这次a和b过的可能是有生以来最快的(?)然后写C写了一个多小时还没写出来(悲)最后剩不到二十分钟看了眼D,结果瞬间悟出了答案(属于是开题失误了)最后以最快速度写完,一抬头发现刚好时间到了(樂)属于是到手的紫名飞了呜呜

比赛时没有注意到的一个重要性质是答案只与最大值和最小值相关,这是十分不应该的。注意到这一点后对所有smartness排序就成为了很自然的想法。接下来就是考虑对于左端点为l时维护当右端点r取到哪里时能凑出的topic的数目为m了,这可以利用双指针线性求出。

大概就是说有个树,每个节点都可能是1或者是0,每过一秒所有节点的值都会变成它们儿子异或起来的值,叶子则会直接变成0,求所有可能的树的初始状态下每秒1棵树所有节点的和的和(有点绕)
因为是考虑所有可能的状态(这种技巧最近十分常见),不妨从考虑概率的角度入手。这里有一个很有趣的point:
于是我们只需要算出每秒可能非0的节点有多少即可.很自然地想到可以用topsort来解决。这里犯了个铸币操作:对无向图dfs再改成有向图来保证拓扑排序的正确性,但事实上即使是无向图只要给根节点1添加一个虚根就可以直接拓扑排序了(如果比赛时想到是不是就来得及交题了呜呜)
今天还学到了一个关于vector的小细节:resize和clear本质上并没有释放内存,清vector最好还是vec.erase(vec.begin(),vec.end())
#pragma GCC optimize(2)
#include<bits/stdc++.h>
#include<iostream>
#include<vector>
#include<algorithm>
#include<set>
#include<utility>
#include<string.h>
#include<ext/rope>
#include<queue>
#include<stack>
using namespace std;
using namespace __gnu_cxx;
#define int long long
#define dnt double
#define rep(i,j,k) for(int i=(j);i<=(k);++i)
#define dow(i,j,k) for(i=(j);i>=(k);--i)
#define pr pair
#define mkp make_pair
#define fi first
#define se second
int gp() {int x;while((x=rand())<=0)srand(time(0));return x%1000;}
inline int read(int &x) {
x=0;int ff=1;char ch=getchar();
while (ch<'0'||ch>'9') {
if (ch=='-') ff=-1;ch=getchar();
}
while (ch>='0'&&ch<='9') {
x=x*10+ch-48;ch=getchar();
}
return x*ff;
}
void write(int x) {
if (x > 9)write(x / 10);
putchar((x % 10) + '0');
}
inline int max(int a,int b) {return a>b?a:b;}
inline int min(int a,int b) {return a>b?b:a;}
inline int exgcd(int a,int b,int&x,int&y) {
if(b==0) {x=1,y=0 ;return a ;}
else {int r=exgcd(b,a%b,x,y);int t=x ;x=y ;y=t-a*y/b ;return r ;}
}
struct matrix {
int n,m;
int num[102][102];
void pri() {
for(int i=1; i<=n; i++) {
for(int j=1; j<=m; j++) {
cout<<num[i][j]<<" ";
}
cout<<endl;
}
}
matrix operator*(matrix y) {
matrix x=*this;
matrix c;
c.n=x.n;
c.m=y.m;
memset(c.num,0,sizeof(c.num));
for(int i=1; i<=x.n; i++) {
for(int k=1; k<=x.m; k++){
if(x.num[i][k])
for(int j=1; j<=y.m; j++){
c.num[i][j]+=x.num[i][k]*y.num[k][j];
// c.num[i][j]+=((x.num[i][k]%mod)*(y.num[k][j]%mod))%mod;
}
}
}
return c;
}
matrix operator ^ (int x) {
matrix c,xx;
xx=*this;
c.m=xx.m;
c.n=xx.n;
for(int i=1; i<=xx.n; i++)
for(int j=1; j<=xx.m; j++)
c.num[i][j]=(i==j);
for(; x; x>>=1) {
if(x&1)
c=c*xx;
xx=xx*xx;
}
return c;
}
};int mod=1e9+7;
int fpow(int x,int y) {
int ans=1;int base=x;
while(y) {
if(y&1){
ans=ans*base;
ans%=mod;
}
y/=2;
base=base*base;
base%=mod;
}
return ans%mod;
}
const int maxn=500005;
int lim=maxn,tot=0;int prime[maxn];bool tof[maxn];
void shai() {
for(int i=2; i<=lim; i++) {if(tof[i] == false) {prime[++tot] = i;}
for(int j=1; j<=tot && i * prime[j] <=lim; j++) {tof[i * prime[j]] = true;if(i % prime[j] == 0) break;}}
}
int head[maxn];
int id=0;
struct Edge {
int w,v,next;
} p[maxn*5];
void build(int u,int v,int w) {
p[++id].v=v;p[id].w=w;
p[id].next=head[u];
head[u]=id;return;
}
int f[maxn],a[maxn];int n,m,t,k;
//加油 注意初始化
int ru[maxn];
int dis[maxn];
queue<int>q;vector<int>edg[200005];
void dfs(int noww,int fa){
if(fa!=0){
build(noww,fa,0);
ru[fa]++;
}
for(auto &it:edg[noww]){
if(it==fa)
continue;
dfs(it,noww);
}
}
signed main() {
ios::sync_with_stdio(false),cin.tie(NULL);
//freopen("data.in","r",stdin);
//freopen("T1.out","w",stdout);
cin>>t;
while(t--){
cin>>n;
int x,y;
rep(i,1,n-1){
cin>>x>>y;
edg[x].push_back(y);
edg[y].push_back(x);
//build(x,y,0);
// build(y,x,0);
// ru[x]++;ru[y]++;
}
dfs(1,0);
int maxx=0;
for(int i=1;i<=n;i++){
if(ru[i]==0){
q.push(i);
dis[i]=1;
// f[0]++;
}
}
while(!q.empty()){
int u=q.front();
q.pop();
f[dis[u]]++;
maxx=max(maxx,dis[u]);
for(int i=head[u];i;i=p[i].next){
int v=p[i].v;
ru[v]--;
if(ru[v]==0){
dis[v]=max(dis[v],dis[u]+1);
q.push(v);
}
}
}
// rep(i,1,maxx)
// cout<<f[i]<<endl;
rep(i,1,maxx){
a[i]=a[i-1]+f[maxx-i+1];
a[i]%=mod;
// cout<<a[i]<<endl;
}
int ll=fpow(2,n-1);
//cout<<ll;
int anss=0;
rep(i,1,maxx){
//cout<<ll*a[i]<<" "<<i<<" "<<a[i]<<endl;
anss+=ll*a[i];
anss%=mod;
}
cout<<anss<<endl;
id=0;
rep(i,0,n){
dis[i]=0;
ru[i]=0;
a[i]=0;
f[i]=0;
head[i]=0;
edg[i].erase(edg[i].begin(),edg[i].end());
}
}
return 0;
}
/*
*/
给定带权的有向图,你可以翻转若干条边,花费为所有翻转边中最大的边权,求使得存在一个点,它能到达其他所有点的最小花费。
这次的E出奇的的简单啊,一眼二分翻转的最大边权,然后把所有小于的边变为双向边检测是否连通即可。有趣的是题解在求解连通性时使用的手法。
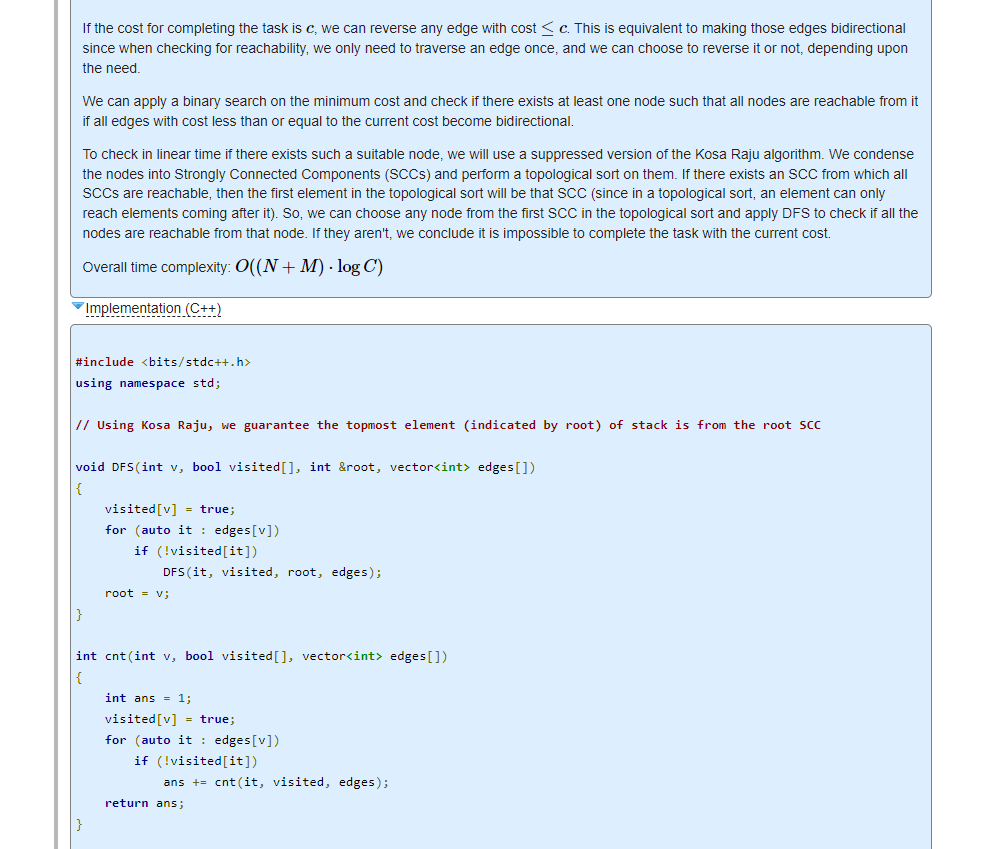

首先介绍一下kosaraju算法(感觉是个挺冷门的知识啊):用于求有向图中的强连通分量。说白了就是先dfs一次,如果有点没有访问过就把它所在的链全访问一遍,记录顺序,然后把所有链自己按顺序存储,链与链之间的顺序按逆序存储,然后在反图上再跑一边进行染色,染到的点就是一个强连通分量。
而题解中的代码本质上是用DFS1找了个拓扑排序的开头,然后尝试从这里走到其他点以检测连通性。这之所以成立是因为拓扑排序的开头本质上是最不可能经由其他点到达的点,如果从它开始能访问到其他点那就找到了答案。反之如果不行,那说明这个图没有更有可能到达其他点的起点了。
本题的代码就不写了,下面是kosaraju的板子,摘自其他博客
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
const int N = 100010;
vector<int> G[N],rG[N];
vector<int> S; // 存第一次dfs1()的结果,即标记点的先后顺序,优先级小的点先进
int vis[N]; // vis[i]标记第一次dfs1()点i是否访问过
int sccno[N]; // sccno[i]标记点i属于第几个强连通分量,同时记录dfs2()过程中点i是否访问过
int cnt; //cnt表示强连通分量的个数
void dfs1(int u){
if(vis[u]) return;
vis[u] = 1;
for(int i=0; i<G[u].size(); i++)
dfs1(G[u][i]);
S.push_back(u); //记录点的先后顺序,按照拓扑排序,优先级大的放在S的后面
}
void dfs2(int u){
if(sccno[u]) return;
sccno[u] = cnt;
for(int i=0; i<rG[u].size(); i++)
dfs2(rG[u][i]);
}
void Kosaraju(int n) {
cnt = 0;
S.clear();
memset(vis,0,sizeof(vis));
memset(sccno,0,sizeof(sccno));
for(int i=1; i<=n; i++) //搜索所有点
dfs1(i);
for(int i=n-1; i>=0; i--){
if(!sccno[S[i]]){
cnt++;
dfs2(S[i]);
}
}
}
int main() {
int n,m,u,v;
while(cin >> n >> m && (n || m)) {
for(int i=0; i<n; i++) {
G[i].clear();
rG[i].clear();
}
for(int i=0; i<m; i++) {
cin >> u >> v;
G[u].push_back(v); // 原图
rG[v].push_back(u); // 反图
}
Kosaraju(n);
}
return 0;
}
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
我知道这篇文章在这里:RubySlim-Howdoyoudefineanelement'sclasswitharailshelperorvariable?我已经尝试了所有三种解决方案。不幸的是,对我来说,没有一个在工作。论坛.rb.panel.panel-heading.span=@forum.name.panel-body.row.col-md-7#{t('global.topic')}.col-md-3.value.title.col-md-1.value.topic.col-md-1.value.dateforum_feed.js.coffeewindow.ForumFeedUI
当验证未通过时,如何停止Rails更改我的代码。每次rails用包裹我的字段...我可以编辑fields_with_error类.fields_with_error{display:inline}这行得通,但它是hacky 最佳答案 没关系。使用CSS而不是这样做。ActionView::Base.field_error_proc=Proc.newdo|html_tag,instance_tag|"#{html_tag}"end我觉得这更hacky:) 关于ruby-on-rails-R
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat
我有这个div我想要的结果是有没有办法在我的erb中添加类(class)?我试过了但是当它呈现时,它不会逃逸到ruby代码中......和想法? 最佳答案 它与一起%>"> 关于ruby-on-rails-使用RubyonRails将类动态添加到.erb中的div,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/3015986/