文章目录
本文介绍如何使用GitHub Pages + Hexo搭建个人博客网站,完全免费,所有内容本人亲测,绝对可用。
需要有一个GitHub账号,没有的话到 官网 申请一个。
注册很简单,不懂的话可以参考 GitHub申请账号
在自己电脑上安装好Git,hexo部署到GitHub时要用。
网上找篇教程或者参考 Git安装(Windows)
在自己电脑上安装好NodeJS,Hexo是基于NodeJS编写的,所以需要安装NodeJS和npm工具。
网上找篇教程或者参考 NodeJS安装及配置(Windows)
在GitHub上创建一个新的代码仓库用于保存我们的网页。
点击Your repositories,进入仓库页面。
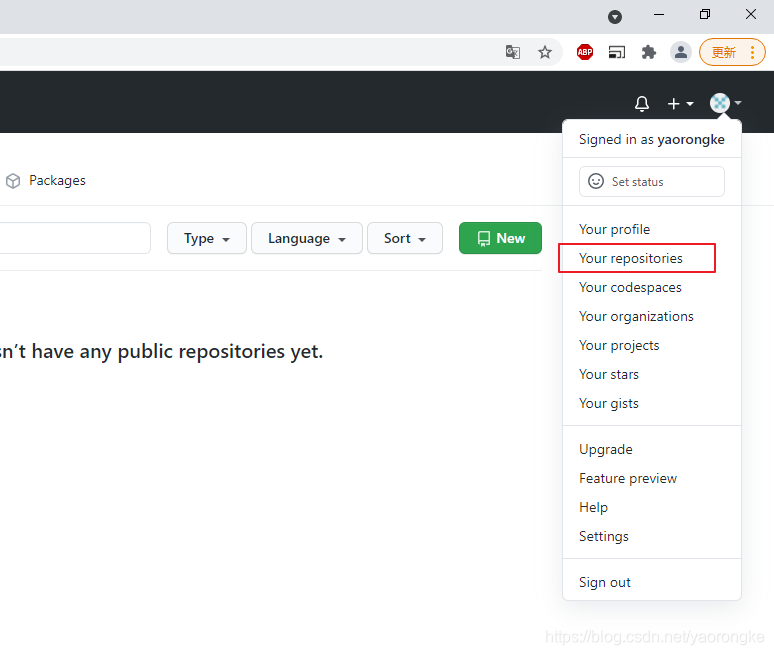
点击New按钮,进入仓库创建页面。
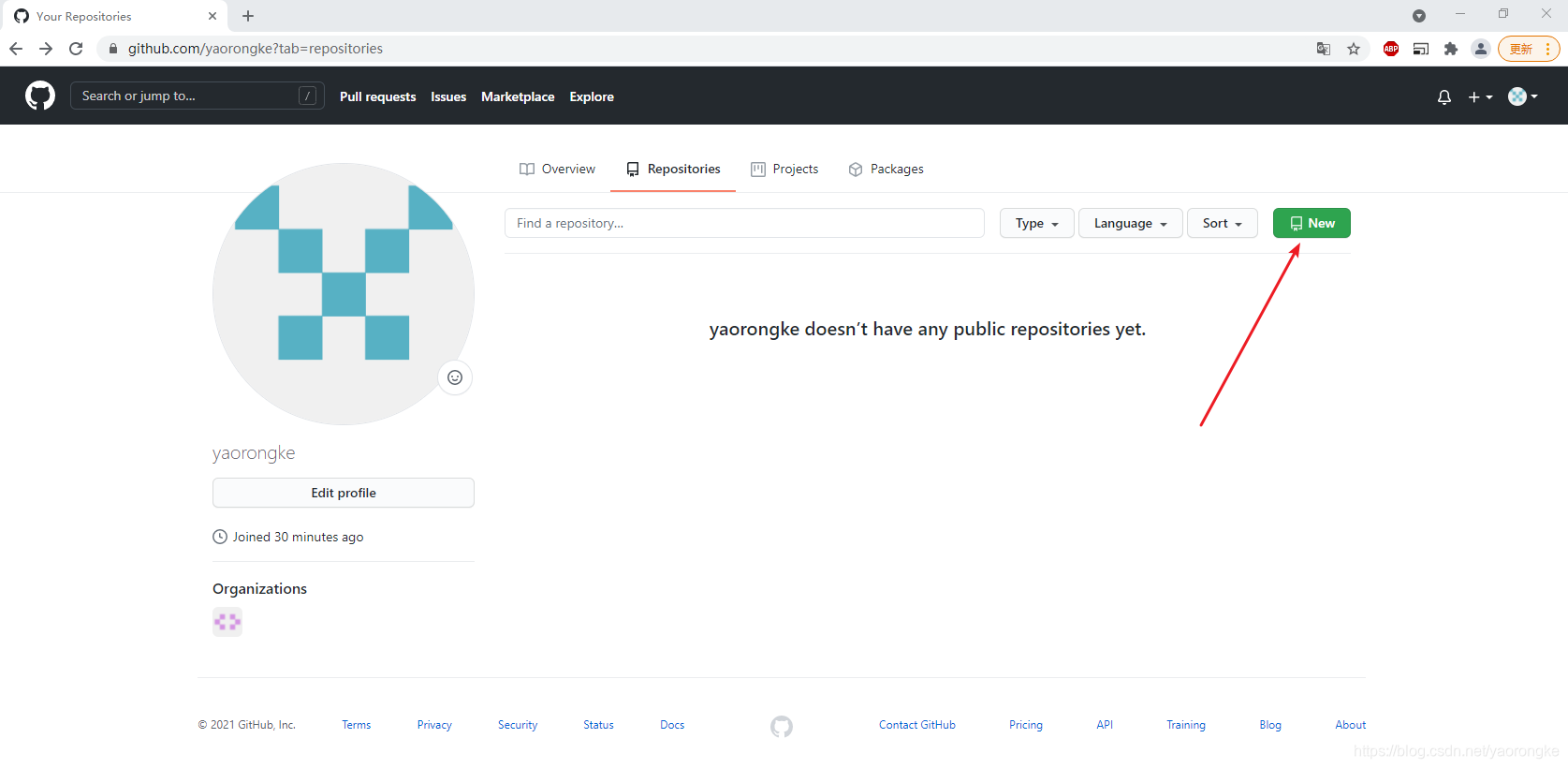
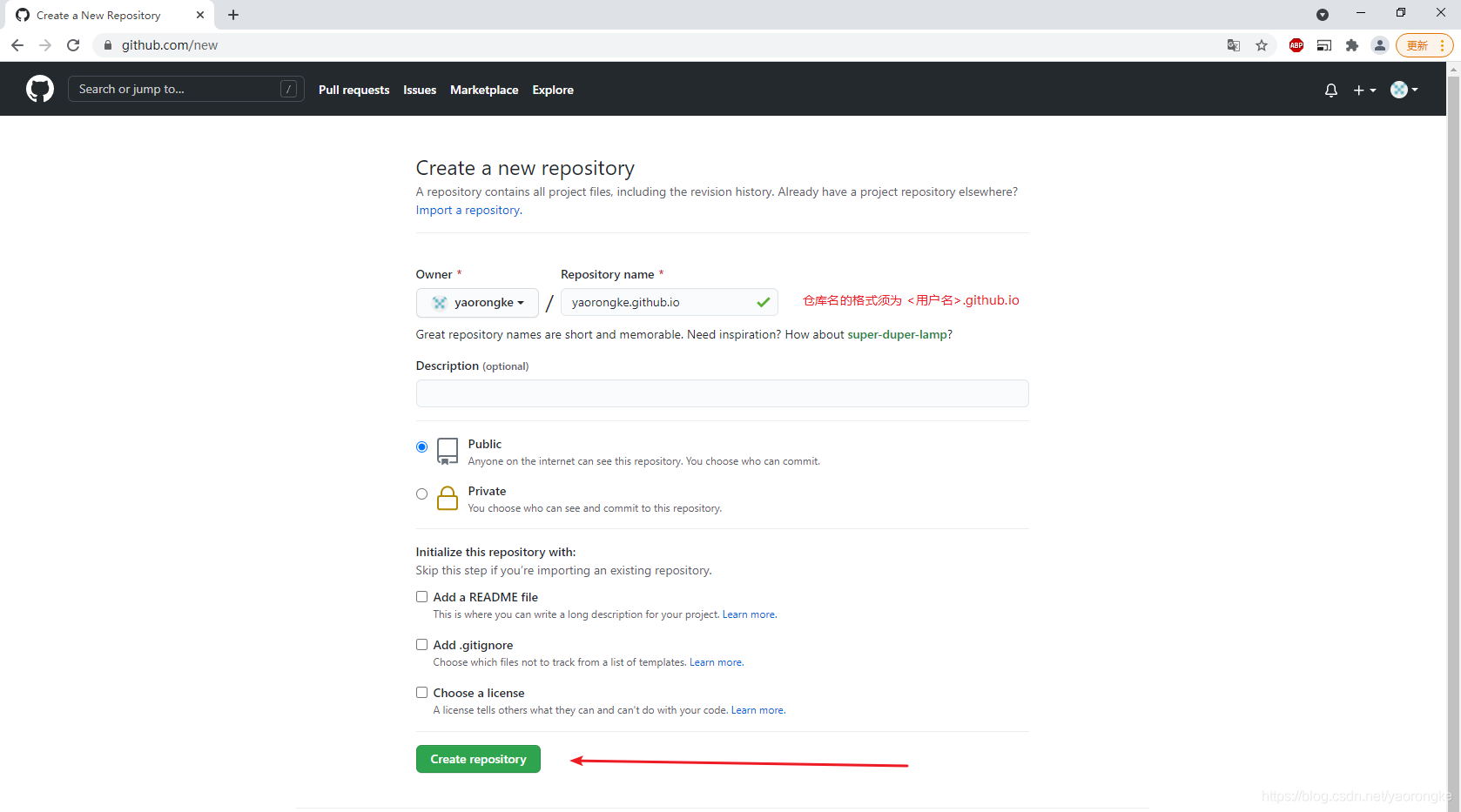
填写仓库名,格式必须为<用户名>.github.io,然后点击Create repository。
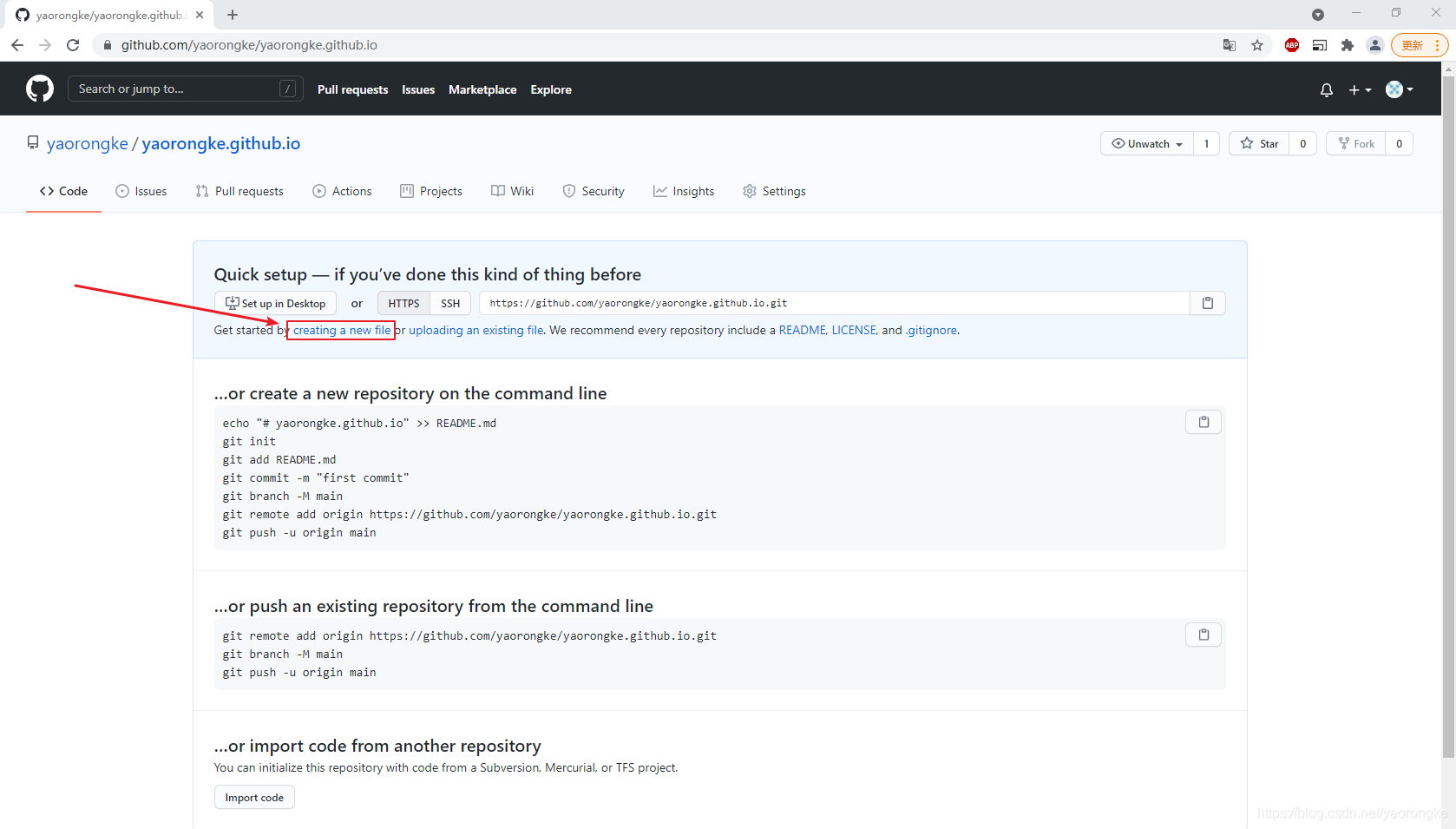
点击creating a new file创建一个新文件,作为我们网站的主页。
新文件的名字必须为index.html,内容先随便写一个简单的,内容示例如下,填写之后点击Commit new file提交。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>yaorongke</title>
</head>
<body>
<h1>yaorongke的个人主页</h1>
<h1>Hello ~</h1>
</body>
</html>
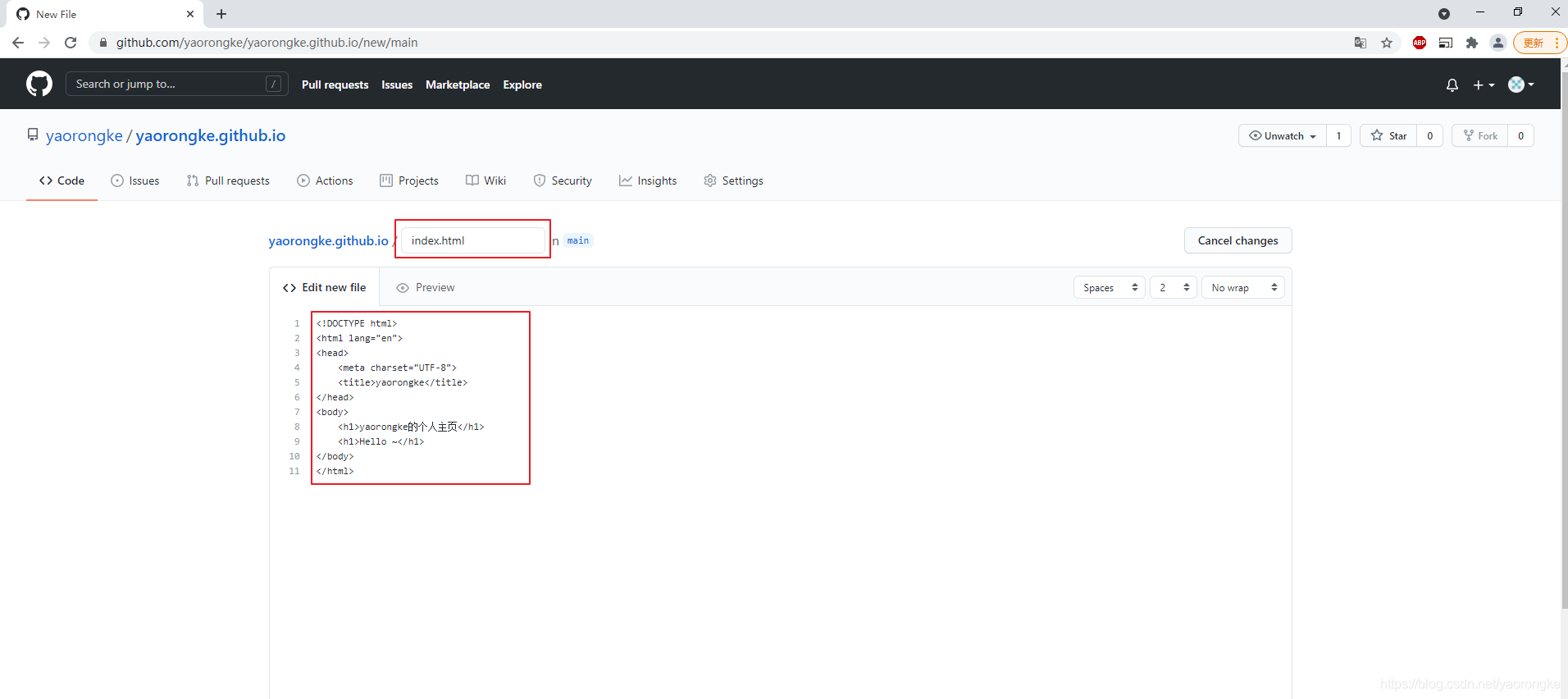
GitHub Pages中找到我们主页的地址为 https://yaorongke.github.io/
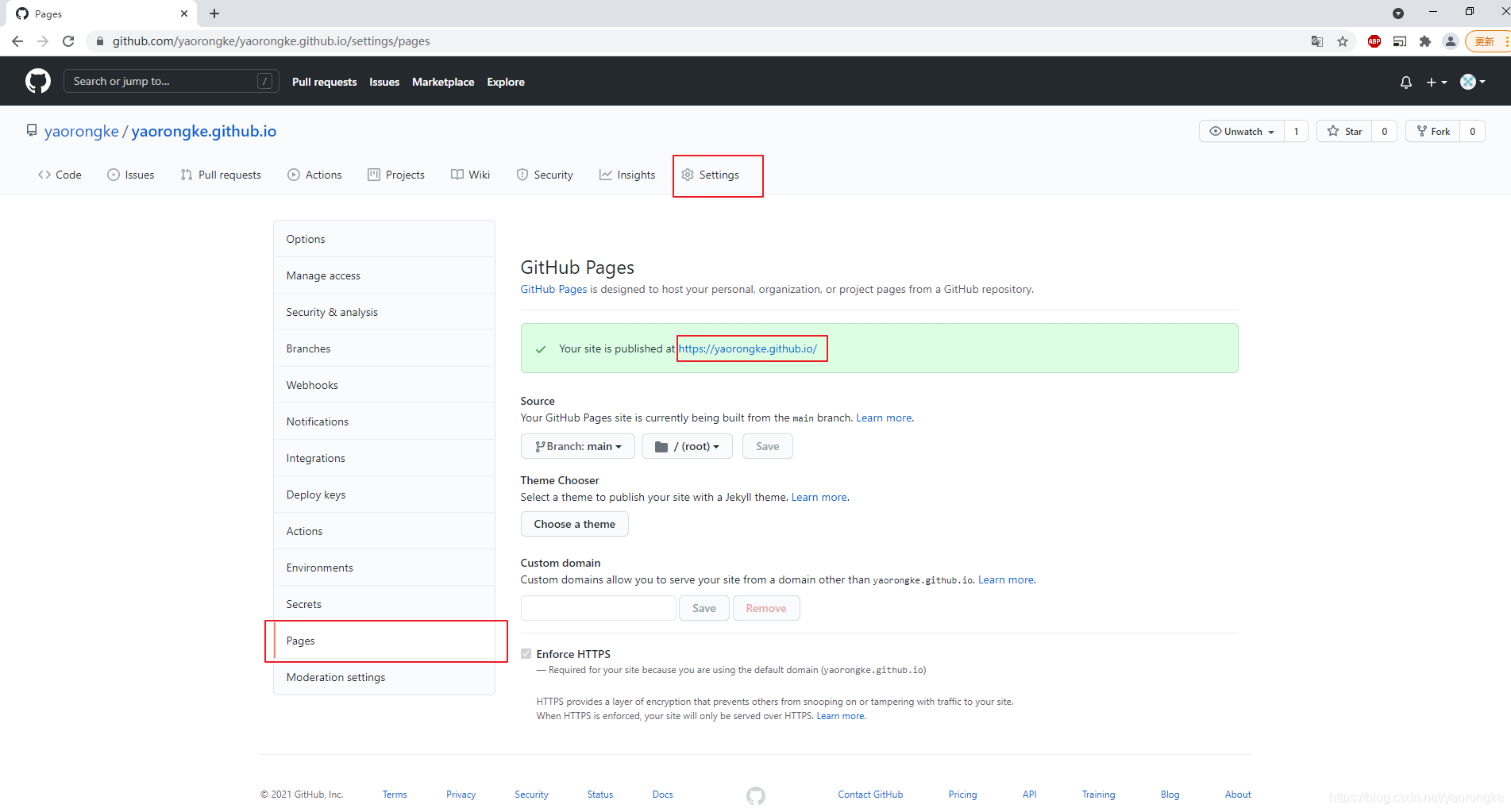
浏览器中访问,展示成功。
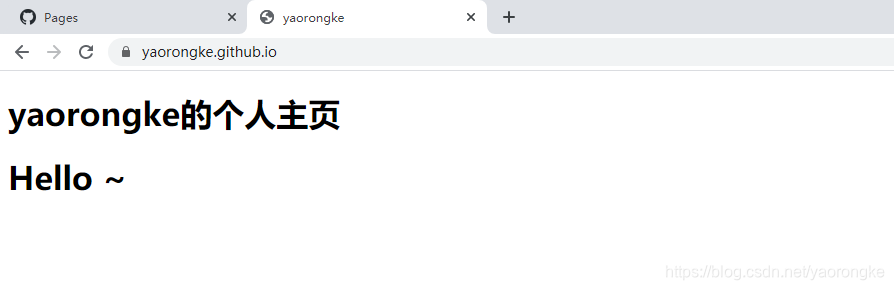
这里创建的网页是非常简陋的,只是为了演示下GitHub Pages的使用方式。
我们采用Hexo来创建我们的博客网站,Hexo 是一个基于NodeJS的静态博客网站生成器,使用Hexo不需开发,只要进行一些必要的配置即可生成一个个性化的博客网站,非常方便。点击进入 官网。
安装 Hexo
npm install -g hexo-cli
查看版本
hexo -v
创建一个项目 hexo-blog 并初始化
hexo init hexo-blog
cd hexo-blog
npm install
本地启动
hexo g
hexo server
浏览器访问 http://localhost:4000,页面默认主图风格如下
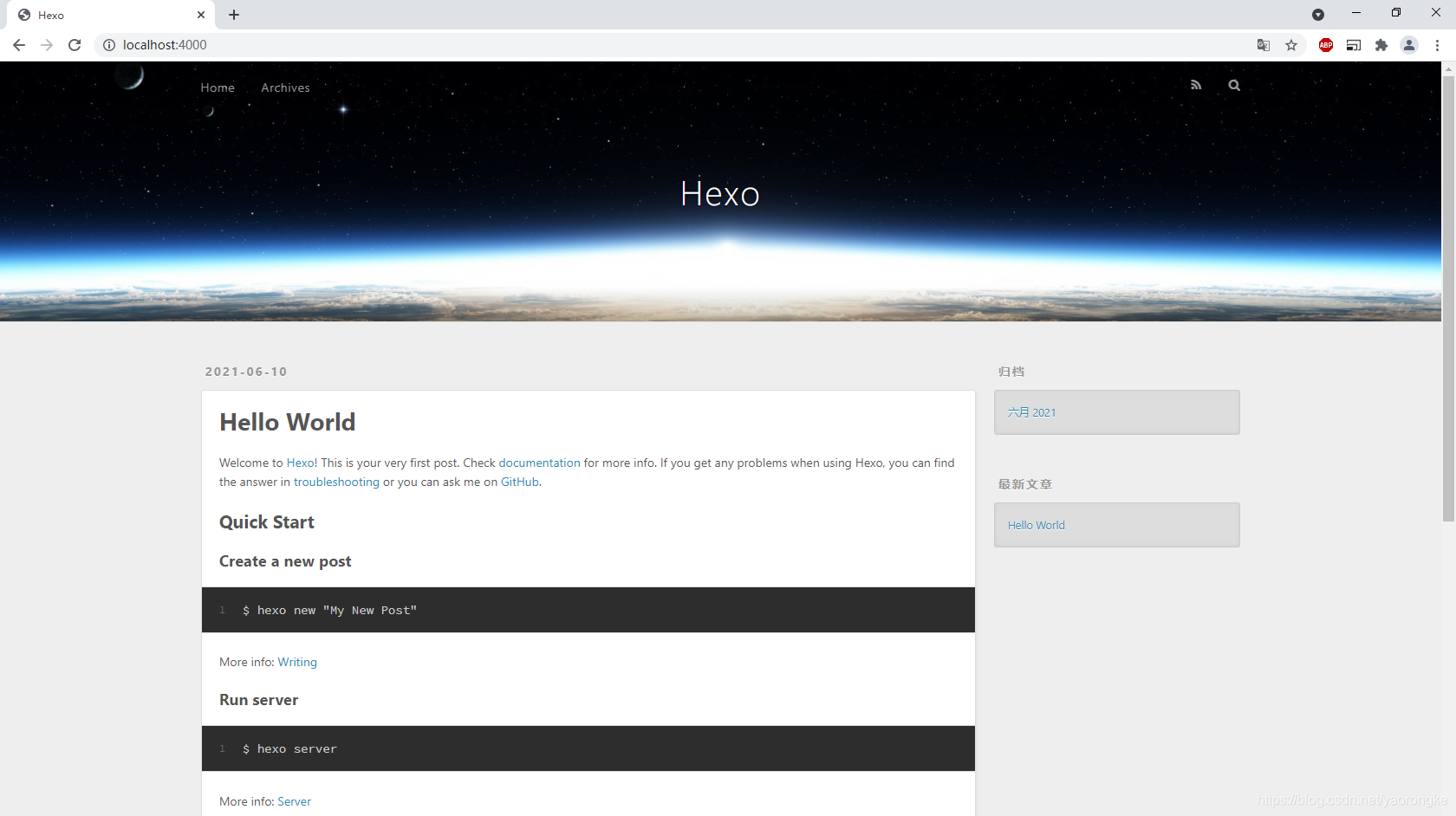
Hexo 默认的主题不太好看,不过官方提供了数百种主题供用户选择,可以根据个人喜好更换,官网主题点 这里 查看。这里介绍两个主题的使用方法,Next 和 Fluid,个人比较喜欢Fluid,后面章节的功能也是以 Fluid 为基础进行讲解的。
安装主题
cd hexo-blog
git clone https://github.com/iissnan/hexo-theme-next themes/next
使用 NexT 主题
打开 _config.yml 文件,该文件为站点配置文件
将主题修改为 next
theme: next
本地启动
hexo g -d
hexo s
以下安装步骤摘自 Fluid官网
安装主题
下载 最新 release 版本 解压到 themes 目录,并将解压出的文件夹重命名为 fluid。
指定主题
如下修改 Hexo 博客目录中的 _config.yml:
theme: fluid # 指定主题
language: zh-CN # 指定语言,会影响主题显示的语言,按需修改
创建「关于页」
首次使用主题的「关于页」需要手动创建:
hexo new page about
创建成功后,编辑博客目录下 /source/about/index.md,添加 layout 属性。
修改后的文件示例如下:
---
title: about
date: 2020-02-23 19:20:33
layout: about
---
这里写关于页的正文,支持 Markdown, HTML
本地启动
hexo g -d
hexo s
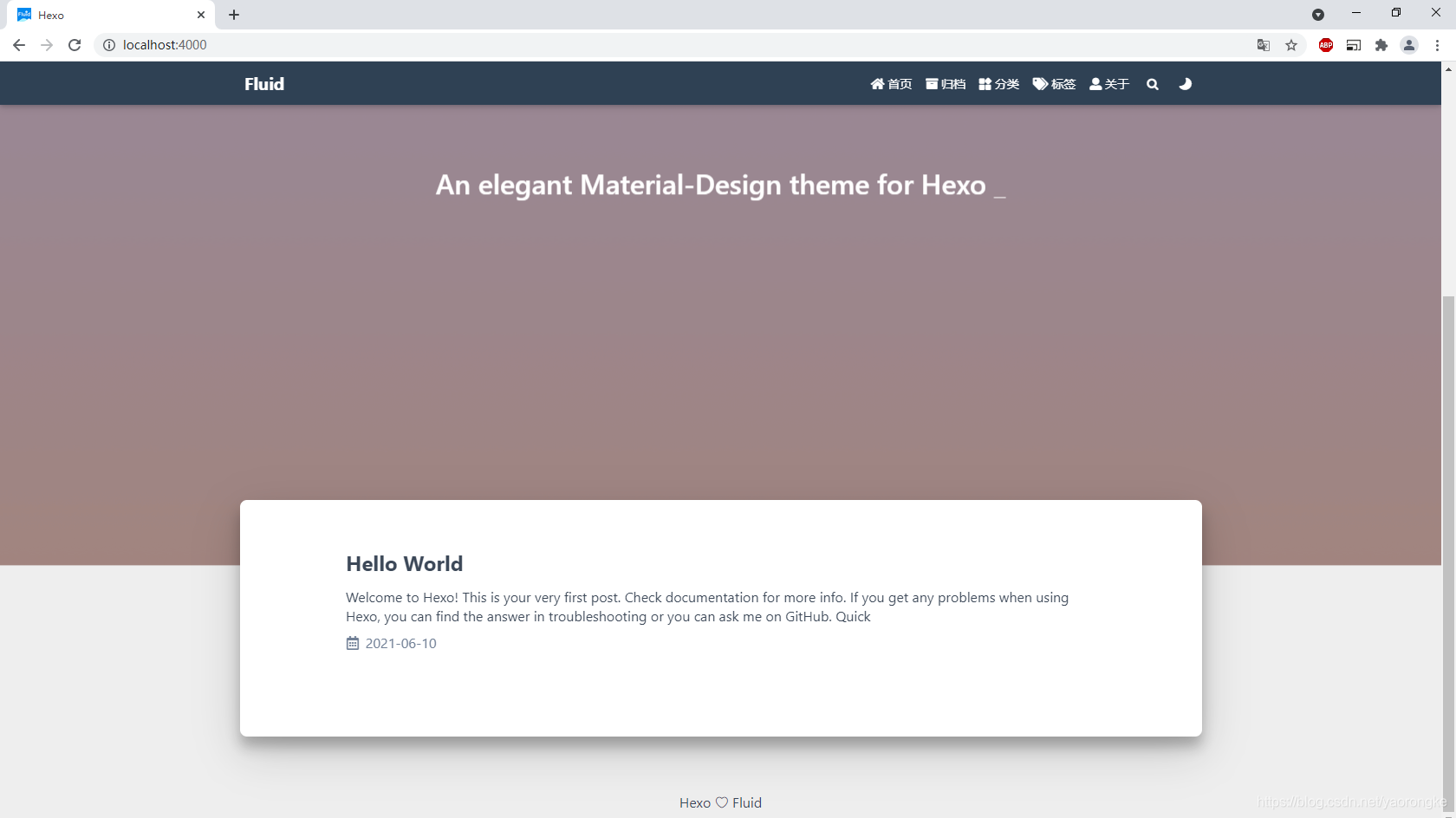
浏览器访问 http://localhost:4000,Fluid主题风格页面如下
如下修改 Hexo 博客目录中的 _config.yml,打开这个配置是为了在生成文章的时候生成一个同名的资源目录用于存放图片文件。
post_asset_folder: true
执行如下命令创建一篇新文章,名为《测试文章》
hexo new post 测试文章
执行完成后在source\_posts目录下生成了一个md文件和一个同名的资源目录(用于存放图片)
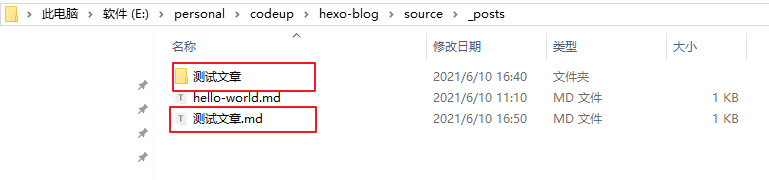
在资源目录测试文章中放一张图片 test.png

在测试文章.md中添加内容如下,演示了图片的三种引用方式。第一种为官方推荐用法,第二种为markdown语法,第三种和前两种图片存放位置不一样,是将图片放在\source\images目录下。这三种写法在md文件中图片是无法显示的,但是在页面上能正常显示。
图片的引入方式可参考官方文档 https://hexo.io/zh-cn/docs/asset-folders.html,有详细介绍。
---
title: 测试文章
date: 2021-06-10 16:35:20
tags:
- 原创
categories:
- Java
---
这是一篇测试文章
{% asset_img test.png 图片引用方法一 %}


本地启动
hexo g -d
hexo s
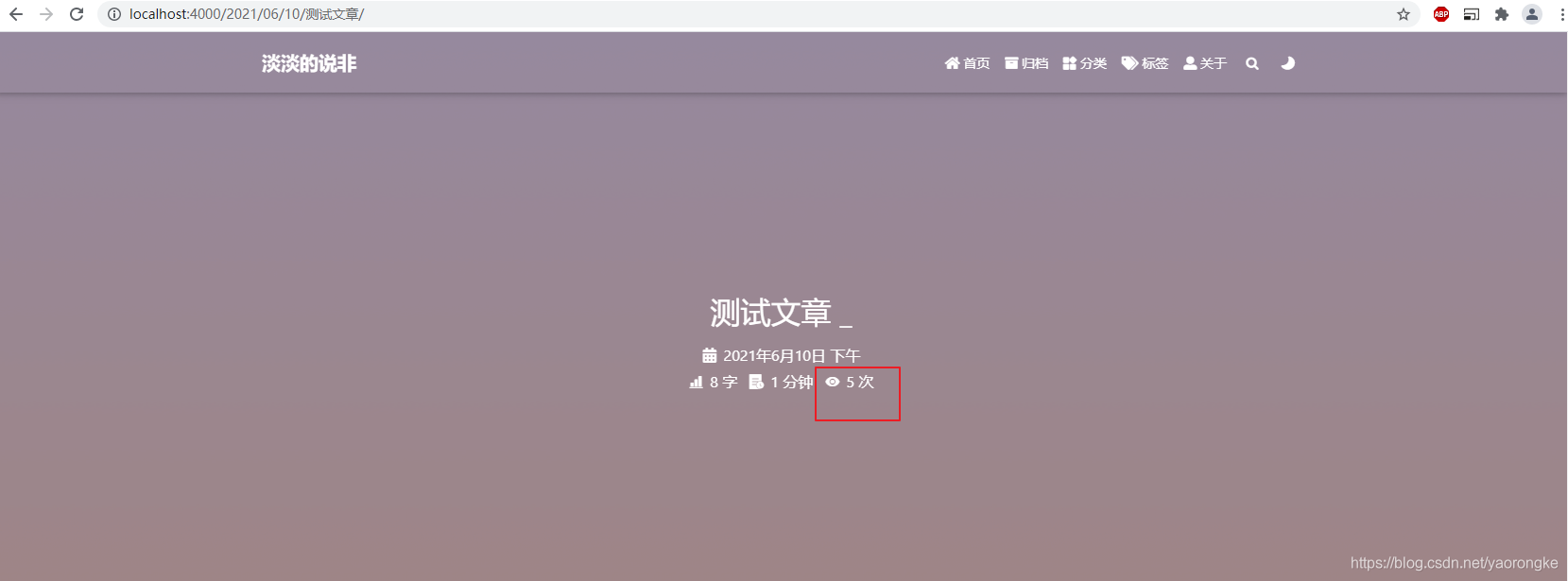
浏览器访问 http://localhost:4000,页面如下,文章添加成功
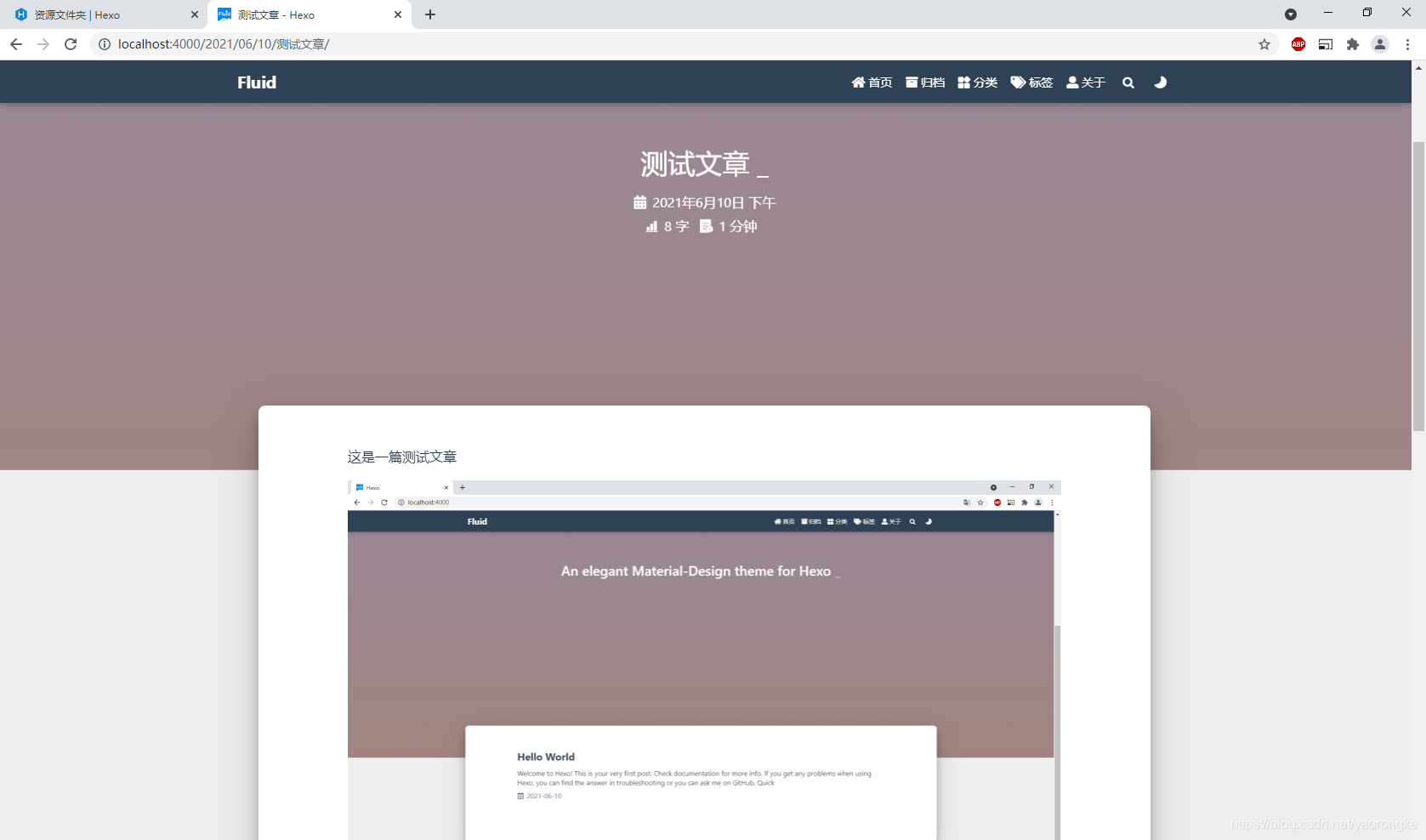
页面的标题等位置显示默认的文字,可以改下显示一些个性化的信息。
修改根目录下 _config.yml 中的 title 字段。
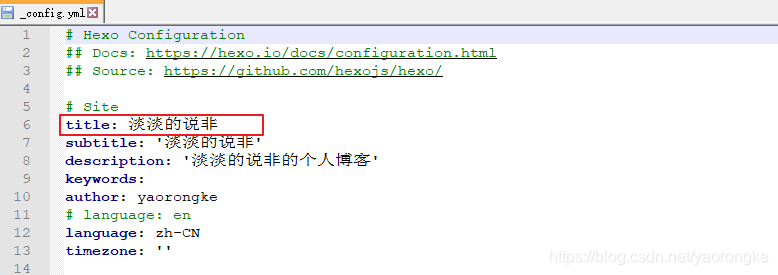
主题目录 themes\fluid 下 _config.yml 中的 blog_title 字段。
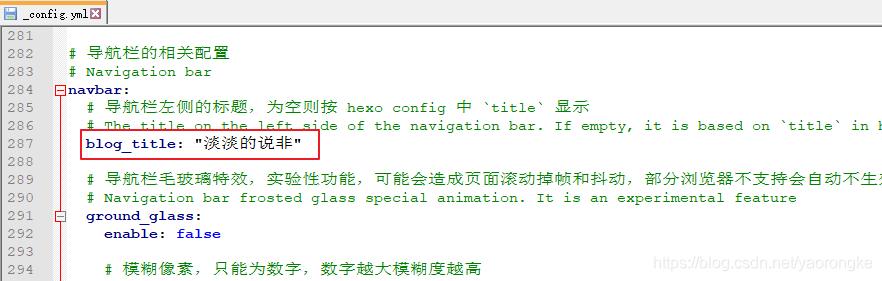
主题目录 themes\fluid 下 _config.yml 中的 text 字段。
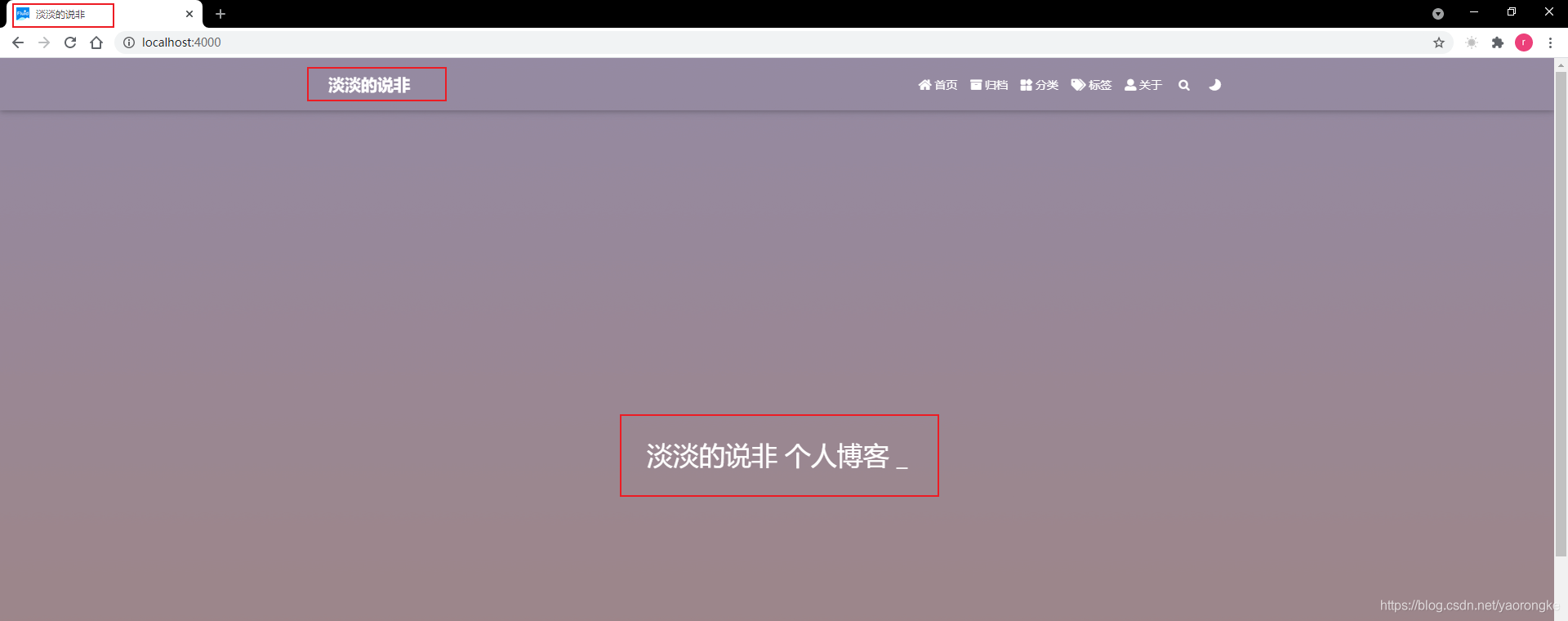
修改好配置后,页面效果如下,可以看到现在显示的内容变成了我们的个人信息。
Fluid 主题写好了统计阅读量的代码,但是缺少相应配置所以没有开启,需要借助三方服务来统计阅读量,这里是有 Leancloud 的免费服务来进行统计。
进入 官网 注册账号
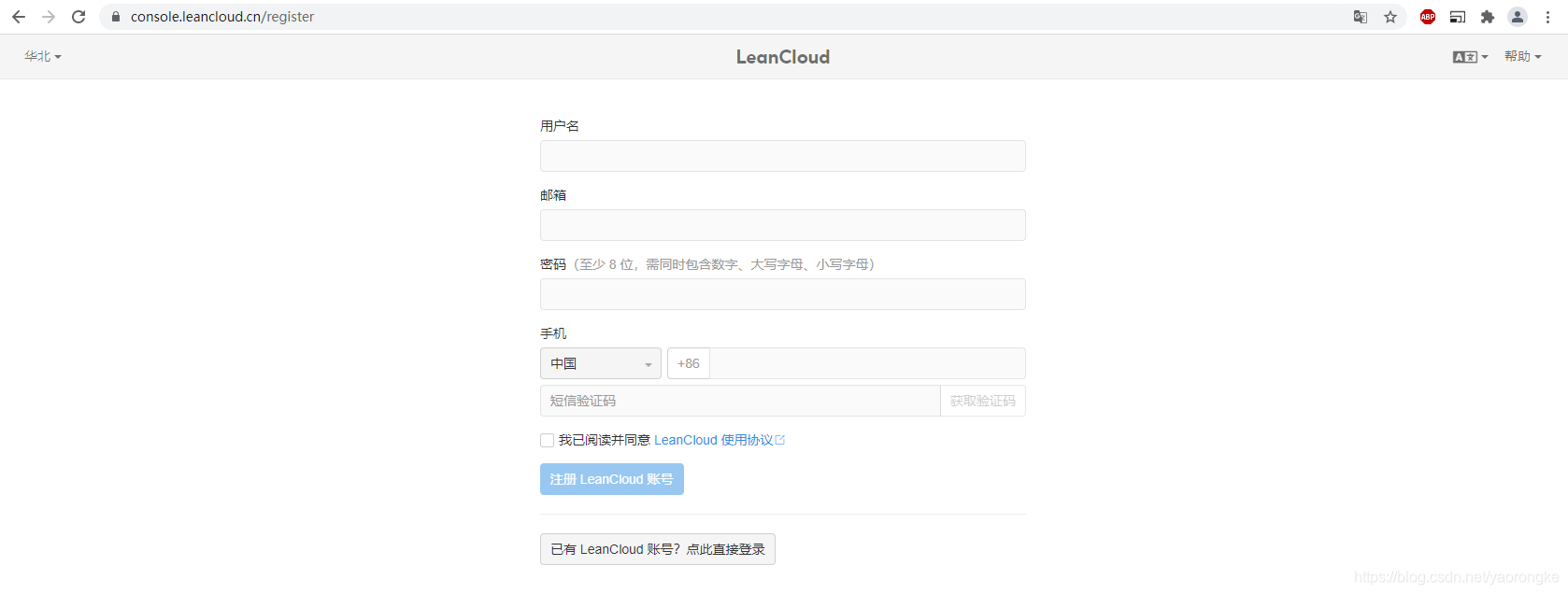
需实名认证,完成后才能使用各项服务
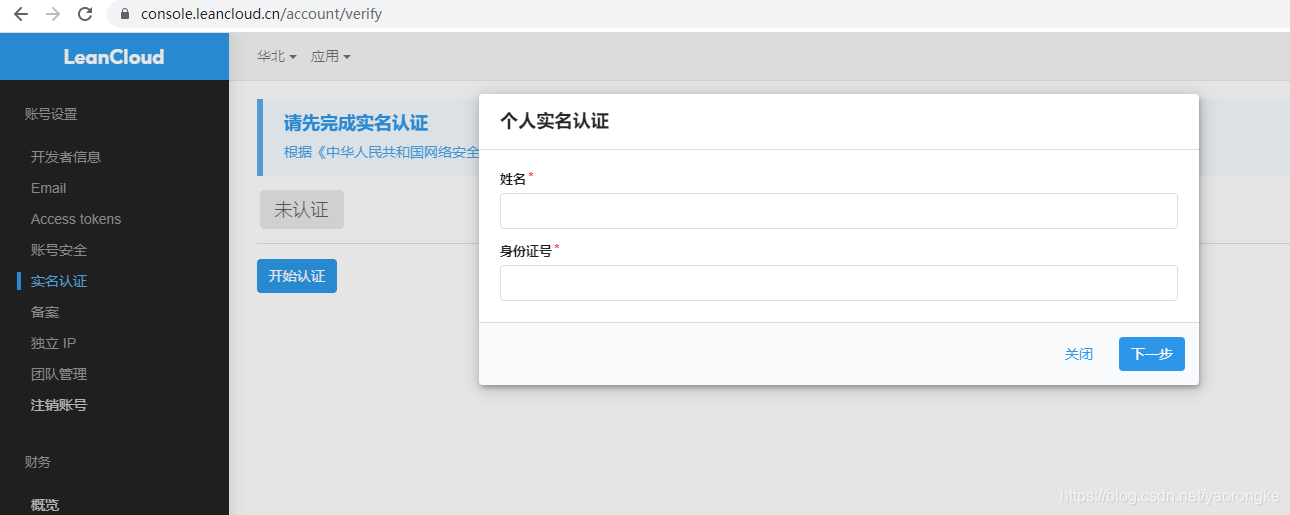
验证邮箱
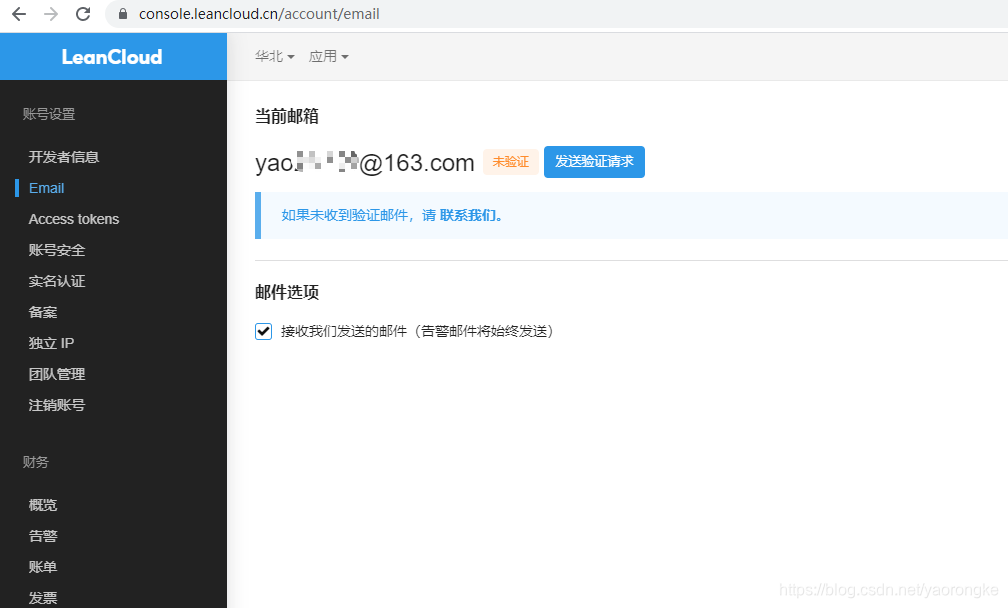
创建应用,选择开发版即可,免费的
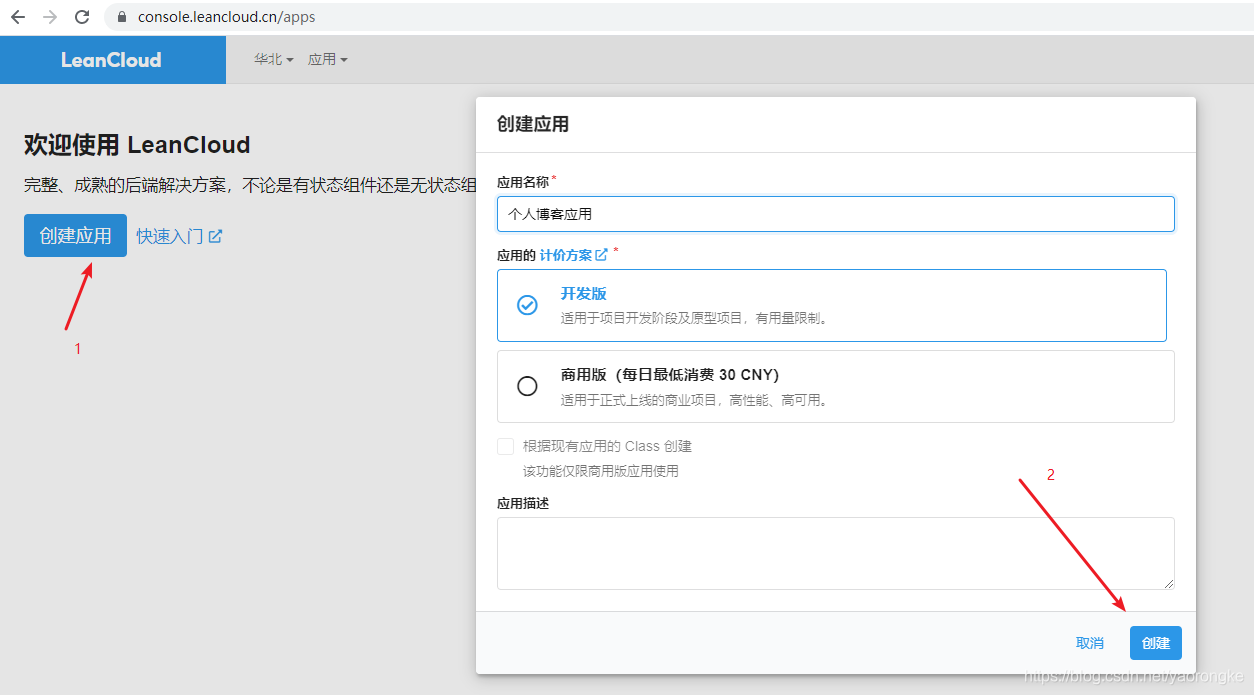
进入该应用的 设置->应用凭证,找到 AppID 和 AppKey,记录下来后面配置要用
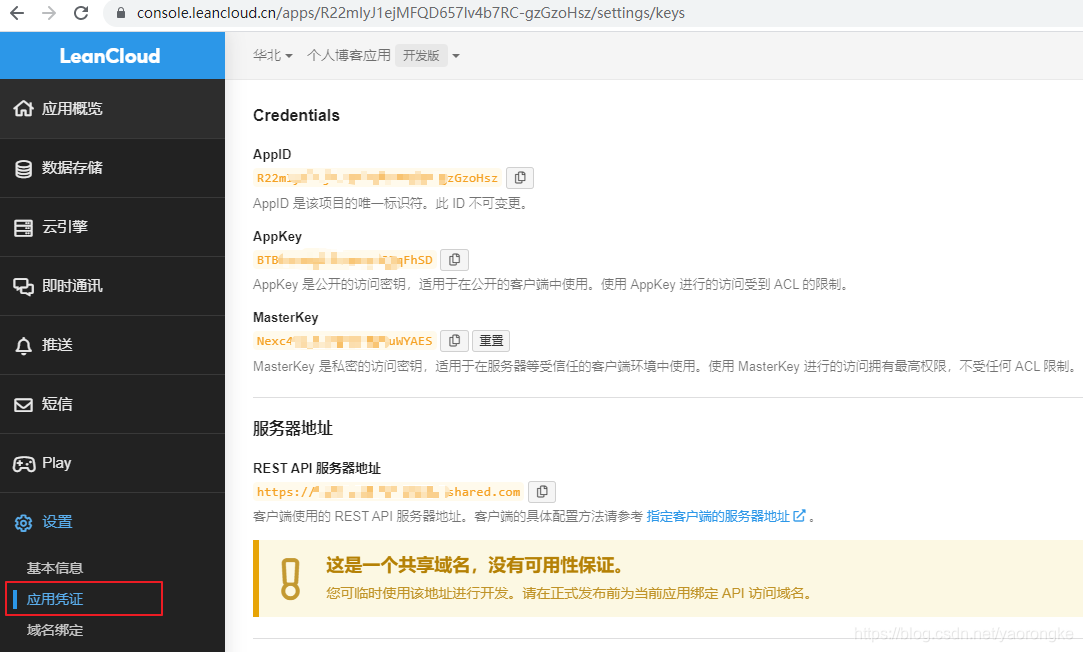
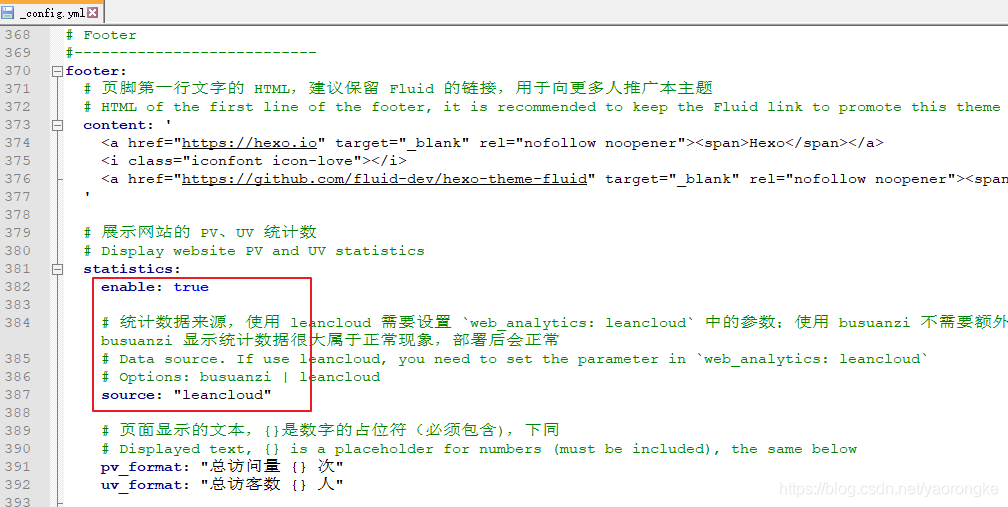
打开主题目录 themes\fluid下的 _config.yml 文件,修改如下配置
打开统计开关
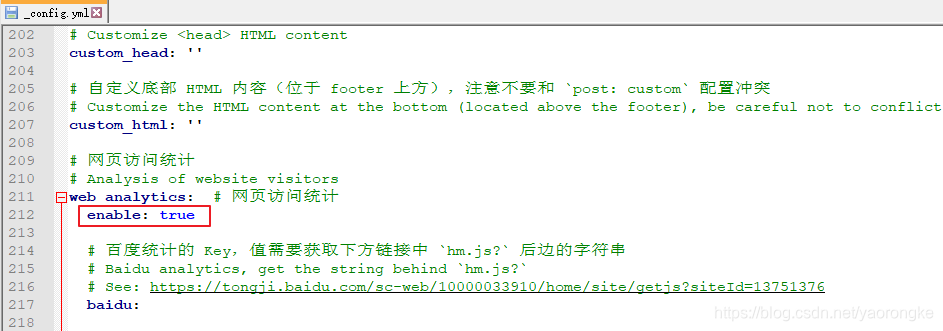
配置 leancloud的 app_id 和 app_key
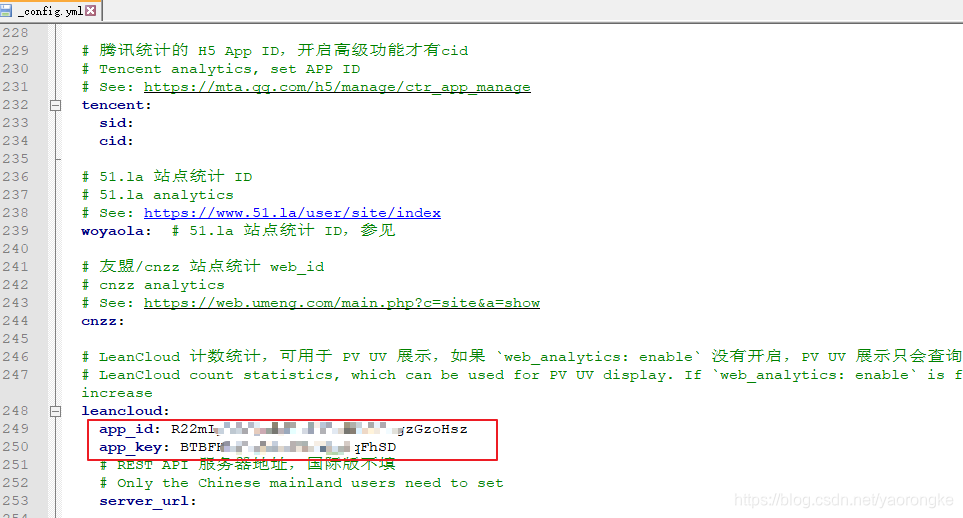
打开计数功能,统计来源改为 leancloud
页面效果
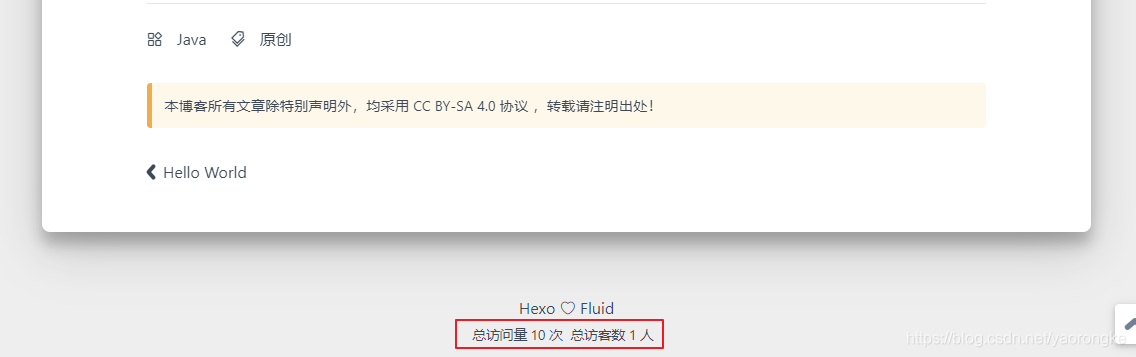
页面效果
评论功能的代码已经写好了,只不过没有开启,需要修改一些配置
打开主题目录 themes\fluid下的 _config.yml 文件,修改如下配置
启用评论插件
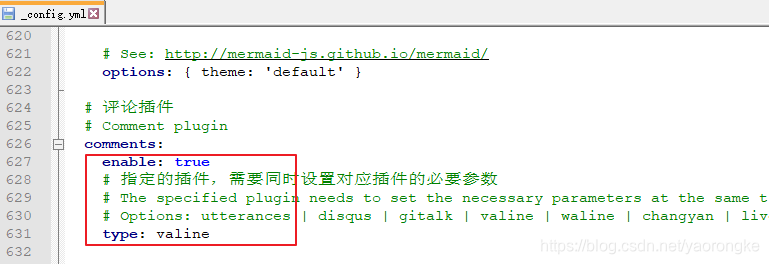
配置 LeanCloud 的 appId 和 appkey
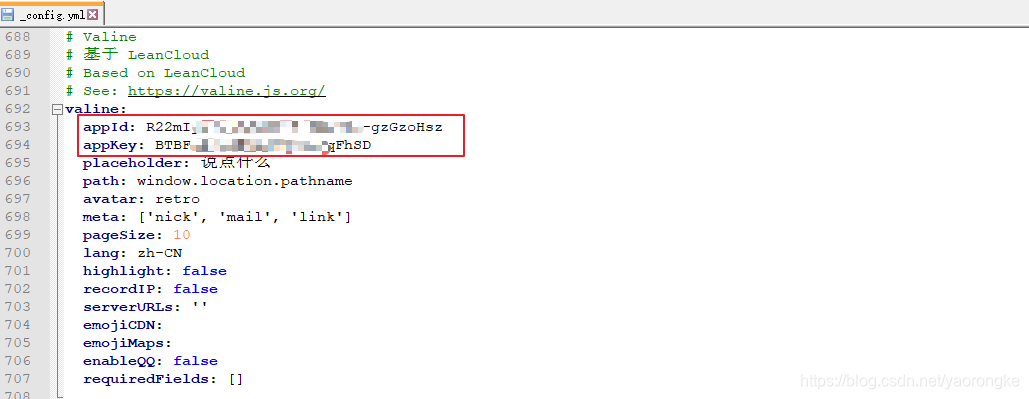
重新部署后,查看页面效果,评论功能已开启
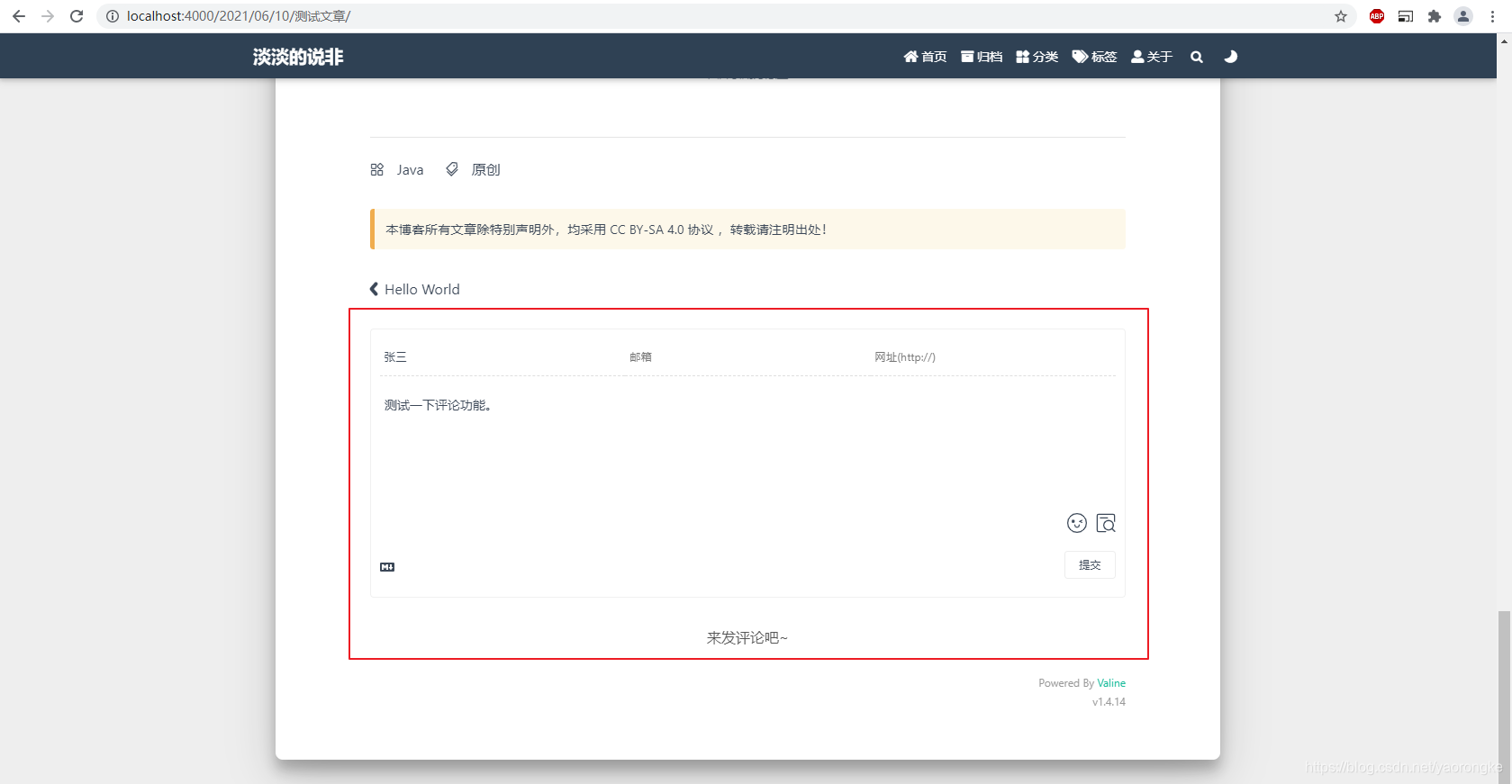
部署在本地时评论无法提交,会报跨域问题,发布到 GitHub Pages 上之后课正常提交评论
安装hexo-deployer-git
npm install hexo-deployer-git --save
修改根目录下的 _config.yml,配置 GitHub 相关信息
deploy:
type: git
repo: https://github.com/yaorongke/yaorongke.github.io.git
branch: main
token: ghp_3KakcaPHerunNRyMerofcFd9pblU282FSbsY
其中 token 为 GitHub 的 Personal access tokens,获取方式如下图
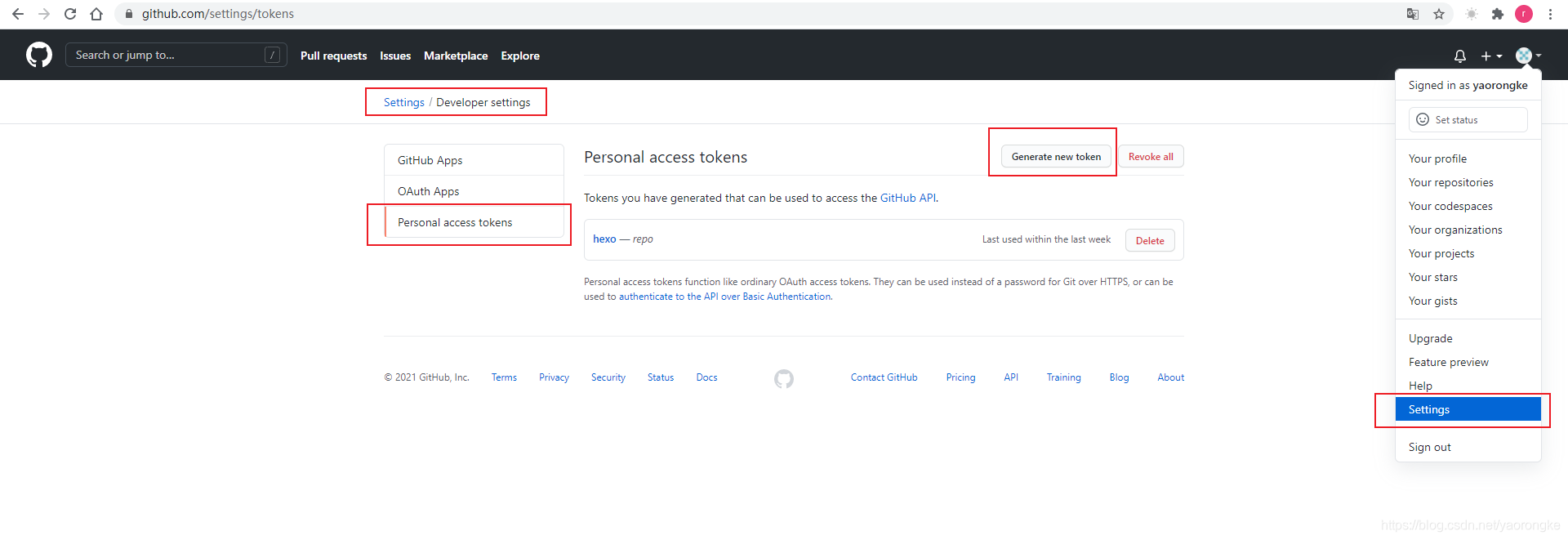
部署到GitHub
hexo g -d
浏览器访问 https://yaorongke.github.io/,部署成功
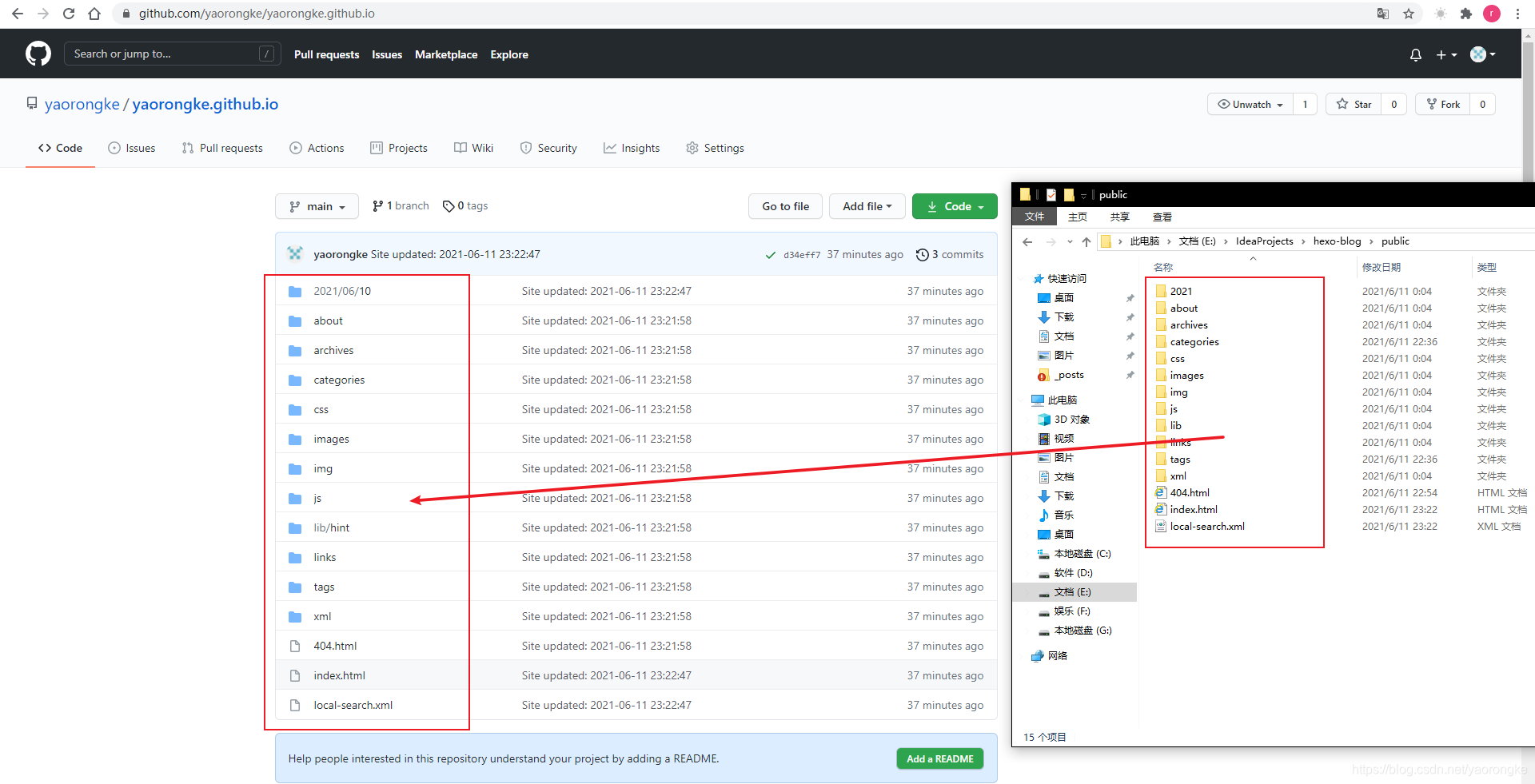
直接将 public 目录中的文件和目录推送至 GitHub 仓库和分支中。
如果自己有服务器的话,也可以不使用 GitHub Pages,直接部署的自己的服务器上,通过 Nginx 进行代理,我这里有一个阿里云上的 CentOS 7 版的 Linux 服务器,演示下如何部署,步骤如下。
打开 hexo-blog 根目录下的 _config.yml,增加如下配置,这是因为把网站存放在了子目录中,要和 Nginx 配置中的 location /blog 路径一致。
root: /blog
hexo-blog 根目录下执行打包命令,打包好的文件在 public 目录下
hexo g
将public 目录下的文件复制到 Linux 服务器上的某个目录下,我的存放目录为
/opt/rkyao/fronted/hexo-blog
修改 Nginx 配置文件,我的 Nginx 安装路径为 /usr/local,大家根据自己实际情况调整
cd /usr/local/nginx/conf
vim nginx.conf
# server节点下添加如下配置
location /blog {
alias /opt/rkyao/fronted/hexo-blog;
index index.html index.htm;
}
重启 Nginx
cd /usr/local/nginx/sbin
./nginx -s reload
访问博客
http://47.96.106.173/blog/
可访问如下地址查看
https://yaorongke.github.io/
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
如何使用rubyonrails获取网络上某处其他网站的页面数据? 最佳答案 您可以使用httparty只是获取数据示例代码(来自example):requireFile.join(dir,'httparty')require'pp'classGoogleincludeHTTPartyformat:htmlend#google.comredirectstowww.google.comsothisislivetestforredirectionppGoogle.get('http://google.com')puts'','*'*7
我正在使用RubyonRailsv3.0.9,我想检索我设置了链接的每个网站的favicon.ico图像。也就是说,如果在我的应用程序中我设置了http://www.facebook.com/URL,我想检索Facebook的图标并在我的网页中使用\插入它。当然,我也想为所有其他网站这样做。如何以“自动”方式从网站检索favicon.ico图标(“自动”是指在网站中搜索图标并获取它的链接-我认为不是,因为并非所有网站都有一个名为“favicon.ico”的图标。我想以“自动”方式识别它)?P.S.:我想做的是像Facebook在您的Facebook页面中添加链接\URL时所做的那样:它
我正在尝试从googleAPI下载client_secret.json。我正在执行https://developers.google.com/gmail/api/quickstart/ruby中列出的步骤.使用此向导在GoogleDevelopersConsole中创建或选择项目并自动启用API。在左侧边栏中,选择同意屏幕。选择电子邮件地址并输入产品名称(如果尚未设置),然后单击“保存”按钮。在左侧边栏中,选择凭据并点击创建新客户端ID。选择应用程序类型已安装应用程序,已安装应用程序类型为其他,然后单击“创建客户端ID”按钮。点击新客户端ID下的下载JSON按钮。将此文件移动到您的工作
🎉精彩专栏推荐💭文末获取联系✍️作者简介:一个热爱把逻辑思维转变为代码的技术博主💂作者主页:【主页——🚀获取更多优质源码】🎓web前端期末大作业:【📚毕设项目精品实战案例(1000套)】🧡程序员有趣的告白方式:【💌HTML七夕情人节表白网页制作(110套)】🌎超炫酷的Echarts大屏可视化源码:【🔰Echarts大屏展示大数据平台可视化(150套)】🔖HTML+CSS+JS实例代码:【🗂️5000套HTML+CSS+JS实例代码(炫酷代码)继续更新中…】🎁免费且实用的WEB前端学习指南:【📂web前端零基础到高级学习视频教程120G干货分享】🥇关于作者:💬历任研发工程师,技术组长,教学总监;
我正在为我的网站使用MiddlemanBloggem,但默认情况下,博客文章似乎需要位于/source中,这在查看vim中的树时并不是特别好并尝试在其中找到其他文件之一(例如模板)。通过查看文档,我看不出是否有任何方法可以移动博客文章,以便将它们存储在其他地方,例如blog_articles文件夹或类似文件夹。这可能吗? 最佳答案 将以下内容放入您的config.rb文件中。activate:blogdo|blog|blog.permalink=":year-:month-:day-:title.html"blog.sources=
我注意到当我使用Mechanize获取没有响应的站点时,它只是继续等待。我该如何克服这个问题? 最佳答案 有几种方法可以处理它。Open-Uri和Net::HTTP有传递超时值的方法,然后告诉底层网络堆栈您愿意等待多长时间。例如,Mechanize允许您在初始化实例时获取其设置,例如:mech=Mechanize.new{|agent|agent.open_timeout=5agent.read_timeout=5}所有这些都在new的文档中,但您必须查看源代码才能了解您可以获得哪些实例变量。或者你可以使用Ruby的timeout模