canal 是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
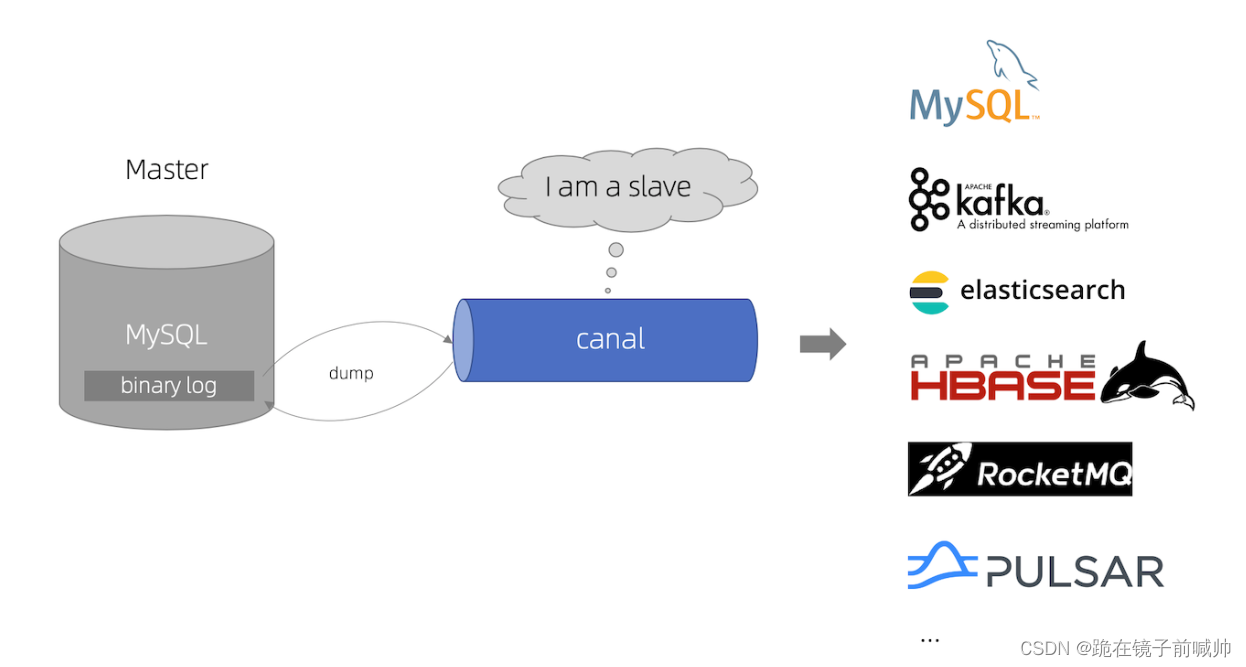
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
基于日志增量订阅和消费的业务包括
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
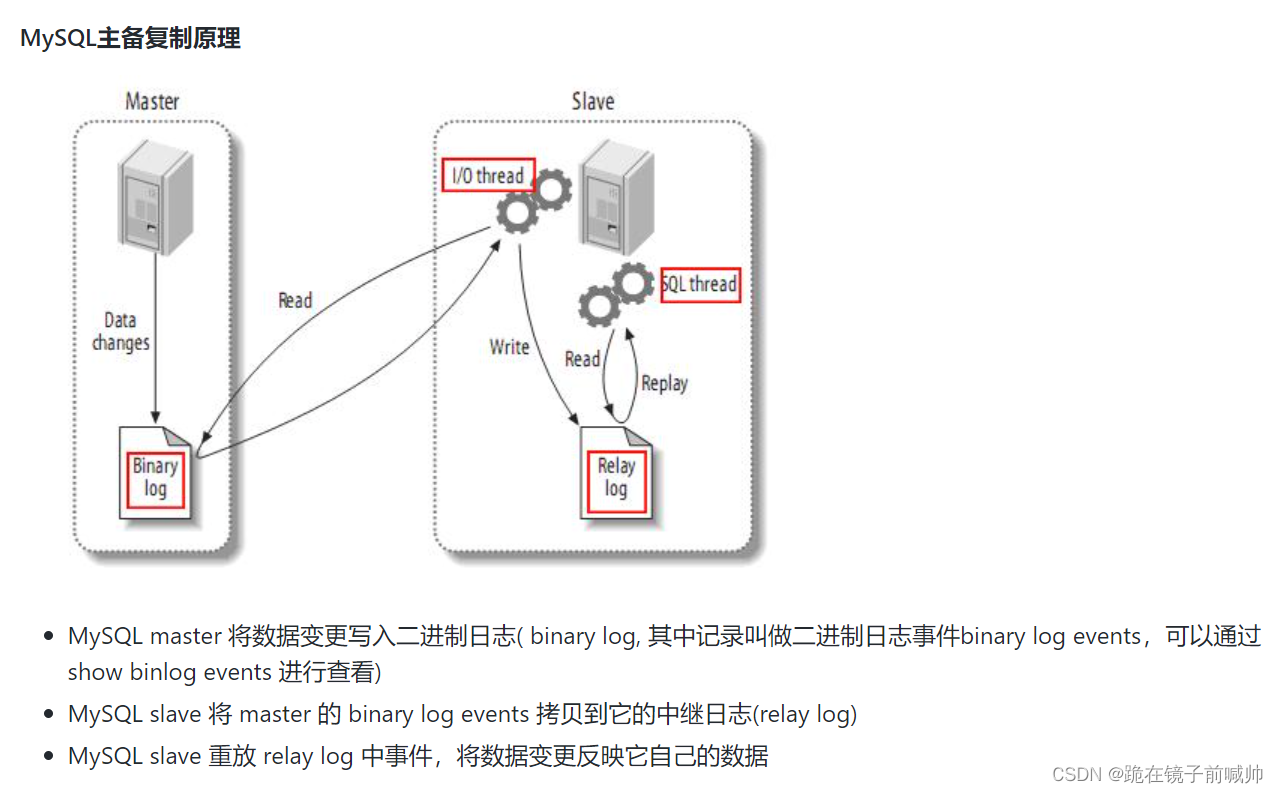
Canal工作原理
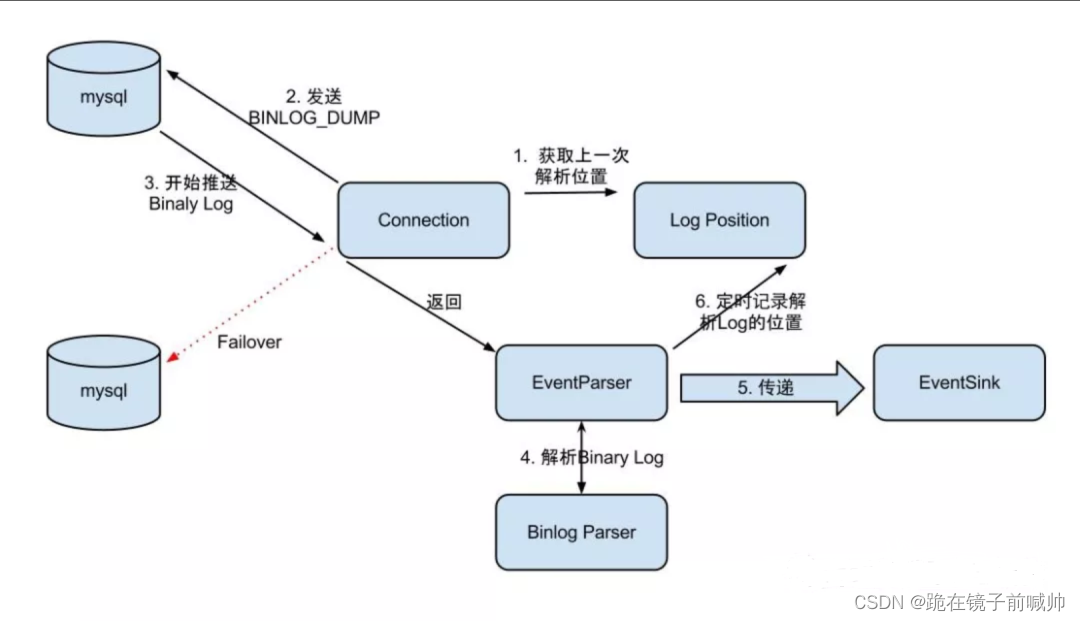
EventParser在向MySQL发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功 ),传送成功之后更新Log Position。流程图如下:
Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]
void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
void ack(long batchId),顾名思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
准备
log-bin=mysql-bin #binlog文件名
binlog_format=ROW #选择row模式
server_id=1 #mysql实例id,不能和canal的slaveId重复
注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
MySQL的binLog
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
启动
canal-adapter(canal-client)
相当于canal的客户端,会从canal-server中获取数据(需要配置为tcp方式),然后对数据进行同步,可以同步到MySQL、Elasticsearch和HBase等存储中去。相较于canal-server自带的canal.serverMode,canal-adapter提供的下游数据接受更为广泛。
canal-admin
为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
canal-deployer(canal-server)
可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。接收到MySQL的binlog数据后可以通过配置canal.serverMode:tcp, kafka, rocketMQ, rabbitMQ连接方式发送到对应的下游。其中tcp方式可以自定义canal客户端进行接受数据,较为灵活。
#################################################
## mysql serverId , v1.0.26+ will autoGen
# mysql 集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定)
canal.instance.mysql.slaveId=1212
# enable gtid use true/false
# 是否启用mysql gtid的订阅模式
canal.instance.gtidon=false
# position info
# mysql 主库链接地址
canal.instance.master.address=127.0.0.1:3306
# mysql 主库链接时起始的binlog文件
canal.instance.master.journal.name=
# mysql 主库链接时起始的binlog偏移量
canal.instance.master.position=
# mysql 主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
# mysql 主库链接时对应的gtid位点
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
# aliyun rds 对应的实例id信息(如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值)
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
# mysql 数据库帐号
canal.instance.dbUsername=canal
# mysql 数据库密码
canal.instance.dbPassword=canal
# mysql 数据解析编码,代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
# mysql 数据解析关注的表,Perl正则表达式,多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
# 注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
canal.instance.filter.regex=.*\\..*
# table black regex
# mysql 数据解析表的黑名单,表达式规则见白名单的规则
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=yang
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
#如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
常见的匹配规则:
所有表:.* or .\…
canal schema下所有表: canal\…*
canal下的以canal打头的表:canal.canal.*
canal schema下的一张表:canal.test1
多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
进入bin目录下启动虚拟机的mysql
工程搭建
# 服务端口
server.port=10000
# 服务名
spring.application.name=canal-client
# 环境设置:dev、test、prod
spring.profiles.active=dev
# mysql数据库连接
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/yang?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&useSSL=true&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=root
# 监听样例使用
# canal.client.instances.example.host=127.0.0.1
# canal.client.instances.example.port=11111
canal 依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
其他依赖(用则添加)
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
官网样例
package com.example.canal.yang;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import org.springframework.stereotype.Component;
import java.net.InetSocketAddress;
import java.util.List;
@Component
public class CanalClient {
private final static int BATCH_SIZE = 1000;
/**
* @Description: canal 客户端
* @Author: yangjj_tc
* @Date: 2022/11/11 11:38
*/
public void run() throws Exception {
// 创建链接
CanalConnector connector =
CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "canal", "canal");
try {
// 打开连接
connector.connect();
// 订阅数据库表,来覆盖服务端初始化时的设置
connector.subscribe(".*\..*");
// 回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(BATCH_SIZE);
// 获取批量ID
long batchId = message.getId();
// 获取批量的数量
int size = message.getEntries().size();
// 如果没有数据
if (batchId == -1 || size == 0) {
try {
// 线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
// 如果有数据,处理数据
printEntry(message.getEntries());
}
// 进行 batch id 的确认
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
/**
* @Description: canal server 解析binlog获得的实体类信息
* @Author: yangjj_tc
* @Date: 2022/11/11 11:37
*/
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == EntryType.TRANSACTIONEND) {
// 开启/关闭事务的实体类型,跳过
continue;
}
// RowChange对象,包含了一行数据变化的所有特征
RowChange rowChage;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
// 获取操作类型:insert/update/delete类型
EventType eventType = rowChage.getEventType();
// 打印Header信息
System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
// 判断是否是DDL语句
if (rowChage.getIsDdl()) {
System.out.println("================》;isDdl: true,sql:" + rowChage.getSql());
}
// 获取RowChange对象里的每一行数据,打印出来
for (RowData rowData : rowChage.getRowDatasList()) {
// 如果是删除语句
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
// 如果是新增语句
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
// 如果是更新的语句
} else {
// 变更前的数据
System.out.println("------->; before");
printColumn(rowData.getBeforeColumnsList());
// 变更后的数据
System.out.println("------->; after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
表数据同步样例
package com.example.canal.yang;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.net.InetSocketAddress;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
@Component
public class CanalClient {
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Resource
private DataSource dataSource;
public void run() {
CanalConnector connector =
CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
int batchSize = 1000;
try {
connector.connect();
connector.subscribe("canal.canal_test");
connector.rollback();
try {
while (true) {
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(1000);
} else {
dataHandle(message.getEntries());
}
connector.ack(batchId);
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
} finally {
connector.disconnect();
}
}
private void dataHandle(List<Entry> entrys) throws InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (EntryType.ROWDATA == entry.getEntryType()) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
if (eventType == EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
private void saveDeleteSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " + entry.getHeader().getTableName() + " where ");
for (Column column : columnList) {
if (column.getIsKey()) {
// 暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
private void saveUpdateSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " + entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName() + " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<Column> oldColumnList = rowData.getBeforeColumnsList();
for (Column column : oldColumnList) {
if (column.getIsKey()) {
// 暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
private void saveInsertSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " + entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
System.out.println("[sql]----> " + sql);
this.execute(sql.toString());
}
}
public void execute(String sql) {
Connection con = null;
try {
if (null == sql)
return;
con = dataSource.getConnection();
QueryRunner qr = new QueryRunner();
int row = qr.execute(con, sql);
System.out.println("update: " + row);
} catch (SQLException e) {
e.printStackTrace();
} finally {
DbUtils.closeQuietly(con);
}
}
}
注解监听样例(依赖下载不下来用这个导入到项目)
<dependency>
<groupId>com.xpand</groupId>
<artifactId>starter-canal</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
package com.example.canal.yang;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.xpand.starter.canal.annotation.*;
@CanalEventListener
public class CanalDataEventListener {
/**
* @Description: 增加数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:16
*/
@InsertListenPoint
public void onEventInsert(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
rowData.getAfterColumnsList()
.forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
/**
* @Description: 修改数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:17
*/
@UpdateListenPoint
public void onEventUpdate(CanalEntry.RowData rowData) {
System.out.println("UpdateListenPoint");
rowData.getAfterColumnsList()
.forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
/**
* @Description: 删除数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:17
*/
@DeleteListenPoint
public void onEventDelete(CanalEntry.EventType eventType) {
System.out.println("DeleteListenPoint");
}
/**
* @Description: 自定义数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:18
*/
@ListenPoint(destination = "example", schema = "canal", table = {"canal_test", "tb_order"},
eventType = CanalEntry.EventType.UPDATE)
public void onEventCustomUpdate(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
System.err.println("DeleteListenPoint");
rowData.getAfterColumnsList()
.forEach((c) -> System.out.println("By--Annotation: " + c.getName() + " :: " + c.getValue()));
}
@ListenPoint(destination = "example", schema = "canal", // 所要监听的数据库名
table = {"canal_test"}, // 所要监听的数据库表名
eventType = {CanalEntry.EventType.UPDATE, CanalEntry.EventType.INSERT, CanalEntry.EventType.DELETE})
public void onEventCustomUpdateForTbUser(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
getChangeValue(eventType, rowData);
}
public static void getChangeValue(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
if (eventType == CanalEntry.EventType.DELETE) {
rowData.getBeforeColumnsList().forEach(column -> {
// 获取删除前的数据
System.out.println(column.getName() + " == " + column.getValue());
});
} else {
rowData.getBeforeColumnsList().forEach(column -> {
// 打印改变前的字段名和值
System.out.println(column.getName() + " == " + column.getValue());
});
rowData.getAfterColumnsList().forEach(column -> {
// 打印改变后的字段名和值
System.out.println(column.getName() + " == " + column.getValue());
});
}
}
}
开始测试,首先启动MySQL、Canal Server,还有刚刚写的Spring Boot项目。然后创建表:
DROP TABLE IF EXISTS `canal_test`;
CREATE TABLE `canal_test` (
`id` int NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`age` int NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
如果新增一条数据到表中:
INSERT INTO `yang`.`canal_test` (`id`, `name`, `age`) VALUES (1, '1', 1);

canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。实时性也能做到准实时,其实是很多企业一种比较常见的数据同步的方案。
通过上面的学习之后,我们应该都明白canal是什么,它的原理,还有用法。实际上这仅仅只是入门,实际项目我们是配置MQ模式,配合RocketMQ或者Kafka,canal会把数据发送到MQ的topic中,然后通过消息队列的消费者进行处理。
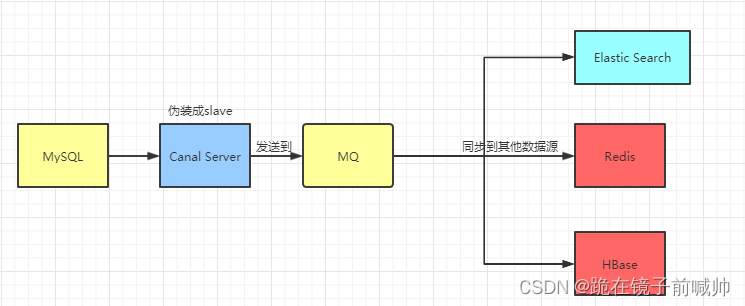
Canal的部署也是支持集群的,需要配合ZooKeeper进行集群管理。
Canal还有一个简单的Web管理界面。
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D
我正在尝试找到一种更好的方法将IRB与我的常规ruby开发集成。目前我很少在我的代码中使用IRB。我只用它来验证语法或尝试一些小的东西。我知道我可以将我自己的代码加载到ruby中作为一个require'mycode'但这通常不符合我的编程风格。有时我要检查的变量超出范围或在循环内。有没有一种简单的方法可以启动我的脚本并在IRB内的某个点卡住?我想我正在寻找一种更简单的方法来调试我的ruby代码而不破坏我的F5(编译)键。也许有经验的ruby开发者可以和我分享一个更精简的开发方法。 最佳答案 安装ruby-debugg
我开始了一个小型网络项目并使用Drupal来构建它。到目前为止,还不错:您可以快速建立一个不错的面向CMS的网站,通过模块添加社交功能,并且您有一个广泛的API可以在一个架构良好的平台中进行自定义。现在问题来了:网站的增长超出了最初的计划,我发现自己正处于认真开始为它编写代码的境地。由于Drupal项目,我对PHP有了新的认识,但我想用Ruby来做。我会感觉更舒服,以后维护起来更容易,我可以在其他Ruby/Rails应用程序中重用它。随着时间的推移,我想我会用Ruby重写Drupal中的现有部分。基于此,问题是:是否有人将两者(成功或失败的故事)结合起来?这是一个相当大的决定,但我在G
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统
一、Elasticsearch简介实际业务场景中,多端的查询功能都有很大的优化空间。常见的处理方式有:建索引、建物化视图简化查询逻辑、DB层之上建立缓存、分页…然而随着业务数据量的不断增多,总有那么一张表或一个业务,是无法通过常规的处理方式来缩短查询时间的。在查询功能优化上,作为开发人员应该站在公司的角度,本着优化客户体验的目的去寻找解决方案。本人有幸做过Tomcat整合solr,今天一起研究一下当前比较火热的Elasticsearch搜索引擎。Elasticsearch是一个非常强大的搜索引擎。它目前被广泛地使用于各个IT公司。Elasticsearch是由Elastic公司创建。它的代码位
场景在SpringBoot项目中需要对接三方系统,对接协议是TCP,需实现一个TCP客户端接收服务端发送的数据并按照16进制进行解析数据,然后对数据进行过滤,将指定类型的数据通过mybatis存储进mysql数据库中。并且当tcp服务端断连时,tcp客户端能定时检测并发起重连。全流程效果 注:博客:霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主实现1、SpringBoot+Netty实现TCP客户端本篇参考如下博客,在如下博客基础上进行修改Springboot+Netty搭建基于TCP协议的客户端(二):https://www.cnblogs.com/haolb
一、SpringBoot是什么SpringBoot是依赖于Spring的,比起Spring,除了拥有Spring的全部功能以外,SpringBoot无需繁琐的Xml配置,这取决于它自身强大的自动装配功能;并且自身已嵌入Tomcat、Jetty等web容器,集成了SpringMvc,使得SpringBoot可以直接运行,不需要额外的容器,提供了一些大型项目中常见的非功能性特性,如嵌入式服务器、安全、指标,健康检测、外部配置等,其实Spring大家都知道,Boot是启动的意思。所以,SpringBoot其实就是一个启动Spring项目的一个工具而已,总而言之,SpringBoot是一个服务于框架的