目 录
①突破1000层的超深的网络结构;
②提出残差(residual)模块;
③使用Batch Normalization加速训练,不需要使用dropout方法了。
网络结构并不是越深越好,原因如下:

①首先是梯度消失和梯度爆炸问题:假设每一层的误差梯度是小于1的数,那在反向传播中,每向前传播一次都要乘以一个小于1的误差梯度,当网络越来越深乘以小于1的数就越多就越接近于0,这样梯度就会越来越小,这就是梯度消失现象,梯度爆炸现象同理;解决该问题通常是对数据进行标准化、权重初始化等处理。
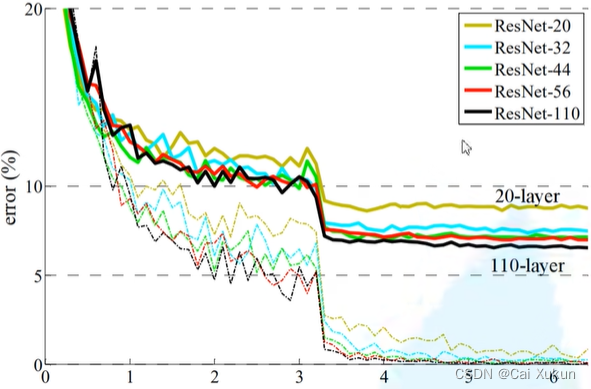
②其次是退化问题:提出了残差结构,如上图所示,ResNet网络能够实现层数越深,效果越好。
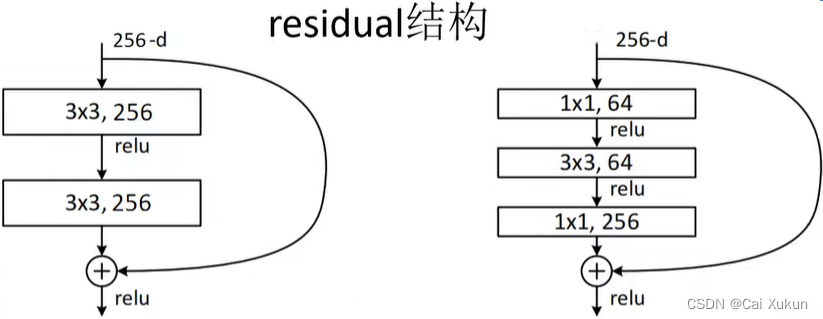
左图是针对网络层数较少的网络结构所使用的残差结构(原论文中用在了ResNet-18、32),右图是针对网络网络层数较多的网络结构所使用的残差结构(原论文中用在了ResNet-50、101、152)。
左图是将输入矩阵经过两个3×3的卷积层得到的输出与原输入矩阵相加(注意是对应维度相加,而不是在深度方向进行拼接),因此需要保证输出与原输入矩阵的shape(H、W、channel)相同,再经过ReLU激活函数得到输出矩阵;右面不同点是加入了两个1×1的卷积层进行降维和升维,这样的好处在:
左面所需参数:3×3×256×256+3×3×256×256=1179648
右面所需参数:1×1×256×64+3×3×64×64+1×1×64×256=69632
会大大减少参数数量。
虚线残差结构出现在以下几个位置:
①所有层数ResNet网络的conv3_x、conv4_x和conv5_x的第一层中(比如ResNet-50的conv3_x需要4个残差结构,只有第一个残差结构需要用虚线结构),主要是为了改变输入的H、W、channel;
②ResNet-50、101、152深层网络的conv2_x的第一层中,只是为了改变输入的channel。
下图为用在ResNet-18、34的虚线残差结构:
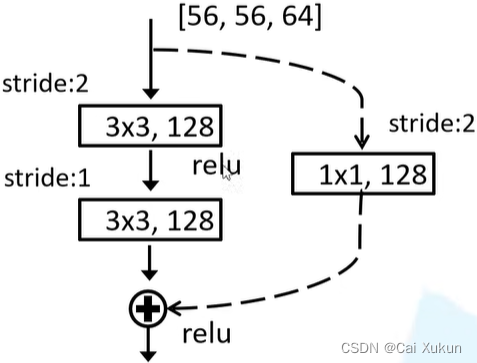
该结构的输出为[28, 28, 128],因此第一层的步长为2,计算如下(主分支padding=1):
(56-3+2)/2+1=28(当计算不被整除时,卷积向下取整,池化向上取整)
将长和宽变为28,再经过一层步长为1的卷积层:
(28-3+2)/1+1=28
得到的输出为[28, 28, 128],输入经过侧分支(padding=0):
(56-1)/2+1=28(当计算不被整除时,卷积向下取整,池化向上取整)
下图为用在ResNet-50、101、152的虚线残差结构(conv2_x的主副分支步长为1,因为前面有最大池化下采样层做了H和W减半的工作):
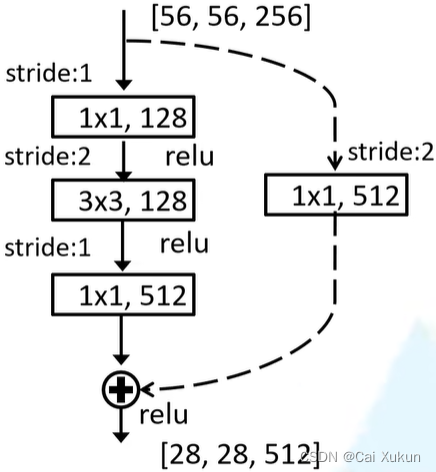
作者一共比较了A、B、C三个结构,最终上图B结构的效果最好。在原论文中残差结构的主分支上第一个1x1卷积层的步长是2,第二个3x3卷积层步长是1;但在pytorch官方实现过程中是第一个1x1卷积层的步长是1,第二个3x3卷积层步长是2,这样能够在ImageNet的top1上提升大概0.5%的准确率。
该标准化处理的目的是使我们一个batch的每一个channel对应的维度满足均值为0、方差为1的分布规律,具体原理如下例子所示:
假设batch size为2(即输入两张图片),每张图片H和W为2,channel为2:

,
channel1的均值:
同理channel2的均值为0.5;channel1的方差为:
同理channel2的方差为1.5,因此可以得出:
,
和
都是在正向传播过程中得到的,再根据公式(
是一个很小的数,作用是为了防止分母为0):
最后一步还需要进行:,其中
初始值为1、
初始值为0,并且这两个参数是在反向传播过程中训练得到的,因此此处就取1和0,因此值不变,最后结果为:

①训练时要将training参数设置为True,验证时要将training参数设置为False(在pytorch中可以通过创建模型的model.train()和model.eval()控制),因为在训练过程中是要不断地统计均值和方差,但是在验证或者预测过程中,是使用我们历史统计的均值和方差,而不是使用当前计算的均值和方差;
②batch size设置的尽可能大,这样计算的均值和方差能够尽可能的接近整个训练集的均值和方差,效果越好,设置的太小效果会很差;
③将BN层放在卷积层(Conv)和激活层(如ReLU)之间,并且卷积层不使用bias,因为即使使用了偏置bias求出来的结果和不使用bias的结果也是相同的。
①能够快速的训练出理想的结果(只迭代几个epoch就可达到),减少训练时间;
②当数据集较小时也能训练出理想的结果。如果网络参数过多而数据集有太少,这些数据集是不足以训练整个网络的,这样便会出现过拟合的情况导致结果很差,但是使用迁移学习的方法可以使用别人预训练好的模型参数来训练我们较小的数据集,也能训练出一个比较好的效果。但是在使用别人的预训练模型参数时,要注意该模型预处理的方式。
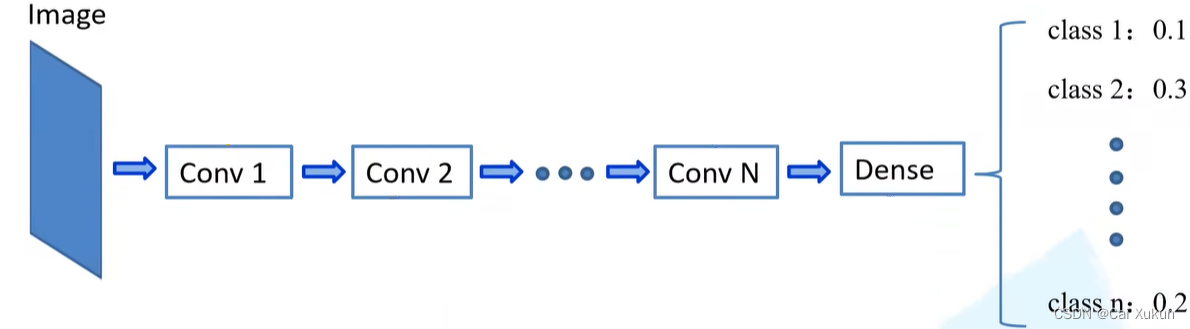
以上图网络模型为例,假设一张图像经过网络训练完之后,第一个卷积层学到了角点信息,第二层学到了稍微复杂的纹理信息,到第n层可能学到了识别眼睛、鼻子等等,最后通过全连接层将一系列的特征整合,最终能够输出对应每一个类别的概率。
对于浅层的网络,所学到的信息是较为通用的信息,不但能在本网络中使用,对于其他网路也是适用的,所以有“迁移”这个概念。将学习好的浅层网络的一些参数,迁移到新的网络中去,这样新网络也具有识别底层通用特征的能力,就能够更加快速的学习新数据集的高维特征了。
①载入权重后训练所有参数(效果最佳):
载入别人预训练好的模型参数之后,针对我们使用的数据集,再去训练所有层的网络参数,但要注意最后一层全连接层是无法载入预训练模型参数的,节点个数要根据我们数据集的类别更改。
②载入权重后只训练最后几层参数;
③载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层。
原论文中不同层数网络的参数列表如下:
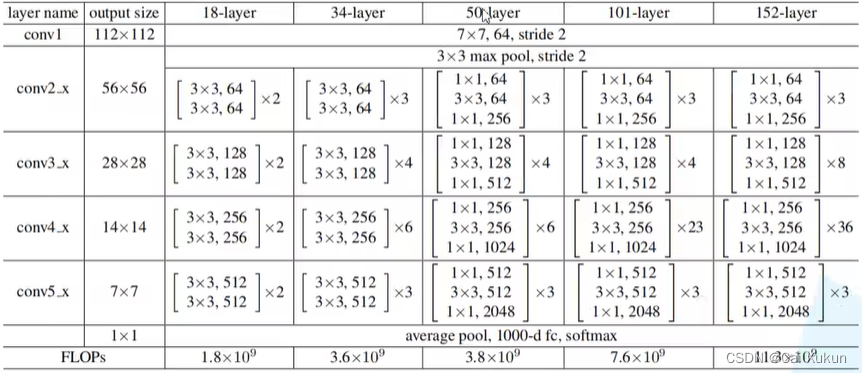
以34层的网络结构为例:
①第一层用了64个7×7的卷积核;
②第二层是3×3的最大池化下采样操作;
③经过Conv_2残差结构(共3个),如下图所示:

后面的残差结构同理,再经过平均池化下采样层和全连接层,最后softmax处理将输出转化为概率分布。
# 定义18层和34层网络所用的残差结构
class BasicBlock(nn.Module):
# 对应残差分支中主分支采用的卷积核个数有无发生变化,无变化设为1(即每一个残差结构主分支的第二层卷积层卷积核个数是第一层卷积层卷积核个数的1倍)
expansion = 1
# 输入特征矩阵深度、输出特征矩阵深度(主分支卷积核个数)、步长默认取1、下采样参数默认为None(对应虚线残差结构)
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
# 每一个残差结构中主分支第一个卷积层,注意步长是要根据是否需要改变channel而取1或取2的,不使用偏置(BN处理)
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
# BN标准化处理,输入特征矩阵为conv1的out_channel
self.bn1 = nn.BatchNorm2d(out_channel)
# 激活函数
self.relu = nn.ReLU()
# 每一个残差结构中主分支第二个卷积层,输入特征矩阵为bn1的out_channel,该卷积层步长均为1,不使用偏置
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
# BN标准化处理,输入特征矩阵为conv2的out_channel
self.bn2 = nn.BatchNorm2d(out_channel)
# 下采样方法,即侧分支为虚线
self.downsample = downsample
# 正向传播过程
def forward(self, x):
# 将输入特征矩阵赋值给identity(副分支的输出值)
identity = x
# 如果需要下采样方法,将输入特征矩阵经过下采样函数再赋值给identity
if self.downsample is not None:
identity = self.downsample(x)
# 主分支的传播过程
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 将主分支和副分支的输出相加再经过激活函数
out += identity
out = self.relu(out)
return out# 定义50层、101层和152层网络所用的残差结构
class Bottleneck(nn.Module):
# 每一个残差结构主分支的第三层卷积层卷积核个数是第一层或第二层卷积层卷积核个数的4倍)
expansion = 4
# 输入特征矩阵深度、输出特征矩阵深度(和18层和34层网络残差结构的主分支卷积核个数相同)、步长默认取1、下采样参数默认为None(对应虚线残差结构)、最后两个参数和ResNeXt网络的搭建有关
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# ResNeXt网络的搭建
width = int(out_channel * (width_per_group / 64.)) * groups
# 每一个残差结构中主分支第一个卷积层,卷积核为1*1,不使用偏置
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
# BN标准化处理,输入特征矩阵为conv1的width
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# 每一个残差结构中主分支第二个卷积层,卷积核为3*3
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
# BN标准化处理,输入特征矩阵为conv2的width
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
# 每一个残差结构中主分支第二个卷积层,卷积核为1*1,输出特征矩阵为4倍的第一层或第二层卷积的卷积核个数
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
# BN标准化处理,输入特征矩阵为conv3的out_channel*self.expansion
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
# 激活函数
self.relu = nn.ReLU(inplace=True)
# 下采样方法,即侧分支为虚线
self.downsample = downsample
# 正向传播过程
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out# 定义ResNet网络结构
class ResNet(nn.Module):
# 对应哪一种残差结构、残差结构数目(是一个列表值,如ResNet-34为[3, 4, 6, 3])、分类个数、方便在ResNet网络基础上搭建更加复杂的网络
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
# 输入矩阵深度,对应3*3maxpool后所得到的特征矩阵深度,不论多少层的ResNet网络均为64
self.in_channel = 64
# ResNeXt网络的搭建
self.groups = groups
self.width_per_group = width_per_group
# 第一层卷积层,输入RGB图像深度为3,64个7*7的卷积核,为了让输出特征矩阵的H和W变为原来一半padding设置为3
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
# BN层
self.bn1 = nn.BatchNorm2d(self.in_channel)
# 激活函数
self.relu = nn.ReLU(inplace=True)
# 最大池化下采样层,为了让输出特征矩阵的H和W变为原来一半padding设置为1
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# conv2_x,通过_make_layer函数生成,注意该层输入的是maxpool输出的56*56的矩阵,因此不需要步长为2来减半,故步长默认为1
self.layer1 = self._make_layer(block, 64, blocks_num[0])
# conv3_x
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
# conv4_x
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
# conv5_x
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
# 平均池化下采样层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
# 全连接层,节点个数可能为512也可能为512*4
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 对卷积层进行初始化操作
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# 生成conv2_x、conv3_x、conv4_x、conv5_x的函数
# 选择哪种残差结构、主分支第一层卷积核个数、该层一共包含了多少个残差结构、步长默认为1
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
# 步长不为1或者conv2、3、4、5_x的第一个卷积层卷积核个数不等于最后一层卷积核个数(即expansion是否为4)
# 若为ResNet-18、34的虚线残差结构,前一项为True;若为ResNet-50、101、152的虚线残差结构,前后均为为True
# 故前一项是为了保证ResNet-18、34的conv3、4、5_x的判断能够通过
if stride != 1 or self.in_channel != channel * block.expansion:
# 生成副分支,输入为输入convx_x的特征矩阵,输出为1倍或4倍,步长为1或2
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
# 定义一个空列表,用来装convx_x的网络结构
layers = []
# 首先要把第一个残差结构加进去,因为第一个残差结构涉及到虚线残差结构
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
# 经过convx_x后输入conv(x+1)_x的channel变为1倍或4倍
self.in_channel = channel * block.expansion
# 把后面的残差结构加上,不涉及虚线残差结构
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
# 将层结构组合在一起并且返回
return nn.Sequential(*layers)
# 整个网络的正向传播过程
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
# 展平
x = torch.flatten(x, 1)
x = self.fc(x)
return x
需要下载预训练模型,并且使用迁移训练,迁移训练代码如下:
# 迁移学习resnet34()中不能直接传入类别个数,若不使用迁移学习可以直接传入5就行
net = resnet34()
# 模型权重的位置
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
# 载入模型权重
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# in_features获取全连接层的输入
in_channel = net.fc.in_features
# Linear定义一个神经网络新的全连接层,输入为in_channel,输出为5
net.fc = nn.Linear(in_channel, 5)
net.to(device)只经过三个epoch就能达到93%的正确率:

预测下面这张图片:

预测结果为向日葵的概率为99.9%:

文件夹里存放了下列图片:

预测结果为:

我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项