目录
1.字符指针
2.数组指针
3.指针数组
4.数组传参和指针传参
5.函数指针
6.函数指针数组
7.指向函数指针数组的指针
8.回调函数
9.qsort排序和冒泡排序
让我们一起来回顾一下指针的概念!
1.指针就是一个变量,用来存放地址,地址唯一标识一块内存空间。
2.指针的大小是固定的4/8个字节(32位平台/64位平台)
3.指针是有类型,指针的类型决定了指针的±整数的步长,指针解引用操作时候的权限。
int main()
{
char ch = 'w';
char* pc = &ch;//pc就是字符指针
char* p = "abcdef";//常量字符串,p中存放的是首字符的地址
//*p = 'w';error这是错误的,常量字符串不能被修改
return 0;
}
如果我们想修改上面的常量字符串该怎么办呢?方法如下:
int main()
{
char arr[] = "abcdef";
char* p = arr;
*p = 'w';
printf("%s\n", arr);//wbcdef
return 0;
}
一道来自剑指offer的题目:
int main()
{
char str1[] = "hello world.";
char str2[] = "hello world.";
const char* str3 = "hello world.";
const char* str4 = "hello world.";
if (str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if (str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}

存放字符的指针数组——字符指针数组
char* arr3[5];
存放整型指针的数组——整型指针数组
int* arr[6];
int main()
{
char* arr[] = { "abcdef","hehe","qwer" };//指针数组
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%s\n", arr[i]);//每个字符串首字符地址
}
return 0;
}
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
//arr就是一个存放整型指针的数组
//arr[i]=*(arr+i)
int* arr[] = { arr1,arr2,arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
//printf("%d ", arr[i][j]);
printf("%d ", *(arr[i] + j));
}
printf("\n");
}
return 0;
}
数组指针就是指向数组的指针。
int arr[10];
&arr;取出的是数组的地址
int (*pa)[10]=&arr;//pa就是指针,pa指向的是数组arr
int main()
{
int arr[10] = { 0 };
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%p\n", &arr);
return 0;
}
&数组名和数组名的区别
数组名绝大部分情况下是数组首元素地址,两个例外:
1.&数组名,取出的是整个数组的地址。从地址值角度来讲和数组首元素地址是一样的,但是意义不一样。
2.sizeof(数组名),数组名表示整个数组,计算得到的是数组的大小。
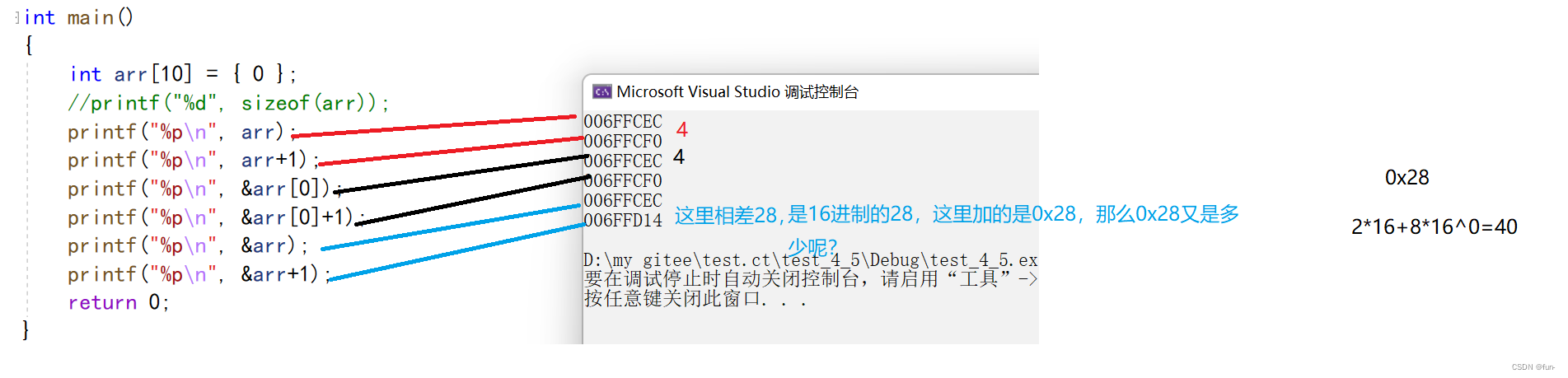
int main()
{
int arr[10] = { 0 };
int(*p)[10] = &arr;//p是一个数组指针
//类型:int(*)[10]
//printf("%d", sizeof(arr));
printf("%p\n", arr);//int*
printf("%p\n", arr+1);//4
printf("%p\n", &arr[0]);//int*
printf("%p\n", &arr[0]+1);//4
printf("%p\n", &arr);//int(*)[10]=&arr;
printf("%p\n", &arr+1);//40
return 0;
}
访问数组的几种方法:
使用下标的形式来访问数组:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
使用指针的方式访问数组:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
int* p = arr;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}
数组指针什么情况下使用呢?
//一维数组传参,形参是数组
void print(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr, sz);
return 0;
}
//一维数组传参,形参是指针
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
//printf("%d ", arr[i]);
printf("%d ", *(arr + i));
}
printf("\n");
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr, sz);
return 0;
}
//二维数组传参,形参部分写成二维数组
void print(int arr[3][5], int r, int c)
{
int i = 9;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7 };
print(arr, 3, 5);
return 0;
}
1.二维数组的数组名也表示首元素的地址
2.二维数组的首元素是第一行
3.首元素的地址就是第一行的地址,是一个一维数组的地址
//二维数组传参,形参部分写成指针
void print(int(*arr)[5], int r, int c)//通过上面引用的解读,所以这里传参,我们只传了第一行的地址,也就是数组指针
{
int i = 9;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", *(*(arr + i) + j));
//arr[i][j];
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7 };
print(arr, 3, 5);
return 0;
}
4.数组传参和指针传参
一维数组传参,形参可以是数组,也可以是指针
当形参是指针的时候,要注意类型
void test(int arr[])//ok
{}
void test(int arr[10])//ok
{}
void test(int* arr)//ok
{}
void test2(int* arr[20])//ok
{}
void test2(int** arr)//No
{}
int main()
{
int arr[10] = { 0 };
int* arr2[20] = { 0 };
test(arr);
test2(arr2);
}
二维数组传参
参数可以是指针,也可以是数组
如果是数组,行可以省略,但是列不能省略
如果是指针,传过去的是第一行的地址,形参就应该是数组指针
void test(int arr[3][5])//ok
{}
void test(int arr[][])//no
{}
void test(int arr[][5])//ok
{}
void test(int* arr)//no
{}
void test(int* arr[5])//no
{}
void test(int(*arr)[5])//ok
{}
void test(int** arr)//no
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
}
一级指针传参
void print(int *p, int sz)
{
int i = 0;
for(i=0; i<sz; i++)
{
printf("%d\n", *(p+i));
}
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9};
int *p = arr;
int sz = sizeof(arr)/sizeof(arr[0]);
//一级指针p,传给函数
print(p, sz);
return 0;
}
二级指针传参
void test(int** ptr)
{
printf("num = %d\n", **ptr);
}
int main()
{
int n = 10;
int*p = &n;
int **pp = &p;
test(pp);
//还可以传一级指针数组的数组名
test(&p);
return 0;
}
注意:函数名和&函数名是一样的,二者没有区别。
int Add(int x, int y)
{
return x + y;
}
int main()
{
printf("%p\n", Add);
printf("%p\n", Add);
return 0;
}
函数指针的地址要存起来,就要放在函数指针变量中
int Add(int x, int y)
{
return x + y;
}
int main()
{
int(*pf)(int, int) = Add;
//pf就是函数指针变量,类型是int(*)(int,int)
}
int Add(int x, int y)
{
return x + y;
}
int main()
{
int(*pf)(int, int) = Add;
/*int ret = (*pf)(3, 5);
int ret = Add(3, 5);*/
int ret = pf(3, 5);
return 0;
}
注意!!!
typedef void(*pf_t2)(int);//pf_t2是类型名
void(*pf)(int);//pf是函数指针变量的名字
数组的每个元素是一个函数指针。
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
//转移表
int(*pf[4])(int, int) = { Add,Sub,Mul,Div };//放到函数指针数组里的函数类型应保持一致
int i = 0;
for (i = 0; i < 4; i++)
{
int ret = pf[i](8, 4);
printf("%d\n", ret);
}
return 0;
}
放到函数指针数组里的函数类型应保持一致,包括参数和返回类型。
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int main()
{
int (*pf)(int, int) = Add;
//函数指针数组
int (*pfArr[4])(int, int) = { Add,Sub };
int (*(*ppfArr)[4])(int, int) = &pfArr;//ppfArr是一个指向函数指针数组的指针
return 0;
}
回调函数是一个通过函数指针调用的函数。如果把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
回调函数不是由该函数的实现方直接调用,而是在特定事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
使用回调函数实现计算器:
//解决了普通语句的冗余
void menu()
{
printf("**********************\n");
printf("***1.Add 2.Sub***\n");
printf("***3.Mul 4.Div***\n");
printf("***0.exit ***\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int Calc(int(*pf)(int, int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("请输入两个操作数:>\n");
scanf("%d %d", &x, &y);
ret = pf(x, y);
printf("%d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请输入选项:>\n");
scanf("%d", &input);
switch (input)
{
case 1:
Calc(Add);
break;
case 2:
Calc(Sub);
break;
case 3:
Calc(Mul);
break;
case 4:
Calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("输入错误\n");
break;
}
} while (input);
return 0;
}
冒泡排序:
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz-1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
print_arr(arr, sz);
return 0;
}
冒泡排序的缺点是什么呢?
它只能排序整型家族类型,而对于结构体等一些其他类型有一定的限制,所以我们引出qsort快速排序。
qsort排序
qsort可以直接使用。
qsort可以排任意类型的数据。
排什么类型的数据,要排序的数据就直接提供比较方法。
void qsort(void* base,//指向待排序数组的第一个元素
size_t num, //待排序的元素个数
size_t width, //每个元素的大小,单位是字节
int(__cdecl* compare)(const void* elem1, const void* elem2));
//指向一个函数,这个函数可以比较两个元素的大小

在进行举例之前,我们还需要知道下面的知识:
因为qsort可以排任意类型的数据,所以在传参的方面就要注意。
我们在普通的地址接收时,不能出现以下不兼容的情况。
这是错误的:
int main()
{
int a = 0;
char* p = &a;//error
return 0;
}
在这里我们可以使用void * 无具体类型的指针,它可以接收任何类型的地址。但是需要注意:
1.void 的指针不能解引用操作符
2.如果是void p,也不能进行p++
3.使用时,我们可以将它进行强制类型转换为其他类型的指针再进行解引用使用。
int main()
{
int a = 10;
void* p = &a;
*(int*)p;
}
对于qsort的各参数类型,我们都不陌生,我们为什么要引出上面使用void*进行传参呢?
对于我们程序员来说,我们清楚的知道接下来我们要排序的数据类型是什么,但是在进行传参的过程中,很容易出现参数类型不兼容的情况,所以我们使用void*来接收各个类型的参数,之后按照什么类型排序就将它强制类型转换为什么形式,这样就会很清晰。
测试qsort排序函数排序整数
#include <stdlib.h>
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int cmp_int(const void* p1, const void* p2)
{
//升序
return *(int*)p1 - *(int*)p2;
//降序
//return *(int*)p2 - *(int*)p1;
}
test()
{
int arr[10] = { 2,1,3,5,6,4,8,7,9,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
//提供一个比较函数
qsort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
test();
return 0;
}
测试qsort排序函数排序结构体数据
#include <stdlib.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
};
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
}
int cmp_stu_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
test()
{
struct Stu s[] = { {"zhangsan",30},{"lisi",40},{"wangwu",50} };
int sz = sizeof(s) / sizeof(s[0]);
//测试按照年龄来排序
qsort(s, sz, sizeof(s[0]), cmp_stu_by_age);
//测试按照姓名来排序
qsort(s, sz, sizeof(s[0]), cmp_stu_by_name);
}
int main()
{
test();
return 0;
}
利用冒泡排序的思想来模拟实现qsort功能的冒泡排序函数bubble_sort()。
1.实现整型排序
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
void Swap(char* buf1, char* buf2, size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void* base, size_t num, size_t width, int(*cmp)(const void* p1, const void* p2))
{
//确定趟数
size_t i = 0;
int flag=1;//假设有序
for (i = 0; i < num - 1; i++)
{
//一趟冒泡排序的过程
size_t j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//两个相邻元素的比较
//arr[j] arr[j+1]
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width)>0)
//降序<0
{
//交换
flag=0;
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
if (flag == 1)
{
break;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10] = { 2,1,3,6,4,5,7,8,9,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
return 0;
}
实现结构体排序:
#include <string.h>
struct Stu
{
char name[20];
int age;
};
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
}
int cmp_stu_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
void Swap(char* buf1, char* buf2, size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void print_s(struct Stu s[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", s[i].name,s[i].age);
}
}
void bubble_sort(void* base, size_t num, size_t width, int(*cmp)(const void* p1, const void* p2))
{
//确定趟数
size_t i = 0;
int flag = 1;//假设有序
for (i = 0; i < num - 1; i++)
{
//一趟冒泡排序的过程
size_t j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//两个相邻元素的比较
//arr[j] arr[j+1]
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width)>0)
{
//交换
flag = 0;
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
if (flag == 1)
{
break;
}
}
}
}
int main()
{
struct Stu s[] = { {"zhangsan",30},{"lisi",40},{"wangwu",50} };
int sz = sizeof(s) / sizeof(s[0]);
bubble_sort(s, sz, sizeof(s[0]), cmp_stu_by_name);
print_s(s, sz);
return 0;
}
感谢友友们阅读,欢迎批评指正!
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
>>a=5=>5>>b=a=>5>>b=4=>4>>a=>5如何将“b”设置为实际的“a”,以便在示例中,变量a也将变为4。谢谢。 最佳答案 classRefdefinitializeval@val=valendattr_accessor:valdefto_s@val.to_sendenda=Ref.new(4)b=aputsa#=>4putsb#=>4a.val=5putsa#=>5putsb#=>5当您执行b=a时,b指向与a相同的对象(它们具有相同的object_id).当你执行a=some_other_thing时,a将指向
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改
我使用Ruby编程已经有一段时间了,现在只使用Ruby的标准MRI实现,但我一直对我经常听到的其他实现感到好奇。前几天我在读有关Rubinius的文章,这是一个用Ruby编写的Ruby解释器。我试着在不同的地方查找它,但我很难弄清楚这样的东西到底是如何工作的。我在编译器或语言编写方面从来没有太多经验,但我真的很想弄明白。一门语言究竟如何才能被自己解释?编译中是否有一个我不明白这有意义的基本步骤?有人可以像我是个白痴一样向我解释这个吗(因为无论如何这都不会太离谱) 最佳答案 它比你想象的要简单。Rubinius并非100%用Ruby编
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su