目录
上篇文章:YOLOv7(目标检测)入门教程详解---环境安装 我们将yolov7外部需要的环境已经全部安装完成,那么这篇文章我们直接进行yolov7的实战----检测,推理,训练。
点击Code,Download ZIP 把yolov7的源码包下载下来
 下载好后打开yolov7源码包
下载好后打开yolov7源码包
在文件路径输入cmd进入终端
 之后在终端activate进入之前创建的环境,并且输入
之后在终端activate进入之前创建的环境,并且输入
pip install -r requirements.txt强调:关掉电脑VPN

pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple,输入这个指令可能会更快一点
我是之前安装过后,所有再输入安装指令后就会显示全部满足,你们也可以通过这样查看自己是否安装成功
此时我们来到官网下载权重,一个是Test用的yolov7.pt
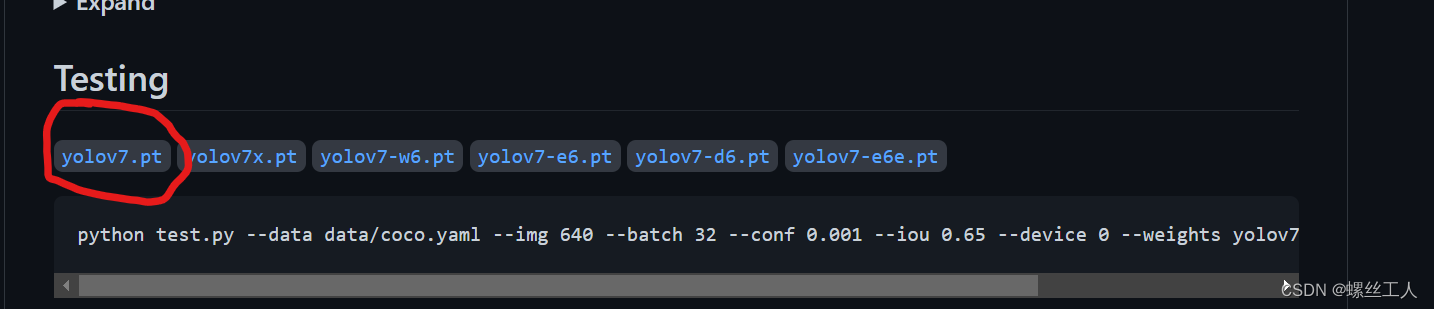
一个是之后 Train 用的yolov7_training.pt

在yolov7的文件夹路径下建一个weights文件夹,然后把刚刚下载好的两个权重放进去。
此刻基本需要的环境和文件都已经准备完成了,接下来我们就可以进行detect(检测了)
进入虚拟环境,输入以下指令
python detect.py --weights weights/yolov7.pt --source inference/images
--weights 指令就是代表权重 --source 是照片存在的路径
检测过程如下
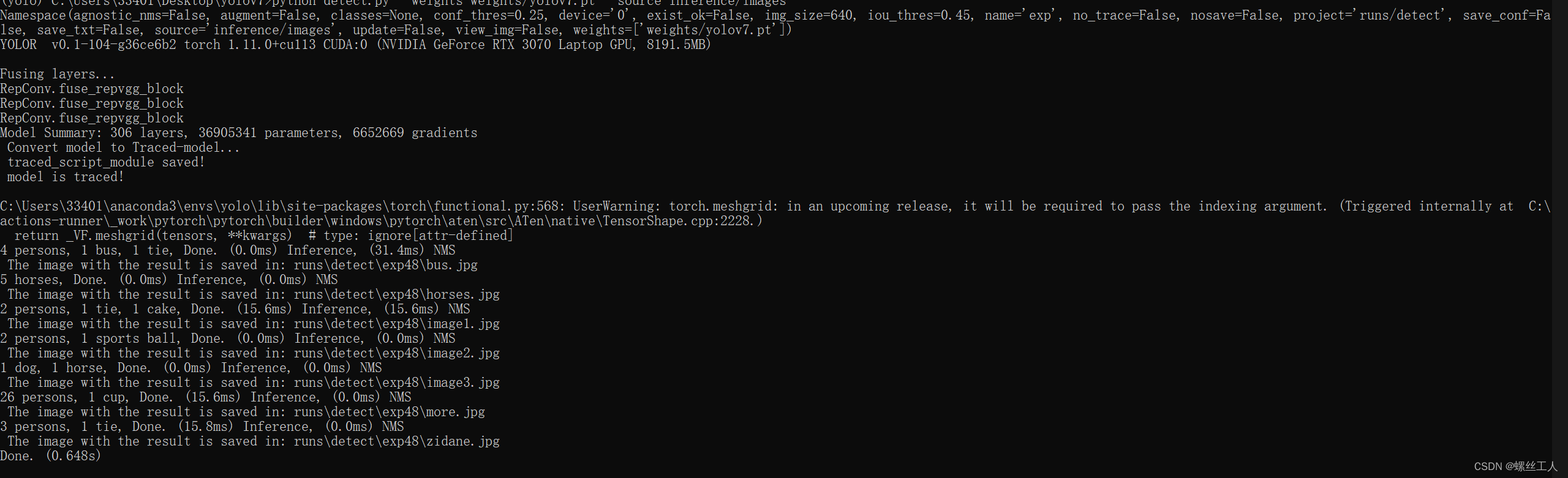
这里可以使用GPU和CPU两种方式进行检测,因为我们之前装了cuda和cudnn所以可以用GPU
只不过我们需要输入--device 0 这个指令,不输入则默认为CPU,我是改了detect源码里面的指令
还有更多操作,我们可以打开detect.py进行查看
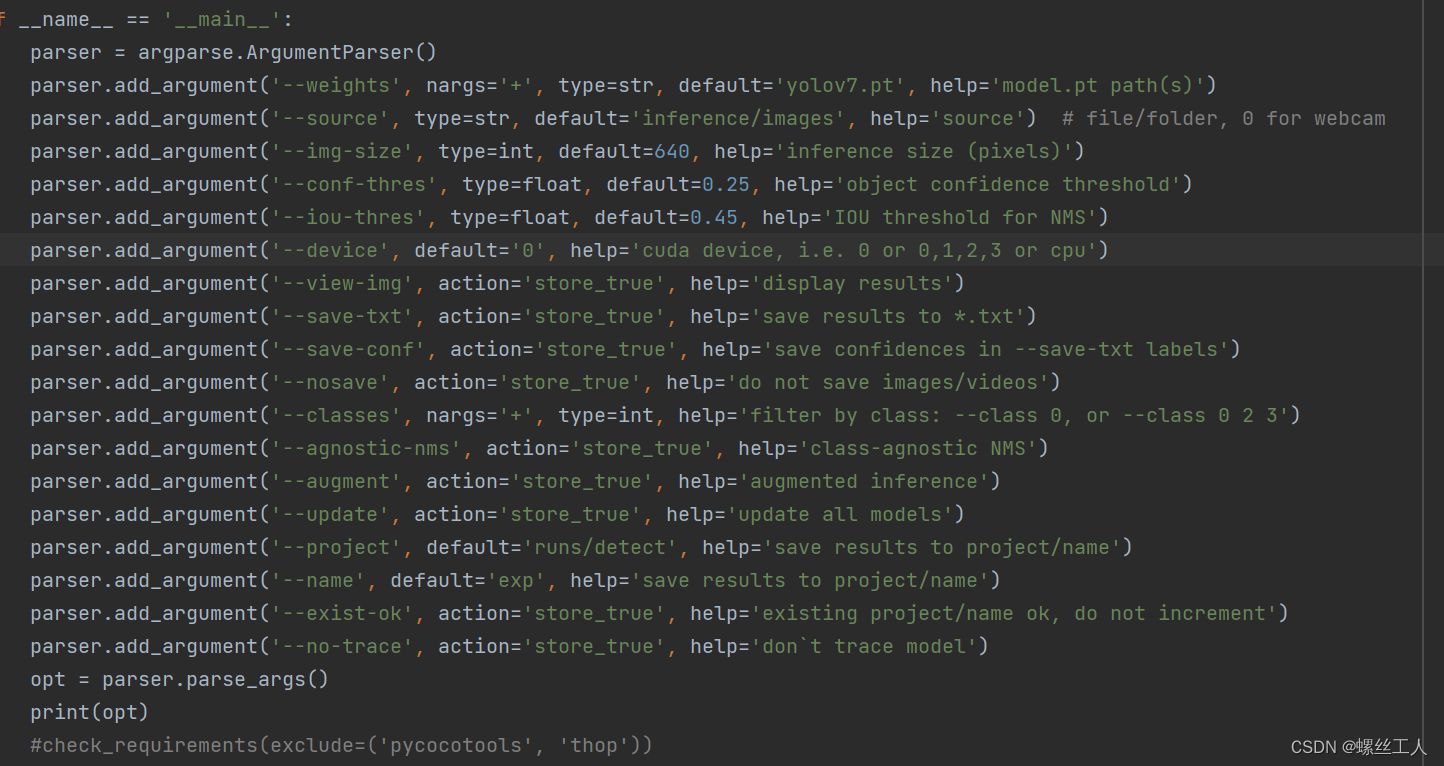
如果你只有cpu就默认cpu,如果是一个gpu就选择--device 0 两块cpu就--deivce 1,以此类推。
我们来看看我们训练之后的结果,进入runs-->detect-->exp 里面有所有预测好的照片
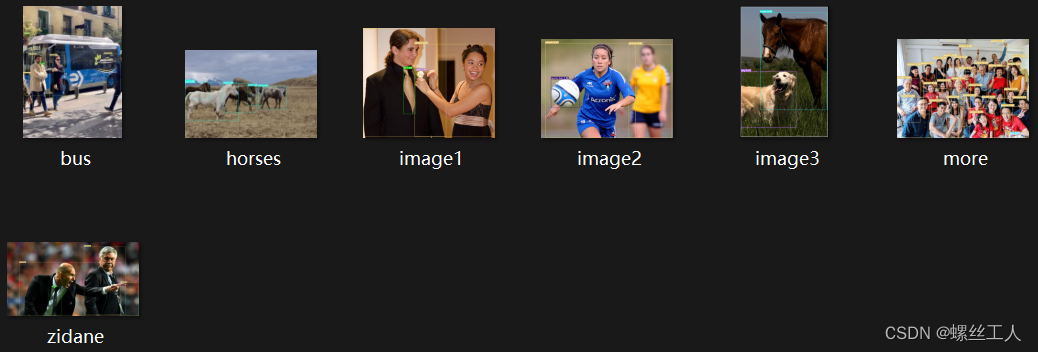

参考博客:【小白教学】如何用YOLOv7训练自己的数据集 - 知乎
我们生成/datasets/文件夹,把数据都放进这个文件夹里进行统一管理。训练数据用的是yolo数据格式,不过多了两个.txt文件,这两个文件存放的,是每个图片的路径,后面会具体介绍。
那么接下来yolo数据集的整体格式如下:
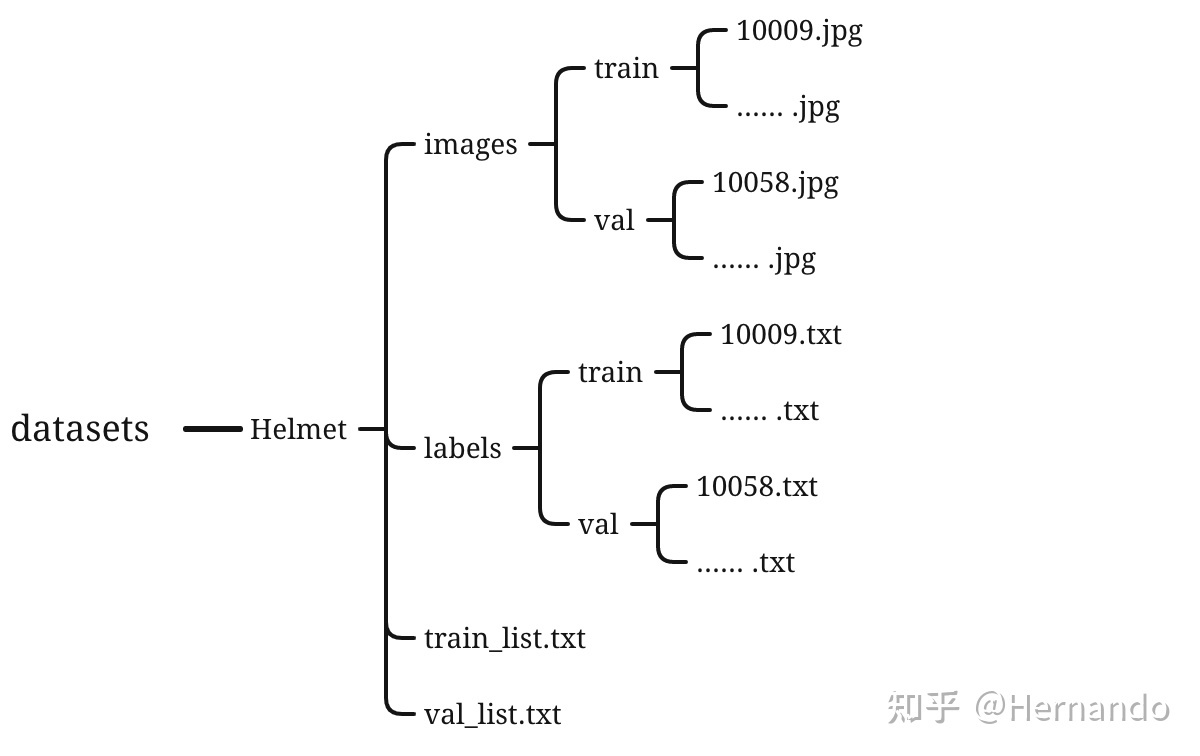
Helmet是你想检测的东西名称,我检测的是圆环所以命名为circle

进入circle文件夹之后,会看到有images 和labels的文件夹,一个是拿来放图片的,一个是拿来存images文件夹中处理jpg图片之后的txt数据
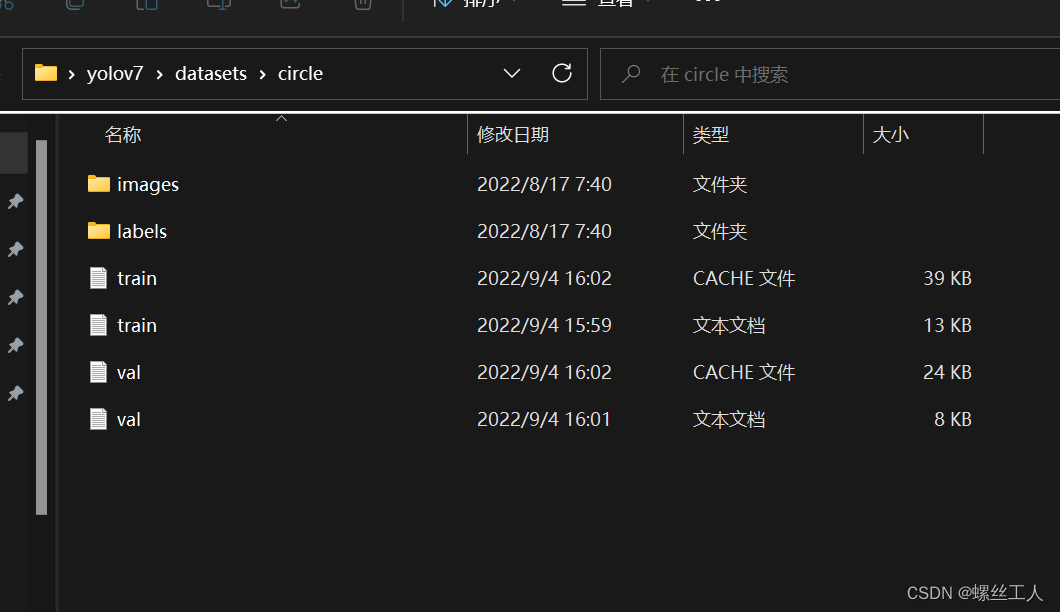
打开images文件夹,我们又要建两个文件夹:train 和 val,并且把想要训练的照片放进去,两个都放差不多数量
 打开labels文件夹,同样建两个文件train和val,然后就ok了
打开labels文件夹,同样建两个文件train和val,然后就ok了
接下来我们就要用到一个软件去处理我们的图片,将其转化为yolo格式
参考博客:labelImg使用教程_G果的博客-CSDN博客_labelimg
进入终端,输入指令进行下载
输入labellmg打开软件
 然后我们使用labellmg进行对图片的处理,首先open dir选择图片路径,我们先选择刚刚创建的datasets/circle/images/train 然后change save dir选择datasets/circle/labels/train,这样我们对image的每张图片的处理都会储存进label中 之后val也是同理。
然后我们使用labellmg进行对图片的处理,首先open dir选择图片路径,我们先选择刚刚创建的datasets/circle/images/train 然后change save dir选择datasets/circle/labels/train,这样我们对image的每张图片的处理都会储存进label中 之后val也是同理。
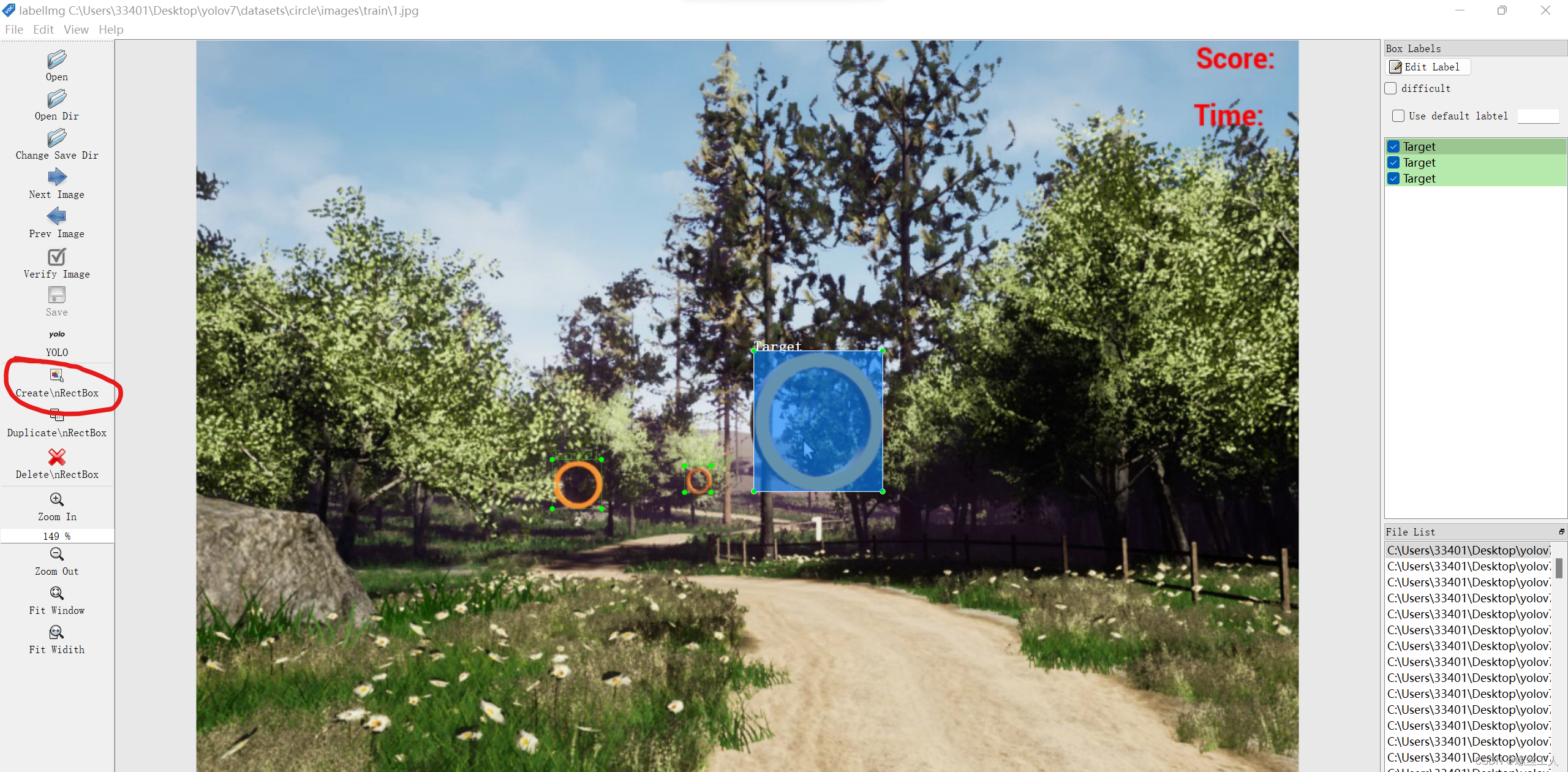
之后就把每一个你想训练的目标给框出来然后进行命名,但是必须要改成YOLO格式
之后打开我们的labels就能发现里面储存了images中每张图片对应的txt文件
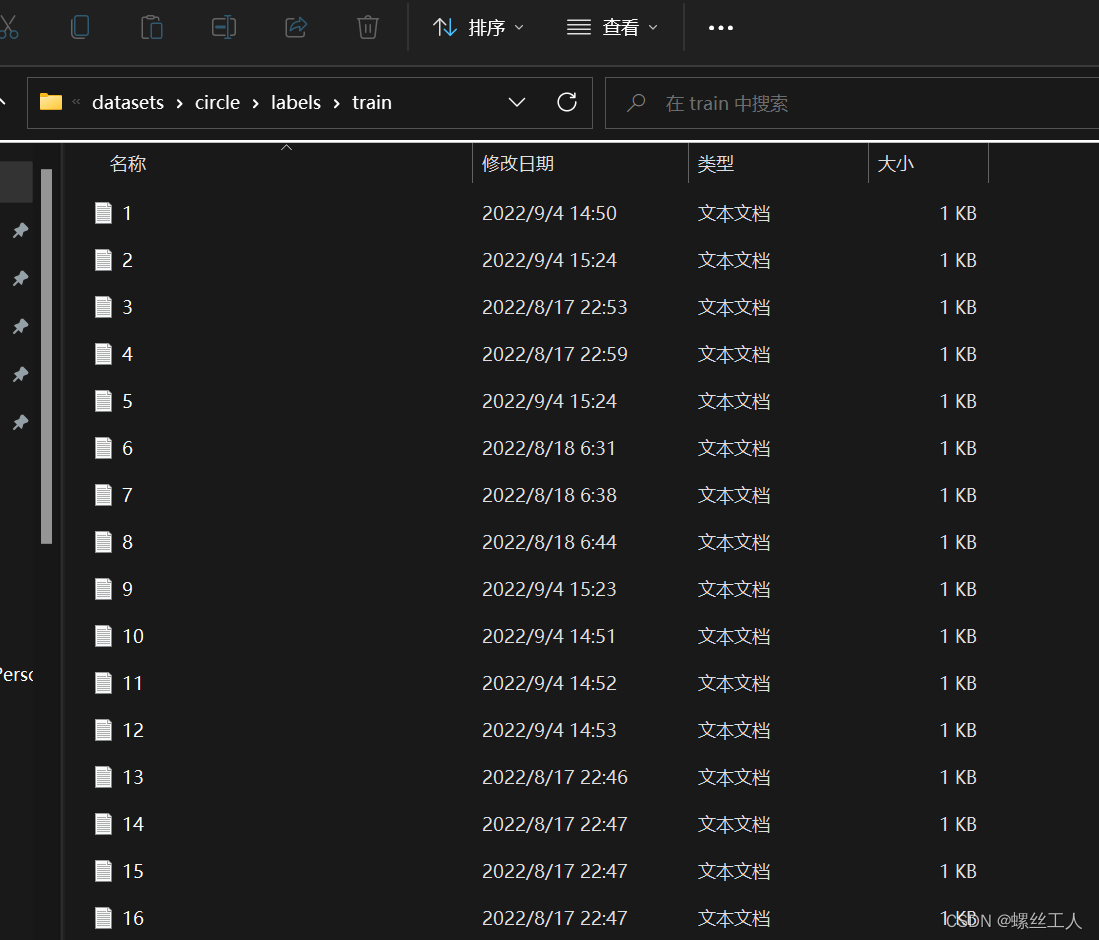
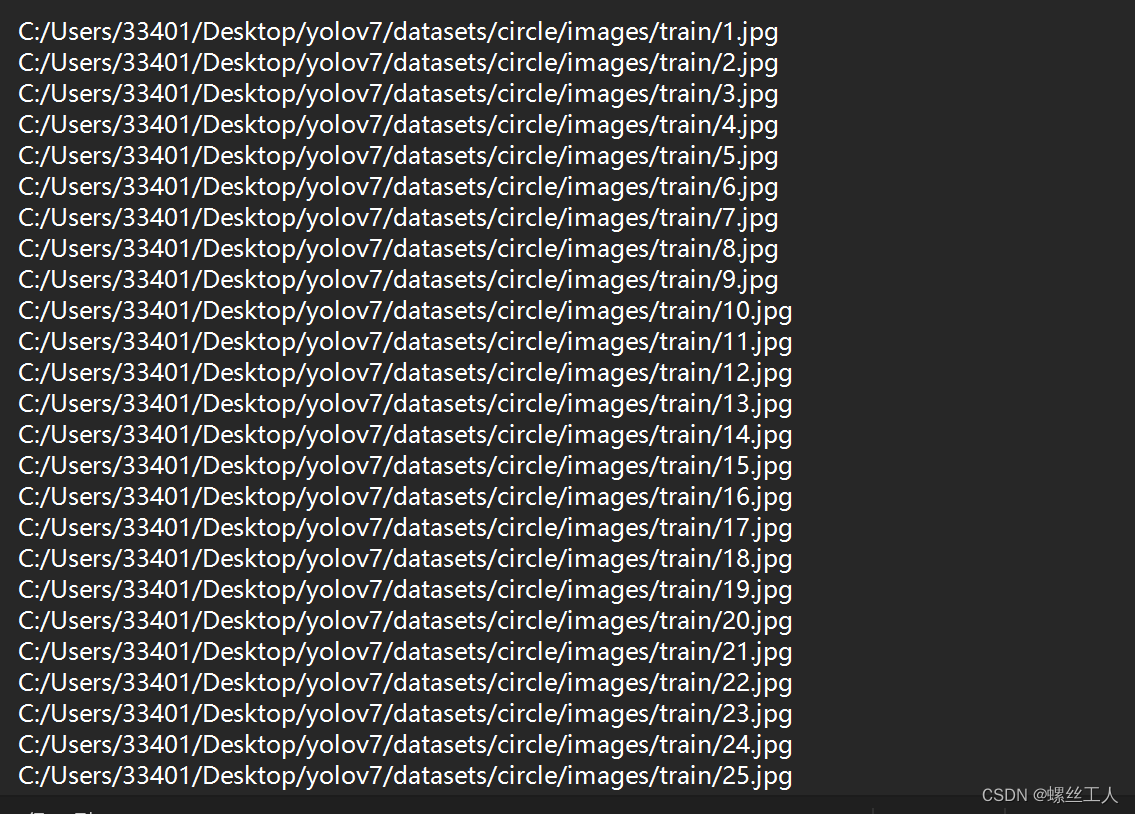
然后我们进入datasets/circle文件夹下面,建立两个txt文件,train.txt val.txt,这两个文件分为写入所有images中train和val中的照片路径
总共有两个文件需要配置,一个是/yolov7/cfg/training/yolov7.yaml,这个文件是有关模型的配置文件;一个是/yolov7/data/coco.yaml,这个是数据集的配置文件。
第一步,复制yolov7.yaml文件到相同的路径下,然后重命名,我们重命名为yolov7-Helmet.yaml。
第二步,打开yolov7-circle.yaml文件,进行如下图所示的修改,这里修改的地方只有一处,就是把nc修改为我们数据集的目标总数即可。然后保存。

第一步,复制coco.yaml文件到相同的路径下,然后重命名,我们命名为circle.yaml。
第二步,打开circle.yaml文件,进行如下所示的修改,需要修改的地方为5处。第一处:把代码自动下载COCO数据集的命令注释掉,以防代码自动下载数据集占用内存;第二处:修改train的位置为train.txt的路径;第三处:修改val的位置为val.txt的路径;第四处:修改nc为数据集目标总数;第五处:修改names为数据集所有目标的名称。然后保存。
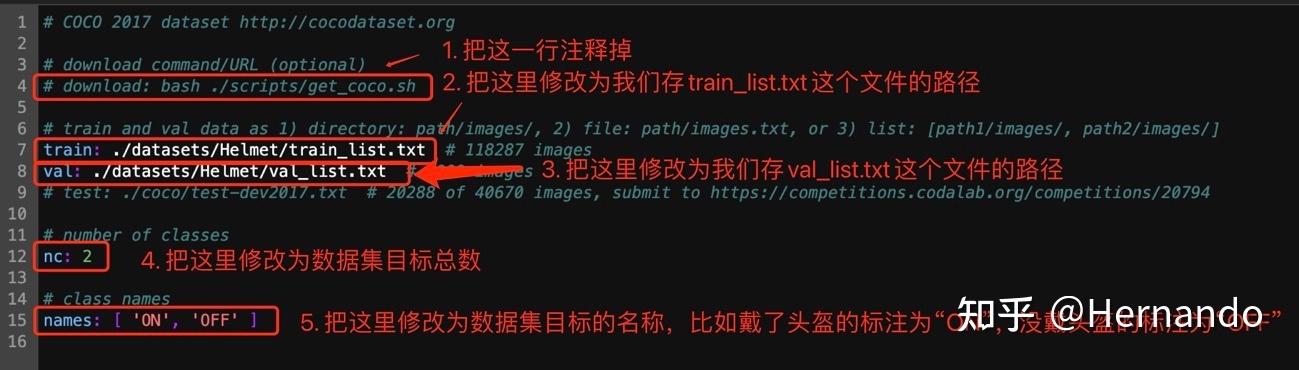
我的参照上图改好如下
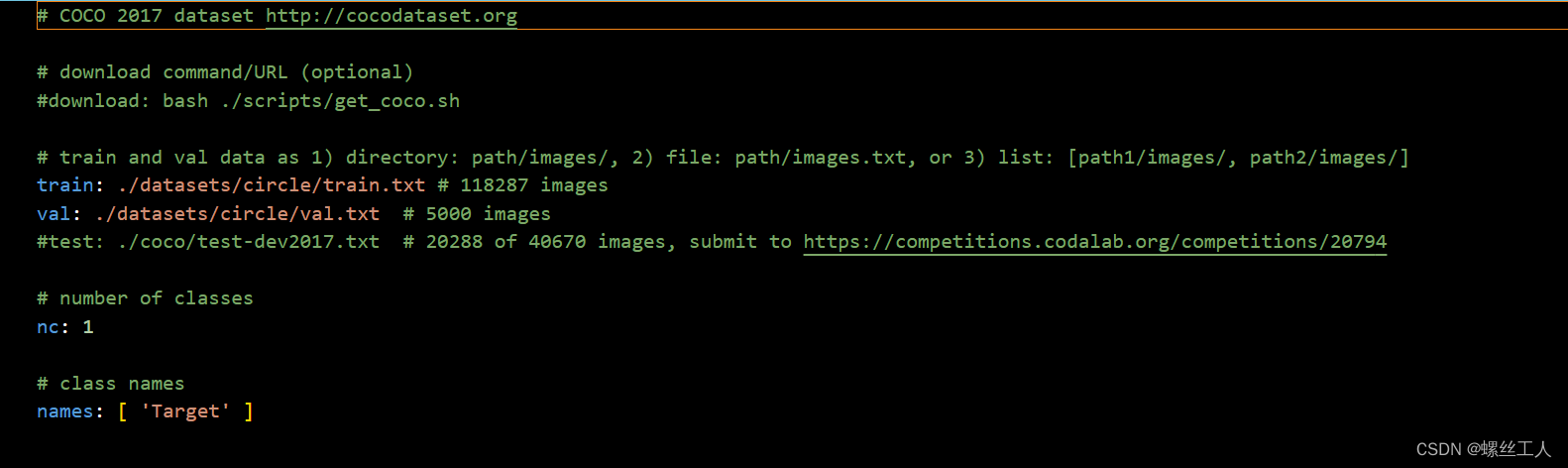
之后我们就可以进行训练了!!!
此时我们在yolov7文件夹路径下cmd,并且进入虚拟环境,输入指令
python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-circlr.yaml --data data/circlr.yaml --device 0 --batch-size 8 --epoch 300
这里对里面的参数进行解释
--cfg 接受模型配置的参数
--data 接收数据配置的参数
--device 0 训练类型,我是一块GPU 所以用0
--batch-size 8 GPU内存大小决定
--epoch 训练次数,建议300
--weights 训练的权重
训练到最后我们就会得到一个last 和best的pt文件,那么我们直接把best.pt拿出来使用就ok了
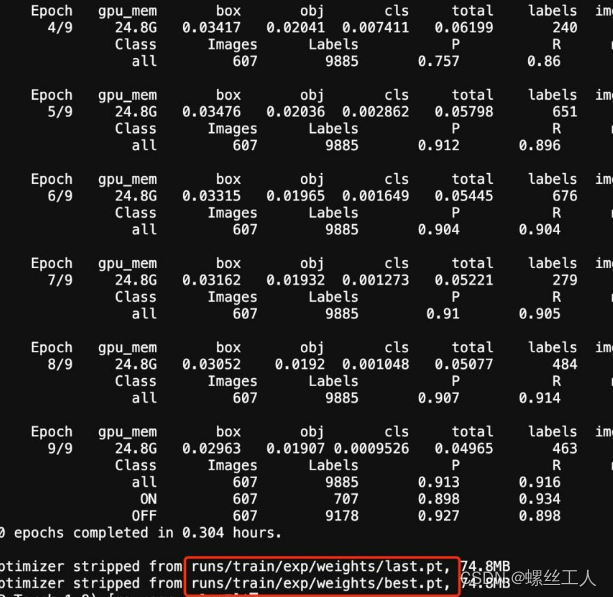
我们已经获得了自己训练出来的权重了,那么这个时候推理,其实跟之前检测的道理是一样的,唯一变换的就是我们的权重文件和自己检测的照片 。
这个时候我们在datasets文件夹下面建立一个textimages文件夹和textvideo文件夹,分别用来储存要被检测的图片和视频
跟detect一样,进入虚拟环境输入权重路径和图片路径就ok了,指令如下
我是把best.pt直接拉到了yolov7文件夹路径下面,你们刚刚训练出来的在runs/train/circle/weights/best.pt
python detect.py --weights best.pt --source datasets/textimages --device 0
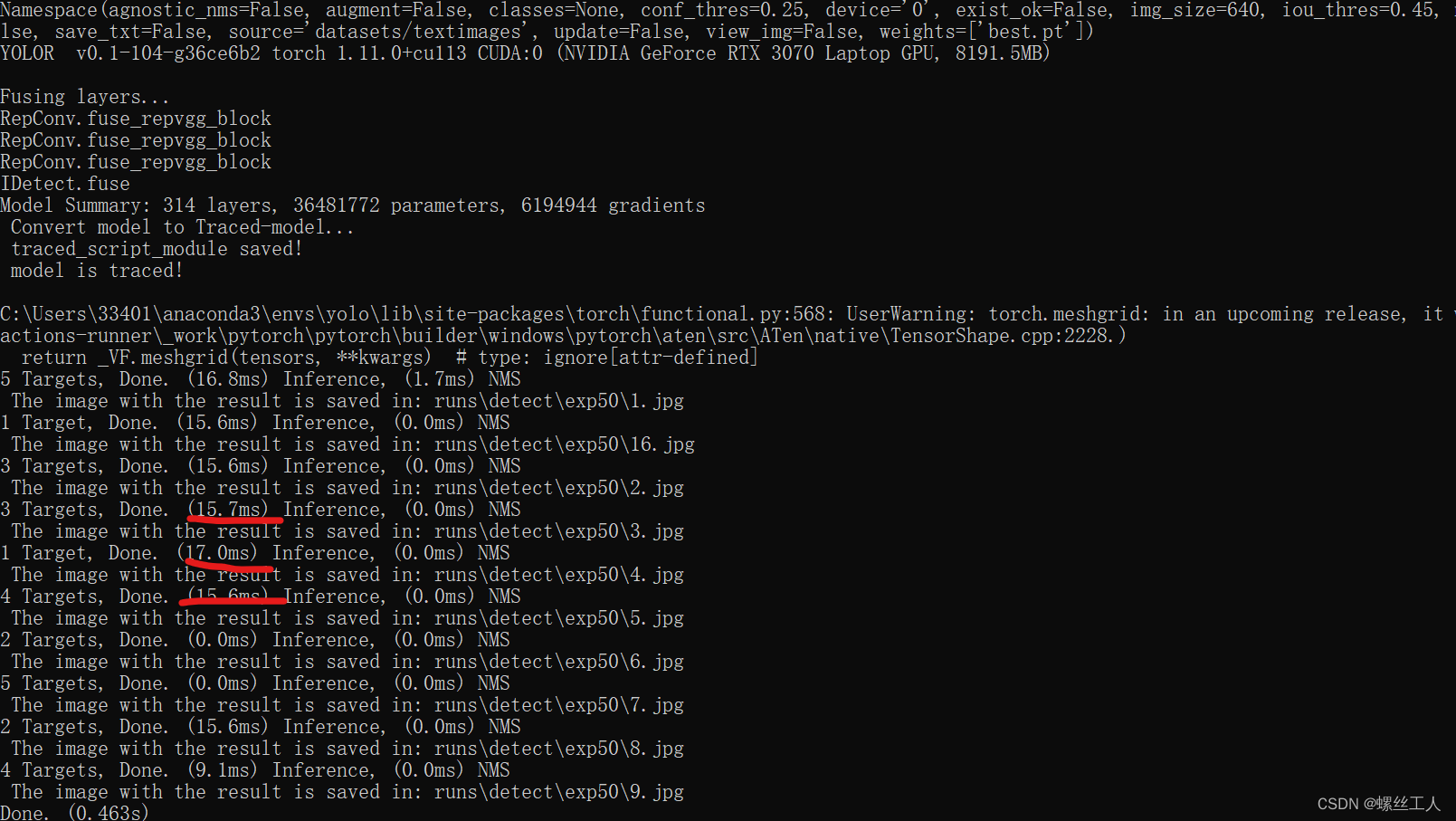
可以看到用gpu训练的yolov7是相当的快,我显卡是3070的,大概一张照片15ms左右的样子,如果用CPU的话,速度要慢十倍左右
我打开runs/detect/exp查看我们的训练效果


可以说效果是非常好的,方框上面的数值就是置信度了,只要训练的好,yolov7的处理能力非常的强大。
那么yolov7的检测,训练,推理的全部流程都已经可以实现了,但是这个是基于python环境下的,如果有特殊的需求需要在c++环境下去进行yolo检测的话,那就又另有一方折腾了,我会在之后的博客中说到如何在c++中去使用yolov7检测。
有相关问题可以私信我进行讨论
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe