
目录
2.2使用initializer_list仿写vector的构造函数
2.2vector、string和deque的shrink_to_fit
自C++11开始。C++的语法就开始不太像C++98和C了。
struct Point
{
int _x;
int _y;
};
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Point p1 = { 1,2 };
Point P2{ 1,2 };
int arr1[] = { 1,2 };
int arr2[]{ 1,2 };
int a1 = 1;
int a2 = { 2 };
int a3{ 3 };
// C++11中列表初始化也可以适用于new表达式中
int* p3 = new int[10];
int* p4 = new int[10] {1, 2, 3};
Point* p3 = new Point[2]{ { 1,1 },{ 2,2 } };
//创建对象时也可以使用列表初始化方式调用构造函数初始化
Date d1(1, 2, 3);
//C++11支持的列表初始化,这里会调用构造函数初始化
Date d2 = { 1,2,3 };//因为日期类支持三个参数的构造函数
Date d3{ 1,2,3 };
return 0;
};C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
initializer_list相当于一个容器,和vector很像,区别在于它不存储数据,有指针指向存储于常量区的数组。

这里的{}被识别成了一个类,这个类叫std::initializer_list。
上面的Date d2 = { 1,2,3 };是因为日期类支持了三个参数的构造函数,如果给它4个参数进行构造,将会报错。那为什么vector、list等支持不定参数的构造呢?并不是因为它们实现了多种不同参数的构造函数,而是因为这些容器中增加了std::initializer_list作为参数的构造函数。
int main()
{
//支持不定参数的构造
vector<int> v1 = { 1,2,3,4 };
vector<int> v2{ 1,2,3,4,5,6 };
return 0;
}vector中有一个initializer_list的构造函数,外部传参构造vector时,使用传入的参数先构造了一个initializer_list对象,initializer_list再将接收到的参数“push_back”进vector,这样vector就能够拥有不定参数的构造能力了。
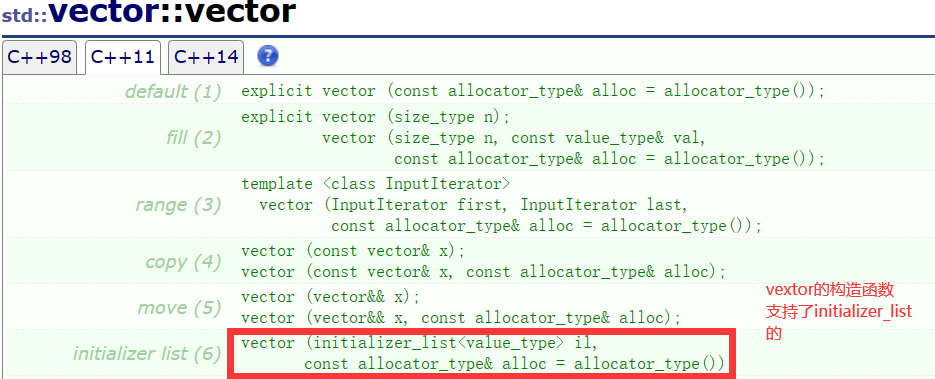
//里面的花括号是调用Date的构造函数,外面的花括号类型是initializer_list<Date>
vector<Date> v={{1,1,1,},{2,2,2},{3,3,3}};
//里面的花括号将生成pair的匿名对象,外面的花括号将生成initializer_list<pair<string,string>>的对象
map<string,string> dict = {{"字符串","string"},{"排序","sort"}};class vector
{
public:
vector(const initializer_list<T>& il)//initializer_list<T>& il是不行的,il具有常属性
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
typename initializer_list<T>::iterator it = il.begin();
while (it != il.end())
{
push_back(*it);
++it;
}
}
//......
};自动推导类型。非常好用。
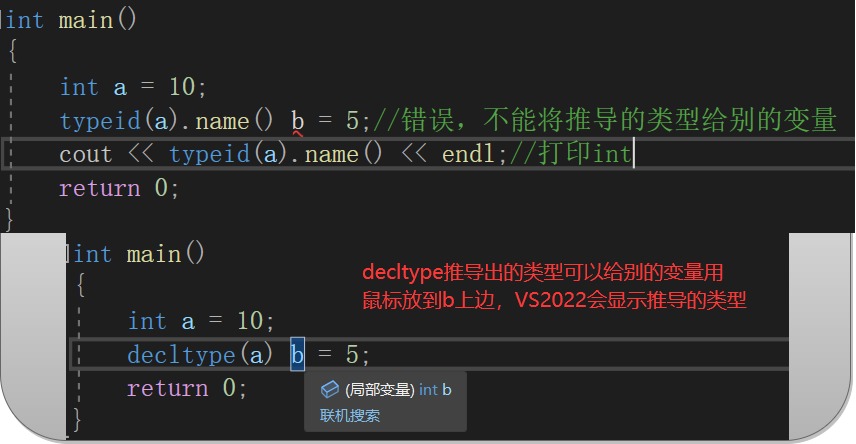
typeid(a).name()返回的是变量类型的字符串;
而decltype只能用于推导一个变量的类型,给另一个变量的类型进行定义。decltype的使用场景:
template<class T1, class T2>
void F(T1 t1, T2 t2)
{
//暂时不确定ret的类型,因为你不知道外部传入的T1,T2哪个会被提升
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}当然这个例子你用auto也行,所以decltype是一个没啥用的特性。
由于C++中NULL被定义成字面量0,这样就可能会带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif语法糖,本质是替换成迭代器。非常好用。
C++11中STL新增了<array>、<forward_list>、<unordered_set>、<unordered_map>,后面两个在往期博客中已经专门介绍过了。

array是固定大小的顺序容器。和vector相比,array中的数据并不要求挨着存储,所以并没有push_back。
array并不会对数组进行初始化,而vector的构造函数会对vector进行初始化。

array和普通数组在越界方面的比较:
普通数组对数组的边界是必检的,但对于其他位置则是抽查,如上图数组a1成功访问a1[20]的数据。
而array不一样,只要数组越界编译器必崩溃。
无论使用哪种方式玩定长数组都是可以的,不过个人认为写代码写出数组越界纯属个人菜,得认。
对于大多数的C系程序员来说,更愿意接受普通数组的写法,因为用习惯了,通俗易懂。其次,array并不会对数组进行初始化,它对数组越界进行了严格的检查,势必增加了开销,相对于普通数组唯一的优势是有错必报,但是vector不是比array更香吗?
这是一个单链表,只支持头插头删,不支持尾插尾删。
对比list的优点就是每一个节点可以节省一个指针的空间。
让人一看就知道这里调用的是const迭代器。
给vector提供了缩容方法。这可能会导致重新分配空间,但是不会影响vector的size。谁没事会去缩容啊。
很有用的特性,见【C++11】左值引用和右值引用。
性能强于C++98的push_back和insert等接口。具体见本文第六节。
final修饰类,表示该类不能被继承,final修饰虚函数,表示该虚函数不能被重写。
override修饰子类的虚函数,用于检查子类是否完成对该函数的重写。
lambda表达式的作用是创建一个匿名函数,可以在需要函数对象的地方使用。它通常用于函数式编程中,可以避免定义一个命名函数,从而简化代码。使用lambda表达式可以在代码中直接定义一个函数对象,并将其作为参数传递给其他函数或算法,或者直接调用它。lambda表达式可以捕获其所在作用域的变量,并将其作为函数对象的成员变量,从而实现闭包功能。使用lambda表达式可以使代码更加简洁、清晰,提高程序的可读性和可维护性。
lambda本质是一个匿名函数,其表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用,必须写;
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略;
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空);
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导;
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量,必须写。
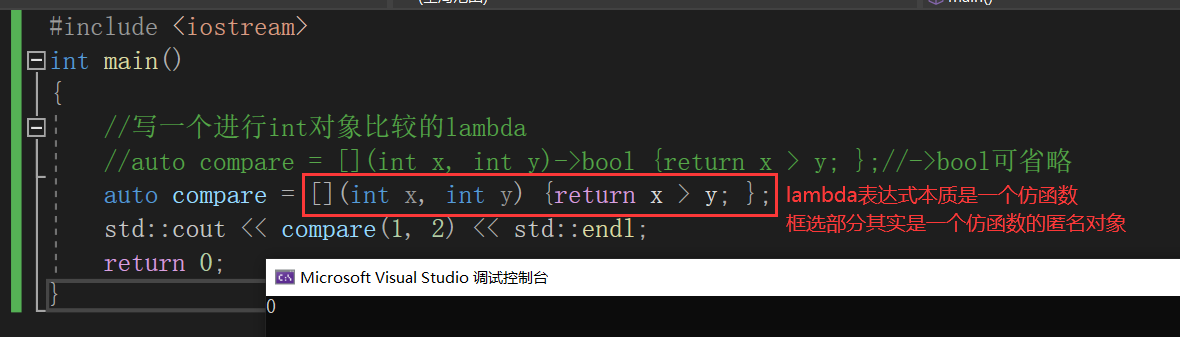
这是一段lambda表达式对外部参数b的捕获:
int main()
{
int a = 0, b = 1;
auto add = [b](int a) {return a + b; };//把上文的b捕捉到lambda表达式中
return 0;
}捕捉的真的是b吗?其实捕捉的仅仅是带const属性的b的拷贝罢了。可使用mutable取消拷贝对象的const属性:
auto add = [b](int a) mutable{return a + b; };//取消b的const属性现在我想用lambda表达式交换一下外部两个变量的值,那么就需要在捕捉列表中引用这两个变量:
int main()
{
int a = 0, b = 1;
auto swap = [&a, &b]()//这里是引用的方式捕捉,不是取地址
{
int tmp = a;
a = b;
b = tmp;
};
swap();
std::cout << a << " " << b << std::endl;
return 0;
}上面的lambda表达式的捕捉列表中的&a和&b其实是a和b的引用,不要理解成取地址。因为捕捉只有两种方式:传值捕捉和传引用捕捉。静态变量和全局变量无法捕捉,但可以在lambda表达式中直接使用并自带引用属性。
| [var] | 传值捕捉 |
| [&var] | 传引用捕捉 |
| [=] | 表示值传递方式捕获上文已出现的变量(包括this) |
| [&] | 表示引用传递捕捉上文已出现的变量(包括this) |
| [this] | 表示值传递方式捕捉当前的this指针 |
| [var1,&var2]、[=,&var]等 | 混合捕捉 |
| 无法重复捕捉,如:[=,var] | 捕捉列表不允许变量重复传递,否则就会导致编译错误。 |
| lambda表达式之间不能互相赋值 | / |

实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
C++11的新增特性可变参数模板能够让使用者创建可以接受可变参数的函数模板和类模板。
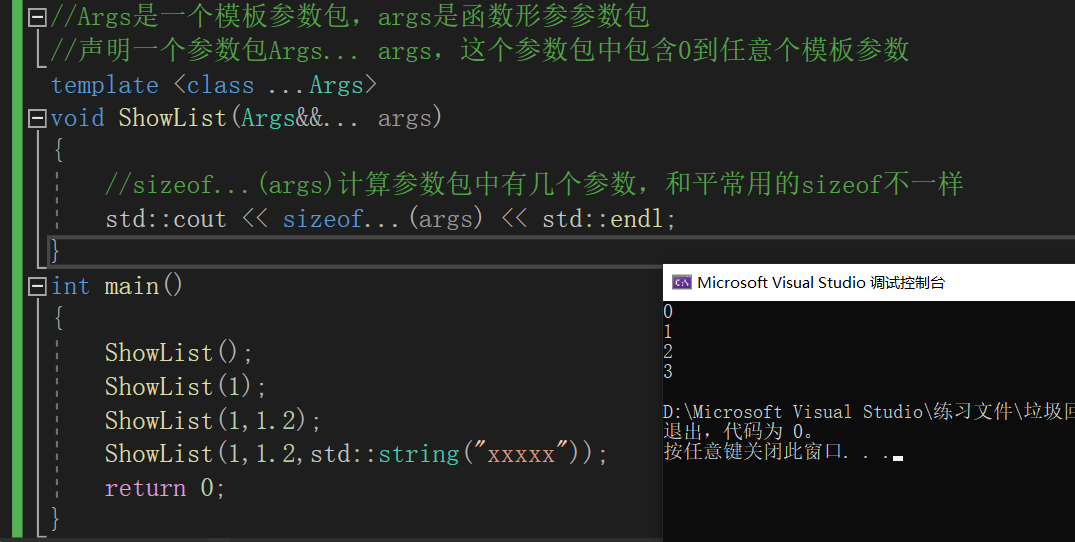
方式一:
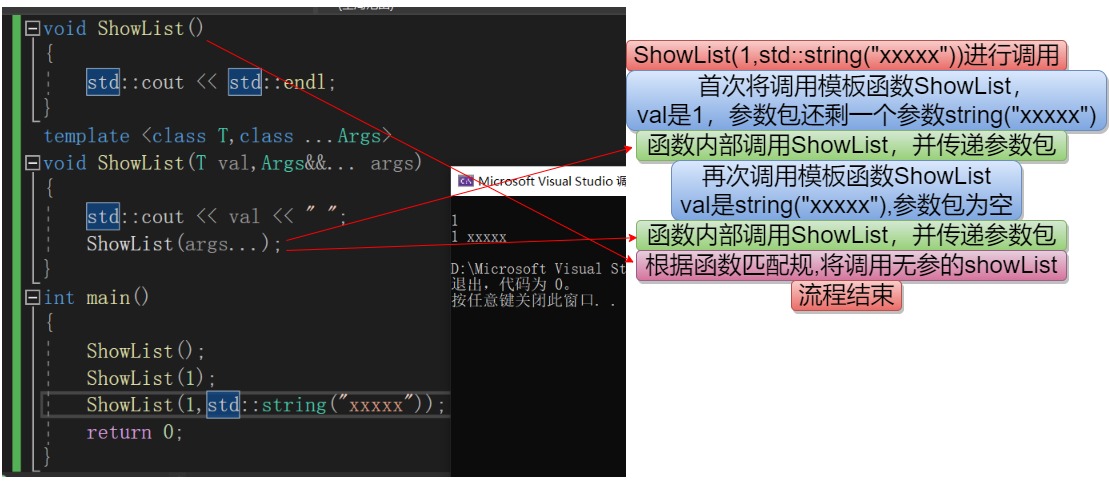
方式二:这种方式不能解析0个参数的参数包
template <class T>
int PrintArgs(T t)
{
std::cout << t << " ";
return 0;
}
template <class ...Args>
void ShowList(Args... args)
{
//int arr[] = { (PrintArgs(args),0)... };//逗号表达式
//参数包有几个值,数组就开多大,函数就被调用几次,函数调用时依次展开参数包中内容
int arr[] = { PrintArgs(args)... };
std::cout << std::endl;
}
int main()
{
//ShowList();
ShowList(1);
ShowList(1,std::string("xxxxx"));
return 0;
}int main()
{
std::list<int> list1;
list1.push_back(1);
list1.emplace_back(2);
list1.emplace_back();//会插入0
std::list< std::pair<int, char> > mylist;
mylist.push_back(make_pair(1, 'a')); // 构造+拷贝构造(如果是右值就是构造+移动构造)
//mylist.push_back(1, 'a');//push_back不允许传两个参数
mylist.push_back({ 40, "sort" });//列表初始化
mylist.emplace_back(1, 'a'); // empalce支持多参数,直接构造
return 0;
}int main()
{
pair<int, std::string> kv(20, "sort");
std::list< std::pair<int, std::string> > mylist;
mylist.push_back(kv); // 左值
mylist.push_back(make_pair(30, "sort")); // 右值
mylist.push_back({ 40, "sort" }); // 右值
mylist.emplace_back(kv); // 左值
mylist.emplace_back(make_pair(20, "sort")); // 右值(简化为一次构造)
mylist.emplace_back(10, "sort"); // 构造pair参数包(简化为一次构造)
return 0;
}无论是push_back还是emplace_back,尽量不要使用左值进行插入操作,插入左值必发生拷贝构造。
对于非深拷贝类型,push_back会调用构造+拷贝构造,如果元素是深拷贝的对象,就是构造+移动构造。
emplace_back方法会在容器尾部直接构造一个新元素,它的参数是元素的构造函数参数列表。emplace系列能将参数包展开,将过程简化为一次构造。
所以从效率上来说,emplace系列会高效一点.如果一个深拷贝的类没有实现移动构造,这个时候push_back的效率将远不如emplace_back。
function包装器,也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
function的作用是对各种可调用对象进行类型统一。
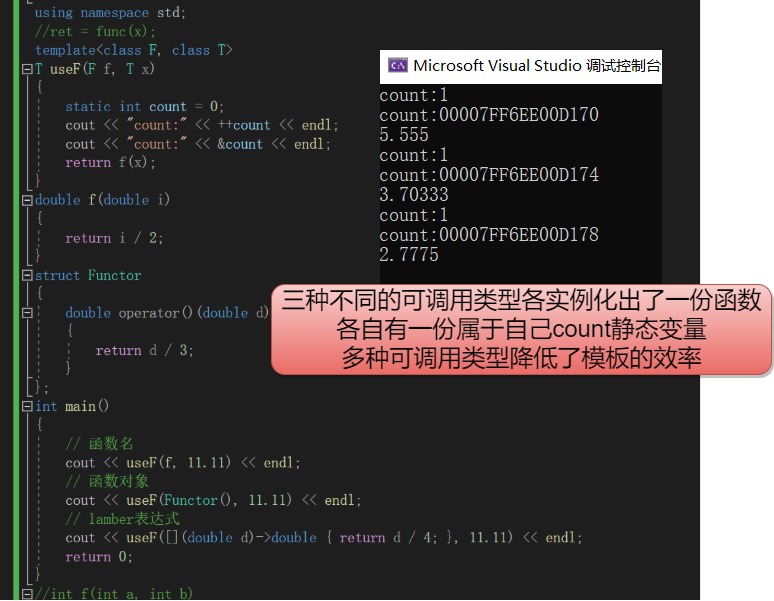
函数模板useF被实例化了三份,使用包装器可以解决这一问题。
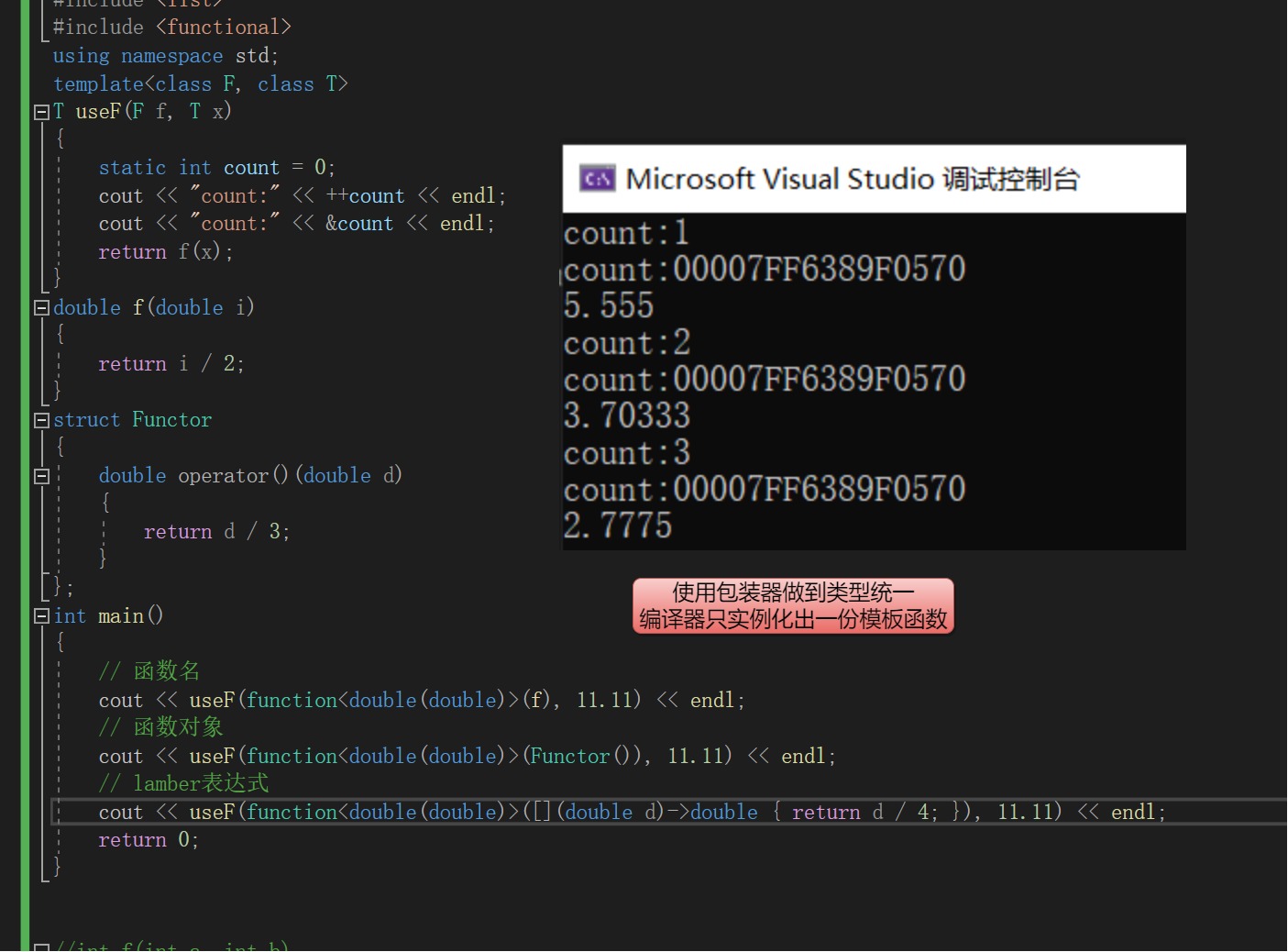
只要返回值和参数一样就可以用function进行统一封装。

int f(int a, int b)
{
return a + b;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
// 函数名(函数指针)的三种写法
function<int(int, int)> func1 = f;
cout << func1(1, 2) << endl;
function<int(int, int)> func2;
func2 = f;
cout << func2(1, 2) << endl;
function<int(int, int)> func3(f);
cout << func3(1, 2) << endl;
// 函数对象
function<int(int, int)> func4 = Functor();
cout << func4(1, 2) << endl;
// lamber表达式
function<int(int, int)> func5 = [](const int a, const int b)
{return a + b; };
cout << func5(1, 2) << endl;
// 类的成员函数,包装器的静态成员函数可以不加&取地址,普通函数需要加&取地址,建议一律加上
function<int(int, int)> func6 = &Plus::plusi;//类静态成员函数指针,&可加可不加
cout << func6(1, 2) << endl;
function<double(Plus, double, double)> func7 = &Plus::plusd;//类成员函数指针,&必须加,并且需要传类名
cout << func7(Plus(), 1.1, 2.2) << endl;//调用的时候得传对象,不是传&Plus的地址
//function包装带捕获的lambda表达式
Plus plus;
function<double(double, double)> func8 = [&plus](double x, double y)->double {return plus.plusd(x, y); };
cout << func8(1.1, 2.2) << endl;
return 0;
}
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
map<string,function<int(int,int)>> opFuncMap
{
{"+",[](int x,int y)->int{return x+y;}},
{"-",[](int x,int y)->int{return x-y;}},
{"*",[](int x,int y)->int{return x*y;}},
{"/",[](int x,int y)->int{return x/y;}}
};
for(auto& str:tokens)
{
if(opFuncMap.count(str)==0)//说明是数字
{
st.push(stoi(str));
}
else//说明是运算符
{
int right=st.top();
st.pop();
int left=st.top();
st.pop();
//执行算术操作,算完后将数据重新push进栈
st.push(opFuncMap[str](left,right));
}
}
return st.top();
}
};std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。可以用于固定绑定参数和调整参数的顺序。
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);int Plus(int a, int b)
{
return a + b;
}
int SubFunc(int a, int b)
{
return a - b;
}
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
//表示绑定函数Plus 参数分别由调用 func1 的第一,二个参数指定
::function<int(int, int)> func1 = ::bind(Plus, placeholders::_1,placeholders::_2);
cout << func1(1, 2) << endl;
function<int(int, int)> func2 = bind(SubFunc, placeholders::_1, placeholders::_2);
cout << func2(1, 2) << endl;
//调整参数的顺序
function<int(int, int)> func3 = bind(SubFunc, placeholders::_2, placeholders::_1);
cout << func3(1, 2) << endl;
function<bool(int, int)> gt = bind( less<int>(), placeholders::_2, placeholders::_1);//降序
cout << gt(1, 2) << endl;
//固定绑定参数
function<int(Sub, int, int)> func4 = &Sub::sub;
cout << func4(Sub(),1, 2) << endl;//这样写总是要传入一个类匿名对象进行打印
function<int(int, int)> func5 = bind(&Sub::sub, Sub(), placeholders::_1, placeholders::_2);//固定sub()
cout << func5(1, 2) << endl;
return 0;
}大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
