
在互联网技术飞速发展的今天,数据已经成为了最为宝贵的资源之一。数据的产生、收集和分析,已经成为了科技公司最为重要的一环。到底什么是湖仓一体?它和数据仓库、数据湖的关系是什么?为什么要用一体来形容呢?
从一体机、超融合到云计算、HTAP,我们不断尝试将多种应用场景融合在一起并试图通过一种技术来解决一类问题,借以达到使用简单高效的目标。现在很热的湖仓一体(Lakehouse)也一样,如果能将数据湖和数据仓库融合在一起就可以同时发挥二者的价值。
数据湖和数据仓库一直以来都有十分密切的联系但同时存在显著的差异。数据湖更注重原始信息的保留,将原始数据“原汁原味”地保存下来是数据湖的首要目标。但原始数据中有很多垃圾数据,原样保留就意味着垃圾数据都要存进数据湖?没错,数据湖就是这样一个数据垃圾场,不管什么样的数据一股脑存进去再说。所以,数据湖面临的第一个问题是海量(垃圾)数据存储问题。
得益于现代存储技术的长足进步,现在海量数据存储的成本很低(如分布式文件系统)完全可以满足数据湖存储的需要。但数据光存起来还不行,还要使用也就是计算才能发挥价值。数据湖数据五花八门,各种类型的数据处理方式也不一样。其中最核心也最重要的是结构化数据处理,无论是历史沉淀还是业务新增,结构化数据处理仍然是重中之重,很多半结构化和非结构化数据计算最后也会转到结构化数据计算上。不过很遗憾,由于数据湖的存储(文件系统)本身没有计算能力,没法在数据湖上直接处理数据,想要处理这些数据还需要借助其他技术(如数据仓库),**“能存不能算”**是目前数据湖面临的主要问题。
数据仓库就刚好相反了,数据仓库基于 SQL 体系往往具备很强的结构化数据计算能力,但原始数据需要经过一系列清洗转换、深度组织满足数据库约束才能入仓,这个过程会伴随大量原始信息丢失甚至数据粒度变粗无法获得更低粒度的数据价值,而且数据仓库是高度面向主题的,为一个或某几个主题服务,主题外的数据并非数据仓库关注的目标,这会导致数据利用范围相对狭小,无法像数据湖一样探索全量、未知的数据价值,更无法像数据湖一样存储海量原始数据,相对数据湖来说数据仓库**“能算不能存”**。
就数据流向来看,数据仓库的数据可以基于数据湖整理,那么一个很自然的想法就是将数据湖和数据仓库的融合在一起,实现**“既能存又能算”**,也就是所谓的“湖仓一体”。
那么现在实现的咋样呢?
简单粗暴的办法是在数据湖上开放数据访问权限供数据仓库实时调用(所谓的实时是相对以前需要定时将数据湖中数据批量 ETL 到数据仓库来说的,实际操作中仍然有一定延时),二者物理上仍分存两处,通过高速网络进行数据交互,由于具备了一定的“实时”数据湖数据处理能力,因此现在把这种实现(更多是架构上的)称为湖仓一体。
就这样?这也能叫湖仓一体?
那你看看,只要你(喊的)不尴尬,尴尬的就是别人(听的)。
那数据仓库咋读数据湖的数据呢?常见的做法是在数据仓库中创建外部表 /schema 映射 RDB 的表或 schema,或者 hive 的 metastore,这个过程与传统的关系数据库通过外部表方式访问外部数据的方式是一样的,虽然保留了元数据信息,但缺点却十分明显。这要求数据湖有相应关系模型下的表和 schema 映射,数据仍需要整理才能使用,而且可利用的数据源种类减少(如无法直接基于 NoSQL、文本、Webservice 做映射)。同时即使数据湖中有其他可供计算的数据源(如 RDB)数据仓库在计算(如分组汇总)时通常还会将数据拉到本地才能计算,产生了大量的数据传输成本导致性能下降,问题多多。
现在的湖仓一体除了能“实时”数据交互以外,原来批量定时整理数据的通道仍然保留,这样可以将数据湖数据整理好存入数仓实施本地计算,当然这已经跟湖仓一体没太大关系了,没有“一体”之前也是这么做的。
不管怎样,无论通过传统的 ETL 将数据由湖到仓,还是通过外部映射“实时”数据由湖到仓,数据湖和数据仓库几乎没有任何变化(只是提升了由湖到仓的数据传输频率,还要符合很多条件),物理仍然上分存两处,湖是湖,仓是仓, 二者根本没有一体! 不仅数据多样性和效率问题没得到根本解决(灵活性不足),数据湖的“脏乱差”数据也还需要整理入仓才能使用(时效性很差)。通过这种方式实现的“湖仓一体”想要在数据湖上构建实时高效地数据处理能力恐怕是个笑话。
为什么会出现这种情况?
如果我们稍加思考就会发现,问题出现在数据仓库上。数据库体系过于封闭缺乏开放性,数据只有入库(包括外部数据映射)才能计算。不仅如此,由于数据库上的约束,数据必须经过深度整理符合规范后才能入库,而数据湖的原始数据本身就充斥着大量“垃圾”,整理这些数据本身无可厚非,但很难响应数据湖上的实时计算需求。如果数据库具备足够的开放性,可以直接计算数据湖上未经整理的数据,甚至可以基于多种不同类型的数据源混合计算,同时提供高性能机制保证计算效率那湖仓一体就可以很好实现了。不过很遗憾,数据库没法完成这个目标。
但开源集算器 SPL 可以。
开源 SPL 就是这样一个可应用在数据湖中提供开放计算能力的结构化数据计算引擎。可以针对数据湖的原始数据直接计算,没有约束,无需“入库”。同时 SPL 还提供了多样性数据源混合计算的能力,无论数据湖使用统一文件系统构建,还是基于多样性数据源(RDB、NoSQL、LocalFile、Webservice)使用 SPL 都可以直接混合计算,快速输出数据湖价值。此外,SPL 还提供了高性能文件存储(数仓的存储功能),在 SPL 实时计算的同时,整理数据可以从容不迫地进行,将原始数据整理到 SPL 存储中可以获得更高性能。这里尤其注意的是,使用 SPL 存储整理后数据仍然存放在文件系统中,理论上可以与数据湖存放一处,这样可以实现真正意义的湖仓一体。

在整个结构中,SPL 可以直接基于数据湖统一存储计算,也可以对接数据湖中的多样性数据源,甚至可以直接读取外部的生产数据源,这样不仅实现了数据湖上的实时计算,在某些数据时效性要求高的场景(当数据还没入湖的时候就要使用),通过 SPL 还可以对接实时数据源计算,数据时效性更高。
原来将从数据湖整理到数据仓库的工作仍可进行,将原始数据 ETL 到 SPL 高性能存储中可以获得更高的计算效率,同时采用文件系统存储,数据可以分布在 SPL 服务器(存储)上,也可以继续使用数据湖的统一文件存储,即通过 SPL 完全接管原来数据仓库的工作,这样在一个体系内就实现了湖仓一体。
下面我们具体来看一下 SPL 的这些能力。
SPL 支持多种数据源,RDB、NoSQL、JSON/XML、CSV、Webservice 等都可以连接,并进行混合计算。这样数据湖存储的各类原始数据就可以直接利用起来,无需整理就可以发挥数据价值,节省“入库”动作,保证数据使用的灵活与高效性,可以覆盖更广泛的业务需求。

有了这个能力以后,数据湖构建之初就能为应用提供数据服务,而不用等原来数据整理、入库、建模等一系列长链路长周期过程完成后才能服务。而且这种方式更加灵活,可以根据业务需要提供实时响应。
特别地,SPL 对文件的很好支持使得文件也拥有强计算能力,这样将数据湖数据存储在文件系统中也可以获得与数据库接近甚至超越的计算能力。SPL 不仅能计算文本,还支持 JSON 等多层数据格式处理,这样 NoSQL 以及 RESTful 等数据不用转换就可以直接使用,非常方便。
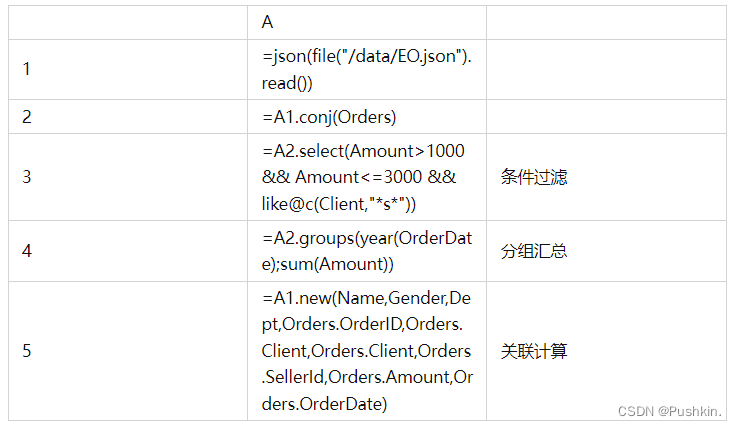
SPL 提供了完善的计算能力,基于离散数据集(而非关系代数)模型可以获得与 SQL 一样的完备计算性,同时在 SPL 敏捷语法与过程计算支持下数据处理比 SQL 更简单。

SPL 丰富的计算类库
这样数据湖就完全拥有了数据仓库的计算能力,实现了湖中有仓的第一步。
再将 SPL 的开放能力延伸一下。如果数据源与数据湖的数据同步没完成但还需要使用这部分数据怎么办?原来就只能等着了,现在有了 SPL 我们甚至可以直接对接数据源进行计算,或者与数据湖中已有数据进行混合计算都可以。逻辑上可以把数据源作为数据湖的一部分使用,这样可以获得更高的灵活性。
SPL 除了自身拥有完善的强计算能力,同时还提供了基于文件的高性能存储。将原始数据 ETL 后存储在 SPL 存储中可以获得更高的计算性能,同时文件系统具备使用灵活、易于并行等特性。提供了数据存储能力后,就完成了湖中有仓的第二步,形成新的开放灵活的数据仓库形式。
目前 SPL 提供了两种高性能文件存储类型:集文件和组表。集文件采用了压缩技术(占用空间更小读取更快),存储了数据类型(无需解析数据类型读取更快),支持可追加数据的倍增分段机制,利用分段策略很容易实现并行计算,保证计算性能。组表支持列式存储,在参与计算的列数(字段)较少时会有巨大优势。组表上还实现了 minmax 索引,同时支持倍增分段,这样不仅能享受到列存的优势,也更容易并行提升计算性能。
SPL 也很容易实施并行计算,发挥多 CPU 的优势。SPL 有很多计算函数都提供并行机制,如文件读取、过滤、排序只要增加一个 @m 选项就可以自动实施并行计算,同时也可以显示编写并行程序,通过多线程并行提升计算性能。
特别地,SPL 能支持很多 SQL 无法支持的高性能算法。比如常见的 TopN 运算,在 SPL 中 TopN 被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
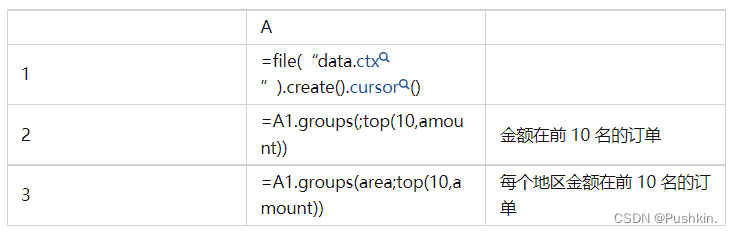
这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算 TopN 的语法基本一致,而且都会有较高的性能,类似的算法在 SPL 中还有很多。通过这些机制,SPL 可以跑出超过传统数据仓库数量级的计算性能。在数据湖中全面实现一体化数仓可不是说说而已。
更进一步,使用 SPL 还可以针对整理好的数据和未整理原始数据进行混合计算充分发挥各种类型的数据价值,而不用等所有数据整理好才能计算使用,不仅数据湖的灵活性得以充分扩展,还具备实时数据仓库的功能,这就完成了湖中有仓的第三步,兼顾了灵活性与高性能。
通过以上三步不仅可以改善数据湖的建设路径(原来需要先导入、再整理、再使用),数据整理与数据使用可以同时进行,循序渐进地建设数据湖,还在建设数据湖的过程中就完善了数据仓库,让数据湖也拥有强计算能力,实现真正意义的湖仓一体,这才是解锁 Lakehouse 的正确姿势。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
这似乎应该有一个直截了当的答案,但在Google上花了很多时间,所以我找不到它。这可能是缺少正确关键字的情况。在我的RoR应用程序中,我有几个模型共享一种特定类型的字符串属性,该属性具有特殊验证和其他功能。我能想到的最接近的类似示例是表示URL的字符串。这会导致模型中出现大量重复(甚至单元测试中会出现更多重复),但我不确定如何让它更DRY。我能想到几个可能的方向...按照“validates_url_format_of”插件,但这只会让验证干给这个特殊的字符串它自己的模型,但这看起来很像重溶液为这个特殊的字符串创建一个ruby类,但是我如何得到ActiveRecord关联这个类模型
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits