 去年我写过一篇吐槽国产数据库文档的文章,后来很多国产数据库厂商都和我做了关于文档方面的沟通,希望我给他们提一些建议。当时我和OB、高斯关于文档的沟通做得都很细。十分高兴的是,我对OB文档的一些建议得到了很好的响应。在OB4文档的预览版中我十分高兴地看到了《参考指南》这份文档,更令我惊喜的是这份文档十分详尽,有7000多页。从内容上来看,这份文档并不是对v2.2.7文档中SQL参考和数据库参考的简单合并,而是真正的把和OB数据库相关的信息都相对完整地做了最细致的描述。对于一个数据库产品而言,丰富的参考文档可以为使用者提供更好的帮助。在文档中还是美中不足,缺少了一份十分重要的文档,那就是《数据库升级指南》,让用户能够更顺利的从OB 2.x和OB 3.X升级到4.x。数据迁移指南中有十分详尽的从Oracle、MySQL等数据库将数据迁移到OB的介绍,但是就是找不到如何从低版本的OB中将数据升级或者迁移到OB4的描述。下面关于OB4的介绍都不是我直接体验OB4产品后写的,而只是从文档中了解的。要了解OB4企业版,首先我们需要了解一下OB4的社区版与企业版之间的差异。社区版是我们可以在社区下载安装的,而企业版是需要付费购买许可证的。
去年我写过一篇吐槽国产数据库文档的文章,后来很多国产数据库厂商都和我做了关于文档方面的沟通,希望我给他们提一些建议。当时我和OB、高斯关于文档的沟通做得都很细。十分高兴的是,我对OB文档的一些建议得到了很好的响应。在OB4文档的预览版中我十分高兴地看到了《参考指南》这份文档,更令我惊喜的是这份文档十分详尽,有7000多页。从内容上来看,这份文档并不是对v2.2.7文档中SQL参考和数据库参考的简单合并,而是真正的把和OB数据库相关的信息都相对完整地做了最细致的描述。对于一个数据库产品而言,丰富的参考文档可以为使用者提供更好的帮助。在文档中还是美中不足,缺少了一份十分重要的文档,那就是《数据库升级指南》,让用户能够更顺利的从OB 2.x和OB 3.X升级到4.x。数据迁移指南中有十分详尽的从Oracle、MySQL等数据库将数据迁移到OB的介绍,但是就是找不到如何从低版本的OB中将数据升级或者迁移到OB4的描述。下面关于OB4的介绍都不是我直接体验OB4产品后写的,而只是从文档中了解的。要了解OB4企业版,首先我们需要了解一下OB4的社区版与企业版之间的差异。社区版是我们可以在社区下载安装的,而企业版是需要付费购买许可证的。| 类目 | 功能 | 企业版 | 社区版 |
| 兼容性 | Oracle 语法兼容 | 支持 | 不支持 |
| 高性能 | 高 级 执 行 计 划 管 理 (SPM,ACS) | 支持 | 不支持 |
| 安全 | 审计 | 支持 | 不支持 |
| 安全 | 高级安全扩展能力 | 支持 | 不支持,社 区 版 本 不 支 持 行 级 标 签 、数 据 和 日 志 加 密 存 储(TDE)。 |
| 运维管理 | 图形化开发及管控工具 | 支持 | 支持,社区版本支持 OCP、 OMS、ODC 等商业配套 图 形 化 开 发 和 管 控 工 具 二 进 制 免 费 下 载 使 用 , 但不包含 OMA。 |
| 支持与服务 | 技 术 咨 询 (产 品 技 术 咨 询服务) | 支持 | 社 区 版 本 仅 提 供 社 区 化 的 产 品 技 术 咨 询 服 务 , 采用社区 issues 运作模 式 , 不 提 供 商 业 化 专 家 团队技术咨询 |
| 支持与服务 | 服 务 获 取 (获 取 技 术 支 持的渠道) | 专业商业支持团队 | 社 区 版 本 仅 支 持 在 OceanBase 社区官方网 站 或 官 方 社 区 提 供 在 线 服 务 咨 询 , 不 提 供 商 业 化专家团队专属服务 |
| 支持与服务 | 专 家 服 务 (规 划 、 实 施 、巡 检 、故 障 恢 复 、 生产保障) | 商业专家驻场服务 | 社 区 版 本 不 提 供 专 家 保 障服务 |
| 支持与服务 | 故障响应 | 7*24 服务 | 社 区 版 本 不 提 供 故 障 应 急处理服务 |
 OB采用SHARE NOTHING架构的对等模式,通过多个ZONE来实现多副本高可用。在服务器上会运行叫做 observer 的单进程程序作为数据库的运行实例,使用本地的文件存储数据 Redo 日志。OB在复制层使用日志流(LS、LogStream) 在多副本之间同步状态,每个OBSERVER中会有多个日志流,每个Tablet 都通过负载均衡的模式对应一个唯一的日志流,DML 操作写入 Tablet 的数据所产生的 Redo 日志会持久化在日志流中。日志流的多个副本会分布在不同的可用区中,多个副本之间通过共识算法选择其中一个副本作为主副本,其他的副本皆为从副本。日志流以租户为单位,每个租户在每台机器上都会有一个唯一的主副本日志流,同时存在多个其他副本的日志流。这种设计实际上实现了真正的租户隔离,我们在分析某个数据库是不是原生态支持多租户的时候,日志流的隔离是一个十分重要的判断因素,只有基于租户粒度的日志流隔离,才能确保一个租户与另外一个租户之间保持真正的隔离。当创建新的Tablet的时候会基于负载均衡原则选择一个日志流,而当某个日志流的负载不均衡的时候,OB会自动裂变生成新的日志流并进行自动均衡。OB4.0对副本做了优化,以满足不同的需求。其副本种类如下:l全能型副本:也就是目前支持的普通副本,拥有事务日志,MemTable 和 SSTable 等全部完整的数据和功能。它可以随时快速切换为 Leader 对外提供服务。l日志型副本:只包含日志的副本,没有 MemTable 和 SSTable。它参与日志投票并对外提供日志服务,可以参与其他副本的恢复,但自己不能变为主提供数据库服务。日志型副本在构建双活系统中可以作为第三点存在,因为其只存储日志,可以大大节约存储空间。l只读型副本:包含完整的日志,MemTable 和 SSTable 等,但是它的日志比较特殊。它不作为 Paxos 成员参与日志的投票,而是作为一个观察者实时追赶 Paxos 成员的日志,并在本地回放。这种副本可以在业务对读取数据的一致性要求不高的时候提供只读服务。因其不加入 Paxos 成员组,又不会造成投票成员增加导致事务提交延时的增加。当一个Tablet被修改的时候,可以通过WAL来确保其一致性,而如果当某个事务修改的数据跨多个日志流的时候,就需要通过两阶段提交算法来确保事务的一致性了。这时候事务层会选择一个事务修改的日志流产生协调者状态机,协调者会与事务修改的所有日志流通信,判断WAL是否持久化,当所有日志流都完成持久化后,事务进入提交状态,协调者会再驱动所有日志流写下这个事务的Commit日志,表示事务最终的提交状态。协调者状态机的存在会对分布式事务的延时有所影响,这也是我以前总说的分布式数据库可以提高并发事务处理的并发量,但是不会直接提高单个事务的性能。
OB采用SHARE NOTHING架构的对等模式,通过多个ZONE来实现多副本高可用。在服务器上会运行叫做 observer 的单进程程序作为数据库的运行实例,使用本地的文件存储数据 Redo 日志。OB在复制层使用日志流(LS、LogStream) 在多副本之间同步状态,每个OBSERVER中会有多个日志流,每个Tablet 都通过负载均衡的模式对应一个唯一的日志流,DML 操作写入 Tablet 的数据所产生的 Redo 日志会持久化在日志流中。日志流的多个副本会分布在不同的可用区中,多个副本之间通过共识算法选择其中一个副本作为主副本,其他的副本皆为从副本。日志流以租户为单位,每个租户在每台机器上都会有一个唯一的主副本日志流,同时存在多个其他副本的日志流。这种设计实际上实现了真正的租户隔离,我们在分析某个数据库是不是原生态支持多租户的时候,日志流的隔离是一个十分重要的判断因素,只有基于租户粒度的日志流隔离,才能确保一个租户与另外一个租户之间保持真正的隔离。当创建新的Tablet的时候会基于负载均衡原则选择一个日志流,而当某个日志流的负载不均衡的时候,OB会自动裂变生成新的日志流并进行自动均衡。OB4.0对副本做了优化,以满足不同的需求。其副本种类如下:l全能型副本:也就是目前支持的普通副本,拥有事务日志,MemTable 和 SSTable 等全部完整的数据和功能。它可以随时快速切换为 Leader 对外提供服务。l日志型副本:只包含日志的副本,没有 MemTable 和 SSTable。它参与日志投票并对外提供日志服务,可以参与其他副本的恢复,但自己不能变为主提供数据库服务。日志型副本在构建双活系统中可以作为第三点存在,因为其只存储日志,可以大大节约存储空间。l只读型副本:包含完整的日志,MemTable 和 SSTable 等,但是它的日志比较特殊。它不作为 Paxos 成员参与日志的投票,而是作为一个观察者实时追赶 Paxos 成员的日志,并在本地回放。这种副本可以在业务对读取数据的一致性要求不高的时候提供只读服务。因其不加入 Paxos 成员组,又不会造成投票成员增加导致事务提交延时的增加。当一个Tablet被修改的时候,可以通过WAL来确保其一致性,而如果当某个事务修改的数据跨多个日志流的时候,就需要通过两阶段提交算法来确保事务的一致性了。这时候事务层会选择一个事务修改的日志流产生协调者状态机,协调者会与事务修改的所有日志流通信,判断WAL是否持久化,当所有日志流都完成持久化后,事务进入提交状态,协调者会再驱动所有日志流写下这个事务的Commit日志,表示事务最终的提交状态。协调者状态机的存在会对分布式事务的延时有所影响,这也是我以前总说的分布式数据库可以提高并发事务处理的并发量,但是不会直接提高单个事务的性能。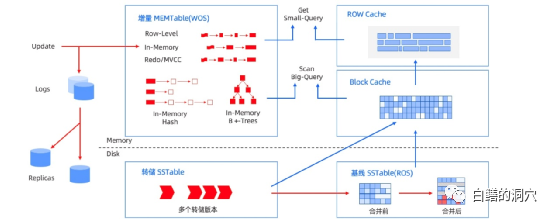 在存储架构上,OB存储层以一张表或者一个分区为粒度存储数据,每个分区对应一个用于存储数据的 Tablet(分片),用户定义的非分区表也会对应一个 Tablet。Tablet的内部是分层存储的结构。DML操作首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 L0 SSTable。L0 SSTable 个数达到阈值后会将多个L0 SSTable合并成一个 L1 SSTable。在每天配置的业务低峰期,Major Merge会将所有的MemTable、L0 SSTable和L1 SSTable 合并成一个 Major SSTable。Major Merge是一个高开销的工作,因此在这个窗口内不要安排大型的维护作业。每个 SSTable 内部是以2MB定长宏块为基本单位,每个宏块内部由多个不定长微块组成。MajorSSTable 的微块会在合并过程中用编码方式进行格式转换,微块内的数据会按照列维度分别进行列内的编码,每一列压缩结束后,还会对多列进行列间等值/子串等规则编码。在编码压缩之后,还可以根据用户指定的通用压缩算法进行无损压缩,进一步提升数据压缩率。从上述的存储结构看,OB采用的是一种混合列压缩结构的存储机制。
在存储架构上,OB存储层以一张表或者一个分区为粒度存储数据,每个分区对应一个用于存储数据的 Tablet(分片),用户定义的非分区表也会对应一个 Tablet。Tablet的内部是分层存储的结构。DML操作首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 L0 SSTable。L0 SSTable 个数达到阈值后会将多个L0 SSTable合并成一个 L1 SSTable。在每天配置的业务低峰期,Major Merge会将所有的MemTable、L0 SSTable和L1 SSTable 合并成一个 Major SSTable。Major Merge是一个高开销的工作,因此在这个窗口内不要安排大型的维护作业。每个 SSTable 内部是以2MB定长宏块为基本单位,每个宏块内部由多个不定长微块组成。MajorSSTable 的微块会在合并过程中用编码方式进行格式转换,微块内的数据会按照列维度分别进行列内的编码,每一列压缩结束后,还会对多列进行列间等值/子串等规则编码。在编码压缩之后,还可以根据用户指定的通用压缩算法进行无损压缩,进一步提升数据压缩率。从上述的存储结构看,OB采用的是一种混合列压缩结构的存储机制。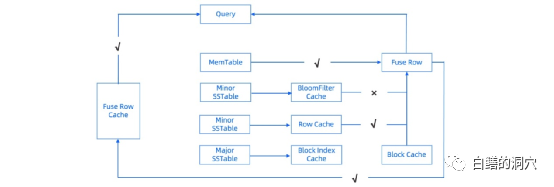 为了数据扫描的提高性能,OB设置了多个缓冲区, OceanBase是LSM-TREE存储架构的,因此其数据库缓冲区与Oracle、Mysql、Postgresql等是完全不同的,在DB CACHE中不会产生数据修改,不会存在脏块,因此OB的缓冲区是一个只读的“纯缓冲”。OB4的缓冲区设计与2.2版本基本相似,除了一些字典缓冲有些变化外,主要的缓冲区都基本上沿用了以前版本的设计。对于LSM-TREE存储架构的数据库,有可能同一行的数据存储在多个SSTAB或者MEMTAB中,为了提高访问效率,OB设置了融合结果缓冲区FUSE ROW CACHE,查询可以直接在FUSE ROW CACHE中命中。虽然SST是排序表,可以通过二分法定位到某一行,不过对于访问比较频繁的数据行,还是有个缓冲比较好,于是row cache就承担了这个工作。Block Index Cache存储的是宏块中的微块的地址,通过这个cache提高在2MB的宏块中查找数据的效率。Block Cache是类似于Oracle DB CACHE的缓冲,存储的是OB的微块。因为OB的微块是可变长的,因此OB的Block Cache在访问算法与特性上与Oracle DB CACHE有较大的不同。 OB的BloomFilter CACHE 是一个针对宏块的过滤器,当一个宏块上的空查次数超过某个阈值时,就会自动构建 BloomFilter,并放入BloomFilter Cache。OB的CACHE都是可变长的,为了便于管理,OB设计了ObKVCacheMap结构,以2MB为单位进行内存分配与释放管理。LSM-TREE存储架构的数据库在CACHE上比BTREE架构的要复杂的多,从CACHE的设计可以看出OB在这方面已经有了比较成熟的解决方案,并且这些缓冲区的设计都是面向不同的业务场景的。
为了数据扫描的提高性能,OB设置了多个缓冲区, OceanBase是LSM-TREE存储架构的,因此其数据库缓冲区与Oracle、Mysql、Postgresql等是完全不同的,在DB CACHE中不会产生数据修改,不会存在脏块,因此OB的缓冲区是一个只读的“纯缓冲”。OB4的缓冲区设计与2.2版本基本相似,除了一些字典缓冲有些变化外,主要的缓冲区都基本上沿用了以前版本的设计。对于LSM-TREE存储架构的数据库,有可能同一行的数据存储在多个SSTAB或者MEMTAB中,为了提高访问效率,OB设置了融合结果缓冲区FUSE ROW CACHE,查询可以直接在FUSE ROW CACHE中命中。虽然SST是排序表,可以通过二分法定位到某一行,不过对于访问比较频繁的数据行,还是有个缓冲比较好,于是row cache就承担了这个工作。Block Index Cache存储的是宏块中的微块的地址,通过这个cache提高在2MB的宏块中查找数据的效率。Block Cache是类似于Oracle DB CACHE的缓冲,存储的是OB的微块。因为OB的微块是可变长的,因此OB的Block Cache在访问算法与特性上与Oracle DB CACHE有较大的不同。 OB的BloomFilter CACHE 是一个针对宏块的过滤器,当一个宏块上的空查次数超过某个阈值时,就会自动构建 BloomFilter,并放入BloomFilter Cache。OB的CACHE都是可变长的,为了便于管理,OB设计了ObKVCacheMap结构,以2MB为单位进行内存分配与释放管理。LSM-TREE存储架构的数据库在CACHE上比BTREE架构的要复杂的多,从CACHE的设计可以看出OB在这方面已经有了比较成熟的解决方案,并且这些缓冲区的设计都是面向不同的业务场景的。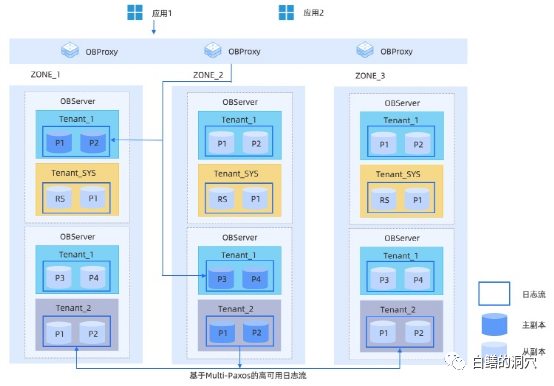 最后我们来看看OB的高可用,实际上OB高可用涉及的技术细节十分复杂,今天我们仅仅从集群架构来看看应用如何实现高可用。OB的高可用架构在OB4里变化不大,除了数据库本身通过Multi-Paxos共识协议实现副本之间的选举与同步外,OBProxy依然是OB高可用的不可或缺的组件。应用通过本身带有高可用与负载均衡能力的OBProxy访问单个或者多个OB集群,从而实现应用级的高可用。当客户端通过OBProxy代理连接OBServer的时候,OBProxy需要帮助客户端维持集群中的可用性状态,OBProxy通过多种方式实现探活,并随时更新黑名单,确保应用的正确访问。今天简单的分析一下OB,下周OB4.1的商用版就要发布了,我们也准备等下周OB 4.1发布之后对OB4商用版进行试用,届时我再把测试的情况写出来和大家分享吧。
最后我们来看看OB的高可用,实际上OB高可用涉及的技术细节十分复杂,今天我们仅仅从集群架构来看看应用如何实现高可用。OB的高可用架构在OB4里变化不大,除了数据库本身通过Multi-Paxos共识协议实现副本之间的选举与同步外,OBProxy依然是OB高可用的不可或缺的组件。应用通过本身带有高可用与负载均衡能力的OBProxy访问单个或者多个OB集群,从而实现应用级的高可用。当客户端通过OBProxy代理连接OBServer的时候,OBProxy需要帮助客户端维持集群中的可用性状态,OBProxy通过多种方式实现探活,并随时更新黑名单,确保应用的正确访问。今天简单的分析一下OB,下周OB4.1的商用版就要发布了,我们也准备等下周OB 4.1发布之后对OB4商用版进行试用,届时我再把测试的情况写出来和大家分享吧。 给定一个文本,我想删除url部分并保留其他文本。例子:'blablabla...blablabla...http://bit.ly/someuriblablabla...'成为'blablabla...blablabla...blablabla...'是否有任何ruby内置方法可以有效地执行此操作? 最佳答案 尝试使用正则表达式:(?:f|ht)tps?:\/[^\s]+ 关于ruby-使用ruby从文本中删除url,我们在StackOverflow上找到一个类似的问题:
我有一个相对较大的文本文件,其中包含如下分层的数据block:ANALYSISOFXSIGNAL,CASE:1TUNEX=0.2561890123390808LineFrequencyAmplitudePhaseErrormxmymsp10.2561890123391E+000.204316425208E-010.164145385871E+030.00000000000E+00100020.2562865535359E+000.288712798671E-01-.161563284233E+030.97541196785E-041000(它们包含更多行然后重复)我想先提取TUNEX=
我有一些带有硬换行符的文本,如下所示:Thisshouldallbeononelinesinceit'sonesentence.Thisisanewparagraphthatshouldbeseparate.我想删除单个换行符但保留双换行符,所以它看起来像这样:Thisshouldallbeononelinesinceit'sonesentence.Thisisanewparagraphthatshouldbeseparate.是否有一个正则表达式可以做到这一点?(或一些简单的方法)到目前为止,这是我唯一可行但感觉很老套的解决方案。txt=txt.gsub(/(\r\n|\n|\r)/
有没有Ruby工具可以让我加载格式为(Abbreviated=>Abr)的缩写文件?然后我需要从另一个文件中读取每个单词。如果单词与缩写中的单词匹配,我需要将其更改为缩写词。我想我可以使用哈希,但我不知道如何从文件加载它。 最佳答案 YAML是一种非常通用的数据存储格式,可以在应用程序和编程语言之间传输。JSON是另一种替代方法,这在网站中很常见。我将YAML用于配置文件之类的内容,因为它非常容易读取和修改。例如,这个Ruby结构:irb(main):002:0>foo={'a'=>1,'b'=>[2,3],'c'=>{'d'=>4
出于某种原因,我找不到任何提及如何执行此操作的教程...那么,如何从文件中读取前n行?我想出了:whileFile.open('file.txt')andcount但它不起作用,而且对我来说也不是很好。出于好奇,我试过类似的东西:File.open('file.txt').10.timesdo|f|但这也没有真正起作用。那么,有没有一种简单的方法可以只读取前n行而不必加载整个文件?非常感谢! 最佳答案 这是一个单行解决方案:lines=File.foreach('file.txt').first(10)我担心它可能不会及时关闭文件(
我想要rubyonrails中的正则表达式,它从给定文本中删除所有html标签及其内容。例如,如果我的文本是:-INPUT:-Hi那么它应该只显示OUTPUT应该如下:-Hi简而言之,我想要一个正则表达式或一个函数来删除以及之间的任何内容。感谢和问候,萨利尔盖克瓦德 最佳答案 'Hi'.gsub(/]+>/,'') 关于ruby-on-rails-rubyonrails正则表达式从文本中删除html标签及其内容,我们在StackOverflow上找到一个类似的问题:
我正在构建一个应该在服务器上运行并分析声音文件的工具。我想在Ruby中执行此操作,因为我的所有其他工具也是用Ruby编写的。但我很难找到完成此任务的好方法。我发现的很多例子都是在做可视化和图形化的东西。我只需要FFT数据,仅此而已。我既需要获取音频数据,又需要对其进行FFT。我的最终目标是计算一些东西,例如所有频率(加权幅度)的均值/中值/众数、第25个百分位数和第75个百分位数、BPM,也许还有其他一些好的特性,以便以后能够将相似的声音聚集在一起.首先,我尝试使用ruby-audio和fftw3,但我从未将两者真正结合使用。文档也不好,所以我真的不知道有什么数据被洗牌了。接下来,我尝
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。据我了解,在给定文档中扫描电子邮件时,Regex并不是最好的选择。我想知道是否有其他选择?或者我不知道的一些最佳实践方式?
我已经看到了一些非常漂亮的Ruby示例,我正在努力改变我的想法,以便能够制作它们,而不是仅仅欣赏它们。这是我能想到的从文件中随机选择一行的最佳方法:defpick_random_linerandom_line=nilFile.open("data.txt")do|file|file_lines=file.readlines()random_line=file_lines[Random.rand(0...file_lines.size())]endrandom_lineend我觉得有可能以更短、更优雅的方式执行此操作,而无需将整个文件的内容存储在内存中。有吗?
我希望“ThisIsA101Test”成为“ThisIsATest”,但语法不正确。src='ThisIsA101Test'puts"A)"+src#base=>"ThisIsA101Test"puts"B)"+src[/([a-z]+)/]#onlydoesfirstword=>"his"puts"C)"+src.gsub!(/\D/,"")#Doesdigits,Iwantalphabetic=>"101"puts"D)"+src.gsub!(/\W///g)#Nothing.=>""puts"E)"+src.gsub(/(\W|\d)/,"")#Nothing.=>""