以下内容对loadrunner进行一个初识,让之后运用更加熟练,咱们这里用的是loadrunner自带的WebTours平台,他是不含数据库的。


当第一次脚本跑出来后进行脚本的升级维护的一些操作如下,包括参数化设置:
其实参数化的方式有很多种,这里简述自己常用的方式。其实方式略有不同,但其结果都是将数据添加进来。
1、编辑数据
菜单【Vuser】—【Parameter List…】,点击new就会创建出一个参数NewParam。创建后,点击Create Table 会出现表格,在表格,再次点击【Edit with Notepad】 ,然后会打开一个记事本,我们可以对记事本进行添加数据。
2、添加dat数据文件
点击File path输入框后面的“Browse…”按钮,找到本地的txt数据文件(记住这个txt文件保存后要修改成dat文件,否则无法找到),进行添加就可以了。
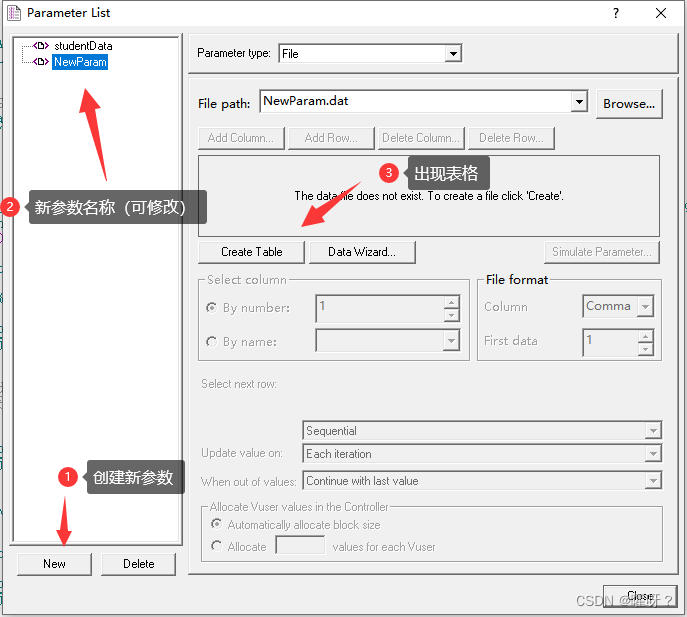
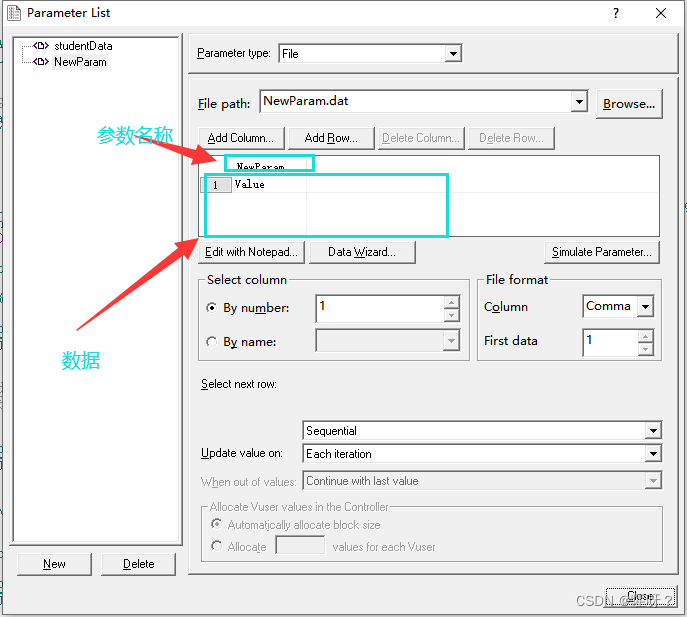
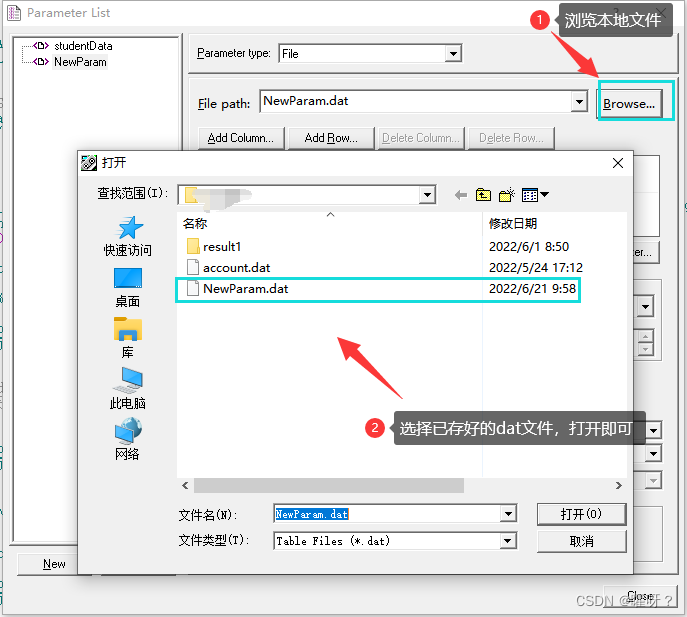
添加后的数据展示
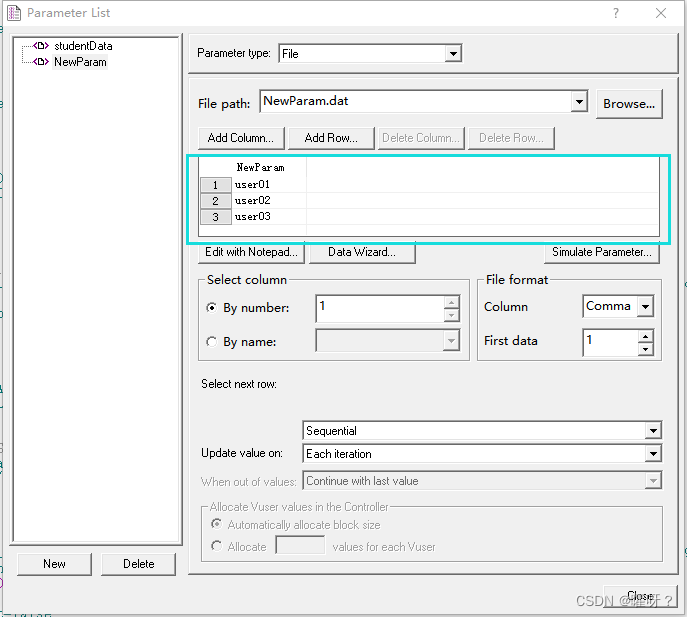
需要注意的是,文件里面的数据不要乱写,每条数据一行,不然会读取有误。这个文件如果需要构造大量的数据,可以用表格或者Python自动化写入文件的方式进行操作。在记事本中编辑参数数据时,数据文件一定要以一个空行结束,否则,最后一行输入的数据不会被参数所使用(也有可能会报错)。表格上最多展示一百条数据,超过一百条就看不到了(数据还在,只是看不到)。
选中要参数化的内容。
注:Parameter name默认会显示NewParam,如果已经有参数化,则需要在下拉按钮进行选择已参数化的Parameter name
方法一,右键参数—【Replace with a new parameter】
方法二,菜单【insert】----【new Parameter…】
两个方法的框都是一样的
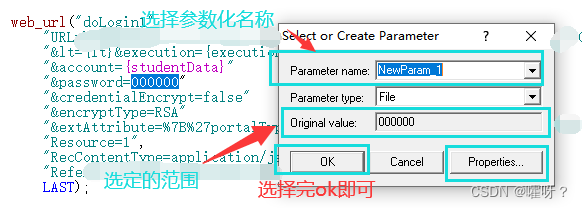
想进行详细设置的就点击上图弹出框右下角的Properties…(Parameter Properties),就会弹出以下这个框框
Parameter Properties (参数属性对话框)----我们的参数化设置就通过这个对话框完成
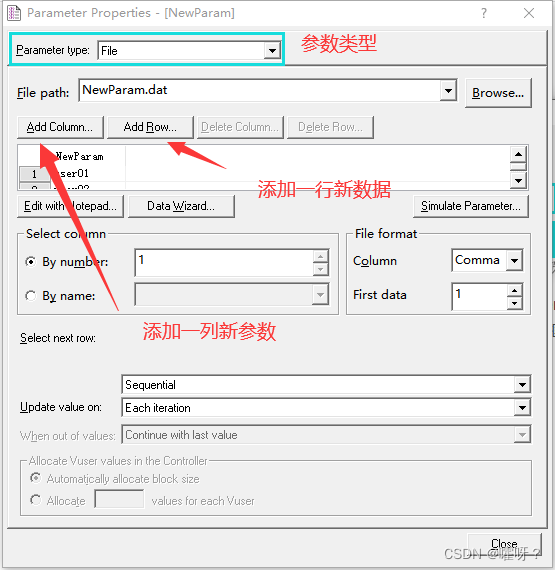
脚本设置完参数化,脚本运行的每一遍所取的参数化的值都不一样,那么这个值按照个什么情况来取呢?会有很多种方式
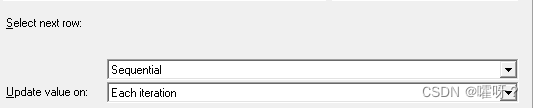
Select next row【选择下一行】:

①顺序(Sequential):按照参数化的数据顺序,一个一个的来取。
②随机(Random):参数化中的数据,每次随机的从中抽取数据。
③唯一(Unique):为每个虚拟用户分配一条唯一的数据。

①每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
②每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
③只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)。
注:先不考虑【When out of values】和【Allocate Vuser values in the Controller】,那就是有9种取值方式;
举例说明下仅在VuGen下的取值方式:回放脚本时可以设置迭代次数,在VuGen中迭代(迭代次数设置:菜单【Vuser】—【Run-time Settings】—【General】中的Run Logic,Number of lterations设置迭代次数),可以理解为只有一个用户重复操作了N次(N表示你设置的迭代次数)。假设设置迭代次数为3次,参数如下:
此时,取值方式的规则如下:
参考地址:https://blog.csdn.net/gaofengyan/article/details/90903814
前提:

Unique的的作用是将参数分给多个压测用户,使得每个用户间拿到唯一的参数范围。
至于每个用户在拿到属于自己的参数范围后怎么用,那就是以下的几种组合了:
前提:依然假设6个参数,启动2个用户,压测2分钟;
Unique & iteration & Automatically allocate block size,则:
vuser1 获得的参数范围是:【test01、test02、test03】;
vuser2 获得的参数范围是:【test04、test05、test06】;
此时when out of values会点亮,它又有三个选项,那它是什么意思呢?
它的意思是:举个例子,假如你这个脚本15s就能跑完一次,那么压测2min,不间断的跑,你能跑8次,但是每个vuser就分到了3个参数,(拿vuser1举例)当vuer1第三次迭代时取的是test03(vuser2跑到第三次时取的test06),当到进行第4次迭代时,参数不够了那怎么办呢?此时这个选项就是干这个的,为你定制规则,它有三个选项,即:
当Unique & Each occurrence时,只能选择Allocate ____values for each Vuser了,其余的逻辑都一样。
当Unique & Once时,说白了,在参数满足的情况下,每个用户只取一个,每个用户在压测时间内都只会用一个参数进行迭代,直至结束。如此例6个参数,压测2分钟,假如我启动了6个vuser,则每个vuser得到一个参数,vuser1取得test01,持续迭代2分钟,并且只用这个test01。假如我设置7个vuser,启动后你会发现实际只启动了6个vuser,报错了一个,因为参数不够分了。所以你的参数的数量最好不小于并发vuser数量。
参考地址:https://www.cnblogs.com/lianggaobo/p/15724566.html
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option