 又一家中国互联网巨头在追赶ChatGPT了。
又一家中国互联网巨头在追赶ChatGPT了。3月底举行的博鳌亚洲论坛上,腾讯集团高级执行副总裁汤道生披露,腾讯正在研发AIGC以及大模型相关技术,类ChatGPT的对话机器人也在酝酿中。
百度、华为,如今再加上腾讯,ChatGPT出现之后,中国的互联网科技企业似乎一夜觉醒。不光公司,还有资本及创业大佬。
3月19日,创新工场董事长兼CEO李开复在朋友圈高调宣布,正在亲自筹组中文版ChatGPT公司“Project AI 2.0”。重燃创业野心的也不止李开复,美团王慧文、阿里贾扬清、搜狗王小川、京东周伯文均亲自下场,赶赴大模型赛道。
“大佬攒局”往往是赛道火热的信号,仅今年前三个月,上万家新注册的公司在经营范围中写上了人工智能。企业如雨后春笋般涌现,人才紧俏起来。应了周鸿祎那句话:一人捅破窗户纸,千军万马独木桥。
这一次不光是资本生意,还有需求催生。在人工智能上,以OpenAI为代表的抢跑选手引领自然语言大模型风潮,从产品上甩开中企老远,而中国还没有合格的ChatGPT满足各行各业对AIGC的体验。
腾讯们、李开复们现在做大模型还来得及吗?投入10年的李彦宏说,应用更靠谱。但真正稀缺的,仍然是底层基础设施。
作为目前全球最火的自然语言大模型产品,ChatGPT至今不对中国用户开放,背后的算法、芯片、数据更是全部被控制在美国公司手中。国产ChatGPT进入需求井喷期,一大批中国公司赶来,有互联网大厂,有资本大佬,也有创业公司,谁都不想错过这一次的AI革命。
3月19日,创新工场董事长兼CEO李开复在朋友圈宣布,成立Project AI 2.0公司,“不仅仅要做中文版 ChatGPT,”他这个公司定位为AI 2.0全新平台和AI-first生产力应用的“世界级公司”,野心颇大。
一个月前,美团联创王慧文在朋友圈发“英雄帖”,出资5000万美元,要创立新公司打造中国版OpenAI。此外,阿里巴巴“框架大神”贾扬清、搜狗前任CEO王小川、京东曾经的AI掌门人周伯文都表明了同样的意愿。
互联网大佬蜂拥入局,中国企业重燃热情,包括创业企业和上市公司。
企查查数据显示,近三个月共有108601家新注册业企业在经营范畴中标注了人工智能,同比增长超24%。《元宇宙日爆》统计,截至今年3月,已有20家上市公司布局了AIGC相关应用,涉及世纪虚拟人、AI写作、AI视频、AI绘画、AI营销等。
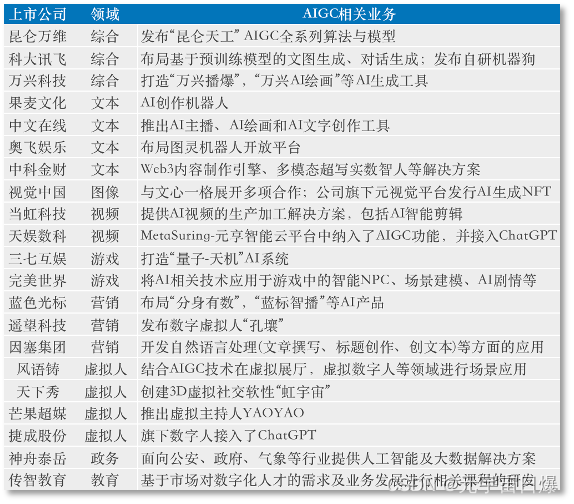
国内上市公司AIGC相关布局
AIGC创业公司千帆竞发,涉及领域包括上游的底层框架与工具、中游的行业服务、下游的包括文字、图像、视频、音频、游戏等应用场景,创业方向也从C端的娱乐游戏拓宽至工业、金融、医疗、教育等2B领域。不同应用场景已出现了一批代表性的玩家。

国内创业公司AIGC相关布局
而在底层大模型上,中国互联网科技巨头的动作则最受瞩目,包括百度、华为、腾讯在内大厂均有自然语言大模型布局。
3月16日,百度履行承诺,发布基于文心大模型的生成式AI产品文心一言,27日又面对企业发布了智能云AI底座文心千帆。
3月27日,华为云官网显示,旗下的盘古系列AI大模型即将上线,涉及NLP(自然语言)大模型、CV(计算机视觉)大模型和科学计算大模型(气象大模型)。
3月30日,腾讯集团高级执行副总裁汤道生披露,腾讯正在研发AIGC以及大模型相关技术,并向澎湃新闻表示,正在研发类ChatGPT的对话机器人,对于对于腾讯的聊天机器人是集成到QQ、微信,还是通过腾讯云向B端用户服务,汤道生说:“都会有。”
人工智能在当下的中国展现出全面开花的热闹。而资金雄厚、人才济济的大厂被视作最能与OpenAI比肩的选手。但最早发布产品的百度,其文心一言在文本、代码生成上尚不及ChatGPT的体验,图片生成的效果则被Midjourney拉开了距离。
赛道火热,产品不佳。中国的人工智能发展进入至暗时刻。缺的不仅是有实力的大模型,还有与之直接相关的人才和AI“三算”,即算力、算法、算据。
先是业内爆出,百度文心大模型团队内的研发人员近期受到了其他公司的疯狂追捧,有3年左右相关经验的员工,可以直接给到原先年薪的两倍。而有涉及海内外人才市场的猎头称,诸多互联网大厂的第一诉求就是就是想找OpenAI项目里的华人。猎聘大数据研究院的统计数据也显示,近一年,AIGC相关新发岗位同比增长了42.5%。
