使用Springboot实现简单的增删改查(仅记录,不喜勿喷)
首先介绍一下SpringBoot基本框架:
Spring Boot框架层次从上至下可分为5层:
分别为View层,Controller层,Service层,Mapper层,Model层
一:View层:视图根据接受到的数据最终展示页面给用户浏览,需要与Controller层结合起来使用
二:Controller层:负责具体的业务模块流程的控制,响应用户的请求,调用Service层的接口来控制业务流程,决定使用何种视图并准备响应数据,并把接收到的参数传给Mapper,调用Mapper的方法接口
三:Service层:主要负责业务模块的逻辑应用设计,同时有一些是关于数据库处理的操作,但是不是直接和底层数据库相关联,而是首先设计接口,再设计实现其中的类,在接口实现方法中需要导入Mapper层,接着在Spring的配置文件中配置其实现的关联,从而在应用中调用Service接口来进行业务处理
四:Mapper层:主要是做数据持久层的工作,同时提供增删改查工作,Mapper层也是首先设计接口,再设计实现其中的类,具体实现在mapper.xml文件中,然后就可以在模块中调用此接口来进行数据业务的处理
五:Model层:创建对象,包括构造器和get、set方法和toString方法
Controller层:沟通前后端,注解为@RestController
Service层:沟通Mapper层和Controller层,注解为@Service
Mapper层:沟通数据库和Service层,注解为@Repository
对应每个实体,比如说user,需要分别的Controller层,Service层,Mapper层,
Mapper层里面包含一个接口和一个实体类impl,接口负责确定数据连接层的方法,
而impl文件就是直接用来连接数据库的一个实体类
具体的web项目:
controller层->service层(serviceimpl实现service接口)->mapper层->mapper.xml文件
解释:
controller层调用了service的具体功能和方法,service层由service对应的接口和实现类组成,serviceimpl实现service的相关接口同时完成相关的业务逻辑处理
service层(serviceimpl)再调用mapper层的接口进行业务逻辑应用的处理。mapper层的接口在对应的xml配置文件中进行配置、实现和关联,故mapper层的任务就是想数据库发送sql语句,完成数据的处理任务
下面开始进行准备工作:
1.新建项目,名称前缀为ProBuildLog
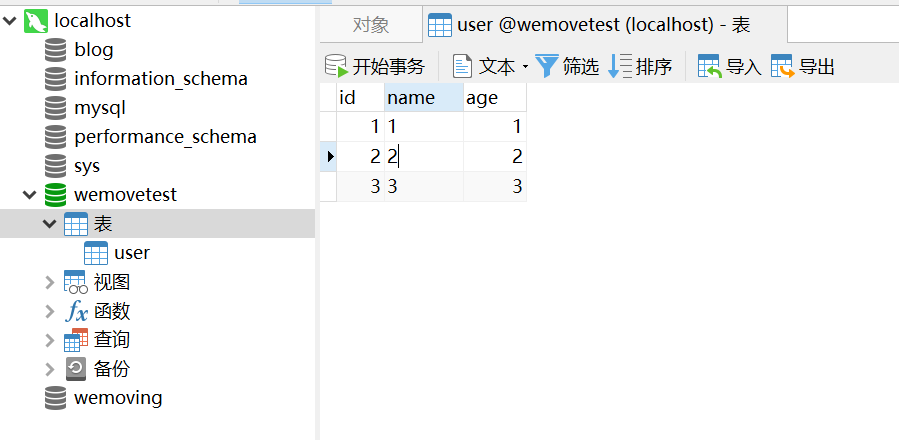
2.新建数据库wemovetest,新建数据表user,并填写部分数据
3.新建application.yml文件,文件代码如下:
server:
port: 8080
spring:
datasource:
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/wemovetest?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: 123456
mybatis-plus:
#mapper映射文件路径
mapper-locations: classpath*:mapper/*Mapper.xml
#配置扫描包别名
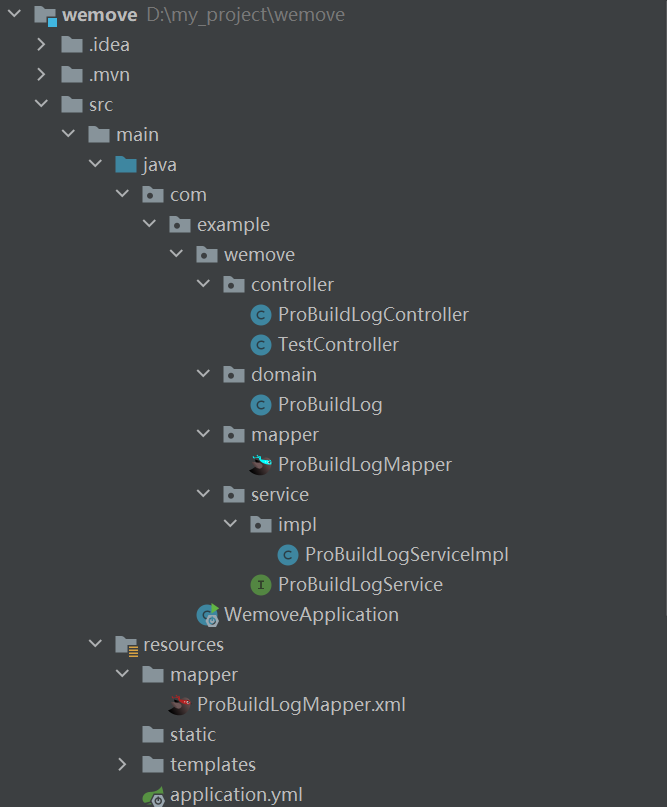
type-aliases-package: com.example.wemove.domain4.新建以下几个包和包中的类,如图:
5编写相关类和接口的代码:
一:controller层
import com.example.wemove.service.ProBuildLogService;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
@RestController
@RequestMapping("/user")
public class ProBuildLogController{
@Resource
private ProBuildLogService userService;
@RequestMapping("/show") //该注解直接返回字符串
public String show(){
return "user";
}
/**
* 查找角色
* @param id
* @return
*/
@GetMapping( "/getUser/{id}")
public ProBuildLog getUser(@PathVariable Long id) {
return userService.selectUserById(id);
}
/**
* 新增角色
*/
@PostMapping
public boolean insertUser(@Validated @RequestBody ProBuildLog role) {
return userService.insertUser(role);
}
/**
* 删除角色
*/
@DeleteMapping("/{roleIds}")
public boolean deleteUser(@PathVariable Long roleIds) {
return userService.deleteUserById(roleIds);
}
/**
* 状态修改
*/
@PutMapping("/changeStatus")
public boolean changeStatus(@RequestBody ProBuildLog role) {
return userService.updateUser(role);
}
}二:service层接口
package com.example.wemove.service;
import com.example.wemove.domain.ProBuildLog;
public interface ProBuildLogService{
/**
* 根据id查询用户
* @param id
* @return
*/
ProBuildLog selectUserById(Long id);
/**
* 新增保存角色信息
*
* @param role 角色信息
* @return 结果
*/
boolean insertUser(ProBuildLog role);
/**
* 通过角色ID删除角色
*
* @param roleId 角色ID
* @return 结果
*/
boolean deleteUserById(Long roleId);
/**
* 修改保存角色信息
*
* @param role 角色信息
* @return 结果
*/
boolean updateUser(ProBuildLog role);
}三:service层接口的imp
package com.example.wemove.service.impl;
import com.example.wemove.domain.ProBuildLog;
import com.example.wemove.mapper.ProBuildLogMapper;
import com.example.wemove.service.ProBuildLogService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class ProBuildLogServiceImpl implements ProBuildLogService {
/**
* 注入mapper到service层
*/
@Autowired
private ProBuildLogMapper userMapper; //创建了一个mapper类的变量
/**
* 通过角色ID查询角色
*
* @param id 角色ID
* @return 角色对象信息
*/
@Override
public ProBuildLog selectUserById(Long id) {
return userMapper.selectUserById(id);
}
/**
* 新增保存角色信息
*
* @param role 角色信息
* @return 结果
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean insertUser(ProBuildLog role) {
// 新增角色信息
return userMapper.insertUser(role)>0;
}
/**
* 修改保存角色信息
*
* @param role 角色信息
* @return 结果
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean updateUser(ProBuildLog role) {
// 修改角色信息
return userMapper.updateUser(role)>0;
}
/**
* 通过角色ID删除角色
*
* @param roleId 角色ID
* @return 结果
*/
@Override
@Transactional
public boolean deleteUserById(Long roleId) {
return userMapper.deleteUserById(roleId)>0;
}
}
}l四:Mapper层接口
package com.example.wemove.mapper;
import com.example.wemove.domain.ProBuildLog;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface ProBuildMapper{
/**
* 根据id查询用户
* @param id
* @return 角色列表
*/
ProBuildLog selectUserById(Long id);
/**
* 修改角色信息
*
* @param role 角色信息
* @return 结果
*/
int updateUser(ProBuildLog role);
/**
* 新增角色信息
*
* @param role 角色信息
* @return 结果
*/
int insertUser(ProBuildLog role);
/**
* 通过角色ID删除角色
*
* @param roleId 角色ID
* @return 结果
*/
int deleteUserById(Long roleId);
}五:Mapper层xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.wemove.mapper.ProBuildLogMapper">
<resultMap id="ProBuildLogResult" type="ProBuildLog"> //id是命名,type是类型
<id property="id" column="id"/> //property是domian里面变量的名称,column是数据库里面的名称
<result property="name" column="name"/>
<result property="age" column="age"/>
</resultMap>
<select id="selectUserById" parameterType="long" resultMap="ProBuildLogResult"> //id是命名,parameterType是接口类型
select * from user where id=#{id}
</select>
<insert id="insertUser" parameterType="ProBuildLog">
insert into user() value(#{id},#{name},#{age})
</insert>
<update id="updateUser" parameterType="ProBuildLog">
update user set name=#{name},age=#{age} where id=#{id}
</update>
<delete id="deleteUserById" parameterType="Long">
delete from user where id=#{id}
</delete>
</mapper>6.启动项目即可:
流程解析:
首先是Controller层,该层自动注入了Service层的接口,并且通过该接口的调用了Service层impl的方法,而impl层自动注入了Mapper层的接口,并且通过该接口调用了Mapper层xml的方法,xml文件中的方法通过对应的MySQL语句进行对数据库的操作,从而完成数据处理任务
如图:(图片转载)

7.项目测试:
项目成功启动后,打开ApiFox或PostMan开始进行数据的测试。
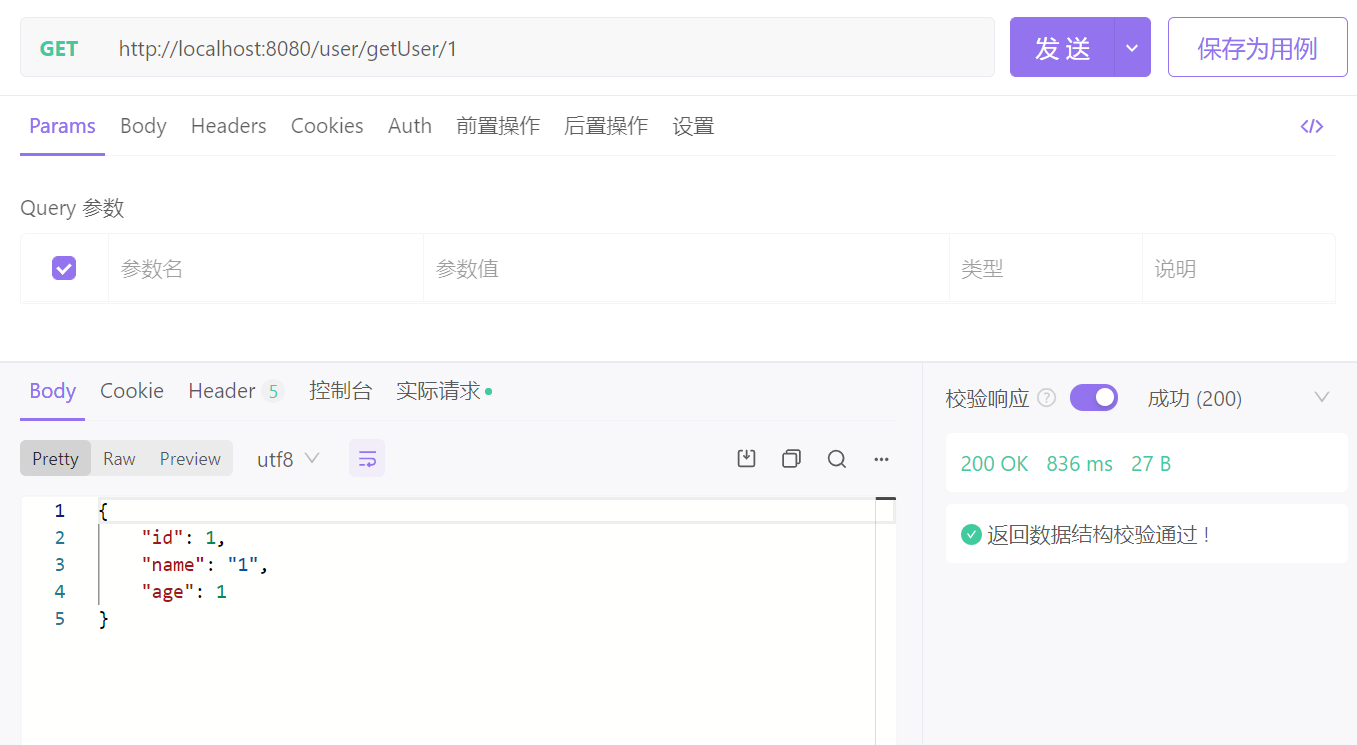
一:查询角色:
创建查询角色接口,接口类型为GET,接口路径为http://localhost:8080+/数据表名称+/注解
eg:http://localhost:8080/user/getUser/1
如图:
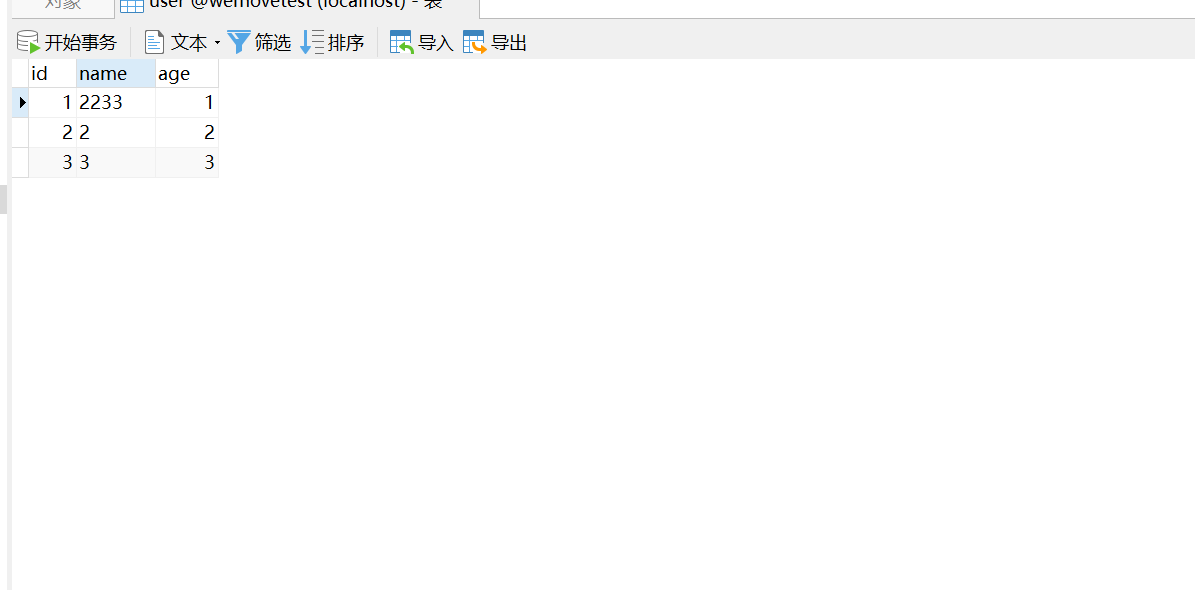
二:修改角色:
创建修改角色接口,接口类型为PUT,接口路径为http://localhost:8080+/数据表名称+/注解
eg:http://localhost:8080/user/changeStatus
修改前:

_____________________________________________________________________________

_____________________________________________________________________________
修改后:
三:删除角色:
创建删除角色接口,接口类型为DELETE,接口路径为http://localhost:8080+/数据表名称+/注解
eg:http://localhost:8080/use/1
删除后如图:
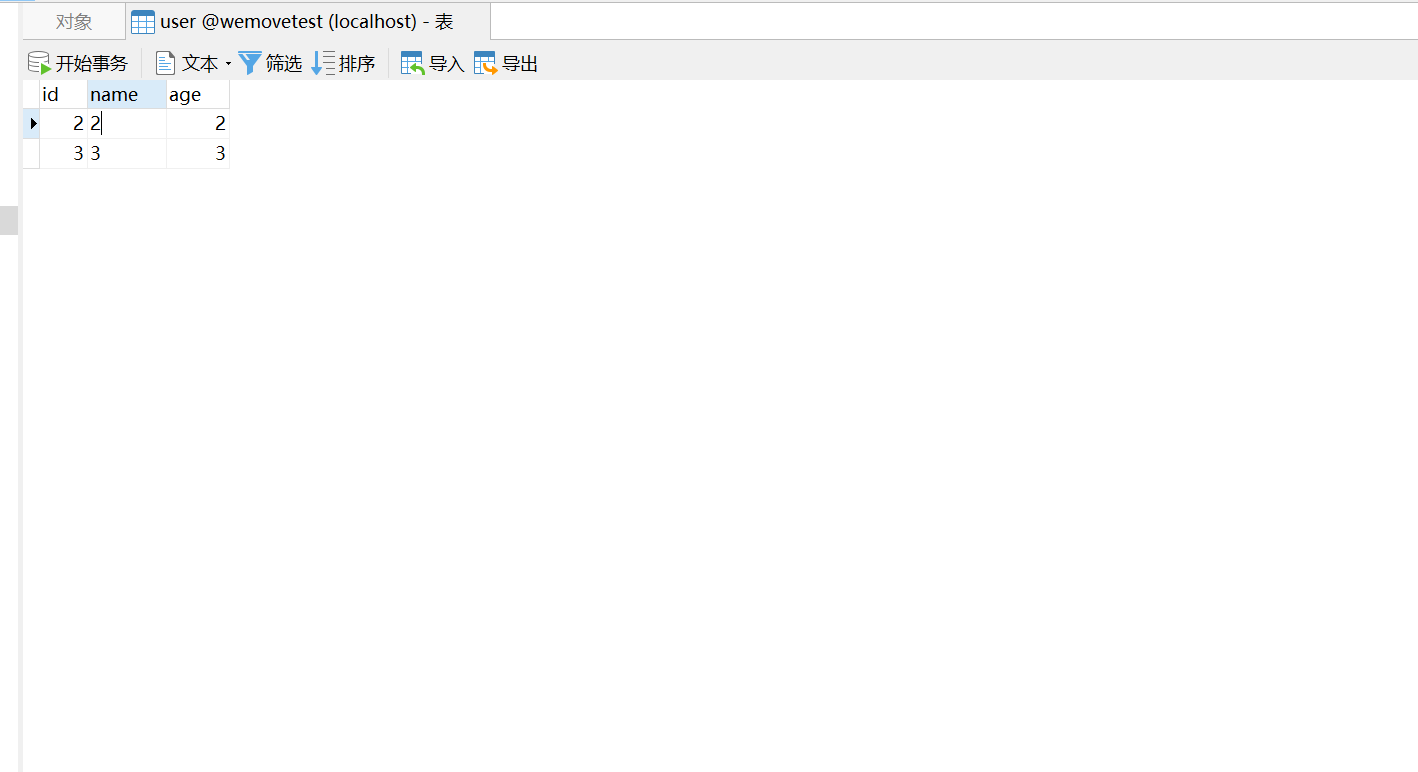
四:新增角色:
创建新增角色接口,接口类型为POST,接口路径为http://localhost:8080+/数据表名称
eg:http://localhost:8080/user

_____________________________________________________________________________
新增后:
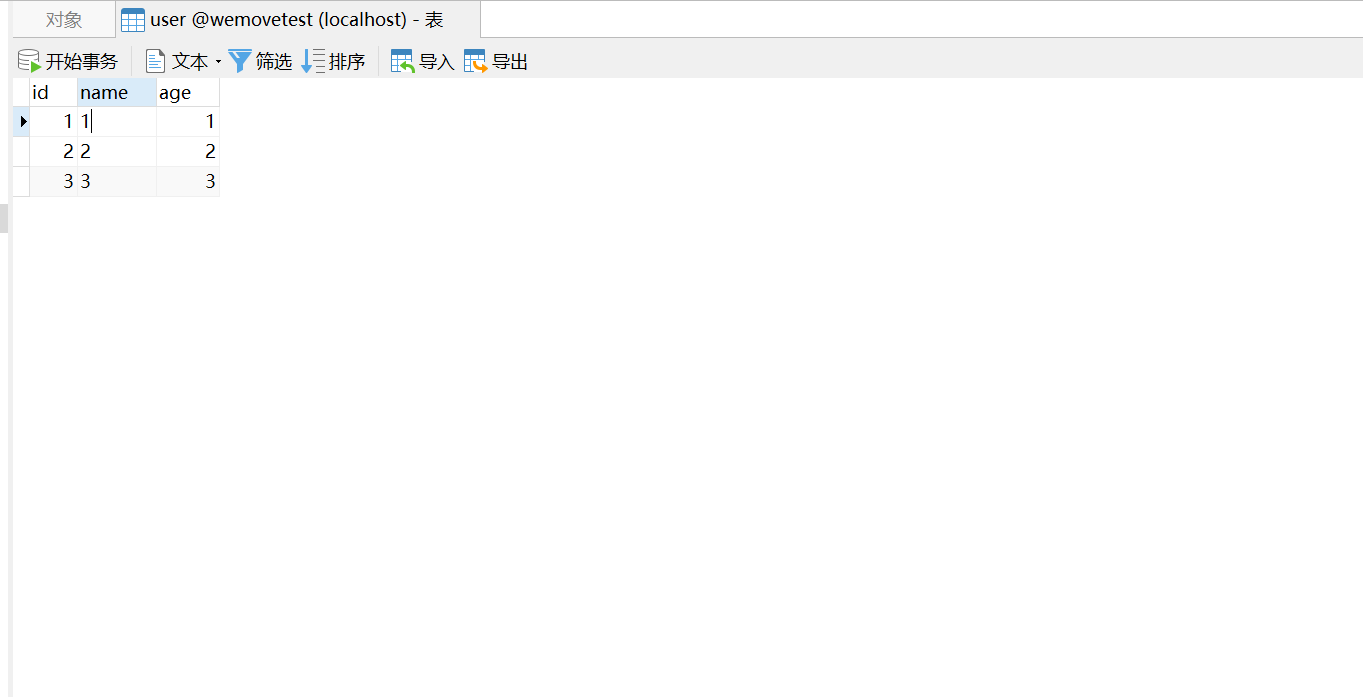
至此,我们已经完成了增删改查的相关工作
感谢浏览,欢迎指教和交流
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r