yolov5修改骨干网络–原网络说明
yolov5修改骨干网络-使用pytorch自带的网络-以Mobilenet和efficientnet为例
yolov5修改骨干网络-使用自己搭建的网络-以efficientnetv2为例
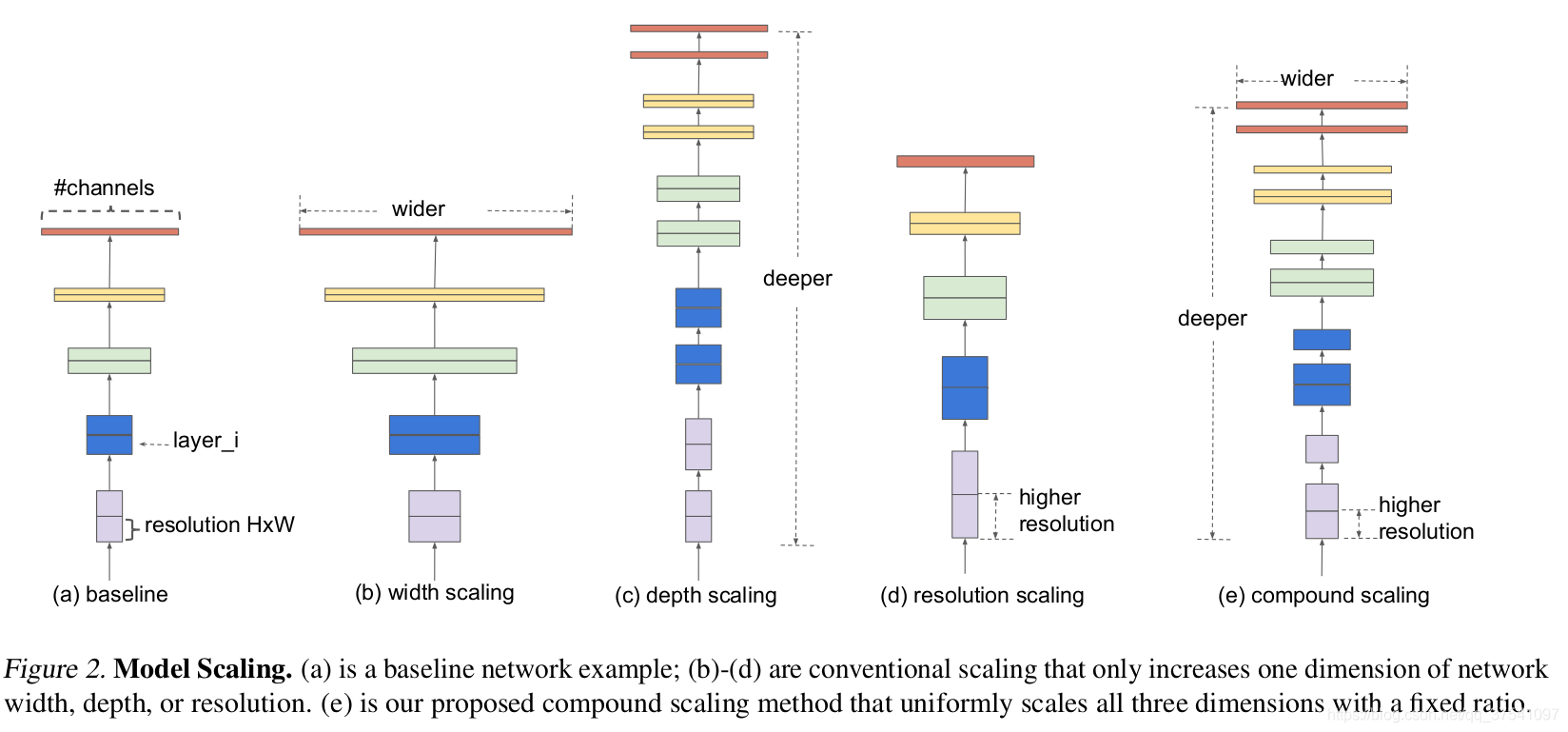
efficientnet则是通过NAS搜索,同时增加width、depth以及resolution,使网络结构达到最优。
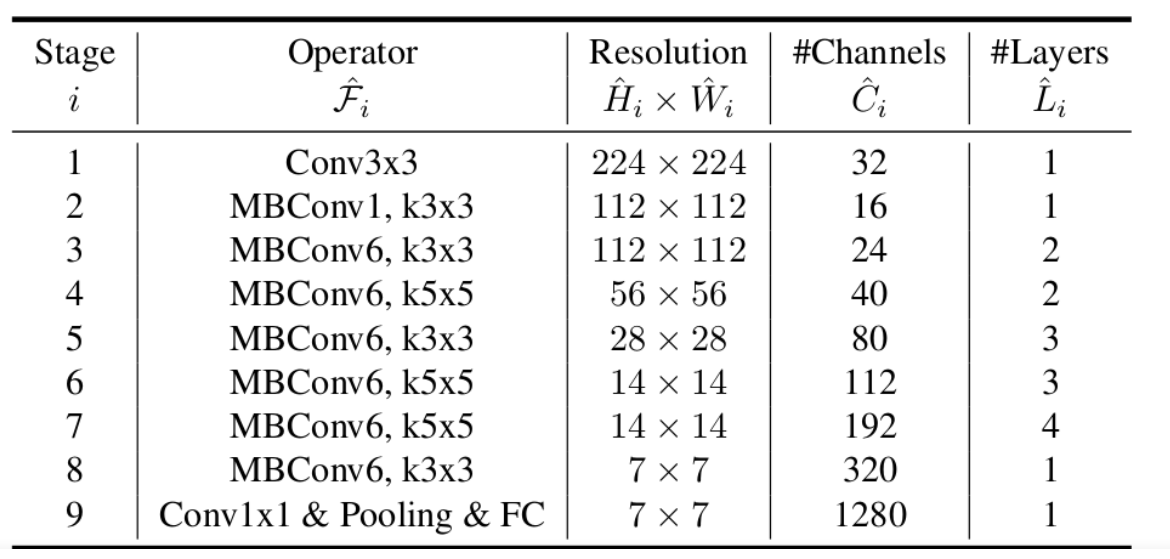
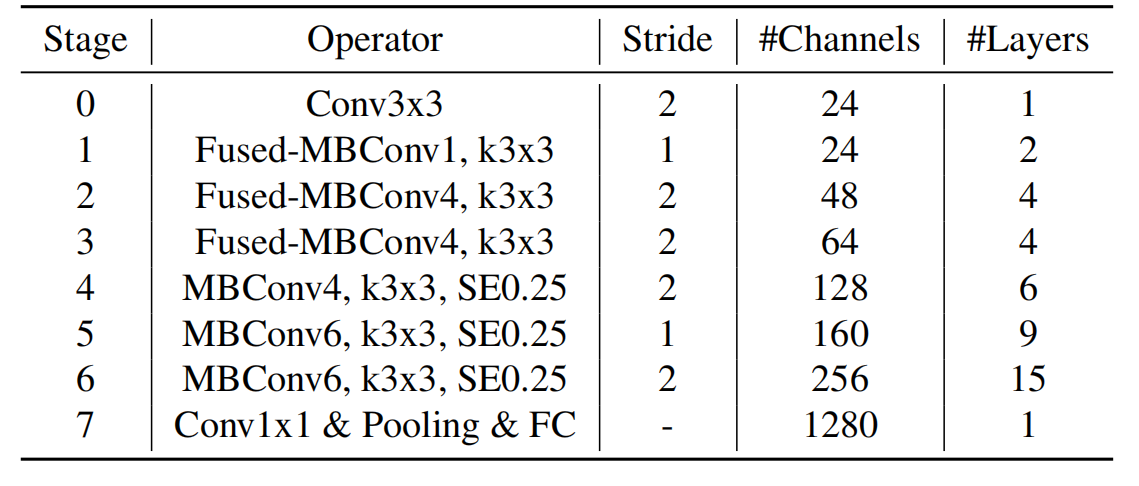
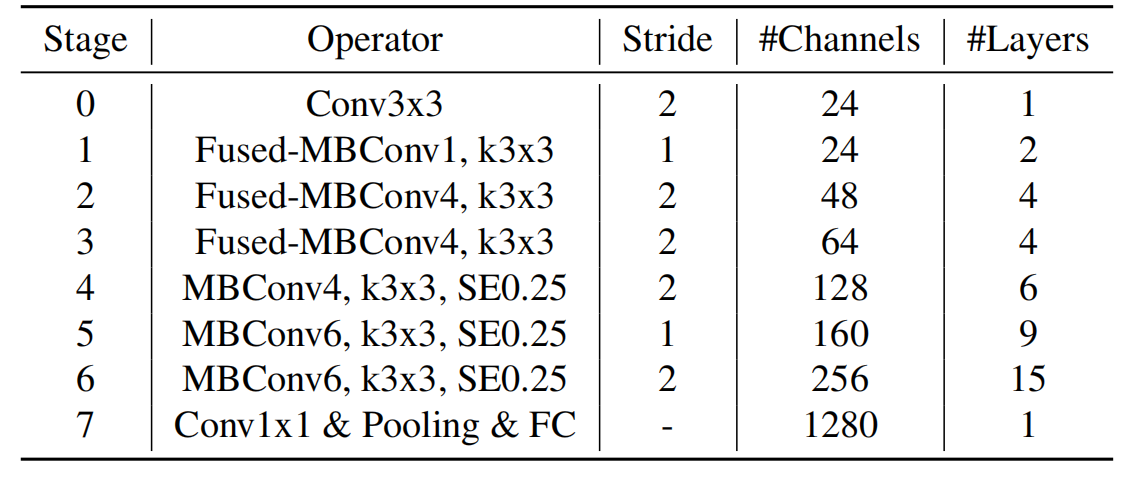
下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage。
第一个Stage是一个卷积核大小为3x3,stride为2的普通卷积层(包含BN和Swish激活函数);
Stage2~Stage8都是在重复堆叠MBConv结构(Layers表示该Stage重复MBConv结构多少次),Stage9由一个普通的1x1的卷积层 + 平均池化层 + 全连接层组成。
MBConv后的1或6就是倍率因子n,即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
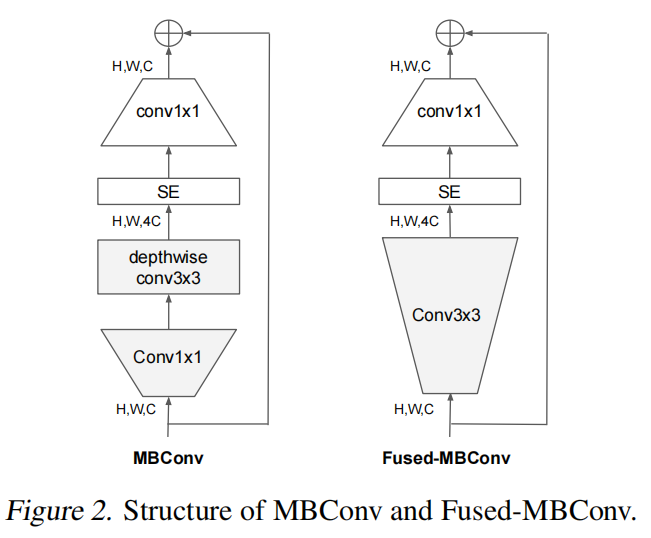
MBConv结构如下:

MBConv主要由一个 1x1 的卷积进行升维 (它的卷积核个数是输入特征矩阵channel的n倍,
n
∈
{
1
,
6
}
n \in \left\{1, 6\right\}
n∈{1,6},当n=1时,不升维),一个kxk的Depthwise Conv卷积,k主要有3x3和5x5两种情况,一个SE模块,然后接一个1x1的普通卷积进行降维作用,再加一个Droupout,最后再进行特征图融合。
仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时shortcut连接才存在(代码中可通过stride== 1 and inputc_channels==output_channels条件来判断)
SE模块,由一个全局平均池化,两个全连接层组成。
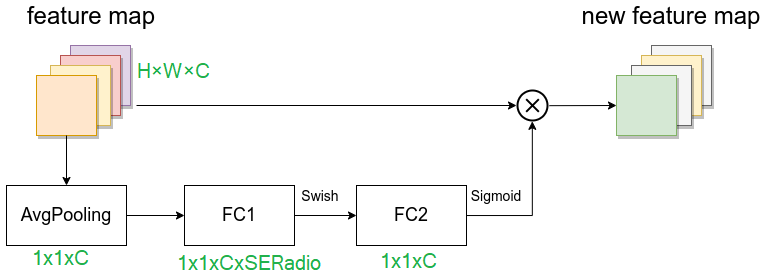
假设输入图像H×W×C,第一个全连接层的节点个数是输入该MBConv特征矩阵 channels 乘SERadio,一般SERadio为 0.25,所以channe为 C 4 \frac{C}{4} 4C ,然后是Swish激活函数。
第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵 channels,即 C C C,且使用Sigmoid激活函数,这样就拉伸成了1×1×C,然后再与原图像相乘,将每个通道赋予权重。这样就实现了注意力。
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
Dropout层在源码实现中只有使用shortcut的时候才有Dropout层。
EfficientNetV1在训练图像的尺寸很大时,训练速度非常慢,而且非常吃显存。
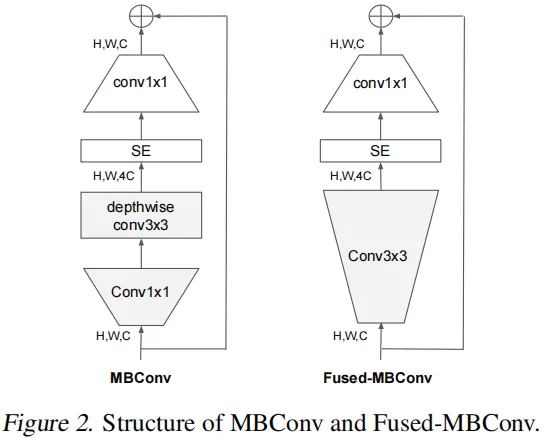
在网络浅层中使用Depthwise convolutions速度会很慢。虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器,于是有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。
Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的 conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图所示。
EfficientNetV2网络框架相比与EfficientNetV1,主要有以下不同:
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN
Fused-MBConv 模块模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。
当stride=1且输入输出channel相等时才有shortcut连接。
当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。
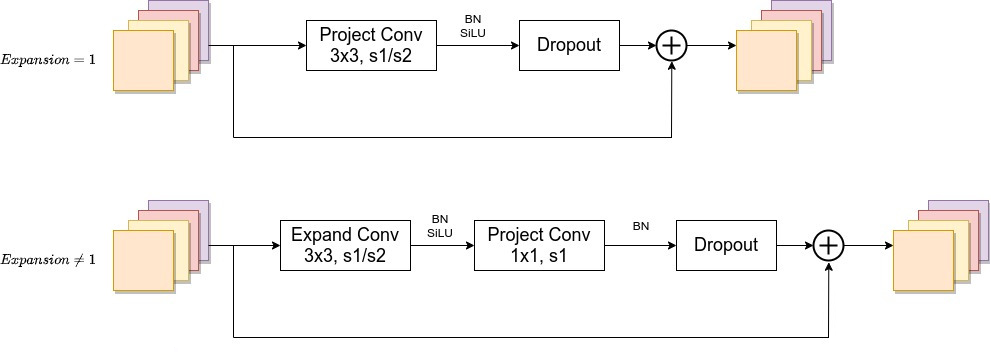
MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的
1
4
\frac{1}{4}
41
注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。

Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,Layers表示该Stage重复堆叠Operator的次数。
根据这个结构图进行代码编写,首先是一个步长为2的3x3矩阵,输出channel为24,后面当然也是有bn+激活的。这里先写一个base,通过修改yaml文件对其操作。
这一行的yaml参数应该如下:[-1, 1, stem, [24, 3, 2]],
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
# kernel_size为3时,padding 为1,kernel为1时,padding为0
padding = (kernel_size - 1) // 2
# 由于要加bn层,所以不加偏置
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
然后是FusedMBConv,根据这个流程图编写:
注意,FusedMBConv是没有SE模块的,虽然上面画了SE。
Fused-MBConv1 后面这个1表示expansion=1,不升维;若不等于1,则升维到原维度的n倍;
后面layers=2表示使用两次这个bolck,所以第一个Fused-MBConv1, k3x3的yaml参数应为[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]]
[24:out_channer, 3:kernel_size, 1:stride,1:expansion, 0:se_ration]
# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
# 当stride=1且输入输出Channels相等时才有shortcut连接,只有使用shortcut时,才用dropout
self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接
# expansion是为了先升维,再卷积,再降维,再残差
self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
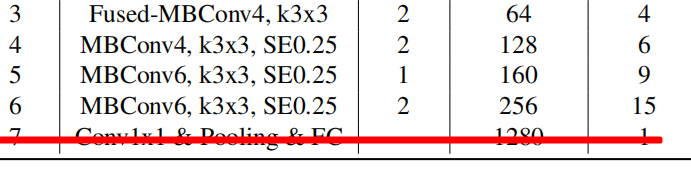
stage2: Fused-MBConv4, k3x3 2 48 4 表示用kernelsize=3的卷积核,先升维4倍,outchannel=48,重复四次,注意stride=2只有在第一次重复时才有,后面三次的stride都是1,所以yaml应该写为:
第一个的stride为2
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]]
后面三个的stride为1
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]]
同理stage 3 Fused-MBConv4, k3x3 2 64 4
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]],
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]],
然后是stage 4 MBConv4, k3x3, SE0.25 2 128 6 表示6个MBConv模块,第一次用kernel size=3的卷积核升维四倍,SERadio为0.25,第一次的stride为2,后三次为1,输出channel为128。
yaml参数就应该为:
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 先用步长为2的卷积
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 后面5个block用步长为1的卷积
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
self.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# 先用1x1的卷积增加升维
result = self.expansion_conv(x)
# 再用一般的卷积特征提取
result = self.dw_conv(result)
# 添加se模块
result = self.se(result)
# 再用1x1的卷积降维
result = self.project_conv(result)
# 如果使用shortcut连接,则加入dropout操作
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了
result += x
return result
同理stage5和stage6的参数分别为:
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]],
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]],
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]],
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]],
注意,我们不需要stage7,因为我们只需要进行特征提取,不需要进行分类
然后是修改concat连接的位置:
下面注释中很清晰的写了特征图大小变化,以及为什么要和那一层连接。默认输入图片尺寸为640*640
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
[[-1, 1, stem, [24, 3, 2]], # 0-P1/2 efficientnetv2 一开始是Stem = 普通的卷积+bn+激活 640*640*3 --> 320*320*24
# # [out_channel,kernel_size,stride,expansion,se_ration]
[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1 2个FusedMBConv=3*3conv+se+1*1conv 320*320*24-->320*320*24
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2 这里strid2=2,特征图尺寸缩小一半,expansion=4输出特征图的深度变为原来的4倍 320*320*24-->160*160*48
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3 三个FusedMBConv
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4 160*160*48-->80*80*64
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6 这里strid2=2,特征图尺寸缩小一半, 40*40*128
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8 这里 strid2=2,特征图尺寸缩小一半,20*20*160
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]], # 10 这里strid2=2,特征图尺寸缩小一半,10*10*160
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]], # 11
[-1, 1, SPPF, [1024, 5]], #12
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 13 10*10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14 20*20
[[-1, 9], 1, Concat, [1]], # 15 cat backbone P4 15 这里特征图大小为20*20,所以应该和9号连接
[-1, 3, C3, [512, False]], # 16 20*20
[-1, 1, Conv, [256, 1, 1]], #17 20*20
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #18 40*40
[[-1, 7], 1, Concat, [1]], # cat backbone P3 19 7号特征图大小也是40*40
[-1, 3, C3, [256, False]], # 20 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], #21 卷积步长为2,所以特征图尺寸缩小,为 20*20
[[-1, 17], 1, Concat, [1]], # cat head P4 17层的特征图也是20*20
[-1, 3, C3, [512, False]], # 23 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 24 10*10
[[-1, 13], 1, Concat, [1]], # cat head P5 13层的特征图大小就是10*10
[-1, 3, C3, [1024, False]], # 26 (P5/32-large)
[[20, 23, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
然后是修改yolo.py,这边很好改,后面加上stem, FusedMBConv, MBConv
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF....
stem, FusedMBConv, MBConv]
common.py中应该添加的efficientnet代码如下:
# ------------------------------efficientnetv2--------------------------------------
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
# kernel_size为3时,padding 为1,kernel为1时,padding为0
padding = (kernel_size - 1) // 2
# 由于要加bn层,所以不加偏置
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
# shorcut 是指到残差结构 expansion是为了先升维,再卷积,再降维,再残差
self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接
self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
self.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# 先用1x1的卷积增加升维
result = self.expansion_conv(x)
# 再用一般的卷积特征提取
result = self.dw_conv(result)
# 添加se模块
result = self.se(result)
# 再用1x1的卷积降维
result = self.project_conv(result)
# 如果使用shortcut连接,则加入dropout操作
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了
result += x
return result
# ------------------------------efficientnetv2--------------------------------------
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po