问题概述
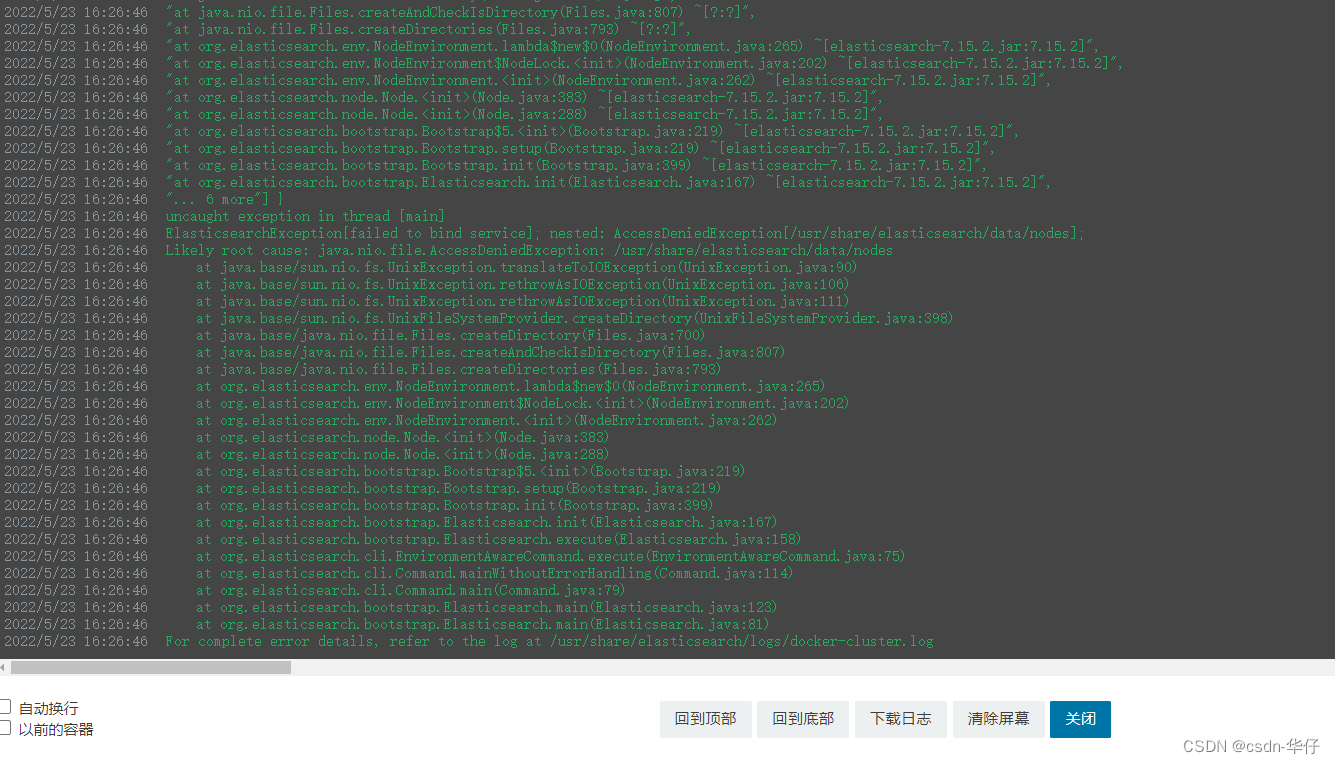
关于这个问题,博主是在通过K8s/K3s管理器构建ELK日志采集、存储、展示时遇到的一个问题,在构建Elasticsearch时,启动报错
“ Likely root cause: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes ”
拒绝访问,
如下图:
解决办法
关于这个问题有刚看到还真有点打脑阔,
根据错误内容,在容器内部倒腾了一番,还是不行,
盯着这个提示内容,穷尽了办法,后边换了个思路,“ 是不是宿主机的目录权限问题 ”
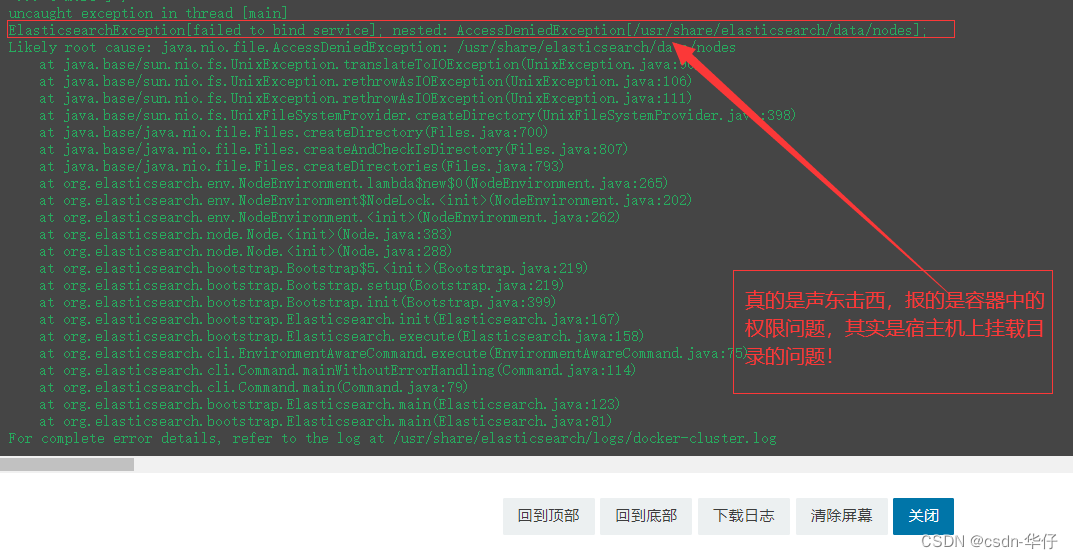
后面按照定位宿主机的目录权限来处理,果然,
解决步骤如下:
1、创建一个Elasticsearch用户,
输入指令 “ useradd elk ”
2、创建一个Elasticsearch存储的文件夹目录
输入指令 “ mkdir /home/elasticsearch ”
3、给当前目录分配以elk权限,并加入到elk分组
输入指令 “ chown elk elasticsearch/chown elk:elk elasticsearch ”
也可以根据获取的用户属性,通过用户的标识号来进行授权也是可以的,
获取用户属性,输入指令 “ cat /etc/passwd ”,如下图:

拿到用户唯一标识号,再执行指令进行授权 ,“ chown 1001 elasticsearch ”
当然,在测试环境中,注意是测试环境中,可以直接用777标识号进行授权,但是在生产环境中这种方式是不可取的,
好了,关于 Likely root cause: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes 的解决办法 就写到这儿了,如果还有什么疑问或遇到什么问题欢迎扫码提问,也可以给我留言哦,我会一一详细的解答的。
歇后语:“ 共同学习,共同进步 ”,也希望大家多多关注CSND的IT社区。
| 作 者: | 华 仔 |
| 联系作者: | who.seek.me@java98k.vip |
| 来 源: | CSDN (Chinese Software Developer Network) |
| 原 文: | https://blog.csdn.net/Hello_World_QWP/article/details/125065338 |
| 版权声明: | 本文为博主原创文章,请在转载时务必注明博文出处! |
这似乎应该有一个直截了当的答案,但在Google上花了很多时间,所以我找不到它。这可能是缺少正确关键字的情况。在我的RoR应用程序中,我有几个模型共享一种特定类型的字符串属性,该属性具有特殊验证和其他功能。我能想到的最接近的类似示例是表示URL的字符串。这会导致模型中出现大量重复(甚至单元测试中会出现更多重复),但我不确定如何让它更DRY。我能想到几个可能的方向...按照“validates_url_format_of”插件,但这只会让验证干给这个特殊的字符串它自己的模型,但这看起来很像重溶液为这个特殊的字符串创建一个ruby类,但是我如何得到ActiveRecord关联这个类模型
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
“输出”是一个序列化的OpenStruct。定义标题try(:output).try(:data).try(:title)结束什么会更好?:) 最佳答案 或者只是这样:deftitleoutput.data.titlerescuenilend 关于ruby-on-rails-更好的替代方法try(:output).try(:data).try(:name)?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我不知道为什么,但是当我设置这个设置时它无法编译设置:static_cache_control,[:public,:max_age=>300]这是我得到的syntaxerror,unexpectedtASSOC,expecting']'(SyntaxError)set:static_cache_control,[:public,:max_age=>300]^我只想将“过期”header设置为css、javaascript和图像文件。谢谢。 最佳答案 我猜您使用的是Ruby1.8.7。Sinatra文档中显示的语法似乎是在Ruby1.
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我