作为一个技术博主,了不起不是在创作就是在创作的路上(当然偶尔也会有点恰饭文~还指望大家多多支持),我们都知道,在写代码的过程中,业务逻辑很大程度上决定了你对业务的理解,但是解决问题,却是你提升比较关键的地方,而了不起,却差点因为这个内存溢出,把自己给干优化掉。
百度百科是这么解释的:
内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出,有时候会自动关闭软件,重启电脑或者软件后释放掉一部分内存又可以正常运行该软件,而由系统配置、数据流、用户代码等原因而导致的内存溢出错误,即使用户重新执行任务依然无法避免
其实很简单,在 Java 中,那就是 Out Of Memory,导致了不合理的 GC ,那么如何去定位这个内存溢出的呢?实际上如果是大公司,那么会有专业的运维人员去定位哪些程序导致了内存溢出,但是如果要是没有专业的运维人员,那么你自己就得学会怎么去定位这个内存溢出了。
一、定位占用CPU最高的服务 1、先找到cpu占用比较高的进程:top -c 进去后按Shift+P键
一般异常的进程cpu的占用会很高,记录下这进程的PID
2、查看指定进程cpu情况:top -cp PID
查看此进程占用cpu最高的线程,记录下线程的ppid也可以将相关信息保存下来:top -Hp PID -o %CPU -n 1 >cpu.txt到此,我们就找到的最占用cpu的进程以及相关线程。
3.如果你已经知道是你们的 Java 程序导致了内存溢出,那么我们就得学会分析日志,一般在 Out Of Memory 的上方,我们都会有各种日志的输出,来标志现在这个时间点,我们的程序执行了什么操作,导致了我们的这个内存溢出,分析到这里,就轮到看代码了。
检查的内容大致都有哪些地方呢?
在一个项目中,使用两个数据库连接,其中专用于发送短信的数据库连接使用 DBCP 连接池管理,用户为不将短信发出,有意将数据库连接用户名改错,使得日志中有许多数据库连接异常的日志,一段时间后,就出现 OutOfMemory 错误。经分析,这是由于 DBCP 连接池 BUG 引起的,数据库连接不上后,没有将连接释放,最终使得D BCP 报OutOfMemory 错误。
上面这是一个简单的例子,比如还有其他的,代码中是否有死循环或递归调用。是否有大循环重复产生新对象实体。检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
比如我们这次内存溢出,就是因为一个很简答的导入功能,因为服务器给服务拆分的内存只有2G,而程序也没有专门的去处理,实施导入数据的时候,直接把100w的空数据从Excel中直接导入了,结果,直接导致了内存溢出。那么我们应该怎么去处理这个呢?
其实我们的比较简单,就是直接限定了文件的大小,因为Excel 虽然很大,但是有数据量的就那么几百行,100w行,都是空行数据,还都识别了,所以处理方式就那么几种,限制文件大小,限制读取数据的时候不读空行,因为毕竟内存大小是已经不允许我们做修改了,只能通过这个代码业务层面来处理这个了。
内存溢出的解决方案:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看OutOfMemory错误前是否有其它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
重点排查以下几点:
1.检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
2.检查代码中是否有死循环或递归调用。
3.检查是否有大循环重复产生新对象实体。
4.检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
第四步,使用内存查看工具动态查看内存使用情况
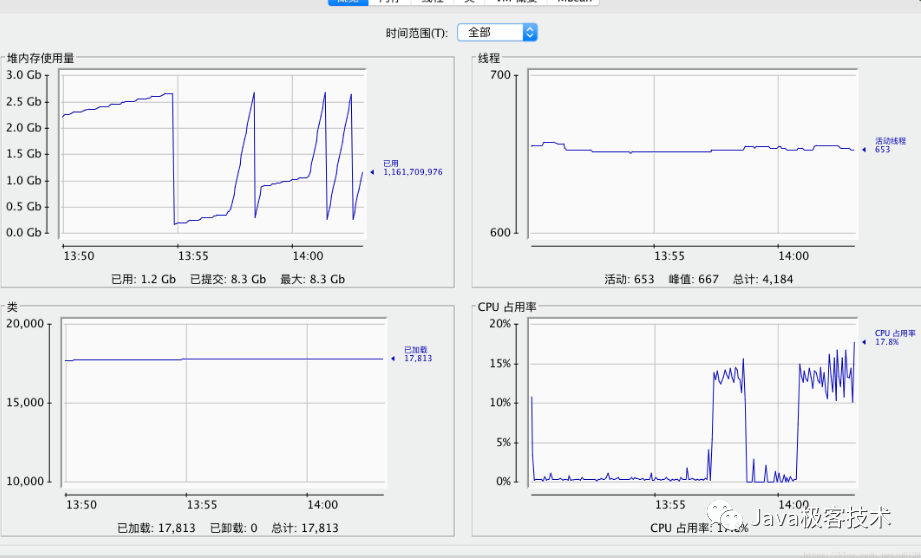
一般的,使用的工具有很多,MAT(Memory Analyzer Tool) 这个工具是一个比较好用的分析内存的工具,还有 jmeter 这个压力测试工具,可对特定接口进行压测,分析tps、响应时间、CPU、内存等性能指标。
JConsole、JVisualVM jdk 自带可视化工具,可监控CPU、内存、线程等状况。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我已经安装了最新版本的compass、sass和susy。但我仍然收到此错误:Unabletoactivatesusy-2.1.1,becausesass-3.2.17conflictswithsass(~>3.3.0)有人知道这个Ruby是如何工作的吗?这是我安装的gem的列表:***LOCALGEMS***CFPropertyList(2.2.0)chunky_png(1.3.0)compass(0.12.4)compass-core(1.0.0.alpha.19)compass-import-once(1.0.4)compass-rails(1.1.3)fssm(0.2.10)l
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_
我的两个不同的Rails应用程序的内存有一些奇怪的问题。这两个应用程序都使用rails3.0.7。每个Controller请求分配20-30-50MB的内存。在生产模式下,这个数量减少到5-10。但这是同样的事情。这是两个应用程序使用的gem列表:gem'pg'gem'haml'gem'sass'gem'devise'gem'simple_form'gem'state_machine'gem"globalize3","0.1.0.beta"gem"easy_globalize3_accessors"gem'paperclip'gem'andand'关闭所有这些gem不会给我任何结果。我
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
正如标题,我有一个处理大量数据的ruby程序。该程序占用了所有内存,其中调用了系统命令hostname,并且发生错误无法分配内存-主机名我试过GC.start但它不起作用。那么如何强制ruby释放未使用的内存呢?OK,这是别人的测试代码,最后报错是big_var被回收了。但是内存仍然没有释放。require"weakref"defreportputs"#{param}:\t\tMemory"+`psax-opid,rss|grep-E"^[[:space:]]*#{$$}"`.strip.split.map(&:to_i)[1].to_s+'KB'endbig_var=""#big
我想上传我在运行时用Ruby生成的数据,就像从block中提供上传数据一样。我找到的所有示例仅展示了如何流式传输必须在请求之前位于磁盘上的文件,但我不想缓冲该文件。除了滚动我自己的套接字连接之外,最好的解决方案是什么?这是一个伪代码示例:post_stream('127.0.0.1','/stream/')do|body|generate_xmldo|segment|body 最佳答案 有效的代码。require'thread'require'net/http'require'base64'require'openssl'class