我正在使用PostgreSQL9.1.3(x86_64-pc-linux-gnu上的PostgreSQL9.1.3,由gcc-4.6.real(Ubuntu/Linaro4.6.1-9ubuntu3)4.6.1,64位编译)和在ubuntu11.10上运行3.2.2或3.2.1。现在,我可以使用以下命令连接PostgreSQLsupostgres输入密码我可以看到postgres=#我将以下详细信息放在我的config/database.yml中并执行“railsdb”,它工作正常。开发:adapter:postgresqlencoding:utf8reconnect:falsedat
电脑上可以截取图片吗?如果可以,该如何操作呢?相信很多小伙伴都只知道一两种截图的方式,知道的并不全面。其实,电脑上有多种方式截图的,而且非常方便。电脑怎么截图?今天我们就来教大家如何使用电脑截取图片的8种常用方式!操作环境:演示机型:Delloptiplex7050系统版本:Windows10方法一:系统自带截图具体操作:同时按下电脑的自带截图键【Windows+shift+S】,可以选择其中一种方式来截取图片:截屏有矩形截屏、任意形状截屏、窗口截屏和全屏截图。 方法二:QQ截图具体操作:在电脑登录QQ,然后同时按下【Ctrl+Alt+A】,可以任意截图你需要的界面,可以把截图的页面直接下载,
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我目前有一个运行Ruby1.8.7和Rails2.3.2的RubyonRails项目我有一些从数据库中读取数据的单元测试,特别是两个连续项目的日期时间列,这两个项目应该相隔24小时。在一项测试中,我将项目2的日期时间设置为与项目1的日期时间相同。当我执行断言以确保两个值相等时,测试在rails2.3.2下工作正常。当我升级到rails2.3.11时,测试失败显示两次之间的差异将关闭并出现以下错误:expectedbutwas.这两个版本的rails中似乎存在浮点转换问题。如何解决float问题? 最佳答案 这也发生在我身上,我最终这
跳过联网激活:OOBE界面直接按Ctrl+Shift+F3进入审核模式。这样就可以直接进入系统进行一些硬件测试等,而不用联网激活导致新机无法退货。需要注意的是,在审核模式下进行的一些操作都会保留,并不会在退出后自动还原!安装的软件在正常开机进系统后还会看见!如果电脑确实没连互联网又不想强行跳过OOBE(网上很多教程会叫你直接结束OOBE进程,但这是不推荐的,因为一些厂商自带优化程序和系统初始化设置在后面都会应用,对于笔记本跳过的话你会发现驱动和内置应用都没有装上。其实这部分脚本就在系统盘的Recovery隐藏文件夹下),可以参考以下方式:https://www.landiannews.com/
1.Scenes游戏场景文件夹用于放置unity的场景文件 2.Plugins插件文件夹用于放置unity的依赖文件,例如dll 3.Scripts脚本文件夹用于放置unity的c#脚本文件 4.Resources游戏资源文件夹用于放置unity的各种游戏资源,比如images,prefabs,同时只有放到Resources文件夹的游戏资源才能使用Resource.load(资源路径不加后缀)加载到游戏内存中进行使用 5.EditorUnity编辑器扩展脚本文件夹usingUnityEditor;这个名称空间就是Unity编辑器的名称空间这个名称空间提供了扩展Unity编辑器的各种类 【你所有