抢人大战不仅在国内上演。
由于一大批硅谷AI大牛排着队挤进OpenAI,谷歌一度遭遇AI人才流出。据外媒体统计,近几个月OpenAI已经雇用了超过12名谷歌的AI人才。
但从公开消息看,到目前为止,还没有哪位OpenAI背景的华人专家流入中国大厂。
AI人才紧俏,以芯片为核心硬件基础的算力一直被视为“卡脖子”的状态,而国产大模型的算据也与GPT-4存在肉眼可见的差距,预训练等大模型算法的距离直接以“肉眼可见”的产品拉胯摆在了用户面前。
在算据上,国产大模型也与GPT-4存在差距。
在自然语言大模型中,参数是衡量一个深度学习模型复杂度和能力的重要指标。参数多,意味着模型能够处理更多的数据,学习更多的知识。国外有研究人员将GPT参数规模与大脑神经元做类比,GPT-3的规模与刺猬大脑类似,GPT-4拥有100万亿个参数,基本达到人类大脑的规模。

大模型参数对比
再看国产大模型,即使是排名靠前的M6大模型,其参数规模也仍与GPT-4相差一个数量级,更多的大模型仍在“原始阶段”。
GPT-4百万亿的参数需要强大的算力来完成训练。算力,同样是AI的核心竞争要素,核心的核心是芯片。
在AI芯片竞争方面,英伟达处于垄断地位,该公司推出的A100与H100是目前性能最强的数据中心专用GPU,市面上几乎没有可替代的方案。ChatGPT的训练用的正是英伟达顶配版A100。
然而,在中美竞争下,A100与H100已被限制出口中国,中国厂商只能用阉割版A800芯片,数据传输速度被降低了30%,影响着AI集群的训练速度和效果。而国产优质芯片,虽能够为预训练大模型提供算力支撑,但仍存在明显差距。
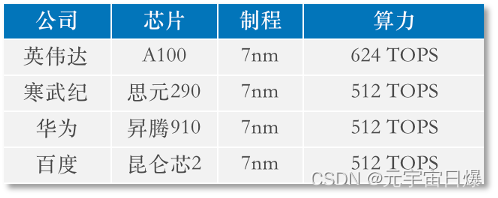
芯片性能对比
以OpenAI为例,该公司使用了数万块英伟达A100进行海量数据训练和推理。如果以1万枚英伟达A800 GPU为标准,仅CPU采购成本就超10亿美元。
如此现状下,国内的大模型研发机构面临两种选择,“烧钱”购买更多的芯片,等待国产芯片的算力突破。但现在的竞争态势下,等已经等不起了。
高昂的前期投入成本绝非普通创业公司可以负担,还要具备绝对顶尖的研发技术。很显然,AI大模型仍是巨头的游戏。但掌握先发优势的OpenAI以“日更”速度向前跃进,互联网巨头与资本面临着一场“烧钱”硬仗。
回顾ChatGPT的迭代,OpenAI至少进行了三次技术路线的"自我革命"。
从2018年GPT-1的推出到今年的GPT-4,OpenAI用了近5年。而百度在自然语言大模型的研发上用了10年。
连李彦宏也认为,中国基本不会再出现一个OpenAI,“没有必要再重新发明一遍轮子”,在他看来,“大模型时代,最大的创业机会在应用,”他的判断基于上一次的移动互联网变革,“操作系统其实没几个,最成功的是微信、抖音、淘宝这些应用。”他指出,未来10年,应用领域可能诞生10倍价值的机会。
周鸿祎也在公开场所表示,目前中国发展GPT技术,首先要占据应用场景,同步全力发展核心算法技术。为什么要同步?如果等算法赶上GPT-4再上马,市场就错过了。
另辟赛道,在现有大模型的基础上创新产品应用可能是大部分企业的超车机会。
就像移动互联网时代,尽管中国没有自己的操作系统,但仍有Tiktok这样的超级应用在海外市场杀出一片天。应用先行的优势是能快速的将AI生产力转化为商业价值,这是在移动互联网时代中国互联网企业探索出的超车捷径,也是在激烈的AI竞争中,大部分中企们赶超ChatGPT最经济、最现实的路径。
但由于GPT-3之后,OpenAI的所有模型就没有再开源,GPT-4的运行机制是什么,国内企业仍无从得知。
面对竞争对手全面的科技封锁,中国人工智能想要长期发展就不能没有“根”。旷视科技CEO印奇认为,中国攻坚 AI 大模型目前最重要的是要先能把GPT-3.5复现出来,"这是所有事情的起点"。
无论如何,发展好自身的硬实力,不在关键技术上被“卡脖子”,将是AI时代下中企们无法逃避的“必修课”。
针对国产AI大模型,周鸿祎指出:“发展大语言模型,别人已经指明了技术路线,剩下的就是长期主义指导下的时间问题,”他认为,“中国有能力发展自己的GPT,差距大概2年。”
百度有文心大模型,阿里有M6,华为的盘古大模型箭在弦上,腾讯的混元大模型也在不断迭代。当李开复、王慧文等一众互联网大佬也亲赴大模型战场时,底层的重要价值已经不言而喻了。
就像《三体》故事里的明喻一般,“基础科学”一旦被“智子”锁死,人类便永远失去探索宇宙真相的机会。底层大模型就是那个基础科学,在人工智能上,中国想要超越,不光需要资本、巨头,更需要的是能顶得住研发压力的“面壁人”。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
假设我有模型Topics和Posts,其中Topichas_many:posts和Postbelongs_to:topic。此时我的数据库中已经有了一些东西。如果我进入Rails控制台并输入Topic.find(1).posts我相信我得到了一个CollectionProxy对象。=>#]>我可以对此调用.each以获得枚举器对象。=>#]:each>我对CollectionProxy如何处理.each感到困惑。我意识到它在某些时候是继承的,但我一直在阅读API文档,他们并没有说得很清楚CollectionProxy是从什么继承的,除非我遗漏了一些明显的东西。Thispage似乎并没有
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
这里还有一个新手问题:require'tasks/rails'我在每个Rails项目的根路径中的Rakefile中看到了这一行。我猜这行用于要求vendor/rails/railties/lib/tasks/rails.rb加载所有rake任务:$VERBOSE=nil#LoadRailsrakefileextensionsDir["#{File.dirname(__FILE__)}/*.rake"].each{|ext|loadext}#LoadanycustomrakefileextensionsDir["#{RAILS_ROOT}/lib/tasks/**/*.rake"].so
当你安装一个新包时,例如,'geminstallfb-graph',文件下载到哪里了? 最佳答案 使用此命令查找特定gem的安装位置:gemwhich例如:gemwhichfb-graph 关于ruby-on-rails-Rubygems-包在哪里下载?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/13200065/
在Rails中向整数类添加方法的最佳位置在哪里?我想添加一个to_meters和to_miles方法。 最佳答案 如果您决心使用数字(或整数等)类来进行单位转换,那么至少要在逻辑上做到这一点,并具有一些实际值(value)。首先,创建一个Unit类,用于存储单位类型(米、英尺、肘等)和创建时的值。然后向Numeric添加一堆方法,这些方法对应于单元可以具有的有效值:这些方法将返回一个单元对象,其类型记录为方法名称。Unit类将支持一组to_*方法,这些方法将转换为具有相应单位值的另一种单位类型。这样,您可以执行以下命令:>>x=47
我有时遇到过Array(value)、String(value)和Integer(value)形式的转换。在我看来,这些只是调用相应的value.to_a、value.to_s或value.to_i方法的语法糖。所以我想知道:这些是在哪里/如何定义的?我在对象、模块、类等中找不到它们是否有任何常见场景更适合使用这些而不是相应/底层的to_X方法?这些可以用于泛型强制转换吗?也就是说,我可以按照[Integer,String,Array].each{|klass|klass.do_generic_coercion(foo)}?(...不,我真的不想那样做;我知道我想要的类型,但我希望避免
例如,如果我们defc=(foo)p"hello"endc=3c=(3)并且不会打印“hello”。我知道它可以被self.c=3调用,但为什么呢?可以通过哪些其他方式调用它? 最佳答案 c=3(和c=(3),完全等同于它)总是被解释为局部变量赋值。你可能会说只有当方法c=没有在self上定义时,它才应该被解释为局部变量赋值,但是这有很多问题:至少MRI需要在解析时知道在给定范围内定义了哪些局部变量。但是,在解析时并不知道给定的方法是否已定义。所以ruby直到运行时才知道c=3是否定义了变量c或者调用了方法c=,这意味着它不会知
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans