一、生产者消费者模式
生产者消费者模式是一种用于解决多个模块之间数据通信问题的高效机制。通过在数据生产者和数据消费者之间设立数据缓冲区,实现地低耦合度的数据通信。
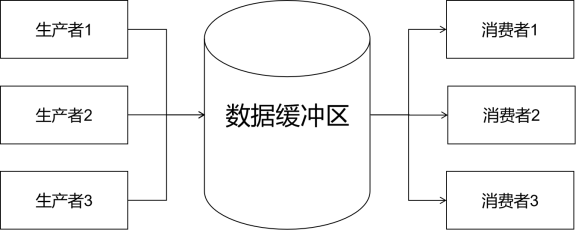
图1 生产者/消费者模式的结构
这样的一个结构就像是流水线上两道工序和他们之间的货架。前道工序上有若干工人,他们会将本工序的产品放到货架上,而后立即回归到自己的生产工作中;同样地,后道工序上的若干工人们,可以直接从货架上收取上道工序的产品,直接开始自己的生产工作。
相比于直接调用的数据通信方式,生产者/消费者模式虽然多了一个数据缓冲区,但是优势也非常明显:
1. 支持模块并发
使用直接调用的通信方式,最明显的弊端就是,调用关系是阻塞的,调用者必须中断自己的任务,等待被调者的返回再继续执行,这样就大大降低了程序运行效率。特别是当被调用的模块中涉及网络通信、文件读写这样的耗时操作时,主调一直在阻塞等待将是不可接受的性能损失。使用生产者/消费者模式,生产者模块(也就是原先的主调函数)只需要将数据放进缓冲区,这一个周期的任务就完成了,它可以立即返回,去执行下一个周期的任务。同样的,消费者模块(对应原先的被调函数)也不必苦苦等待上一个流程的结束,只要数据缓冲区不是空的,他就可以立即开始消费操作。
2. 支持忙闲不均
在很多业务场景中,数据生产者的生产速度和数据消费者的消费速度有可能在一定范围内波动,如果使用直接调用的方式,则无论主调侧还是被调侧进入忙碌状态,两侧都必须将速度减慢,来协调数据同步的速度。而如果通过数据缓冲区进行交互,某一方进入忙碌状态时,可以利用缓冲区中的数据或空间进行调节(如消费者处理速度放缓,则生产者也不必随之减缓速度,产生数据可以利用缓冲区中剩余的部分存储)。
同样也可以对应到流水线的例子里,如果前道工序的工人去一趟洗手间,如果采用的是直接交接产品的方式,那么后道工序的工人也就不得不暂时停工了;而如果双方通过货架交接,那么前道工序的工人离开的这段时间,货架上的产品也足够后道工序工人来操作了。
3. 降低耦合程度
如果使用直接调用的方式,如果未来双方任何一边代码改变(如收发数据的频率和数据单元大小改变),则双方的代码都需要变化。而在生产者/消费者模式中,如果一方的数据存取方法变化,只需要将他使用缓冲区的部分即可。
对应到流水线的例子里,如果后道工序上来了个新人,新人有自己的干活节奏,习惯一次拿两块零件,那前道工序的人还得改变自己的节奏,做好两块在给隔壁送过去;而如果两边通过货架交接,不管隔壁的人是什么工作习惯,都可以根据自己的想法从货架上取任意个零件,前道工序的生产节奏不需要进行任何的调整。
二、环形缓冲区结构
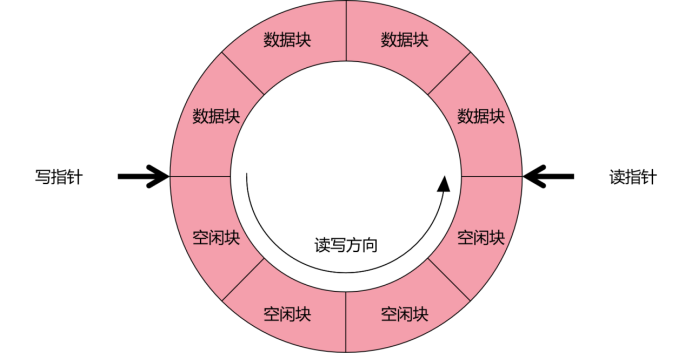
图2 环形缓冲区的结构
环形缓冲区使用两个指针分别用于读操作和写操作,两者以相同的方向转动,就像在操场上相互竞逐的两个人一样。读指针身前写指针身后,这部分为数据区块,这部分区域的状态为可读不可写;而写指针身前读指针身后,这部分为空闲区块,这部分区块的状态为可写不可读。当写指针追上读指针时,缓冲区满,需要写指针暂停写入;而当读指针追上写指针时,缓冲区空,需要读指针暂停读取。
相比于普通的队列结构(FIFO),环形缓冲区的所有读写操作都在一个相对固定的存储区域内完成,这样如果程序涉及频繁的读写,就可以省去大量的空间申请释放操作。
三、环形缓冲区在生产者消费者模式中的应用(代码实现)
以下代码在linux环境下编译运行,其他环境可能会略有不同。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <semaphore.h>
#include <pthread.h>
#define SIZE 10
int product_idx = 0; //生产者指针
int consume_idx = 0; //消费者指针
int data = 0;
int ring[SIZE]; //环形缓冲区
sem_t blankSem; //控制空闲块的信号量
sem_t dataSem; //控制数据块的信号量
pthread_mutex_t product_lock = PTHREAD_MUTEX_INITIALIZER; //各生产者之间的互斥锁
pthread_mutex_t consume_lock = PTHREAD_MUTEX_INITIALIZER; //各消费者之间的互斥锁
pthread_t product_1_tid, product_2_tid, consume_1_tid, consume_2_tid;
void* product_1(void *arg) //生产者线程1
{
while(1)
{
pthread_mutex_lock(&product_lock); //抢占生产者互斥锁
sem_wait(&blankSem); //获取一个空闲块资源
ring[product_idx] = data++;
sem_post(&dataSem); //释放一个数据块资源
printf("product_1 put data : %d\n",ring[product_idx++]);
product_idx = product_idx%SIZE; //环形缓冲区的寻址方法
pthread_mutex_unlock(&product_lock); //释放生产者互斥锁
sleep(1);
}
return NULL;
}
void* product_2(void *arg) //生产者线程2
{
while(1)
{
pthread_mutex_lock(&product_lock);
sem_wait(&blankSem);
ring[product_idx] = data++;
sem_post(&dataSem);
printf("product_2 put data : %d\n",ring[product_idx++]);
product_idx = product_idx%SIZE;
pthread_mutex_unlock(&product_lock);
sleep(1);
}
return NULL;
}
void* consume_1(void *arg) //消费者线程1
{
int consume_data = 0;
while(1)
{
pthread_mutex_lock(&consume_lock); //抢占消费者互斥锁
sem_wait(&dataSem); //获取一个数据块资源
consume_data = ring[consume_idx];
sem_post(&blankSem); //释放一个空闲块资源
printf("consume_1 get data : %d\n",consume_data);
sleep(1);
consume_idx++;
consume_idx = consume_idx%SIZE; //环形缓冲区的寻址方法
pthread_mutex_unlock(&consume_lock); //释放消费者互斥锁
sleep(2);
}
return NULL;
}
void* consume_2(void *arg) //消费者线程2
{
int consume_data = 0;
while(1)
{
pthread_mutex_lock(&consume_lock);
sem_wait(&dataSem);
consume_data = ring[consume_idx];
sem_post(&blankSem);
printf("consume_2 get data : %d\n",consume_data);
sleep(1);
consume_idx++;
consume_idx = consume_idx%SIZE;
pthread_mutex_unlock(&consume_lock);
sleep(2);
}
return NULL;
}
int main()
{
sem_init(&blankSem, 0, SIZE); //初始化信号量
sem_init(&dataSem, 0, 0);
int ret = 0;
ret = pthread_create(&product_1_tid, NULL, (void *) product_1, NULL); //创建线程
if (ret) {
printf("pthread_create product_1 error\n");
exit(0);
}
ret = pthread_create(&product_2_tid, NULL, (void *) product_2, NULL);
if (ret) {
printf("pthread_create product_2 error\n");
exit(0);
}
ret = pthread_create(&consume_1_tid, NULL, (void *) consume_1, NULL);
if (ret) {
printf("pthread_create consume_1 error\n");
exit(0);
}
ret = pthread_create(&consume_2_tid, NULL, (void *) consume_2, NULL);
if (ret) {
printf("pthread_create consume_2 error\n");
exit(0);
}
pthread_join(product_1_tid, NULL); //让主线程等待各个子线程结束
pthread_join(product_2_tid, NULL);
pthread_join(consume_1_tid, NULL);
pthread_join(consume_2_tid, NULL);
sem_destroy(&blankSem); //销毁信号量
sem_destroy(&dataSem);
}
代码编译运行之后,运行效果如下图所示:
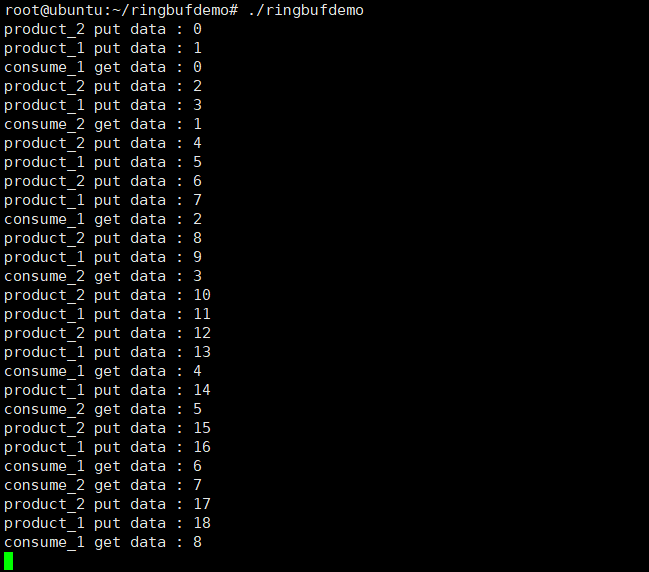
图3 demo程序的运行效果
可以看到生产者产生的数始终大于消费者取到的数,而且也不会比消费者的数大10,这体现了生产者的指针既不能被消费者超过,也不能把消费者套圈。
四、定速生产者模式下的设计思想
生产者/消费者模式中非常重要的一个原则是,需要时刻监控缓冲区的状态,当缓冲区满时,就要让生产者停止生产操作;而当缓冲区空时,就要让消费者停止消费操作。
然而在实际开发中,可能会出现生产者或消费者某一方是一个定速的状态(比如,生产者是一个数据采集模块,他采集的数据需要一个不少的被消费掉)。这种情况下流水线的例子好像就不适用了,我们可以用一个新的具象模型:天花板漏水。
天花板以固定的速度向地板漏水,地上放了一个小水桶,住户偶尔会从卧室里出来一趟把水倒掉。这里,天花板漏水充当生产者,住户是消费者,而这个小水桶就是二者之间的缓冲区。在这种情况下,生产者以固定的速度不间断的产生数据,而即便缓冲区满,他也不会停止滴水,那这种情况下要如何保护缓冲区不发生溢出呢?我的想法是,给缓冲区再加一个缓冲区,也就是在水桶下面再放个盆。实际开发中使用的是读写文件的方式,缓冲区满就去写文件。这样的话消费者策略也要变更为缓冲区非空时读缓冲区,缓冲区空时读文件。
落实到代码层面上,可以考虑使用sem_trywait(sem_t *sem)替代sem_wait(sem_t*sem)。当sem_wait想要获取的资源量为0时,线程会一直阻塞在这里等待其他线程释放该资源,而sem_trywait则不会等待,当资源量为0时,也会继续向下执行,通过返回值来判断是否成功获取了该资源,获取成功返回0,并将信号量减1;获取失败返回-1,信号量不变。
这样我们可以将上文中的生产者消费者代码做如下修改:
void* product(void *arg) //生产者线程
{
while(1)
{
pthread_mutex_lock(&product_lock); //抢占生产者互斥锁
if (sem_trywait(&blankSem) != 0) //非阻塞尝试获取一个空闲块资源
{
/* 此处补充写文件代码 */
}
else //获取成功
{
ring[product_idx] = data++;
sem_post(&dataSem); //释放一个数据块资源
printf("product_1 put data : %d\n",ring[product_idx++]);
product_idx = product_idx%SIZE;
}
pthread_mutex_unlock(&product_lock); //释放生产者互斥锁
sleep(1);
}
return NULL;
}
void* consume(void *arg) //消费者线程
{
int consume_data = 0;
while(1)
{
pthread_mutex_lock(&consume_lock); //抢占消费者互斥锁
if (sem_trywait(&dataSem) != 0) //非阻塞尝试获取一个数据块资源
{
/* 此处补充读文件代码 */
}
else //获取成功
{
consume_data = ring[consume_idx];
sem_post(&blankSem); //释放一个空闲块资源
printf("consume_1 get data : %d\n",consume_data);
sleep(1);
consume_idx++;
consume_idx = consume_idx%SIZE;
}
pthread_mutex_unlock(&consume_lock); //释放消费者互斥锁
sleep(2);
}
return NULL;
}
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc