文章目录
插入数据,即向已有的表中增加一条记录。

# 使用 atguigudb
USE atguigudb;
# 新建表格
CREATE TABLE IF NOT EXISTS emp1 (
id INT,
`name` VARCHAR(15),
hire_data DATE,
salary DOUBLE(10, 2)
);
# 查看表的结构
DESC emp1;

语法:
INSERT INTO 表名
VALUES (value1, value2, ...);
注意:值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
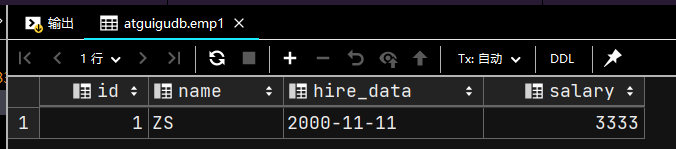
# 向表 emp1 中插入一条记录
INSERT INTO emp1
VALUES (1, 'ZS', '2000-11-11', 3333);
SELECT * FROM emp1;
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
语法:
INSERT INTO 表名(column1 [column2, column3, ...])
VALUES (value1, [value2, value3, ...]);
注意:在 INSERT 子句中列出的列名顺序以及个数可以与定义表格时的顺序和个数不同,但是一旦列出,VALUES中要插入的value值需要与column列一一对应。如果不对应,将无法插入,并且MySQL会产生错误。
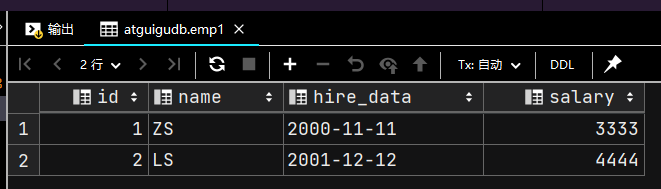
INSERT INTO emp1(id, hire_data, `name`, salary)
VALUES (2, '2001-12-12', 'LS', 4444);
SELECT * FROM emp1;
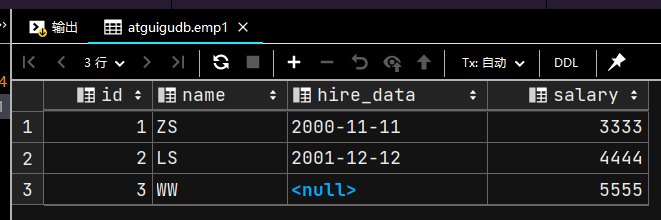
INSERT INTO emp1(id, `name`, salary)
VALUES (3, 'WW', 5555);
SELECT * FROM emp1;
INSERT语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号分隔开,基本语法格式如下:
INSERT INTO 表名
VALUES
(value1 [,value2, ..., valuen]),
(value1 [,value2, ..., valuen]),
......
(value1 [,value2, ..., valuen]);
或者
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, ..., valuen]),
(value1 [,value2, ..., valuen]),
......
(value1 [,value2, ..., valuen]);
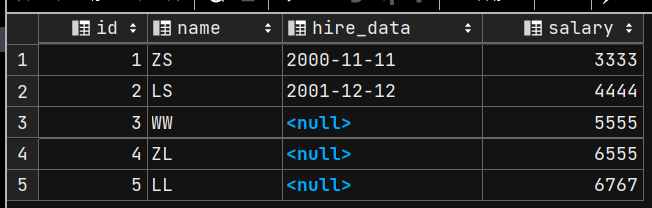
INSERT INTO emp1(id, `name`, salary)
VALUES (4, 'ZL', 6555),
(5, 'LL', 6767);
SELECT * FROM emp1;
一个同时插入多行记录的INSERT语句等同于多个单行插入的INSERT语句,但是多行的INSERT语句在处理过程中 效率更高 。因为MySQL执行单条INSERT语句插入多行数据比使用多条INSERT语句快,所以在插入多条记录时最好选择使用单条INSERT语句的方式插入。
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入多行。
语法:
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
将查询结果插入到表中,即在 INSERT 语句中加入子查询,不必书写 VALUES 子句,子查询中的字段应与 INSERT 子句中的字段对应。
INSERT INTO emp1(id, `name`, salary, hire_data)
SELECT employee_id, last_name, salary, hire_date
FROM employees
WHERE department_id IN (70, 60);
SELECT * FROM emp1;
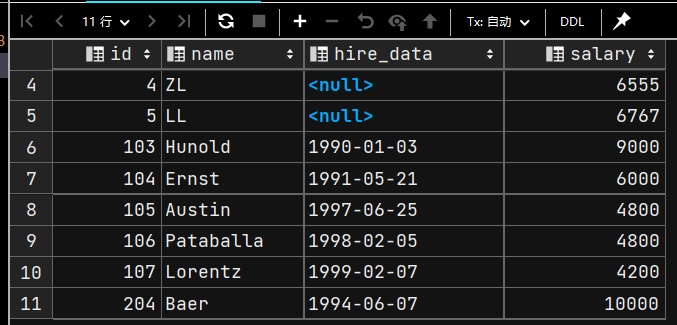
注意:被插入数据的表中要添加数据的字段的长度不能低于查询表中查询的字段的长度。如果被插入数据的表中要添加数据的字段的长度低于查询表中查询的字段的长度的话,就有添加不成功的风险。
更新(修改)数据,对表中已有的记录进行修改。
UPDATE 表名
SET 字段名 = 值, [字段名 = 值, ...]
[WHERE 条件];
使用 WHERE 子句指定需要更新指定数据的记录;如果省略 WHERE 子句,则表中的所有记录的指定数据都将被更新。
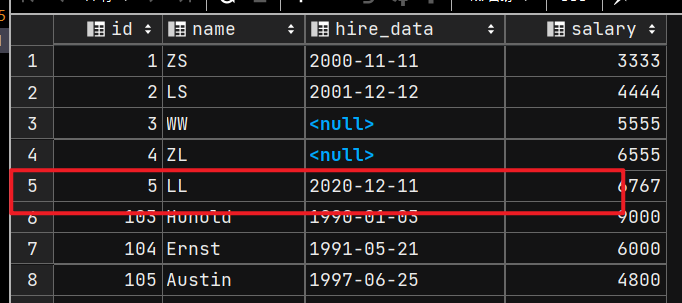
UPDATE emp1
SET hire_data = '2020-12-11'
WHERE id = 5;
SELECT * FROM emp1;
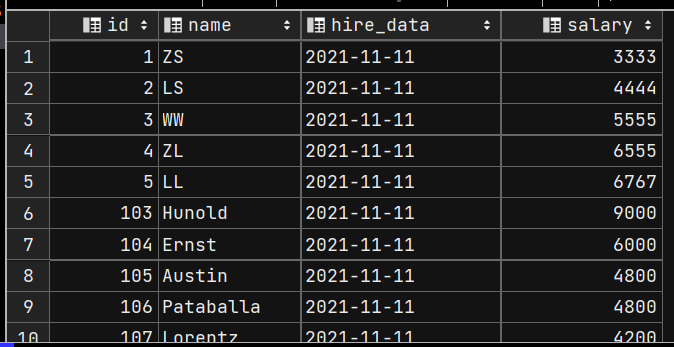
UPDATE emp1
SET hire_data = '2021-11-11';
# WHERE id = 5;
SELECT * FROM emp1;
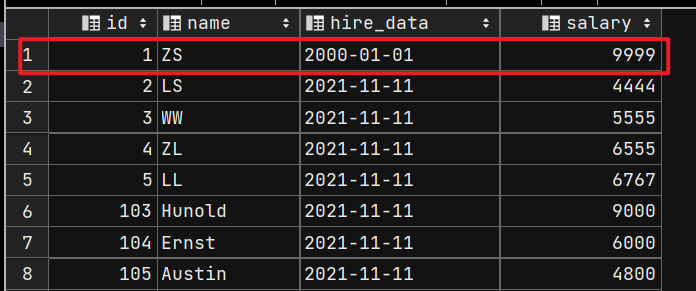
UPDATE emp1
SET hire_data = '2000-01-01', salary = 9999
WHERE id = 1;
SELECT * FROM emp1;
DELETE FROM 表名
[WHERE 条件];
使用 WHERE 子句删除指定的记录;如果没有WHERE子句,DELETE语句将删除表中的所有记录。
DELETE FROM emp1
WHERE id > 2;
SELECT * FROM emp1;

DELETE FROM emp1;
# WHERE id > 2;
SELECT * FROM emp1;

SET autocommit = FALSE。计算列:简单来说就是某一列的值是通过别的列计算得来的。
例如,a列值为1、b列值为2,c列不需要手动插入,定义a+b的结果为c的值,那么c就是计算列,是通过别的列计算得来的。当a或b列的值发生修改,c列的值也会对应修改。
在MySQL 8.0中,CREATE TABLE 和 ALTER TABLE 中都支持增加计算列。
计算可以提升查询数据时,需要查询出记录的某些列数据的计算结果的效率。使用计算列,不用在每次查询时每条记录都进行一次运算。
定义数据表tb1,然后定义字段id、字段a、字段b和字段c,其中字段c为计算列,用于计算a+b的值。
CREATE TABLE tb1
(
id INT,
a INT,
b INT,
# 计算列
c INT GENERATED ALWAYS AS (a + b) VIRTUAL
);
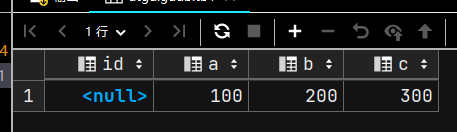
插入数据
INSERT INTO tb1(a,b) VALUES (100,200);
SELECT * FROM tb1;
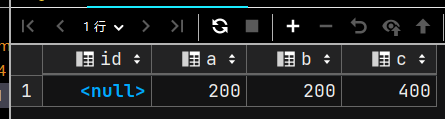
更新数据
UPDATE tb1
SET a = 200
WHERE id IS NULL ;
SELECT * FROM tb1;
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD