自 ChatGPT 发布以来,这段时间对话模型的热度只增不减。当我们赞叹这些模型表现惊艳的同时,也应该猜到其背后巨大的算力和海量数据的支持。
单就数据而言,高质量的数据至关重要,为此 OpenAI 对数据和标注工作下了很大力气。有多项研究表明,ChatGPT 是比人类更加可靠的数据标注者,如果开源社区可以获得 ChatGPT 等强大语言模型的大量对话数据,就可以训练出性能更好的对话模型。这一点羊驼系列模型 ——Alpaca、Vicuna、Koala—— 已经证明过。例如,Vicuna 使用从 ShareGPT 收集的用户共享数据对 LLaMA 模型进行指令微调,就复刻了 ChatGPT 九成功力。越来越多的证据表明,数据是训练强大语言模型的第一生产力。
ShareGPT 是一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。ShareGPT 上的数据是开放但琐碎的,需要研究人员自己收集整理。如果能够有一个高质量的,覆盖范围广泛的数据集,开源社区在对话模型研发方面将会事半功倍。
基于此,最近一个名为 UltraChat 的项目就系统构建了一个超高质量的对话数据集。项目作者尝试用两个独立的 ChatGPT Turbo API 进行对话,从而生成多轮对话数据。
具体而言,该项目旨在构建一个开源、大规模、多轮的基于 Turbo APIs 的对话数据,方便研究者开发具有通用对话能力的强大语言模型。此外,考虑到隐私保护等因素,该项目不会直接使用互联网上的数据作为提示。为了确保生成数据质量,研究者在生成过程中采用了两个独立的 ChatGPT Turbo API,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。

如果直接使用 ChatGPT 基于一些种子对话和问题让其自由生成,容易出现话题单一、内容重复等问题,从而难以保证数据本身的多样性。为此,UltraChat 对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:
这三部分数据覆盖了大部分用户对于 AI 模型的要求。同时,这三类数据也会面临着不同的挑战,为此需要不同的构造方法。
例如,第一部分的数据主要挑战在于如何在总量为几十万组对话中尽量广泛地涵盖人类社会中的常见知识,为此研究者从自动生成的主题和来源于 Wikidata 的实体两个方面进行了筛选和构造。
第二、三部分的挑战主要来自于如何模拟用户指令,并在后续对话中让用户模型的生成尽量多样化的同时又不偏离对话的最终目标(按照要求生成材料或改写材料),为此研究者对用户模型的输入提示进行了充分的设计和实验。在构造完成之后,作者还对数据进行了后处理以削弱幻觉问题。
目前,该项目已经发布了前两部分的数据,数据量为 124 万条,应该是目前开源社区内规模最大的相关数据集。内容包含在现实世界中丰富多彩的对话,最后一部分数据将在未来发布。
世界问题数据来源于 30 个具有代表性和多样性的元主题,如下图所示:

此外,该项目从维基数据中收集了最常用的 10000 个命名实体;使用 ChatGPT API 为每个实体生成 5 个元问题;对于每个元问题,生成 10 个更具体的问题和 20 个相关但一般的问题;采样 20w 个特定问题和 25w 个一般问题以及 5w 个元问题,并为每个问题生成了 3~7 轮对话。
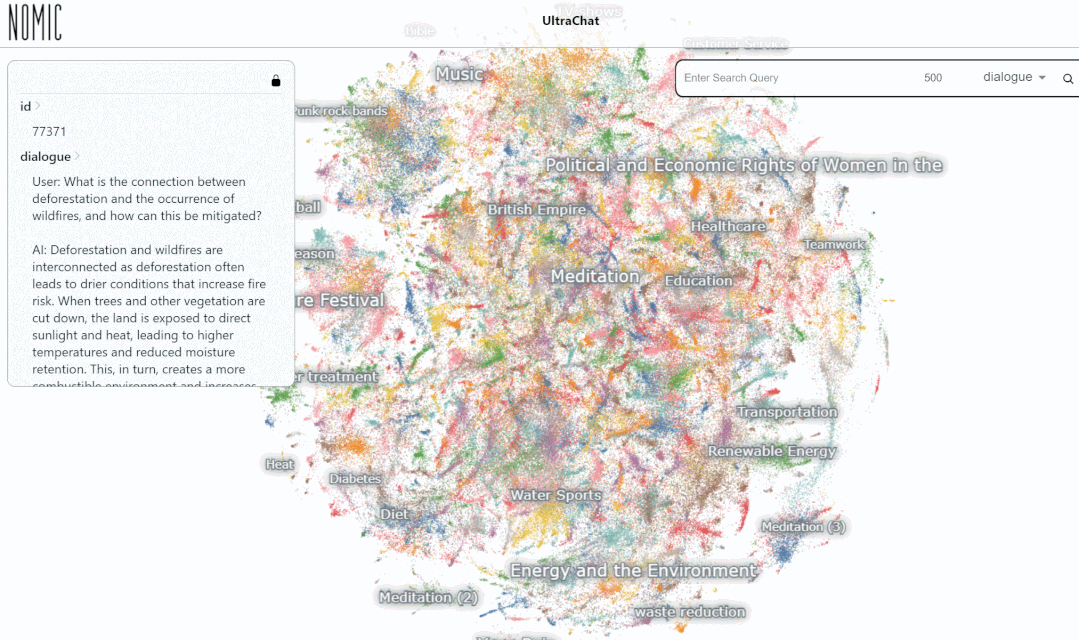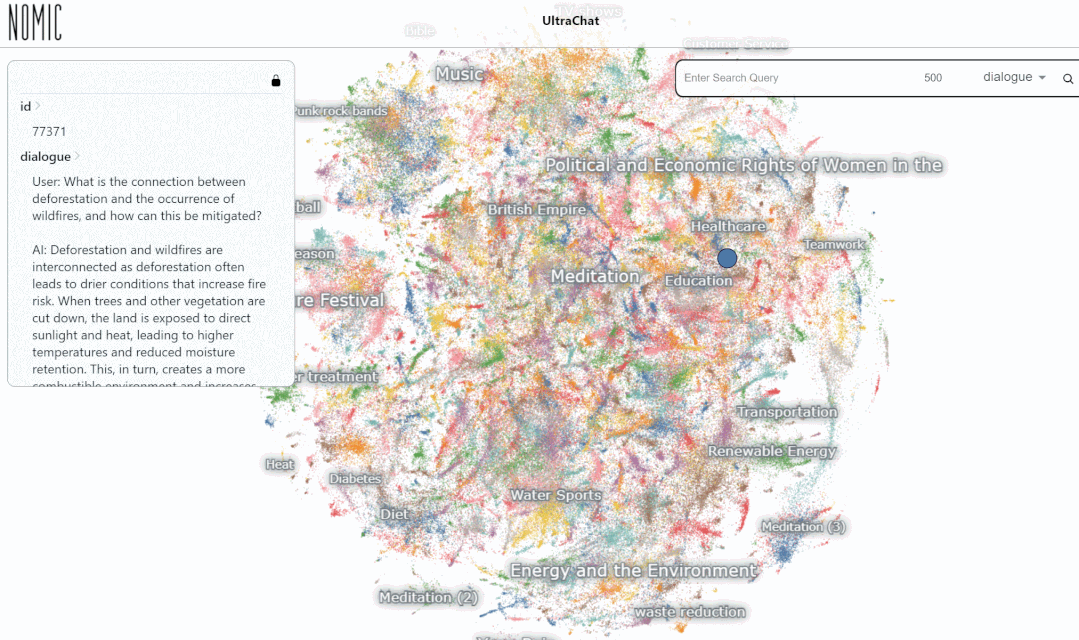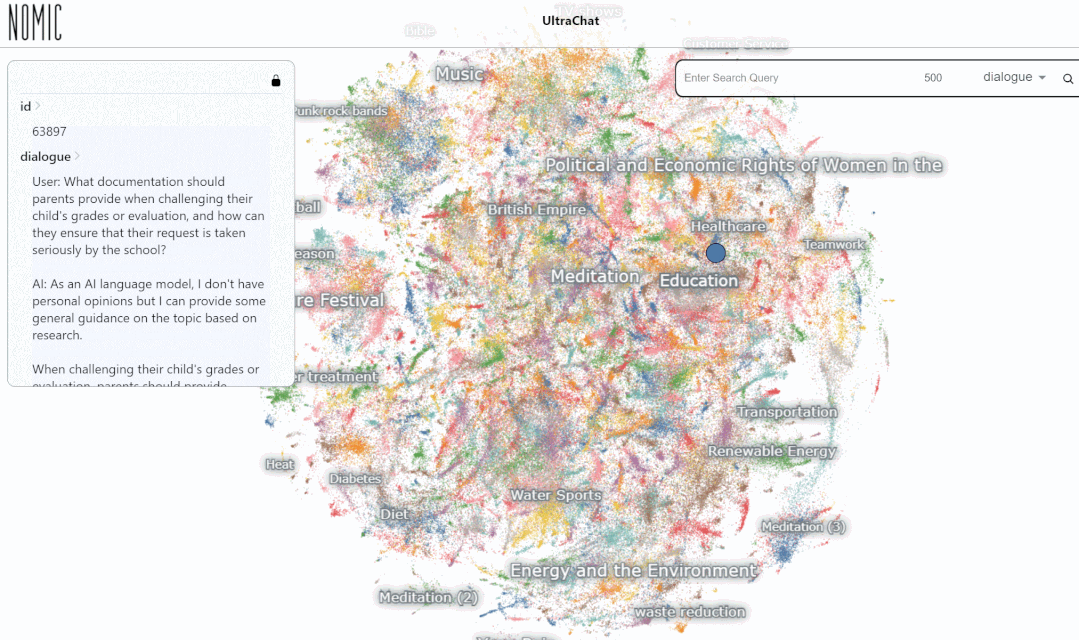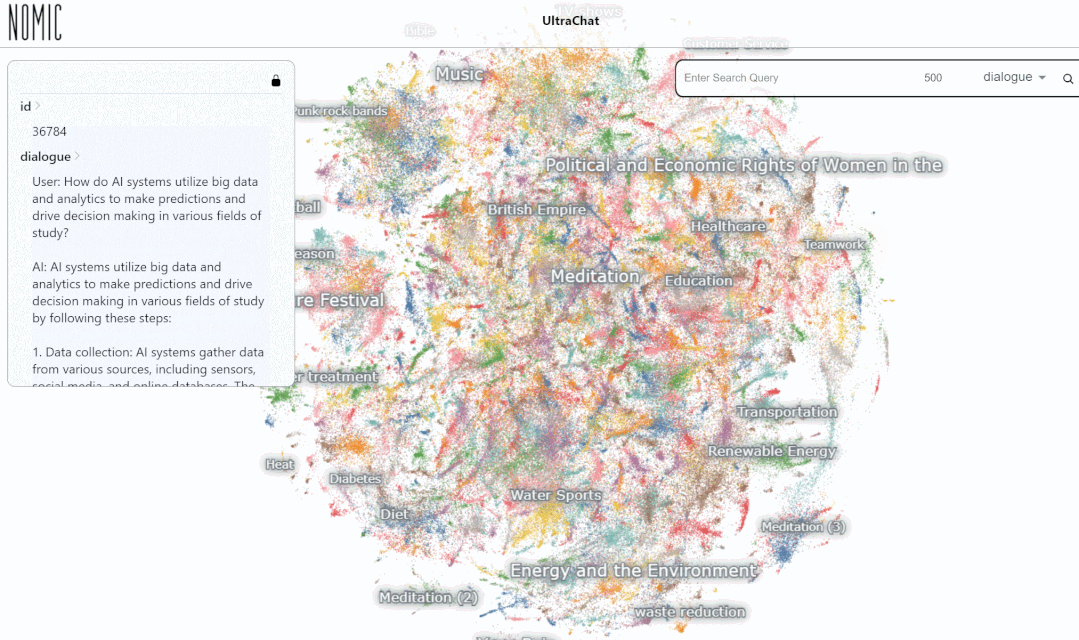
接下来我们看一个具体的例子:

我们在 UltraChat 平台上测试了数据搜索效果。例如,输入「音乐(music)」,系统会自动搜索出 10000 组与音乐相关的 ChatGPT 对话数据,并且每组都是多轮对话

输入关键词「数学(math)」的搜索结果,有 3346 组多轮对话:

目前,UltraChat 涵盖的信息领域已经非常多,包括医疗、教育、运动、环保等多个话题。同时,笔者尝试使用开源的 LLaMa-7B 模型在 UltraChat 上进行监督的指令微调,发现仅仅训练 10000 步后就有非常可观的效果,一些例子如下:

世界知识:分别列出 10 个很好的中国和美国大学

想象问题:当时空旅行成为可能后,有什么可能的后果?

三段论:鲸鱼是鱼吗?

假设问题:证明成龙比李小龙更出色
总体来说,UltraChat 是一个高质量、范围广的 ChatGPT 对话数据集,可以和其它数据集结合,显著地提升开源对话模型的质量。目前 UltraChat 还只放出了英文版,但也会在未来放出中文版的数据。感兴趣的读者快去探索一下吧。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www