数组由数据类型相同的一系列元素组成。
通过声明数组告诉编译器数组中内含多少元素和这些元素的类型。 编译器根据这些信息正确地创建数组。
float candy[365];
char code[12];
int states[50];
方括号 [] 表明candy、 code和states都是数组, 方括号中的数字表明数组中的元素个数。
要访问数组中的元素, 通过使用数组下标数(也称为索引) 表示数组中
的各元素。 数组元素的编号从 0 开始。
int powers[8] = {1,2,4,6,8,16,32,64};
推荐使用宏定义数组长度,只需修改 #define 这行代码即可
要创建只读数组, 应该用 const 声明和初始化数组
const int days[MONTHS] = {31,28,31,30,31,30,31,31,30,31,30,31};
存储类别警告:数组和其他变量类似, 可以把数组创建成不同的存储类别(storage class),第12章将介绍存储类别的相关内容。本章描述的数组属于自动存储类别
当初始化列表中的值少于数组元素个数时, 编译器会把剩余的元素都初始化为 0。
如果初始化列表的项数多于数组元素个数, 编译器可没那么仁慈, 它会毫不留情地将其视为错误。
如果初始化数组时省略方括号中的数字, 编译器会根据初始化列表中的项数来确定数组的大小。
const int days[] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31 };
sizeof days 是整个数组的大小(以字节为单位),sizeof day[0] 是数组中一个元素的大小(以字节为单位)。整个数组的大小除以单个元素的大小就是数组元素的个数。C99 增加了一个新特性: 指定初始化器(designated initializer) 。 利用该特性可以初始化指定的数组元素。
对于传统的C初始化语法,要初始化指定元素,则必须同时初始化其之前的所有元素。
int arr[6] = {0,0,0,0,0,212}; // 传统的语法
int arr[6] = {[5] = 212}; // 把arr[5]初始化为212
[4] = 31,30,31, 那么后面这些值将被用于初始化指定元素后面的元素。days[1] 初始化为 28, 但是 days[1] 又被后面的指定初始化 [1] = 29 初始化为 29。int days[MONTHS] = { 31, 28, [4] = 31, 30, 31, [1] = 29 };
在使用数组时, 要防止数组下标超出边界。 也就是说, 必须确保下标是有效的值。
归功于 C 信任程序员的原则。 不检查边界, C 程序可以运行更快。 编译器不会检查数组下标是否使用得当。 在C标准中, 使用越界下标的结果是未定义的。 这意味着程序看上去可以运行, 但是运行结果很奇怪, 或异常中止。
sizeof 表达式被视为整型常量, 但是(与C++不同) const 值不是。 另外, 表达式的值必须大于 0int n = 5;
int m = 8;
float a1[5]; // 可以
float a2[5*2 + 1]; //可以
float a3[sizeof(int) + 1]; //可以
float a4[-4]; // 不可以, 数组大小必须大于0
float a5[0]; // 不可以, 数组大小必须大于0
float a6[2.5]; // 不可以, 数组大小必须是整数
float a7[(int)2.5]; // 可以, 已被强制转换为整型常量
float a8[n]; // C99之前不允许
float a9[m]; // C99之前不允许
float rain[5][12]; // 内含 5 个元素的数组, 每个元素本身是一个内含12个 float 类型值的数组
上述声明中 rain[5] 表明 rain 是一个内含 5 个元素的数组; float [12] 说明每个元素的类型是 float[12]
rain[i] 是一个内含12个 float 类型值的数组,因此该数组的首元素就是 rain[i][0],第 2 个元素是rain[0][1] ,以此类推,要访问第 i 个数组的第 j 个元素(编号从 0 开始)即为 rain[i][j]
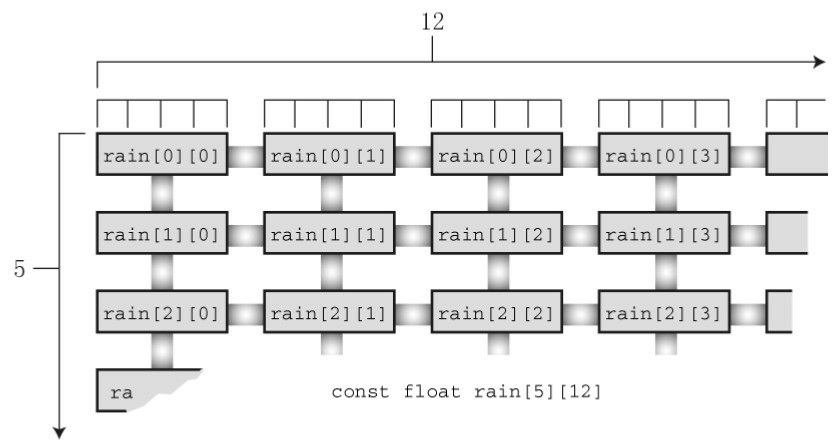
该二维视图有助于帮助读者理解二维数组的两个下标。 在计算机内部,这样的数组是按顺序储存的, 从第1个内含12个元素的数组开始, 然后是第2个内含12个元素的数组, 以此类推。
遍历二维数组常用两个嵌套的 for 循环,一个循环处理数组的第1个下标, 另一个循环处理数组的第2个下标。
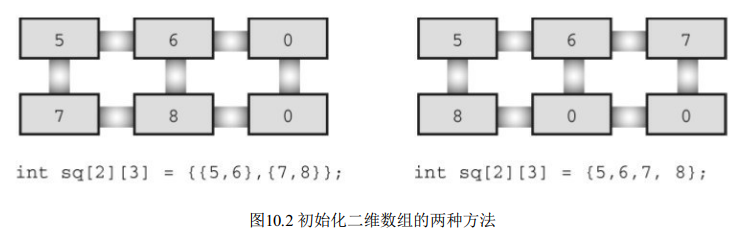
sometype ar1[5] = {val1, val2, val3, val4, val5};
rain[5][12] ,rain是一个内含 5 个元素的数组, 每个元素又是内含12个 float 类型元素的数组。 所以, 对 rain 而言, val1 应该包含 12 个值, 用于初始化内含 12 个 float 类型元素的一维数组。const float rain[5][12] =
{
{4.3,4.3,4.3,3.0,2.0,1.2,0.2,0.2,0.4,2.4,3.5,6.6},
{8.5,8.2,1.2,1.6,2.4,0.0,5.2,0.9,0.3,0.9,1.4,7.3},
{9.1,8.5,6.7,4.3,2.1,0.8,0.2,0.2,1.1,2.3,6.1,8.4},
{7.2,9.9,8.4,3.3,1.2,0.8,0.4,0.0,0.6,1.7,4.3,6.2},
{7.6,5.6,3.8,2.8,3.8,0.2,0.0,0.0,0.0,1.3,2.6,5.2}
};
// 使用了 5 个数值列表(花括号括起来),逗号分隔来初始化二维数组
// 第一个列表初始化第一个元素,依次类推。
数组名是数组首元素的地址
*pt 就无法正确地取回地址上的值) 。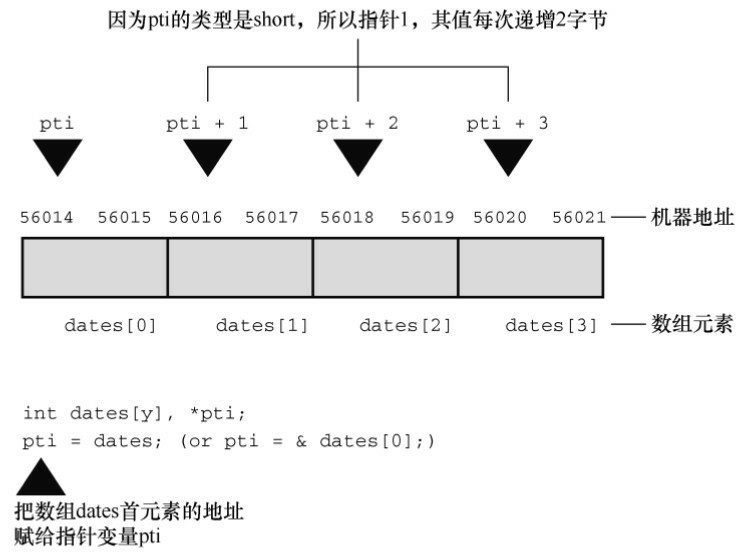
指针的值是它所指向对象的地址。 地址的表示方式依赖于计算机内部的硬件。 许多计算机(包括PC和Macintosh) 都是按字节编址, 意思是内存中的每个字节都按顺序编号。 这里, 一个较大对象的地址(如double类型的变量) 通常是该对象第一个字节的地址。
在指针前面使用 * 运算符可以得到该指针所指向对象的值。
指针加 1, 指针的值递增它所指向类型的大小( sizeof type 以字节为单位)
dates + 2 == &date[2] // 相同的地址
*(dates + 2) == dates[2] // 相同的值
以上关系表明了数组和指针的关系十分密切, 可以使用指针标识数组的元素和获得元素的值。 从本质上看, 同一个对象有两种表示法。 定义 ar[n] 的意思是 *(ar + n)。 可以认为 *(ar + n) 的意思是“到内存的 ar 位置, 然后移动 n 个单元, 检索储存在那里的值”。
不要混淆 *(dates+2) 和 *dates+2。 间接运算符 * 的优先级高于 +, 所以 *dates+2 相当于 (*dates)+2
明白了数组和指针的关系, 便可在编写程序时适时使用数组表示法或指针表示法。
指针表示法和数组表示法是两种等效的方法。编译器编译这两种写法生成的代码相同。
第1个形参告诉函数该数组的地址和数据类型, 第2个形参告诉函数该数组中元素的个数
int sum(int* ar, int n);
int ar[] 代替 int *ar:
int *ar 形式和 int ar[] 形式都表示 ar 是一个指向 int 的指针。 但是,int ar[] 只能用于声明形式参数。 第 2 种形式 int ar[] 提醒读者指针 ar 指向的不仅仅一个 int 类型值, 还是一个 int 类型数组的元素int sum (int ar[], int n);
int sum(int *ar, int n);
int sum(int *, int);
int sum(int ar[], int n);
int sum(int [], int);
还有一种方法是传递两个指针, 第1个指针指明数组的开始处(与前面用法相同) , 第2个指针指明数组的结束处。
int sump(int* start, int* end)
{
int total = 0;
while(start < end)
{
total += *start;// 把数组元素的值加起来
start++;
}
return total;
}
// 因为下标从0开始, 所以 marbles + SIZE 指向数组末尾的下一个位置。
answer = sump(marbles, marbles + SIZE);
可以把循环体压缩成一行代码:total += *start++; 一元运算符 * 和 ++ 的优先级相同, 但结合律是从右往左, 所以 start++ 先求值, 然后才是*start。
处理数组的函数实际上用指针作为参数, 但是在编写这样的函数时, 可以选择是使用数组表示法还是指针表示法。
ar[i] 和 *(ar+1) 这两个表达式都是等价的。 无论 ar 是数组名还是指针变量, 这两个表达式都没问题。 但是, 只有当 ar 是指针变量时, 才能使用 ar++ 这样的表达式。
指针表示法(尤其与递增运算符一起使用时) 更接近机器语言, 因此一些编译器在编译时能生成效率更高的代码。然而, 许多程序员认为他们的主要任务是确保代码正确、 逻辑清晰, 而代码优化应该留给编译器去做。
指针变量的 9 种基本操作
赋值: 可以把地址赋给指针。
解引用: * 运算符给出指针指向地址上储存的值。
取址: 和所有变量一样, 指针变量也有自己的地址和值。
指针与整数相加: 可以使用 + 运算符把指针与整数相加, 或整数与指针相加。如果相加的结果超出了初始指针指向的数组范围, 计算结果则是未定义的。
递增指针: 递增指向数组元素的指针可以让该指针移动至数组的下一个元素。
指针减去一个整数: 可以使用-运算符从一个指针中减去一个整数。指针必须是第1个运算对象, 整数是第 2 个运算对象。
递减指针: 当然, 除了递增指针还可以递减指针。
指针求差: 可以计算两个指针的差值。 通常, 求差的两个指针分别指向同一个数组的不同元素, 通过计算求出两元素之间的距离。 **差值的单位与数组类型的单位相同,如 ptr2 - ptr1 得 2, 意思是这两个指针所指向的两个元素相隔两个 int , 而不是 2 字节。
比较: 使用关系运算符可以比较两个指针的值, 前提是两个指针都指向相同类型的对象。
在递增或递减指针时还要注意一些问题。 编译器不会检查指针是否仍指向数组元素。
千万不要解引用未初始化的指针。在使用指针之前, 必须先用已分配的地址初始化它。 例如, 可以用一个现有变量的地址初始化该指针(使用带指针形参的函数时, 就属于这种情况) 。或者还可以使用第 12 章将介绍的 malloc() 函数先分配内存。
指针的第 1 个基本用法是在函数间传递信息。前面学过, 如果希望在被调函数中改变主调函数的变量, 必须使用指针。 指针的第 2 个基本用法是用在处理数组的函数中。
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用