作者|许斌斌
经过长期的业务迭代,C 端工程增量编译已经严重劣化,2021 年 12 月前,C 端平均增量编译长达 3 分钟以上,严重影响研发效率,急需优化!经过优化之后,增量编译时长降低到 2 分钟左右。
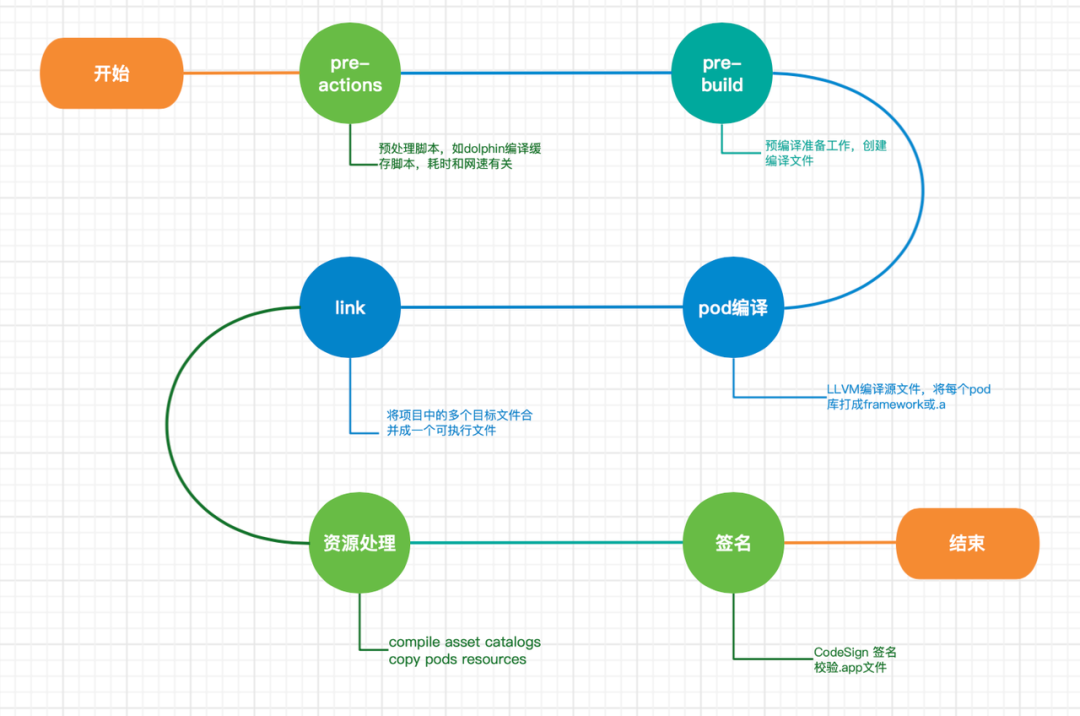


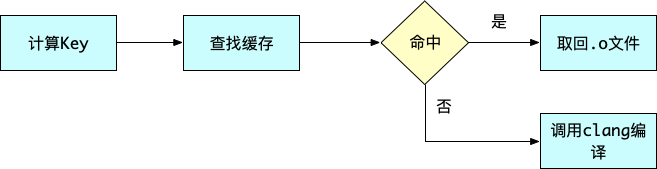
.m 文件编译从点.o 文件依次经历以下阶段:
可以看到,从源文件到目标文件的编译过程中做了大量工作,如果一个源文件新增了一行代码,那么所有研发同学 build 时都要按照这些步骤重新走一遍,增加了大量重复耗时。
字节 app infra 团队通过 hook LLVM Clang,对于基本编译命令(比如 oc 文件),可以根据内容、依赖将其哈希成一个唯一的 key,我们编译完新的.m 后,将对应的.o 和 key 存储在本地硬盘和远程服务器上,其他研发同学编译时,就只需要下载.o 文件即可,可以极大提高编译的效率。幸福里 CI 接入 dolphin 后,打包编译部分耗时从 600s 降低到 240s。
主工程 asset 编译
主工程资源在每次编译都会被编译成 Assets.car,项目里有不少图片存放在主工程的资源下,每次编译都会在这一步耗费 30+s,于是将大部分主工程图片资源迁移至 pod 库中去,可以降低主工程资源编译耗时到 5s 内。
copy pods resource
我们工程是用 resources 引用资源,这一步是复制所有 pod 库的资源并编译合并到主工程的 Assets.car,耗时大概在 40s 左右。优化有两个方向:
ld64
ld64 工作原理参考:https://mp.weixin.qq.com/s/tSj6JVEg7plJQm7aDHLyMw
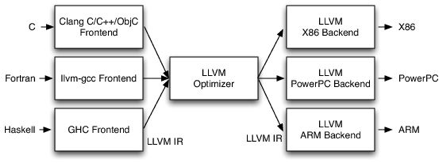
静态链接器 ld64 负责分析 compiler 等模块输出的 .o、.a、.dylib、经过对 symbol 的解析、重定向、聚合,组装出 executable。ld64 主要工作流程如下:

zld
zld 是基于 ld64 开发的优化版链接器,增加并发数、使用效率更快的数据结构去优化 link 过程,当然我们也可以参与优化 zld,如飞书一位大佬就通过 map 查找优化线性查找,降低算法时间复杂度优化了符号决议的耗时。
线性查找
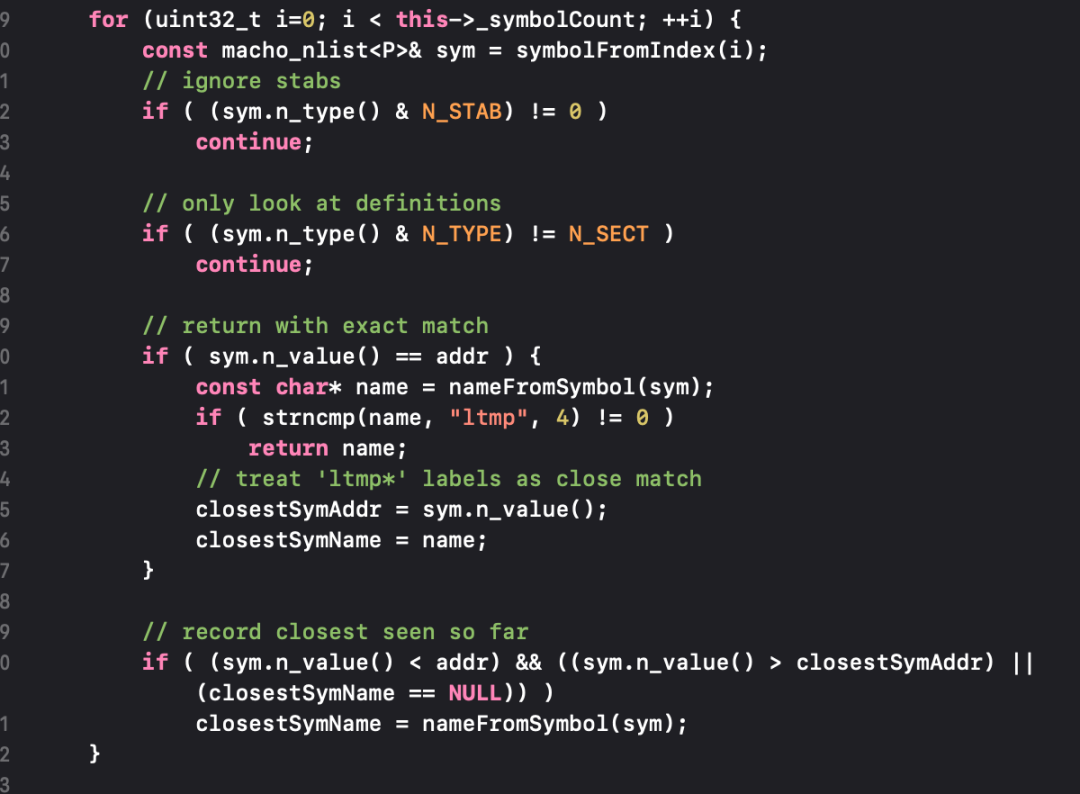
map 查找
ld64 数据:
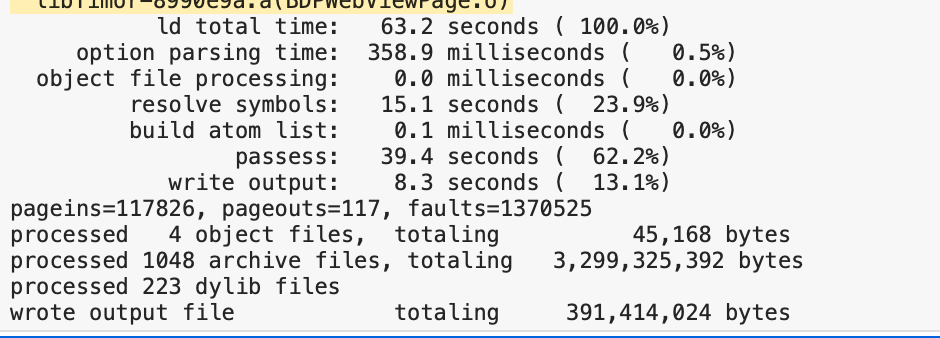
zld 数据:
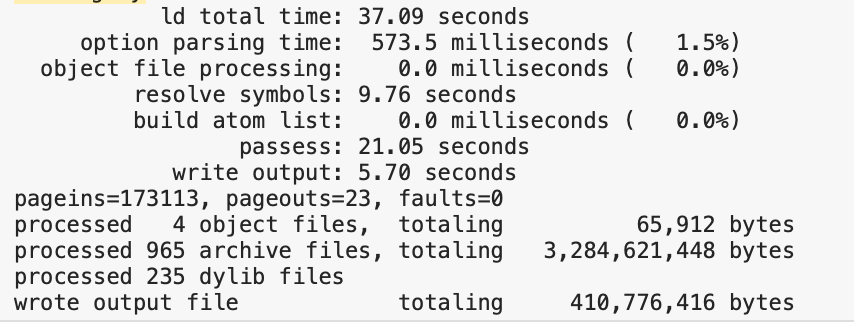
数据对比:
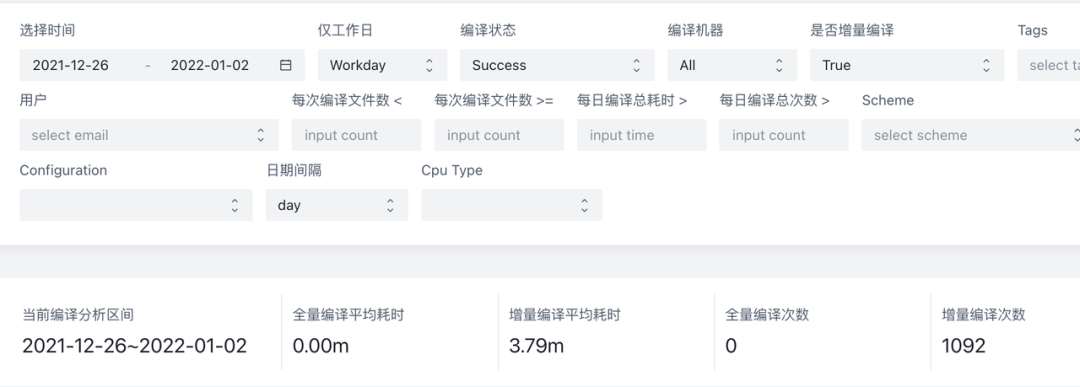
优化前:3.79m
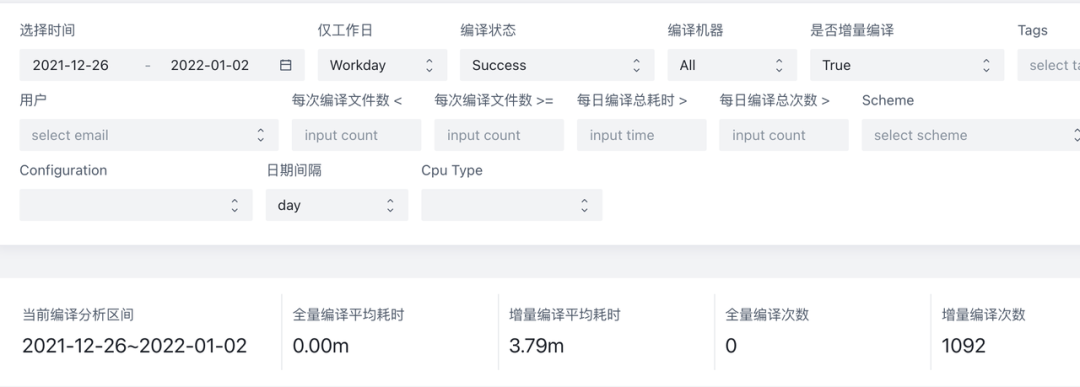
优化后:1.91m
项目 pod install 时会在 pods-target-resources 生成资源拷贝脚本代码, 编译的时候都会运行这个脚本,如果想跳过资源拷贝,直接在 resources 第一行加上 exit 0 即可。

zld 源码:https://github.com/michaeleisel/zld
使用 zld 编译工程,查看编译日志,获取 link 命令代码:
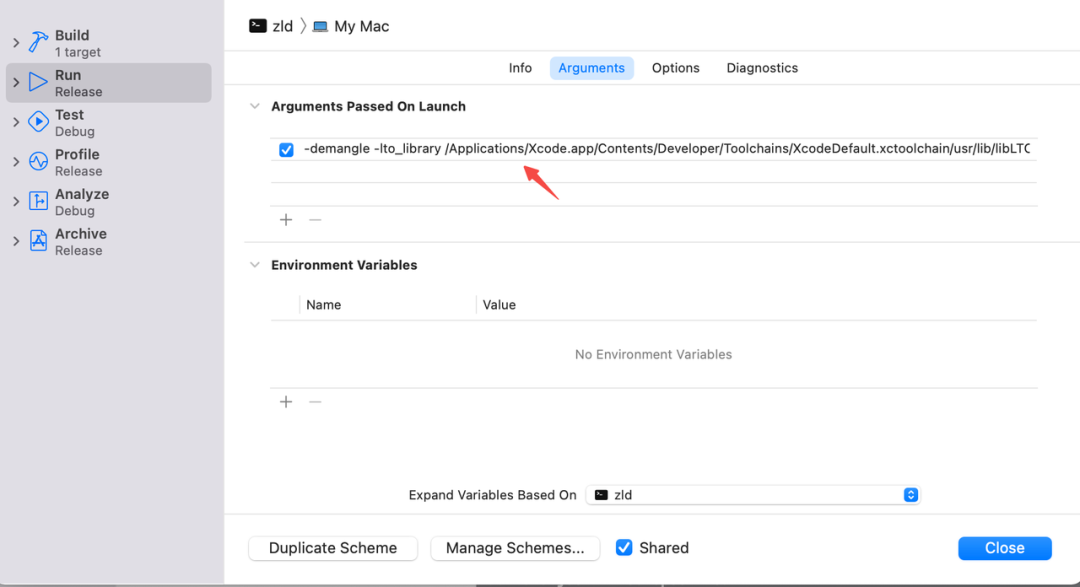
删掉括号和里面的东西,clang 命令后加一个-v,可以显示 link 参数,然后执行脚本,生成 link 参数,复制并删除-demangle 之前的东西,存到 juzi.txt:
-demangle -lto_library /Applications/Xcode.app/Content......打开 zld 工程,编译模式调整为 release(debug 运行太慢,release 运行快但是不能断点调试),并将 juzi.txt 的参数复制到 arguments,就可以直接调试项目的 link 过程了。
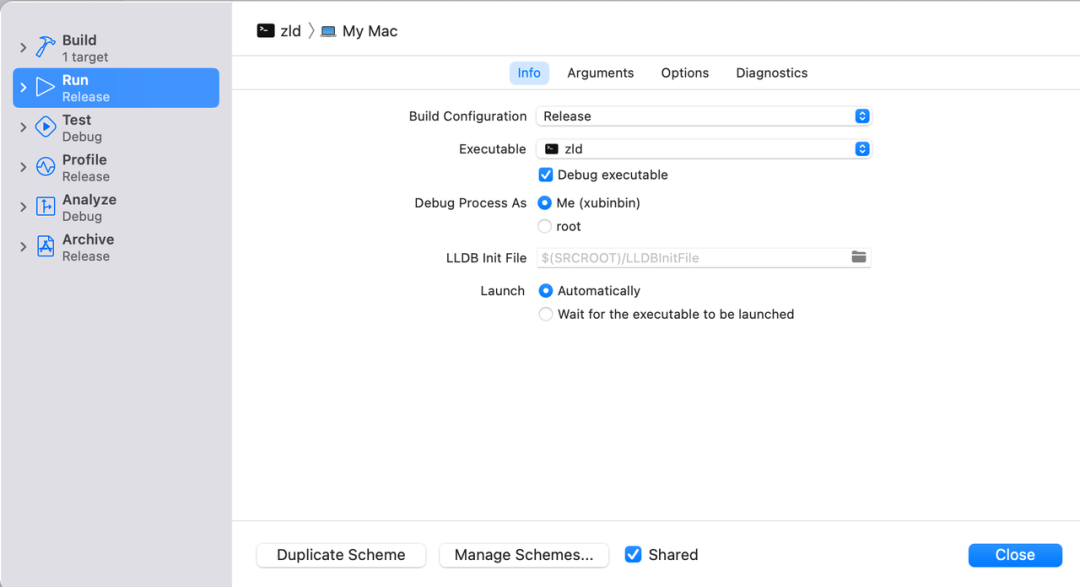
将 zld 工程跑出来的 release 版可执行文件复制到桌面。
打开 xcode 的 instruments 的 time profiler,选择桌面上的 zld 可执行文件。
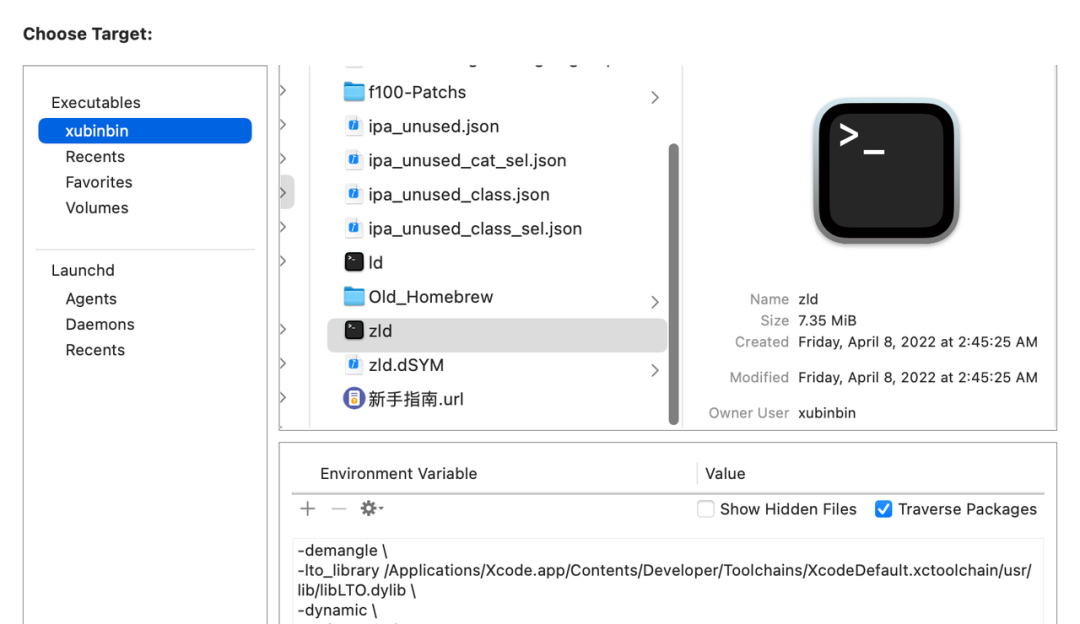
将 juzi.txt 参数中的\s-换成 \\n-,并复制到上图的 arguments,然后运行并分析。
-demangle \
-lto_library /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libLTO.dylib \
-dynamic \
...
如图,getUserVisibleName()耗时较多,我们查看 zld 源码:
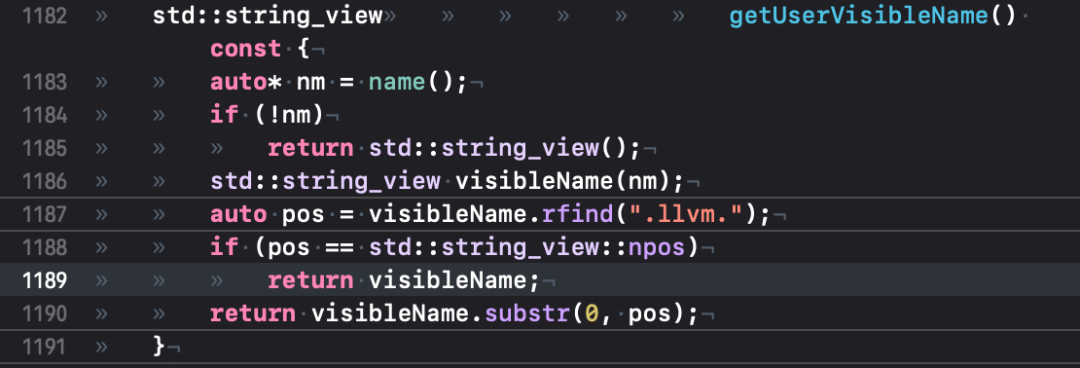
经过断点或加日志测试发现,这个方法永远找不到".llvm."的子串(仅作为 demo 测试),于是尝试改成以下代码:
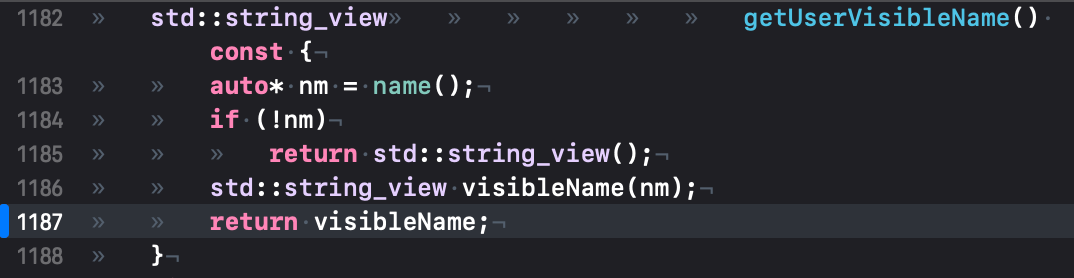
再次编译产生新的可执行文件,经过 instruments 再次测试得到如下数据:

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
我不知道为什么,但是当我设置这个设置时它无法编译设置:static_cache_control,[:public,:max_age=>300]这是我得到的syntaxerror,unexpectedtASSOC,expecting']'(SyntaxError)set:static_cache_control,[:public,:max_age=>300]^我只想将“过期”header设置为css、javaascript和图像文件。谢谢。 最佳答案 我猜您使用的是Ruby1.8.7。Sinatra文档中显示的语法似乎是在Ruby1.
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
最近因为项目需要,需要将Android手机系统自带的某个系统软件反编译并更改里面某个资源,并重新打包,签名生成新的自定义的apk,下面我来介绍一下我的实现过程。APK修改,分为以下几步:反编译解包,修改,重打包,修改签名等步骤。安卓apk修改准备工作1.系统配置好JavaJDK环境变量2.需要root权限的手机(针对系统自带apk,其他软件免root)3.Auto-Sign签名工具4.apktool工具安卓apk修改开始反编译本文拿Android系统里面的Settings.apk做demo,具体如何将apk获取出来在此就不过多介绍了,直接进入主题:按键win+R输入cmd,打开命令窗口,并将路
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上