druid官方文档:
https://github.com/alibaba/druid
https://github.com/alibaba/druid/wiki
druid maven仓库
https://mvnrepository.com/artifact/com.alibaba/druid
参考文章:https://www.cnblogs.com/dxiaodang/p/14571590.html
主要原因还是要不要手动写配置类,spring boot 的使用 auto帮我们封装好了属性值
描述如下:
所以建议改用druid-spring-boot-starter依赖。
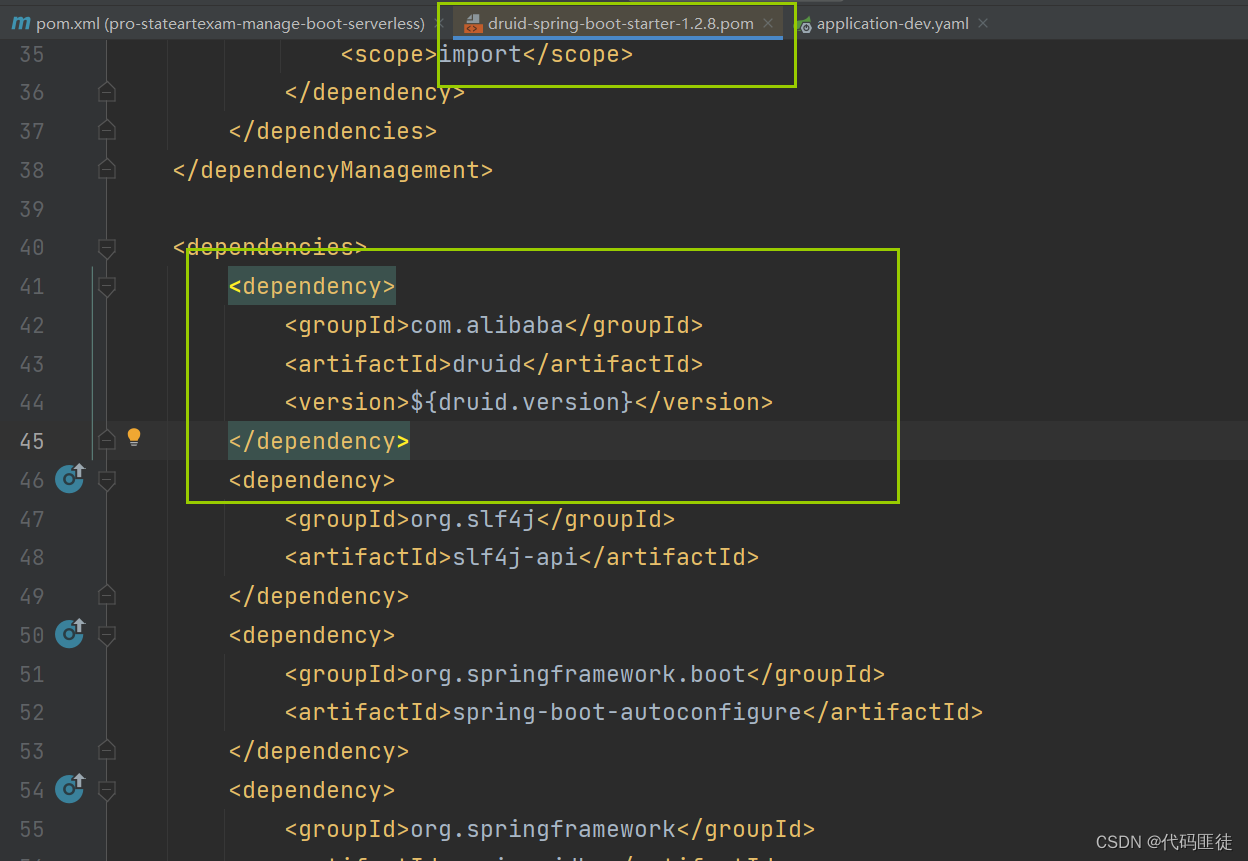
pom文件
<!--Druid-->
<!--可以不配这个因为druid-spring-boot-starter里面已经有了,随便带着一下这个依赖,代码可读性高一点,反正对其他啥也没影响-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!-- Druid Spring Boot 组件-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>
并且在application.yml文件中配置如下内容:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/test01
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
# Druid数据源配置
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1
#申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
testWhileIdle: true
#配置从连接池获取连接时,是否检查连接有效性,true每次都检查;false不检查。做了这个配置会降低性能。
testOnBorrow: false
#配置向连接池归还连接时,是否检查连接有效性,true每次都检查;false不检查。做了这个配置会降低性能。
testOnReturn: false
#打开PsCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
#合并多个DruidDatasource的监控数据
useGlobalDataSourceStat: true
#通过connectProperties属性来打开mergesql功能罗慢sQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500;
如此就不需要单独对DruidDatasource写个配置类了。
也可参考这篇文章的yaml文件配置:https://blog.csdn.net/yzh_1346983557/article/details/117673280
1、问题发现:
定位接口无响应问题时,发现是由于数据库挂了导致的;但是不应该呀,数据库连接池设置了最大等待超时时间还是有返回的,然后深入解读代码,发现是配置参数有问题

2、分析
问题1:为什么datasource下边就没有这些参数,这样子配置居然没有报错,只是提示? —> 原来spring-boot是可以配置不存在的key值,只要保证格式正确,在加载的时候不会解析错误的key
问题2:那应该怎么配置? —> 查看源码分析
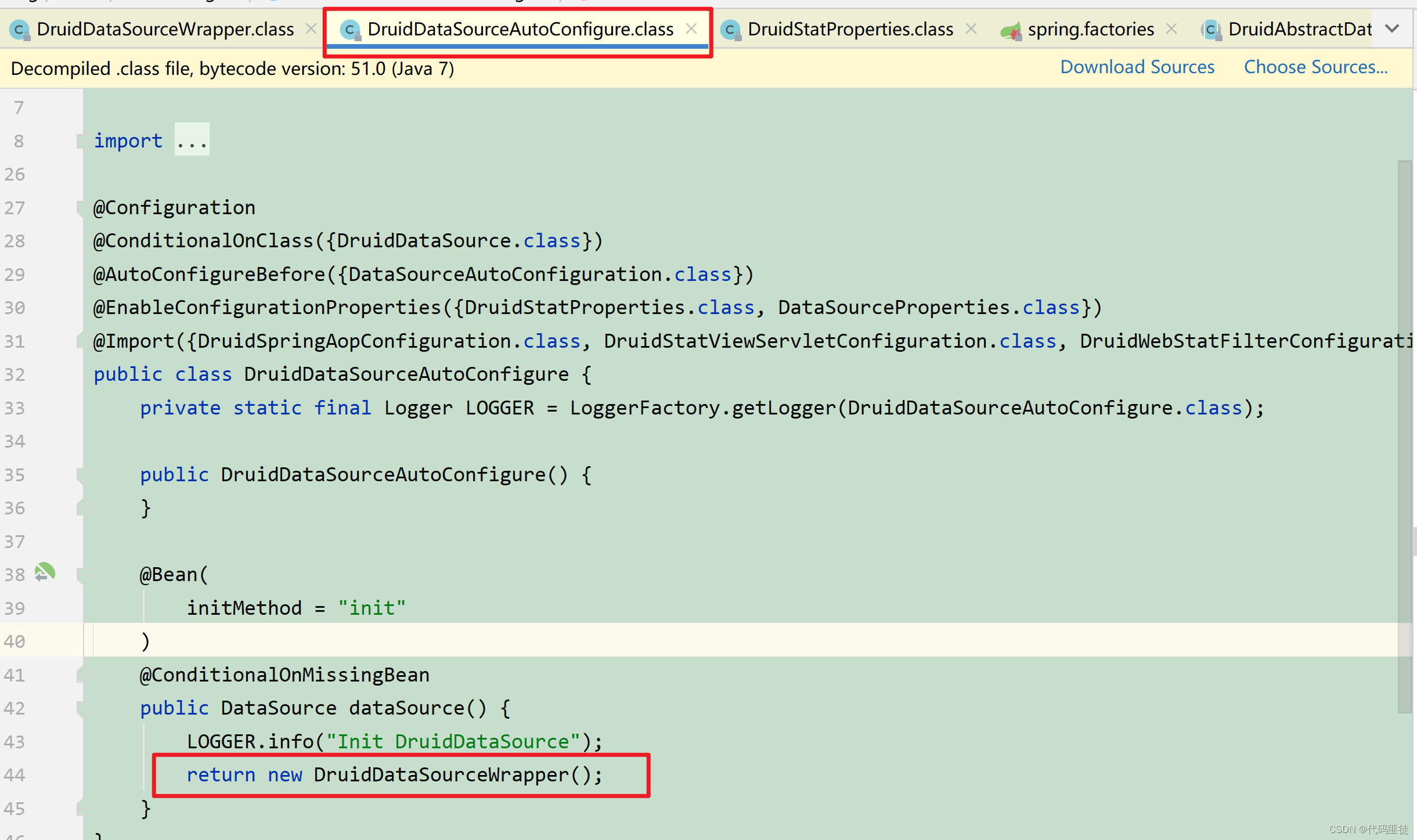
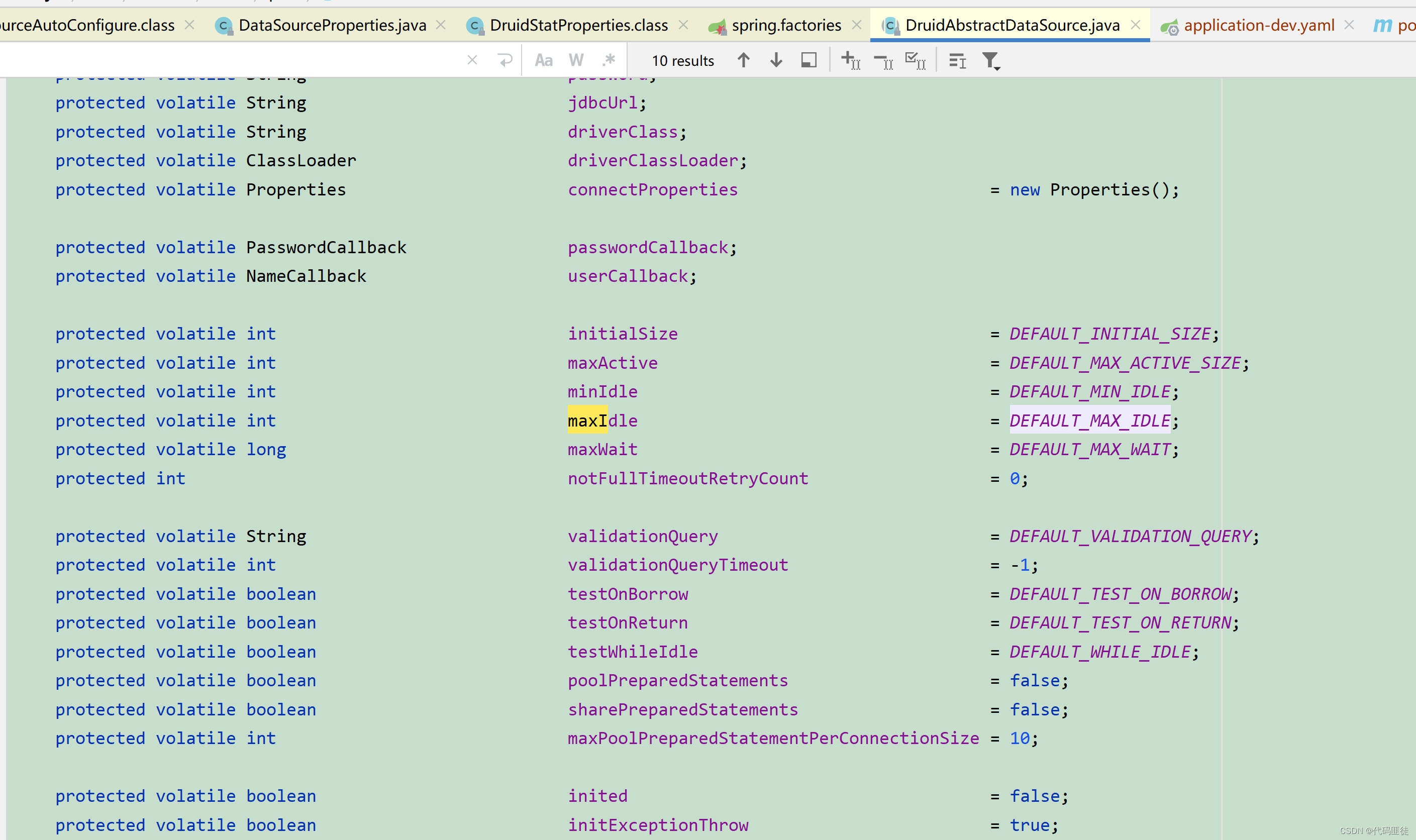
(1)第一步:
先找到druid配置类 —> spring-boot-starter的自动配置类基本都是xxxxxAutoConfigure 或xxxxxAutoConfiguration
发现druid配置类中注入了一个DruidDataSourceWrapper实例,且用@EnableConfigurationProperties({DruidStatProperties.class, DataSourceProperties.class})开启@ConfigurationProperties注解配置
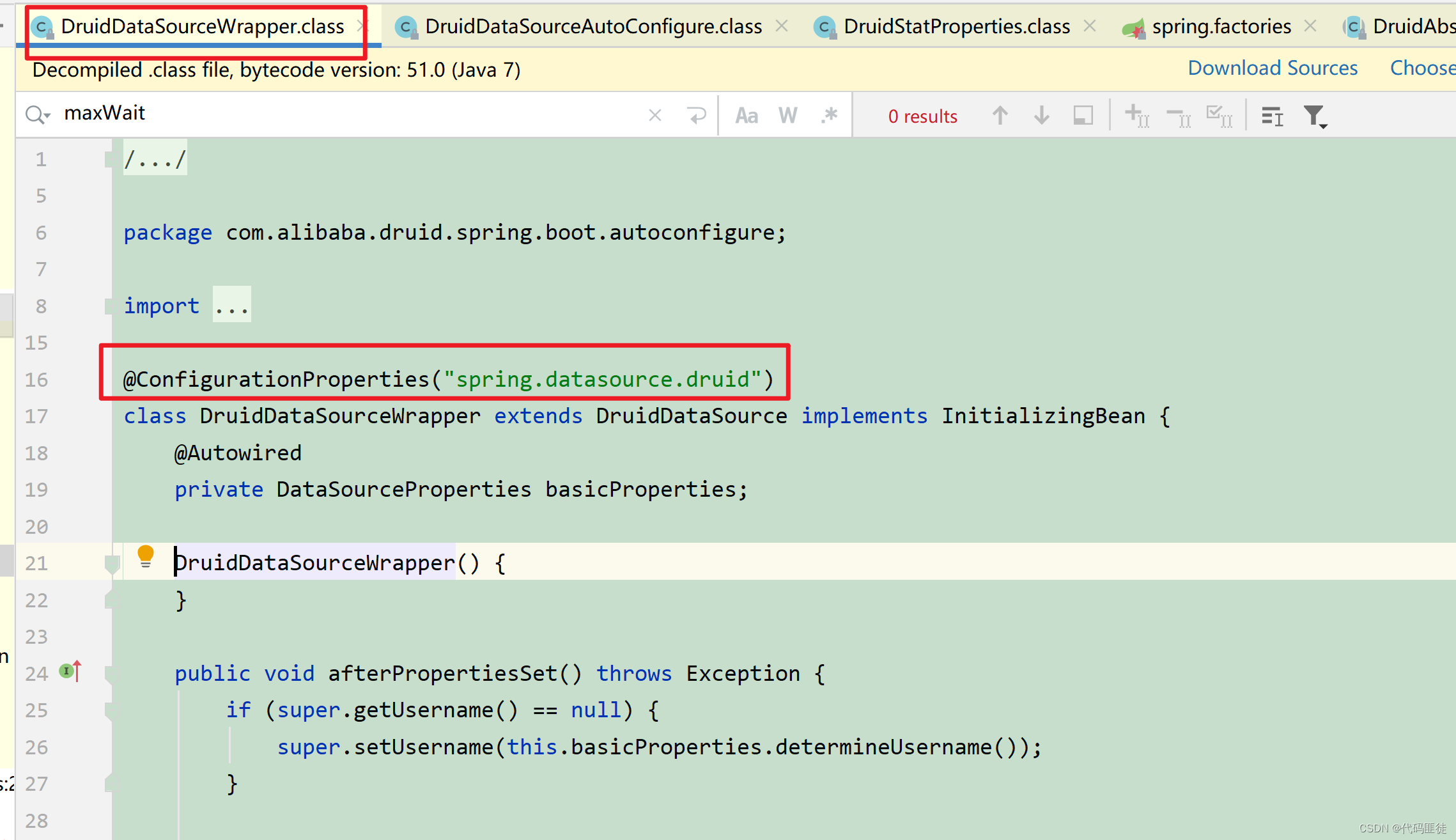
(2)第二步:
找到对应的bean实例DruidDataSourceWrapper,发现使用注解@ConfigurationProperties配置了前缀:spring.datasource.druid,把该前缀开头的主配置文件中配置属性设置到对于的Bean属性上
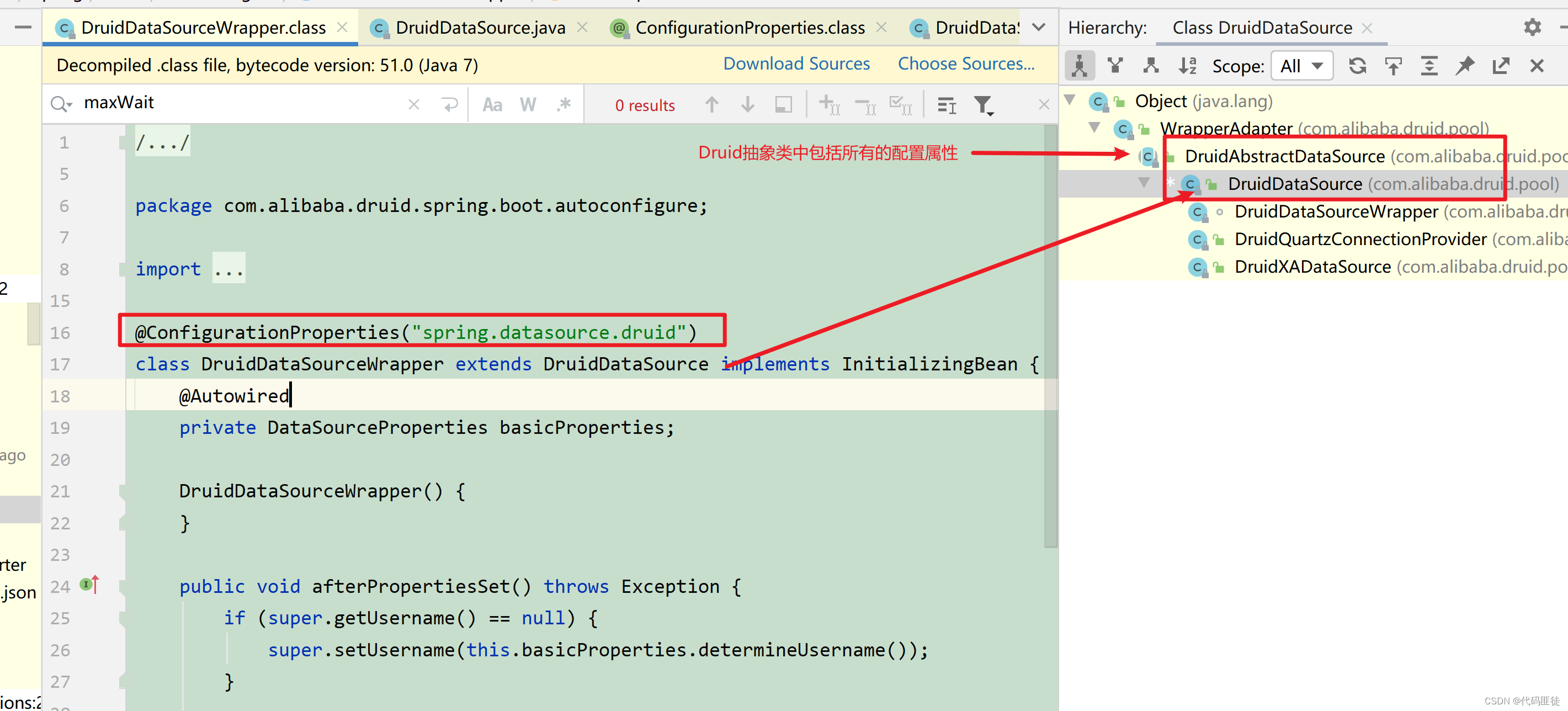
(3)第三步:
Bean本身没有属性,都是继承抽象类父类的属性,基本都设置了默认值。
3、配置文件
参考如下配置
spring:
#数据源配置
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.100.99:3306/energy_storage_test?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&rewriteBatchedStatements=true
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
initial-size: 5 # 初始化大小
min-idle: 5 # 最小空闲连接个数
max-active: 20 # 最大连接个数
max-wait: 60000 # 配置获取连接等待超时的时间
time-between-eviction-runs-millis: 60000 # 配置间隔多久才进行一次监测,监测需要关闭的空闲连接,单位时毫秒
min-evictable-idle-time-millis: 60000 # 配置一个连接在池中最小生存的时间
validation-query: select 'x' # 用来监测连接是否有效的sql,要求是一个查询语句
test-while-idle: true # 建议配置为true,不影响性能,并且保证安全性。如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-on-borrow: false # 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
test-on-return: false # 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
pool-prepared-statements: true # 打开PSCache,并且指定每个连接上PSCache的大小
max-open-prepared-statements: 20
filter:
commons-log:
connection-logger-name: stat,wall,log4j # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙,此处是filter修改的地方
3、总结
①springboot项目整合druid,建议使用druid-spring-boot-strater,但是不代表druid一定不可以使用,有兴趣的可以自己试试
②配置yaml文件时,一定要使用druid下边的参数,要不然不起作用
springboot2.0默认集成了hikari连接池,号称史上性能最好,速度最快的连接池,自动装配原理都一样,大家可以试试,下面附上常用的一些参数配置
spring:
datasource:
username: dangbo
password: dangbo
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306?auth_shiro
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 5 # 最小空闲数,默认值为10
maximum-pool-size: 15 # 最大连接数,默认值为10
auto-commit: true # 控制从池返回的连接的默认自动提交行为
idle-timeout: 30000 # 控制允许连接在池中闲置的最长时间,默认值10min
pool-name: DatebookHikariCP # 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置。 默认:自动生成
max-lifetime: 1800000 # 池中连接的最大生存期,默认值30min
connection-timeout: 30000 # 控制客户端将等待来自池的连接的最大毫秒数,默认值为30s
connection-test-query: SELECT 'x'
hikari配置参考于:https://blog.csdn.net/Maskkiss/article/details/82115149
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
我正在尝试获得良好的Ruby编码风格。为防止意外调用具有相同名称的局部变量,我总是在适当的地方使用self.。但是现在我偶然发现了这个:classMyClass上面的代码导致错误privatemethodsanitize_namecalled但是当删除self.并仅使用sanitize_name时,它会起作用。这是为什么? 最佳答案 发生这种情况是因为无法使用显式接收器调用私有(private)方法,并且说self.sanitize_name是显式指定应该接收sanitize_name的对象(self),而不是依赖于隐式接收器(也是
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A