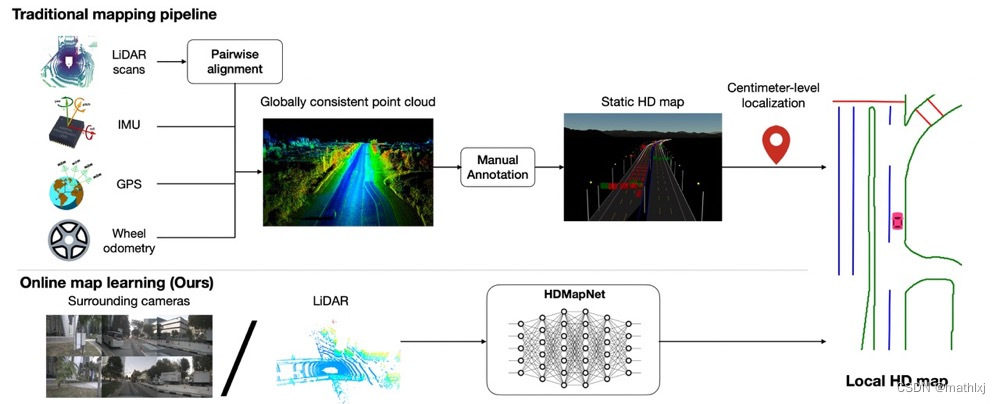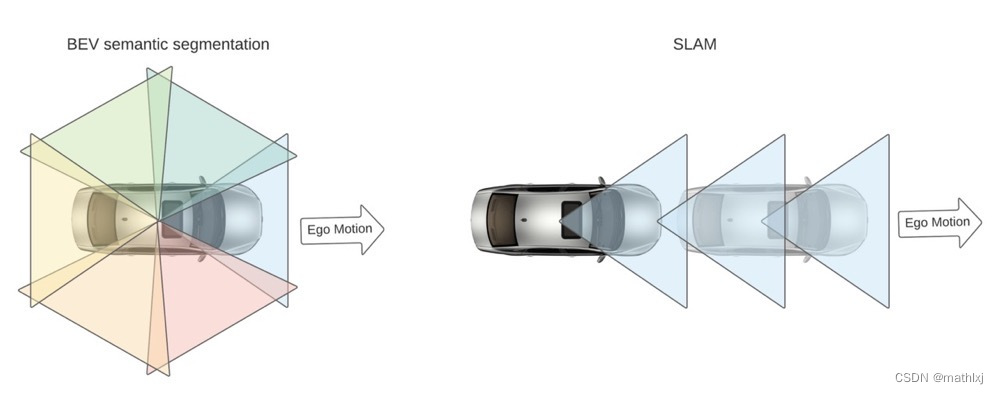
一些较新的数据集,例如(Lyft, Nuscenes, Argoverse),提供了
输入:多模态,主要是多视角的图像
输出:语义分割
VPN (Cross-view Semantic Segmentation for Sensing Surroundings)几乎是第一个探索BEV语义分割的任务。
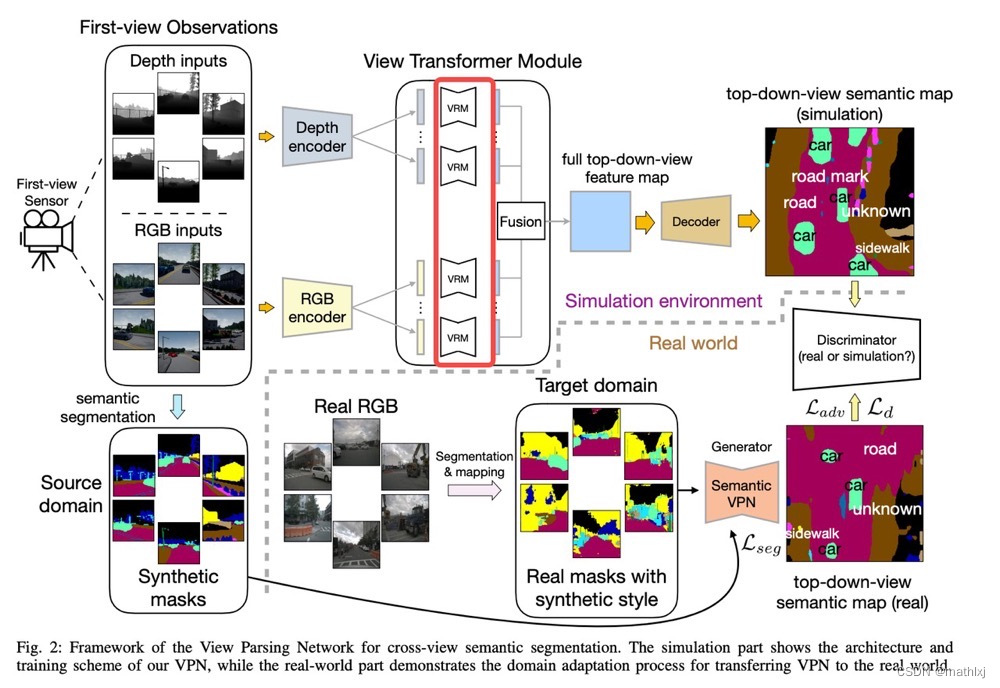
VPN 对每个模态的每个输入经encoder得到的feature map,经过不同的MLP回归从原始view到BEV视角的映射矩阵R_i(View transformer)。当然,不足之处是也忽略了feature点与点之间的位置关系。
使用人造的数据和对抗损失来训练。
View transformer:输入(原视角)与输出(BEV视角)尺寸相同。(实际上是没必要的)
A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View
输入:4个摄像头
输出:语义分割
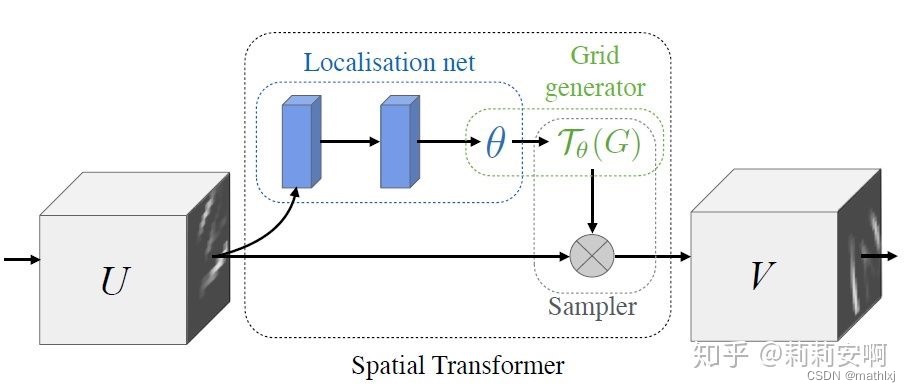
Cam2BEV 使用一个space trasnformer module with IPM(Inverse Perspective Mapping)来将原视角的feature映射到BEV空间。
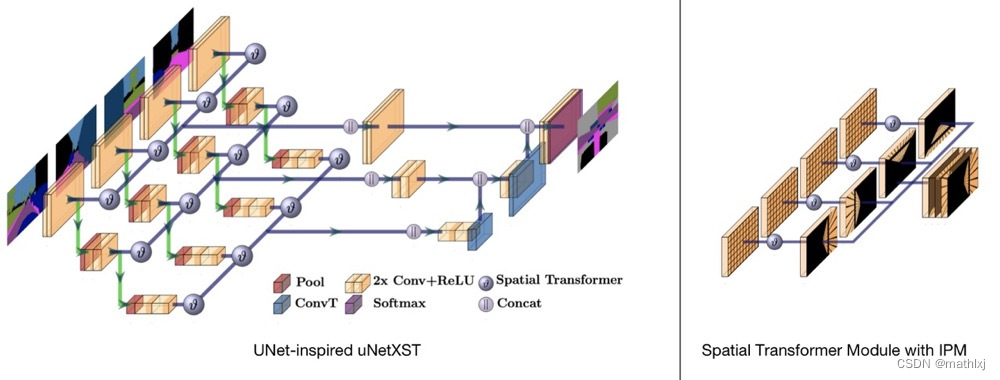
主干网络借鉴了uNet的思想
对ground truth做预处理,来生成被遮挡的部分为一类。
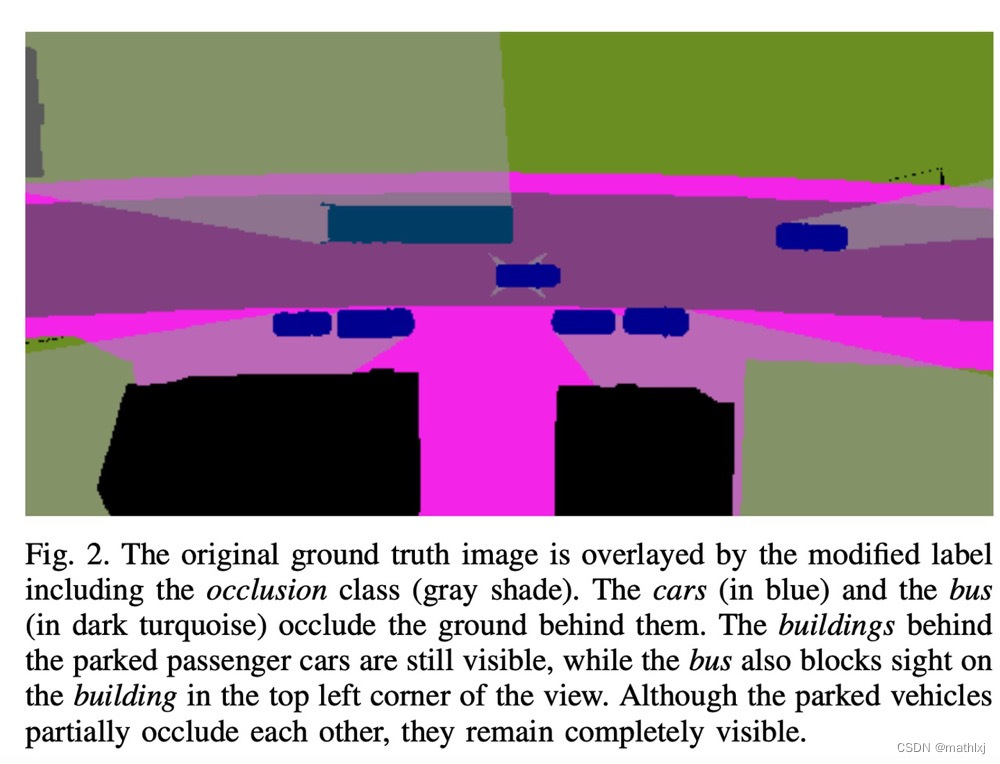
Spatial Transformer Module
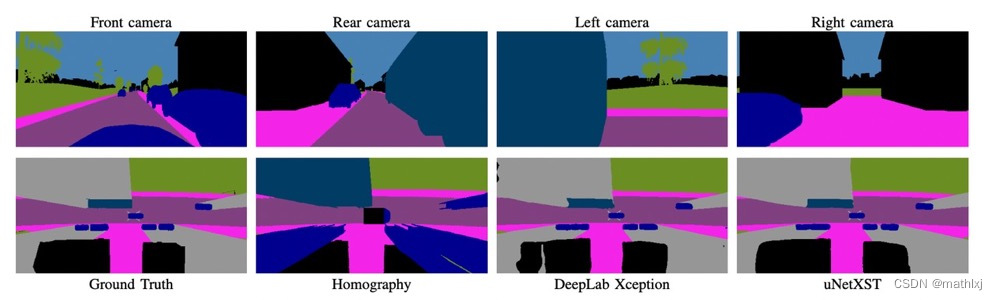
直接用四个相机的语义分割结果作为输入,类别有road, sidewalk, person, car, truck, bus,
bike, obstacle, vegetation.
MonoLayout: Amodal scene layout from a single image
输入:单个摄像头
输出:语义分割,道路和交通参与者
Shared encoder,分两个decoder,一个用来做静态语义分割,一个做动态语义分割
对KITTI数据集使用temporal sensor fusion生成一些weak groundtruth,通过结合2D语义分割结果和位置信息
对抗学习损失,静态分割head的先验数据分布来自公开数据集OpenStreetMap,属于unpaired fashion.
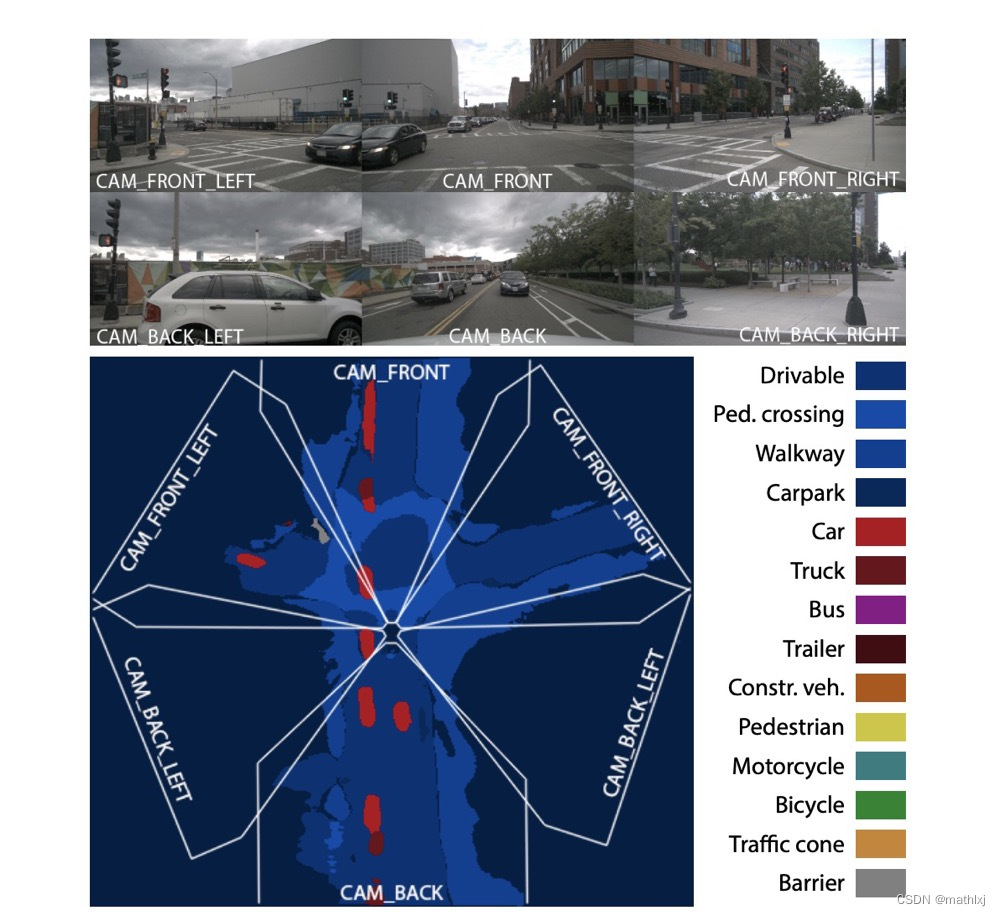
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
输入:多个摄像头
输出:语义分割,道路、交通参与者、障碍物
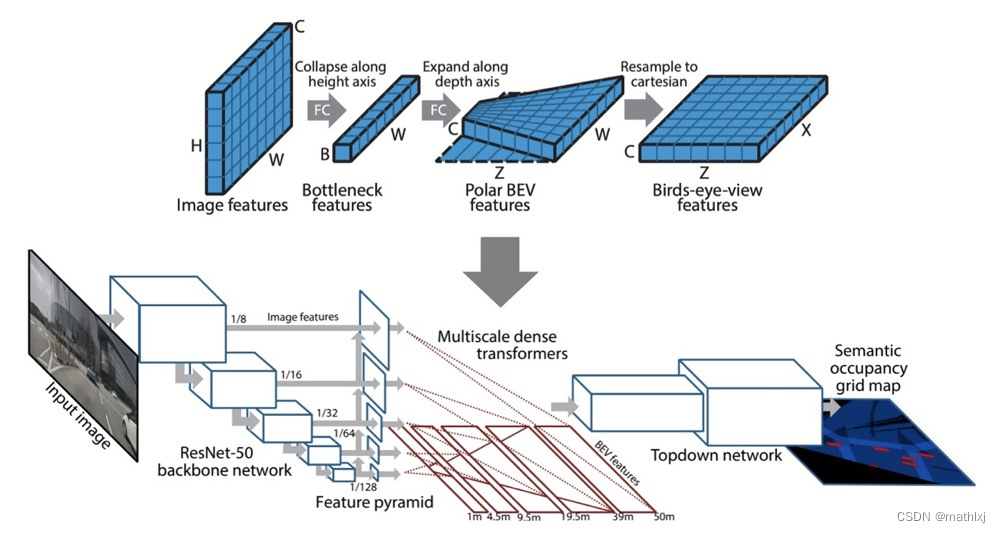
Semantic occupancy grid prediction:与2D图像的语义分割类似,预测 m i c m_i^c mic,即第c类占据第i个grid的概率
dense transformer module,use of both camera geometry and fully-connected reasoning to map features from the image to the BEV space。这里feature map的size不一定一致了,输入为
H
×
W
×
C
H\times W \times C
H×W×C, 输出为
Z
×
X
×
C
Z\times X \times C
Z×X×C。
Multiscale transformer pyramid
使用Bayesian Filtering融合跨相机和扩时间的信息。
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
输入:多个摄像头
输出:语义分割,道路和交通参与者
第一篇对每个角度的摄像头作用于不同的CNN,对像素点的深度进行估计,根据深度将感知的图像提升大3D点云,然后使用相机外参(已知)映射到BEV空间,最后使用一个BEV CNN来精修这些预测。

流程
Lift: Latent Depth Distribution:无训练参数地将2D图像(H,W)等深度间距地提升到(D,H,W),神经网络预测该深度的置信度,对生成的feature乘以该深度的概率。
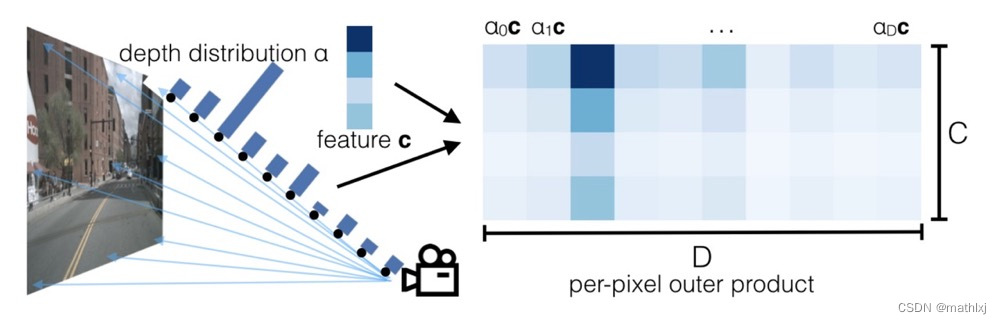
Splat: Pillar Pooling:借鉴pointpillars,得到(C,H,W)的feature,可被CNN处理
Shoot: Motion Planning:为ego预测K条轨迹模板的分布
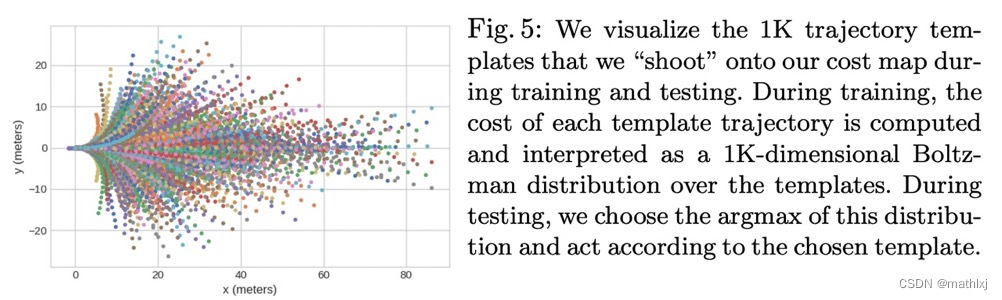
结果展示(其实是个动画,可以进主页看)

Understanding Bird’s-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
输入:单个摄像头的多帧+估计的ego pose
输出:静态/动态目标的分割
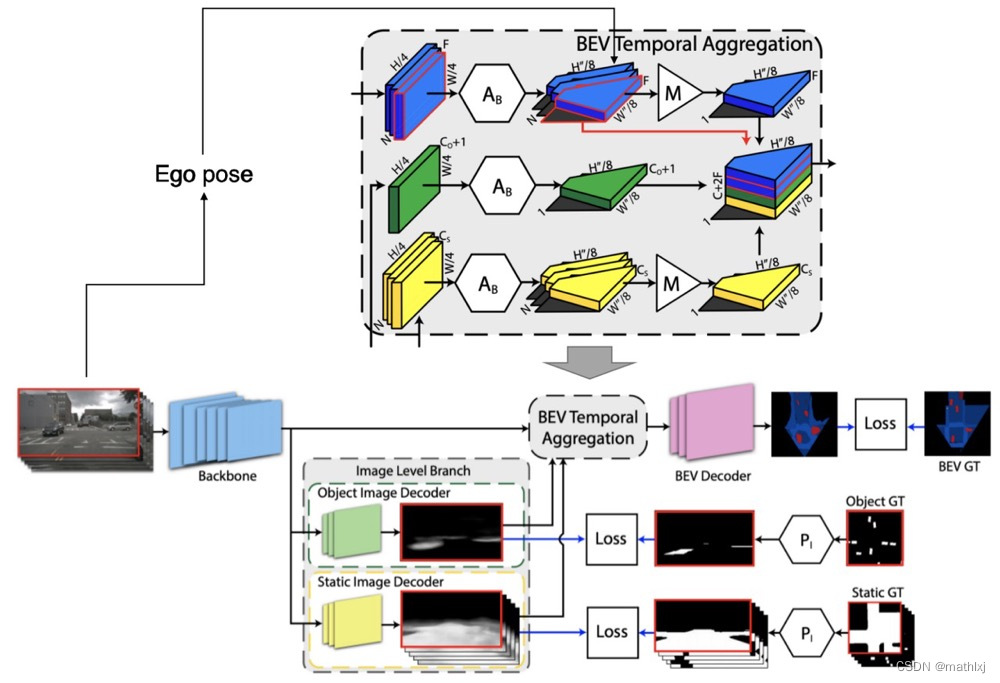
输入: N × H × W × 3 N\times H\times W \times 3 N×H×W×3,输出 1 × H ′ × W ′ × C 1\times H'\times W' \times C 1×H′×W′×C,C为静态目标(HD map)类别+动态目标类别+1个背景类别
object image decoder:仅对当前一帧进行分割;static image decoder 对输入的所以帧分割。两者皆输出heatmap
Temporal Aggregation
BEV Decoder

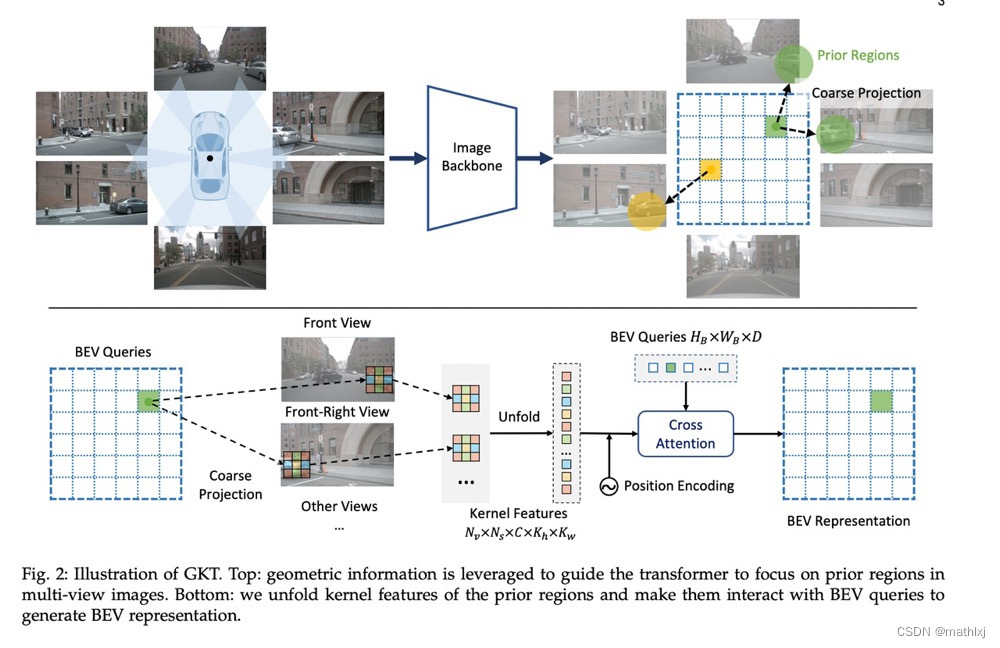
Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer
Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation
paper,github,35 FPS
输入:单张摄像头前向图
输出:road layout estimation and vehicle occupancy estimation
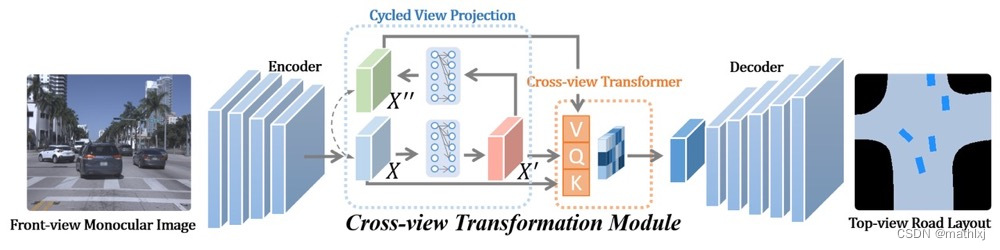
a cross-view transformation module:
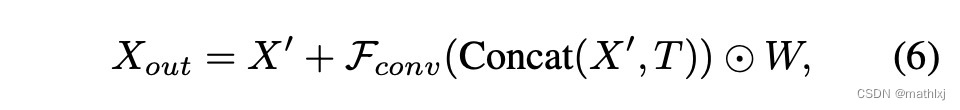
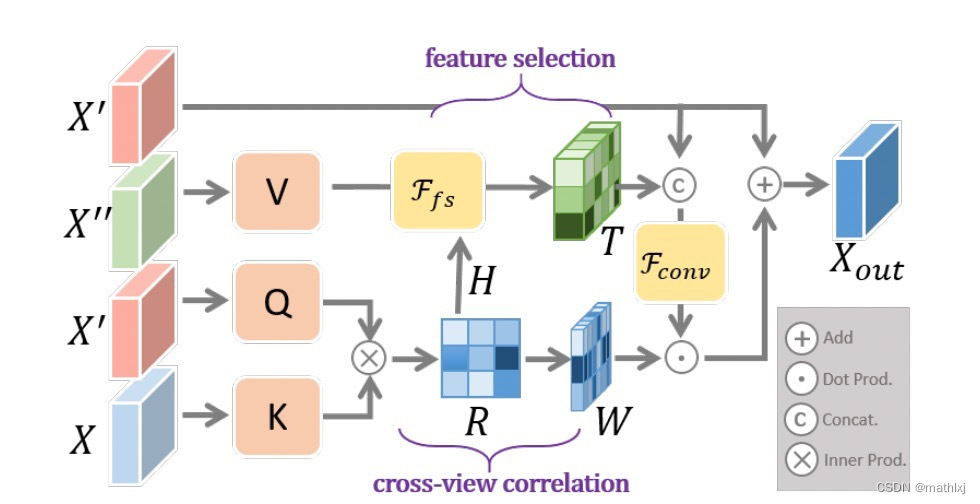
如果将 X ′ ′ X'' X′′和 X X X看作同一种特征表达,该方法更类似于cross-attention
损失函数:对抗损失
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
paper,github,中文blog,测速V100上,R101-DCN,input size 900X1600,大约2FPS
输入:多视角相机图像
输出:语义分割/3D目标检测
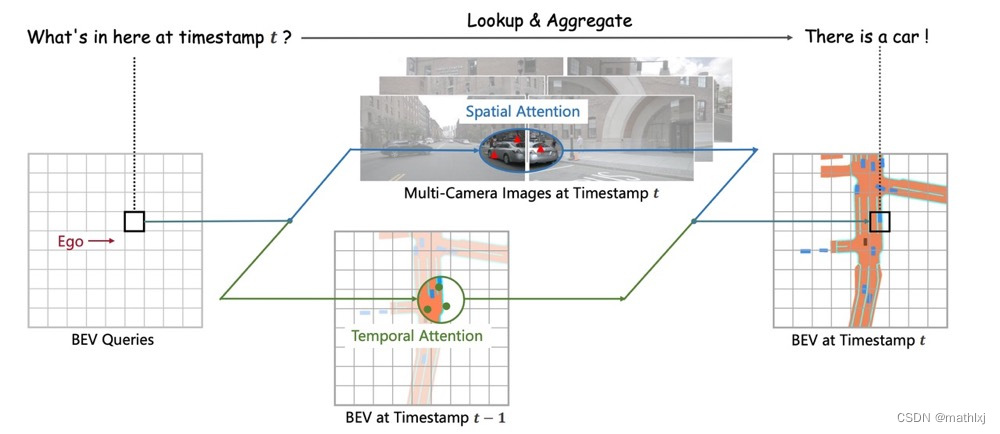
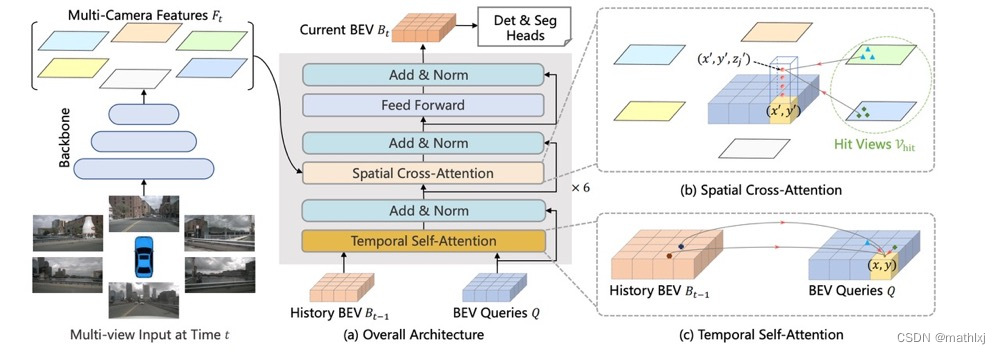
使用Transformer在BEV空间下进行时空信息融合,通过生成显式的BEV特征,用来融合时序信息或者来自其他模态的特征,并且能够同时支撑更多的感知任务
定义BEV queries:BEV queries 每个位于(x, y)位置的query都仅负责表征其对应的小范围区域。BEV queries 通过对spatial space 和 tempoal space 轮番查询从而能够将时空信息聚合在BEV query特征中。最终我们将BEV queries 提取的到的特征视为BEV 特征,该BEV特征能够支持包括3D 目标检测和地图语义分割在内的多种自动驾驶感知任务。
Spatial Cross-Attention:使用了一种基于deformable attention 的稀疏注意力机制时每个BEV query之和部分图像区域进行交互。 对于每个位于(x, y)位置的BEV特征,我们可以计算其对应现实世界的坐标x’,y’。 然后我们将BEV query进行lift 操作,获取在z轴上的多个3D points。 有了3D points, 就能够通过相机内外参获取3D points 在view 平面上的投影点。受到相机参数的限制,每个BEV query 一般只会在1-2个view上有有效的投影点。基于Deformable Attention, 我们以这些投影点作为参考点,在周围进行特征采样,BEV query使用加权的采样特征进行更新,从而完成了spatial 空间的特征聚合。
Temporal Self-Attention:从经典的RNN网络获得启发,我们将BEV 特征视为类似能够传递序列信息的memory。对于当前时刻位于(x, y)出的BEV query, 它表征的物体可能静态或者动态,但是我们知道它表征的物体在上一时刻会出现在(x, y)周围一定范围内,因此我们再次利用deformable attention 来以(x, y)作为参考点进行特征采样
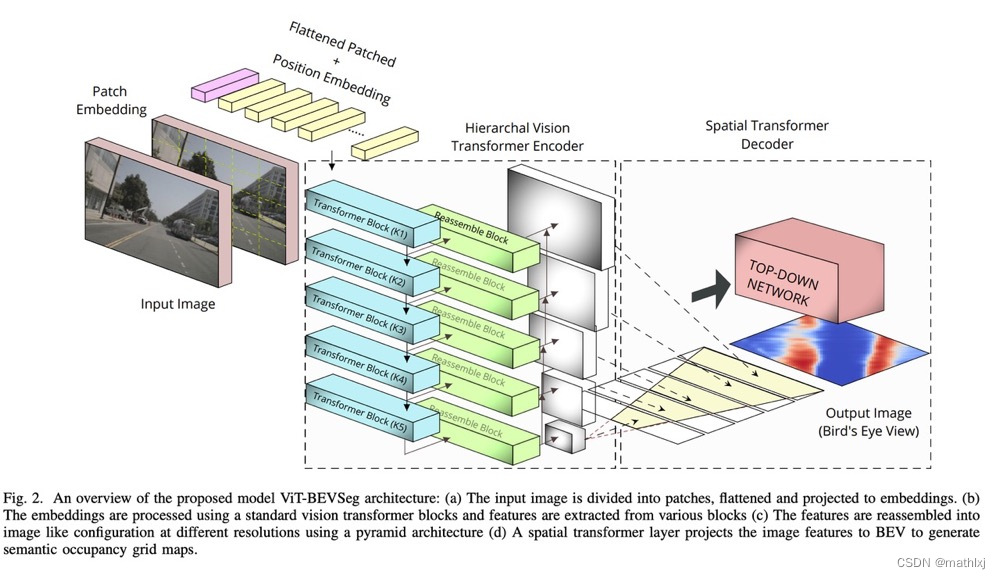
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation

Predicting the Future from Monocular Cameras in Bird’s-Eye View
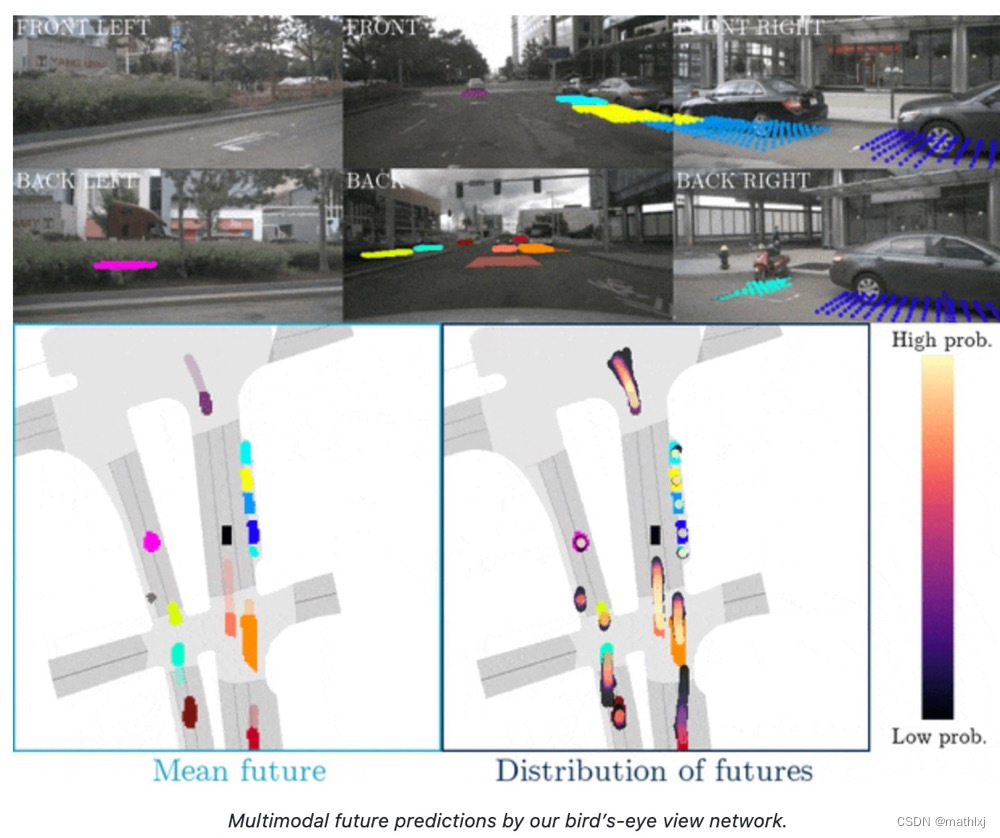
对交通参与者进行轨迹预测
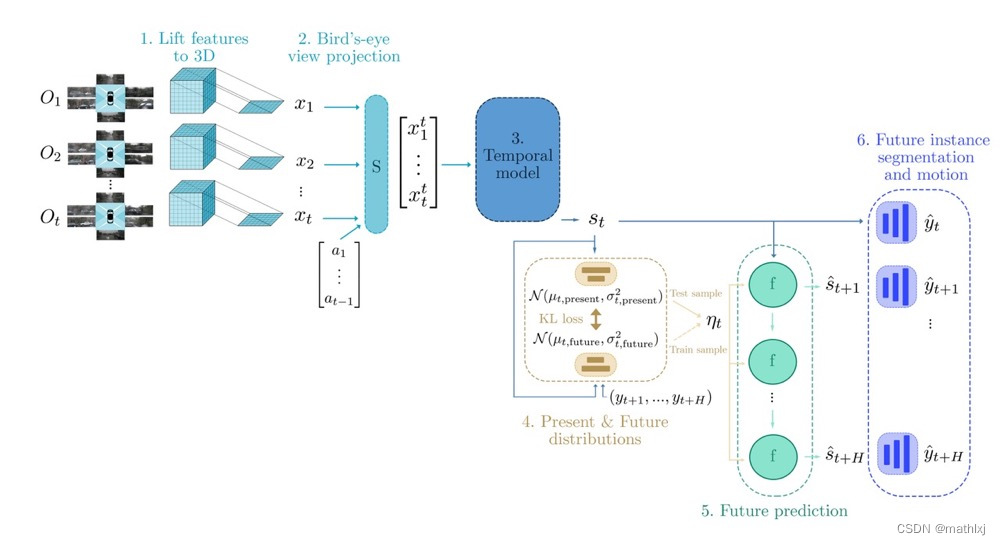
Pipeline

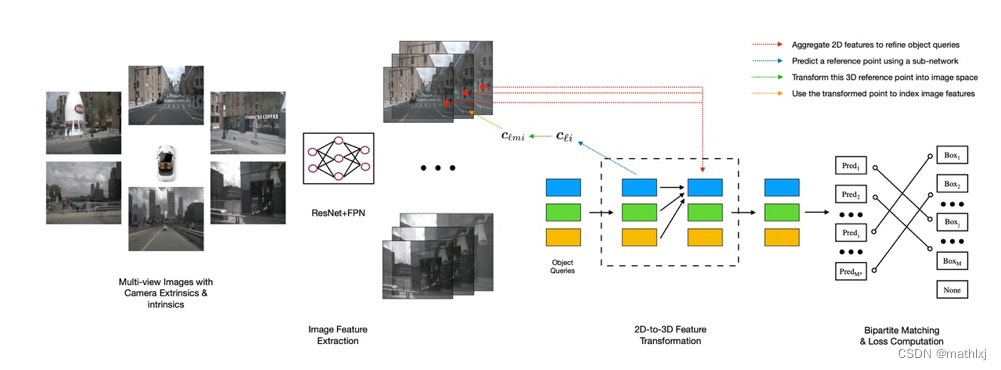
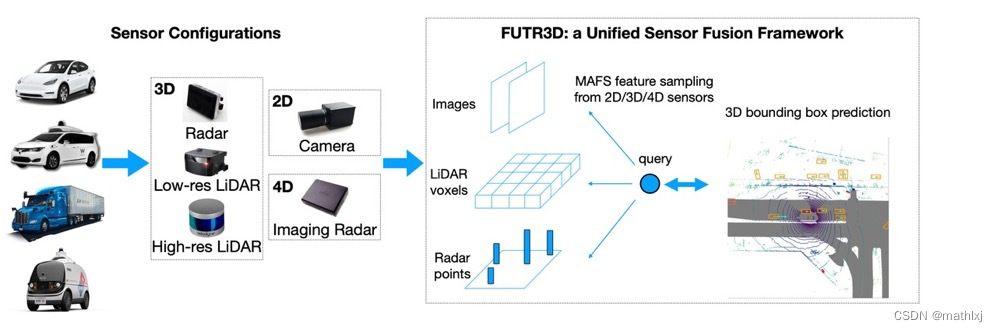
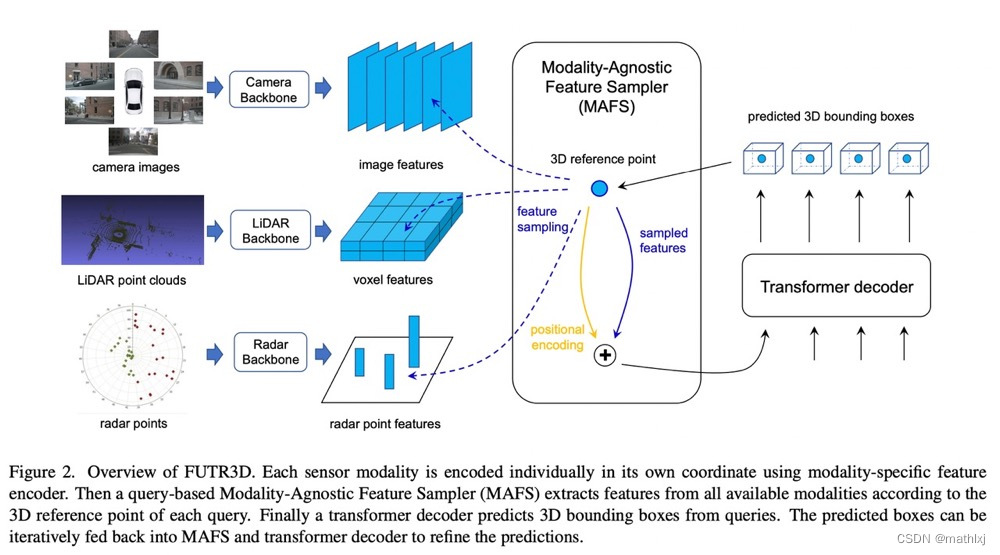
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries

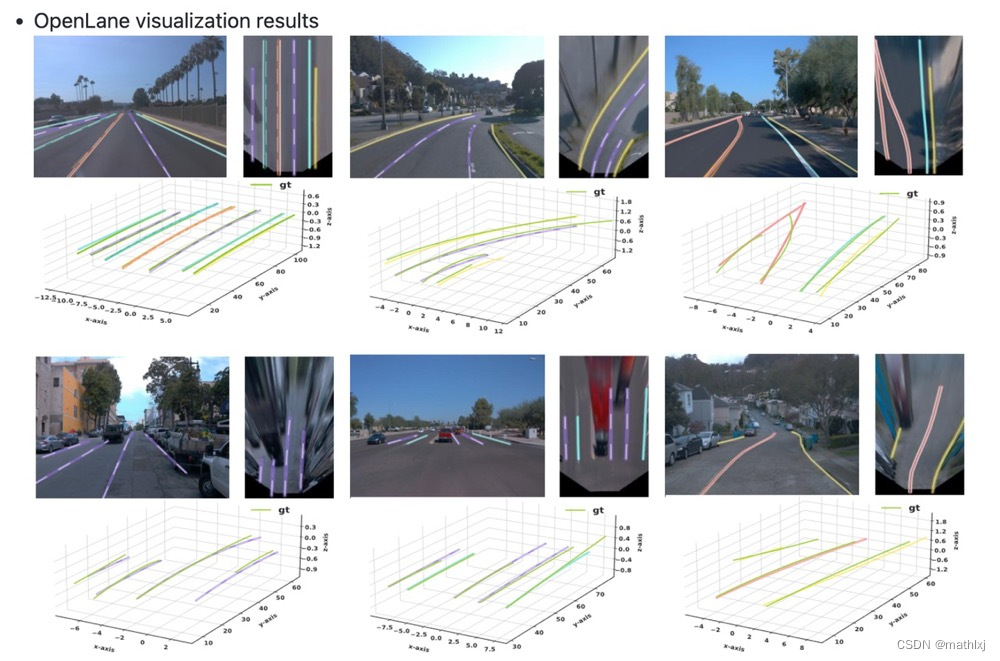
PersFormer: a New Baseline for 3D Laneline Detection
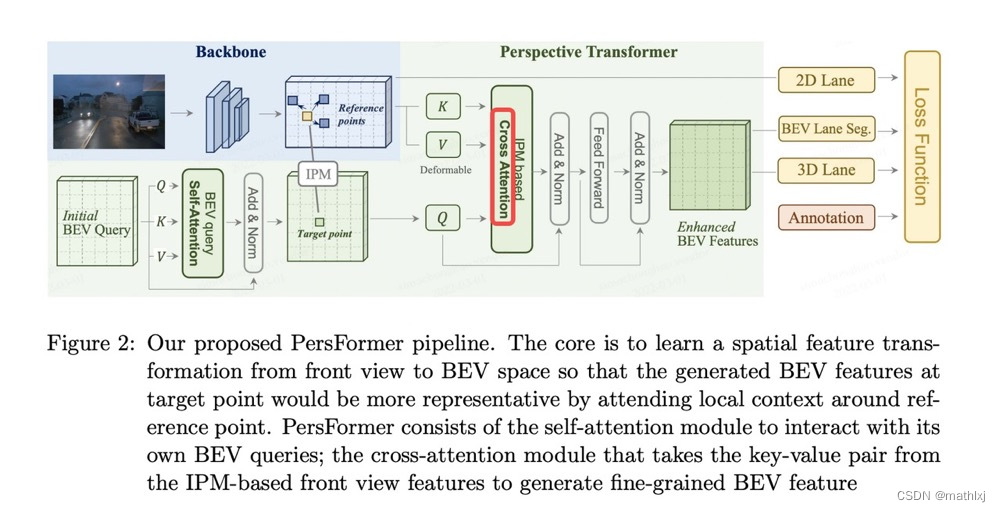
核心Proposed Perspective Transformer:
HDMapNet: An Online HD Map Construction and Evaluation Framework
主要解决两个问题:道路预测向量化和从相机前视图到鸟瞰图的视角转换。
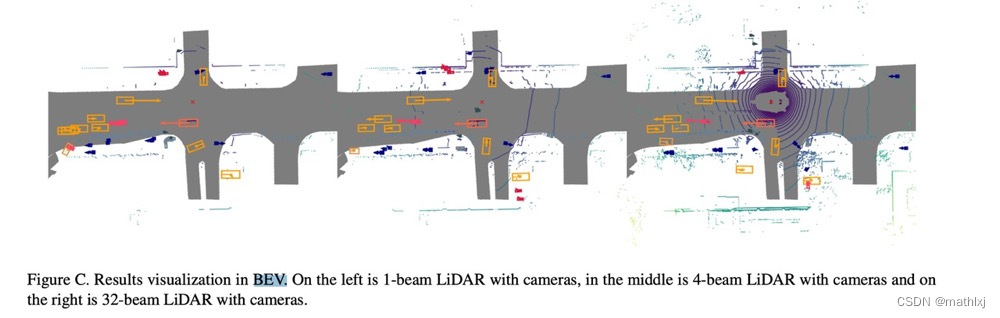
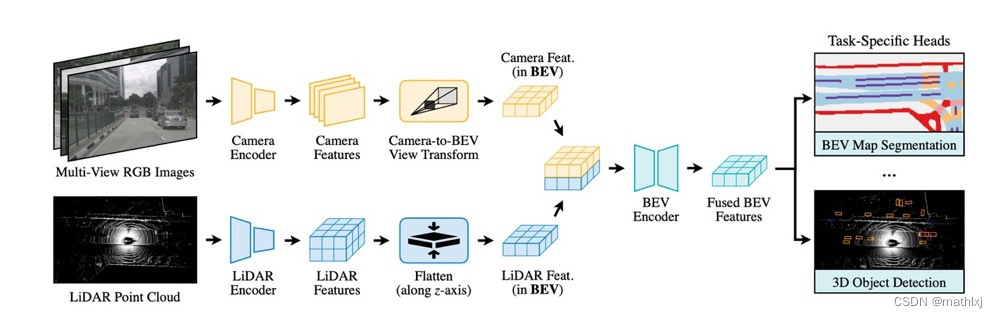
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
BEVFusion ranks first on nuScenes among all solutions.
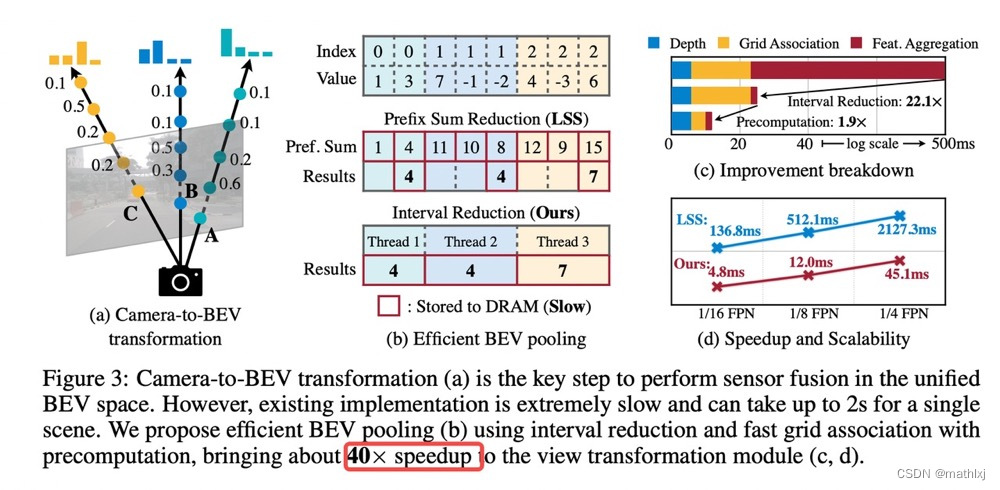
核心:对BEV pooling的操作做了加速,从500ms 缩减到 12ms

我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
目前,Itembelongs_toCompany和has_manyItemVariants。我正在尝试使用嵌套的fields_for通过Item表单添加ItemVariant字段,但是使用:item_variants不显示该表单。只有当我使用单数时才会显示。我检查了我的关联,它们似乎是正确的,这可能与嵌套在公司下的项目有关,还是我遗漏了其他东西?提前致谢。注意:下面的代码片段中省略了不相关的代码。编辑:不知道这是否相关,但我正在使用CanCan进行身份验证。routes.rbresources:companiesdoresources:itemsenditem.rbclassItemi
除了可访问性标准不鼓励使用这一事实指向当前页面的链接,我应该怎么做重构以下View代码?#navigation%ul.tabbed-ifcurrent_page?(new_profile_path)%li{:class=>"current_page_item"}=link_tot("new_profile"),new_profile_path-else%li=link_tot("new_profile"),new_profile_path-ifcurrent_page?(profiles_path)%li{:class=>"current_page_item"}=link_tot("p
我正在尝试以一种更类似于普通RubyGem结构的方式构建我的Sinatra应用程序。我有以下文件树:.├──app.rb├──config.ru├──Gemfile├──Gemfile.lock├──helpers│ ├──dbconfig.rb│ ├──functions.rb│ └──init.rb├──hidden│ └──Rakefile├──lib│ ├──admin.rb│ ├──api.rb│ ├──indexer.rb│ ├──init.rb│ └──magnet.rb├──models│ ├──init.rb│ ├──invite.rb│ ├─
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
基本上,我试图在用户单击链接(或按钮或某种类型的交互元素)时执行Rails方法。我试着把它放在View中:但这似乎没有用。它最终只是在用户甚至没有点击“添加”链接的情况下调用该函数。我也用link_to试过了,但也没用。我开始认为没有一种干净的方法可以做到这一点。无论如何,感谢您的帮助。附言。我在ApplicationController中定义了该方法,它是一个辅助方法。 最佳答案 View和Controller是相互独立的。为了使链接在Controller内执行函数调用,您需要对应用程序中的端点执行ajax调用。该路由应调用rub
为了减少我的小Rails应用程序中的代码重复,我一直致力于将我的模型之间的通用代码放入它自己的单独模块中,到目前为止一切顺利。模型的东西相当简单,我只需要在开头包含模块,例如:classIso这工作正常,但是现在,我将有一些Controller和View代码,这些代码也将在这些模型之间通用,到目前为止,我有这个用于我的可发送内容:#Thisisamodulethatisusedforpages/formsthatarecanbe"sent"#eitherviafax,email,orprinted.moduleSendablemoduleModeldefself.included(kl