在启动Stable Diffusion时一直报Torch not compiled with CUDA enabled警告,一开始没在意本着能用就行的态度凑活用,每个图都耗时十多秒,然后本着好奇Torch not compiled with CUDA enabled这个警告去搜索解决方案,都没说这个警告解决了有什么用,并且网上资料东拼西凑根本不能解决问题,本着专研解决问题的心态花一晚上解决这个警告,并将计算速度提高了十倍基本4G的模型2秒能出图。
出现这个问题是两个方面一是的确显存不足
本地环境:windows11 13900k 32G Nvidia 3080ti
当前显卡驱动版本:
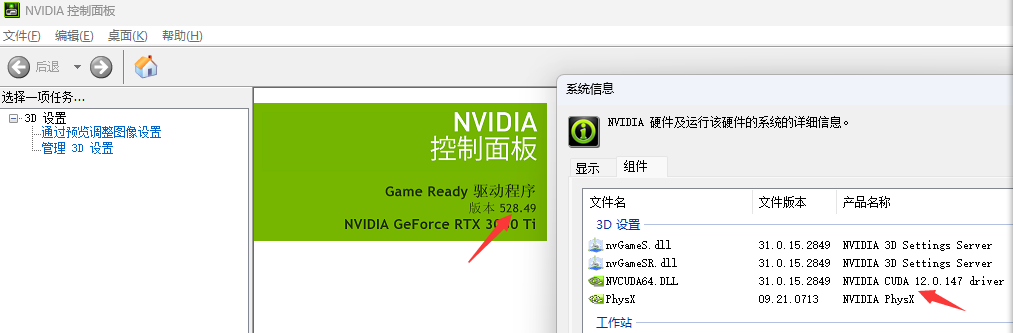
注意上面的CUDA12.0.147不一定要和CUDA Toolkit 版本一样,但是CUDA Toolkit一定要和pytorch中版本一样

我没用conda太麻烦了,直接裸装到本地python环境速度还快,下面是步骤:
正式开始
首先要安装cuda_11.6.0_511.23_windows.exe 这个版本必须要和pytorch官网对应(其实不一定非要安装最新的cuda老的也可以的只要版本对上),然后安装pytorch可以从官网或者本地,如果安装过程中出现以来报错,可以检查手动安装依赖再重新安装
网盘地址:
我用夸克网盘分享了「cuda驱动」,
链接:https://pan.quark.cn/s/678739c40a91
关于CUDA Toolkit 与你的显卡驱动版本对应关系可以参考这个文档,他都是大于等于也就是说你的cuda老版本也没关系 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html 可以如上图看显卡版本或者cmd命令行执行nvidia-smi查看
1.下载CUDA Toolkit
cuda_11.6.0_511.23_windows.exe (全部下一步)
2.安装pytorch
https://pytorch.org/get-started/locally/ 参考地址
pip都是在cmd命令行安装如果没pip去baidu查一下python pip安装教程,python版本我这里是10.0
组合脚本(在线安装):
pip install protobuf==3.20.0 requests==2.28.2 torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
本地安装(可选)
下载地址:https://download.pytorch.org/whl/cu116/torch-1.13.1%2Bcu116-cp310-cp310-win_amd64.whl
pip install protobuf==3.20.0 requests==2.28.2 torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 torch-1.13.1+cu116-cp310-cp310-win_amd64.whl
python命令行:
import torch
torch.cuda.is_available()
如果返回true表示安装成功


50步加了很多关键词才19秒不到
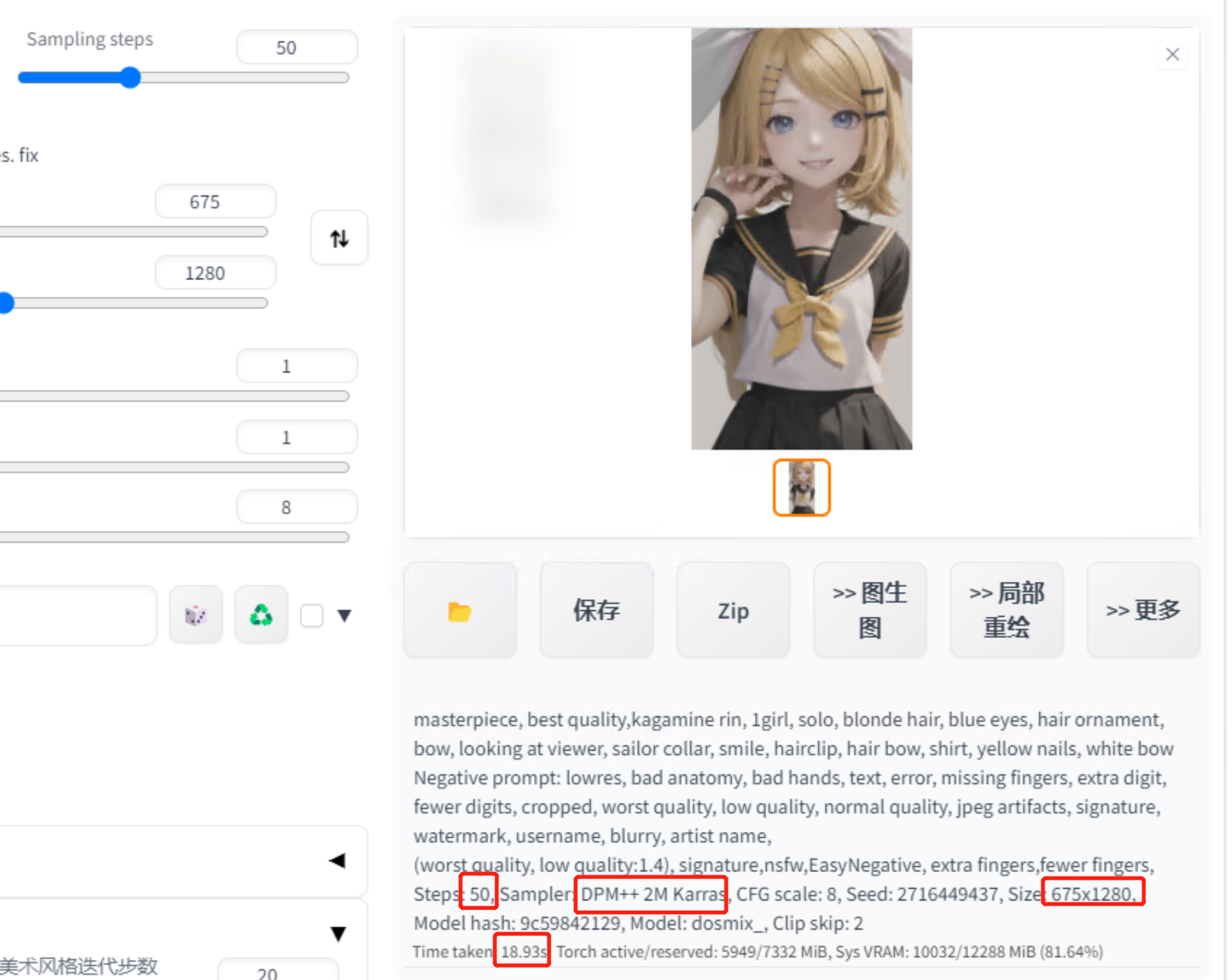
如果20步只要3秒,并且分辨率也高不会崩溃。

另外补充就是分辨率采样过高报错问题:
RuntimeError: CUDA out of memory. Tried to allocate 31.29 GiB(GPU 0; 12.00 GiB total capacity; 4.29 GiBlready allocated; 5.1l GiB free; 4.37 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
————————————————
对于小显存我设置成
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:32 貌似也能解决问题,这个需要在启动bat里面加入一行就行了
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序