这一章节主要分析allocation模块的结构和原理,分析allocation模块的工作过程
在此之前先看看什么是分片,它在磁盘上是以什么形式存储的
首先用postman发起创建索引请求
PUT localhost:9200/test02
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1
}
}test02在后台代码中用随机UUID生成对应的index.uuid;
indexSettingsBuilder.put(SETTING_INDEX_UUID, UUIDs.randomBase64UUID());请求结束后,本地节点data目录下:产生如下数据目录
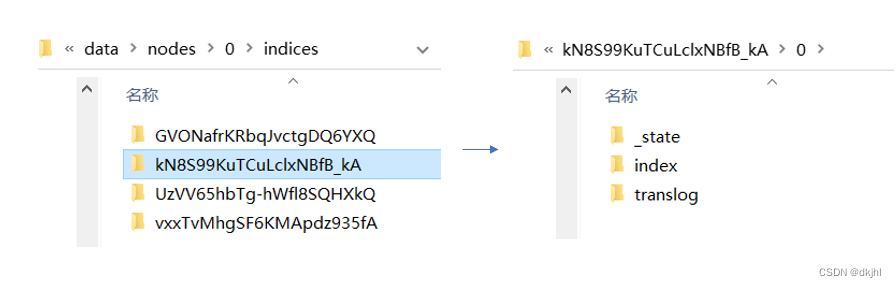
他们的相关参数在代码中对应的key如下json所示
{
"client.type": "node",
"cluster.election.strategy": "supports_voting_only",
"cluster.name": "es-source-demo",
"http.type": "security4",
"http.type.default": "netty4",
"node.attr.ml.machine_memory": "16934494208",
"node.attr.ml.max_open_jobs": "20",
"node.attr.transform.node": "true",
"node.attr.xpack.installed": "true",
"node.name": "es-source-node",
"path.home": "E:\\installations\\es_tools\\elasticsearch-7.8.0-windows-x86_64\\elasticsearch-7.8.0",
"path.logs": "E:\\installations\\es_tools\\elasticsearch-7.8.0-windows-x86_64\\elasticsearch-7.8.0\\logs",
"transport.features.x-pack": "true",
"transport.type": "security4",
"transport.type.default": "netty4"
}
将数据目录梳理成树形结构如下所示:
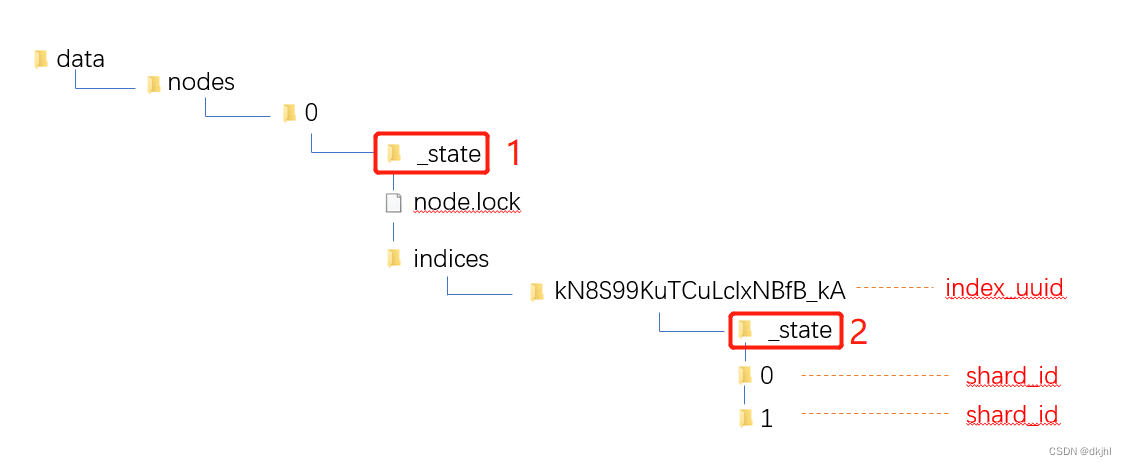
上面图片中的0/1就是所谓的分片,分片是一个物理概念,对应节点上的一个具体路径;其中分片0/1中也保存当前分片是主分片还是副本分片信息
分片分配就是把一个分片分配到集群中某个节点的过程。分配决策由主节点完成,分片决策包含两个方面
对于新建索引和已有索引,分片分配过程不同;ES通过allocators和deciders两个组件完成分配工作;其中allocator尝试寻找最优节点分配分片,deciders负责判断并决定是否要进行这次分配
对于新建索引(分配)
对于已有索引
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我有一个Controller,我想为这个Controller创建一个助手,我可以在不包含它的情况下使用它。我尝试像这样创建一个与Controller同名的助手classCars::EnginesController我创建的助手是moduleCars::EnginesHelperdefcheck_fuellogger.debug("chekingfuel")endend我得到的错误是undefinedlocalvariableormethod`check_fuel'for#有没有我遗漏的约定? 最佳答案 如果你真的想在Controll
我有一个模块stat存在于目录结构中:lib/stat_creator/stat/在lib/stat_creator/stat.rb中,我在lib/stat_creator/stat/目录中有我需要的文件,以及:moduleStatCreatormoduleStatendend当我使用该模块时,我将这些类称为StatCreator::Stat::Foo.new现在我想要一个存在于应用程序中的根Stat类。我在app/models中制作了我的Stat类,并在routes.rb中进行了设置。但是,如果我转到Rails控制台并尝试在应用程序/模型中使用Stat类,例如:Stat.by_use
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Testingmodulesinrspec目前我正在使用rspec成功测试我的模块,如下所示:require'spec_helper'moduleServicesmoduleAppServicedescribeAppServicedodescribe"authenticate"doit"shouldauthenticatetheuser"dopending"authenticatetheuser"endendendendend我的模块位于应用程序/服务/services.rb应用程序/服务/app_servi