库中的一些现有数据。在开发和测试阶段,一切正常,因为它在干净的表数据库上运行,但是当尝试部署到生产环境时,我收到如下消息:PGError:ERROR:column"email"ofrelation"users"alreadyexists***[err::localhost]:ALTERTABLE"users"ADDCOLUMN"email"charactervarying(255)DEFAULT''NOTNULL但是我在迁移中有这
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom
我是Rails的新手,我是从Django背景开始接触它的。我已经接受了这样一个事实,即模型和数据库模式在Rails和在线Django中是分开的。但是,我仍在努力处理迁移。我的问题很简单-如何使用迁移向模型添加关系?例如,我现在有Artist和Song作为ActiveRecord::Base子类的空模型,没有任何关系。我需要开始做这件事:classArtist但是我如何使用railsgmigrate更改架构以反射(reflect)这一点?我正在使用Rails3.1.3。 最佳答案 现在,在Rails4中,您可以:classAddPro
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
我的生产Rails应用程序需要167秒来运行rakedb:migrate。可悲的是,没有要运行的迁移。我试图在检查是否有待处理的迁移时调整运行的迁移,但随后检查花费了同样长的时间。我心目中唯一的“借口”是数据库并不小,那里有1M条记录,但我看不出这有什么关系。我查看了日志,但没有任何迹象表明出了什么问题。我在运行ruby2.2.0rails4.2.0有没有人知道为什么会这样,是否有什么办法可以解决? 最佳答案 运行rakedb:migrate任务还会调用db:schema:dump任务,这将更新您的db/schema.rb。因此,即
我这个模型:classBunny每当我提交一个表单来创建这个模型时,我都会收到以下错误:#的未定义方法“number_before_type_cast” 最佳答案 我通过将此方法添加到我的Bunny模型中解决了这个问题:defnumber_before_type_castnumberend我不喜欢它,但我想在有人发布更好的解决方案之前它会起作用。 关于ruby-on-rails-Rails验证虚拟属性,我们在StackOverflow上找到一个类似的问题: h