Redis是典型的单线程架构,所有的读写操作都是在一条主线程中完成的。当Redis用于高并发场景时,这条线程就变成了它的生命线。如果出现阻塞,哪怕是很短时间,对于我们的应用来说都是噩梦。导致阻塞问题的场景大致分为内在原因和外在原因:
·内在原因包括:不合理地使用API或数据结构、CPU饱和、持久化阻塞等。
·外在原因包括:CPU竞争、内存交换、网络问题等
单线程的Redis处理命令时只能使用一个CPU。而CPU饱和是指Redis把单核CPU使用率跑到接近100%。使用top命令很容易识别出对应Redis进程的CPU使用率。CPU饱和是非常危险的,将导致Redis无法处理更多的命令,严重影响吞吐量和应用方的稳定性。
使用统计命令redis-cli-h{ip}-p{port}--stat获取当前Redis使用情况,该命令每秒输出一行统计信息
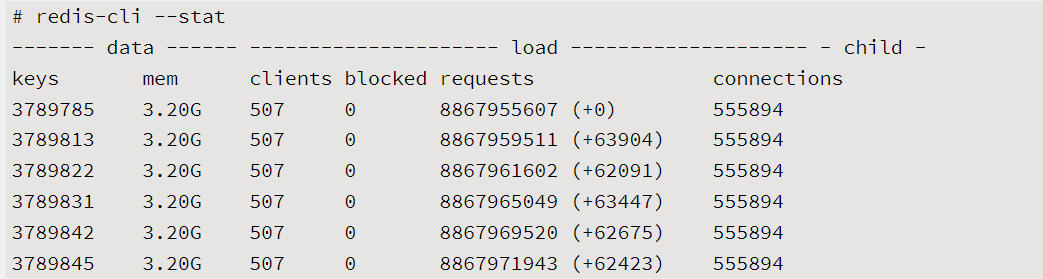
以上输出是一个接近饱和的Redis实例的统计信息,它每秒平均处理6万+的请求。对于这种情况,垂直层面的命令优化很难达到效果,这时就需要做集群化水平扩展来分摊OPS压力。如果只有几百或几千OPS的Redis实例就接近CPU饱和是很不正常的,有可能使用了高算法复杂度的命令。还有一种情况是过度的内存优化,这种情况有些隐蔽,需要我们根据info commandstats统计信息分析出命令不合理开销时间,例如下面的耗时统计:

查看这个统计可以发现一个问题,hset命令算法复杂度只有O(1)但平均耗时却达到135微秒,显然不合理,正常情况耗时应该在10微秒以下。这是因为上面的Redis实例为了追求低内存使用量,过度放宽ziplist使用条件(修改了hash-max-ziplist-entries和hash-max-ziplist-value配置)。进程内的hash对象平均存储着上万个元素,而针对ziplist的操作算法复杂度在O(n)到O(n2)之间。虽然采用ziplist编码后hash结构内存占用会变小,但是操作变得更慢且更消耗CPU。ziplist压缩编码是Redis用来平衡空间和效率的优化手段,不可过度使用。
进程竞争
:Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务部署在一起。当其他进程过度消耗CPU时,将严重影响Redis吞吐量。可以通过top、sar等命令定位到CPU消耗的时间点和具体进程
绑定CPU
:部署Redis时为了充分利用多核CPU,通常一台机器部署多个实例。常见的一种优化是把Redis进程绑定到CPU上,用于降低CPU频繁上下文切换的开销
2.内存交换:
内存交换(swap)对于Redis来说是非常致命的,Redis保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把Redis使用的部分内存换出到硬盘,由于内存与硬盘读写速度差几个数量级,会导致发生交换后的Redis性能急剧下降。
1)查询Redis进程号:
# redis-cli -p 6383 info server | grep process_id
process_id:4476
2)根据进程号查询内存交换信息:
# cat /proc/4476/smaps | grep Swap
Swap: 0 kB
Swap: 0 kB
Swap: 4 kB
3.网络问题
Redis连接拒绝
Redis通过maxclients参数控制客户端最大连接数,默认10000。当Redis连接数大于maxclients时会拒绝新的连接进入,info stats的rejected_connections统计指标记录所有被拒绝连接的数量
总结:
1)客户端最先感知阻塞等Redis超时行为,加入日志监控报警工具可快速定位阻塞问题,同时需要对Redis进程和机器做全面监控。 2)阻塞的内在原因:确认主线程是否存在阻塞,检查慢查询等信息,发现不合理使用API或数据结构的情况,如keys、sort、hgetall等。关注CPU使用率防止单核跑满。当硬盘IO资源紧张时,AOF追加也会阻塞主线程。 3)阻塞的外在原因:从CPU竞争、内存交换、网络问题等方面入手排查是否因为系统层面问题引起阻塞。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
我读过的关于Ruby符号的每一篇文章都在谈论符号相对于字符串的效率。但是,这不是1970年代。我的电脑可以处理一些额外的垃圾收集。我错了吗?我拥有最新最好的奔腾双核处理器和4GBRAM。我认为这应该足以处理一些字符串。 最佳答案 您的计算机可能能够处理“一点点额外的垃圾收集”,但是当“一点点”发生在运行数百万次的内部循环中时呢?如果它在内存有限的嵌入式系统上运行呢?有很多地方你可以随意使用字符串,但在某些地方你不能。这完全取决于上下文。 关于ruby-现代计算机的功能是否不足以处理字符串
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_