 短短数年后,这些当年多多少少都曾被诟病“商业公司破坏开源生态”的收购案,如今恰恰证明商业巨头介入对于开源生态的持续繁荣是何等重要。种种迹象表明,在时代变革的浪潮下,迅速发展的公有云厂商不仅不是开源的“拦路虎”,反而还能促进开源软件生态快速成长,正在成为开源的引领者。仅2022年我们看到,Github
新增了2050万开发人员,总数达到 9400万,同比大增27%。Flink的Github
Star数和贡献者人数也在以同比超30%的速度增长,如今Star数已超2万个,拥有上千名贡献者
(contributors),有超过20万开发者关注、超过100家国内外知名公司参与代码贡献,月下载量峰值突破1400万次,已连续两年蝉联Apache基金会财年报告最活跃项目。这些事实无疑再次印证了开源软件领域那些“金玉良言”——开源与商业并不矛盾:开源项目背后的商业公司,往往是推动开源项目生态繁荣的关键;开源项目后面的商业公司若不在,开源项目本身必然走向衰落或灭亡。单以Flink这一开源项目从“技术领先”到“生态领先”的蜕变之旅来看,这种“铁律”到云时代不仅没有失效,反而得到了发扬光大。阿里的深度介入,为这个诞生于欧洲的项目注入了来自中国的雄厚的技术、人才和应用生态,推动Flink全球化社区快速演进,支撑各行各业规模商用,一路狂飚成为全球大数据实时计算业界的事实标准!生于欧洲爆发于中国,中国开发者推动Flink狂飙Flink最早诞生于德国柏林工业大学大数据研究项目Stratosphere。2014年,Stratosphere项目组核心成员孵化出Flink,将Flink定位为主攻流处理计算
(Streaming) 的大数据引擎;同年,将Flink捐赠给Apache软件基金会。2015年,Flink成为Apache顶级项目。
短短数年后,这些当年多多少少都曾被诟病“商业公司破坏开源生态”的收购案,如今恰恰证明商业巨头介入对于开源生态的持续繁荣是何等重要。种种迹象表明,在时代变革的浪潮下,迅速发展的公有云厂商不仅不是开源的“拦路虎”,反而还能促进开源软件生态快速成长,正在成为开源的引领者。仅2022年我们看到,Github
新增了2050万开发人员,总数达到 9400万,同比大增27%。Flink的Github
Star数和贡献者人数也在以同比超30%的速度增长,如今Star数已超2万个,拥有上千名贡献者
(contributors),有超过20万开发者关注、超过100家国内外知名公司参与代码贡献,月下载量峰值突破1400万次,已连续两年蝉联Apache基金会财年报告最活跃项目。这些事实无疑再次印证了开源软件领域那些“金玉良言”——开源与商业并不矛盾:开源项目背后的商业公司,往往是推动开源项目生态繁荣的关键;开源项目后面的商业公司若不在,开源项目本身必然走向衰落或灭亡。单以Flink这一开源项目从“技术领先”到“生态领先”的蜕变之旅来看,这种“铁律”到云时代不仅没有失效,反而得到了发扬光大。阿里的深度介入,为这个诞生于欧洲的项目注入了来自中国的雄厚的技术、人才和应用生态,推动Flink全球化社区快速演进,支撑各行各业规模商用,一路狂飚成为全球大数据实时计算业界的事实标准!生于欧洲爆发于中国,中国开发者推动Flink狂飙Flink最早诞生于德国柏林工业大学大数据研究项目Stratosphere。2014年,Stratosphere项目组核心成员孵化出Flink,将Flink定位为主攻流处理计算
(Streaming) 的大数据引擎;同年,将Flink捐赠给Apache软件基金会。2015年,Flink成为Apache顶级项目。 在Flink横空出世之前,上一代流式计算引擎的名字叫Storm。Flink取而代之的关键在于它是一款有状态的流计算,而Storm没有。换句话说,除了低延迟、高吞吐的流计算能力,Flink还能够将流计算与状态存储进行有机融合,从而在框架层支持整个流计算状态的精准数据一致性。正因为如此,Flink很快击败Storm,受到开发者青睐,迅速成为Apache顶级项目。不过,Flink真正的爆发始于2019年。彼时,Flink技术路线最早的拥趸之一——阿里收购了Flink背后的公司,成为Flink社区最大的推动者;同年,阿里将内部自研并演进多时的Flink分支Blink开源,一举为Flink贡献超百万行代码。特别是Stream
SQL的注入,使得Flink社区也有了一套非常易用的Stream SQL,开发者们无需再写高难度的Java代码,大幅降低了开发门槛。自那以后阿里在核心技术、人才培养、社区运营以及应用落地等维度持续发力,中国开发者大量涌入,推动Flink全球化生态实现爆发式增长。数据显示,Flink迄今已有超过20万开发者关注、超过100家国内外知名公司参与代码贡献,月度下载量峰值已突破1400万次,形成了庞大的用户和开发者生态。其中2022年阿里、腾讯、字节跳动等中国企业贡献了超过一半的代码;Flink社区在Github上产生的Pull
Request有45%来自于中国开发者,表明中国开发者已经成为Flink全球化社区的中坚力量。
在Flink横空出世之前,上一代流式计算引擎的名字叫Storm。Flink取而代之的关键在于它是一款有状态的流计算,而Storm没有。换句话说,除了低延迟、高吞吐的流计算能力,Flink还能够将流计算与状态存储进行有机融合,从而在框架层支持整个流计算状态的精准数据一致性。正因为如此,Flink很快击败Storm,受到开发者青睐,迅速成为Apache顶级项目。不过,Flink真正的爆发始于2019年。彼时,Flink技术路线最早的拥趸之一——阿里收购了Flink背后的公司,成为Flink社区最大的推动者;同年,阿里将内部自研并演进多时的Flink分支Blink开源,一举为Flink贡献超百万行代码。特别是Stream
SQL的注入,使得Flink社区也有了一套非常易用的Stream SQL,开发者们无需再写高难度的Java代码,大幅降低了开发门槛。自那以后阿里在核心技术、人才培养、社区运营以及应用落地等维度持续发力,中国开发者大量涌入,推动Flink全球化生态实现爆发式增长。数据显示,Flink迄今已有超过20万开发者关注、超过100家国内外知名公司参与代码贡献,月度下载量峰值已突破1400万次,形成了庞大的用户和开发者生态。其中2022年阿里、腾讯、字节跳动等中国企业贡献了超过一半的代码;Flink社区在Github上产生的Pull
Request有45%来自于中国开发者,表明中国开发者已经成为Flink全球化社区的中坚力量。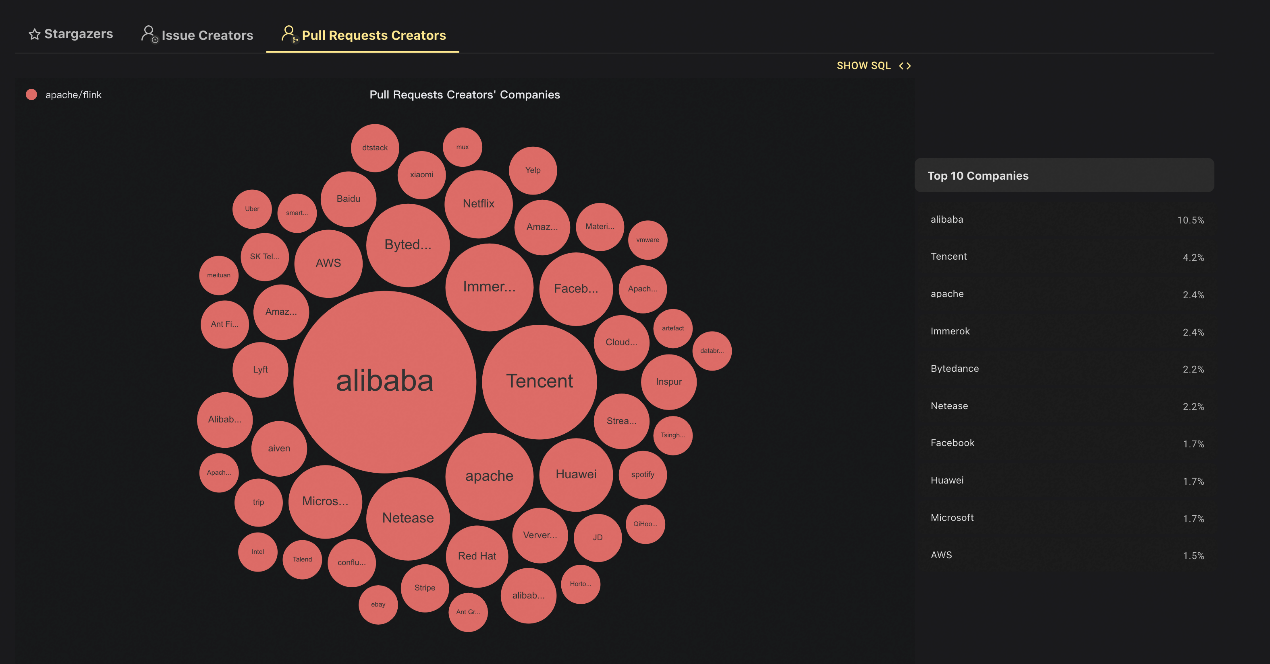 在中国开发者力量的大力驱动下,Flink从2020年开始已成为全球范围内大数据实时计算业界的事实标准。如今只要想到实时流计算,基本上都会选择Apache
Flink。其应用也从早期的互联网行业逐步扩展到政务、金融、制造、零售、交通出行、传媒、游戏、科技等更多行业。短短数年间,Flink完成了一个开源项目从技术领先到生态领先的蜕变之旅!从使用者到主导者,阿里引领Flink社区快速演进众所周知,开源社区是开源生态发展壮大的根基。中国不缺开发者,但长期以来在开源软件领域的形象是世界开源大国,而不是开源强国,其中最显著的标志是缺乏拥有主导权的开源社区,无法定义和掌控核心项目的走向。近些年在政策及市场需求的驱动下,领先企业纷纷迈出了构建具有主导权的开源社区的步伐。阿里之于Flink社区,正是其中的典型。熟悉阿里业务的都知道,大数据实时计算可谓是阿里最显著的标签之一。比如每年双11我们看到天猫交易大屏幕上显示的那些跳动的实时成交数字,就是实时流计算的结果。那些瞬息变化的数字,需要汇总各个地方的海量报表、数据库等数据,在毫秒级别的时间延迟内进行计算,并将计算结果汇总为单一的视图呈现。此外诸如实时广告、推荐、欺诈检测、服务质量监控等等,背后都有实时流计算的身影。所以早在2015年阿里就开始调研Flink,并于2016年在双11搜索推荐场景中首次使用,随后利用Flink实现了搜索推荐和在线学习全链路实时化。2017年,Flink成为阿里集团内实时计算的标准解决方案。2018年,阿里将Flink上云,开启阿里云上基于Flink的商业化产品供给,以更好地为中小企业服务。同年,阿里将Flink的标杆大会Flink
Forward引入中国并连续举办,让广大中国开发者与这个大数据领域的顶级技术大会零距离接触,加速了Flink社区在中国的渗透。然后是关键的2019年,阿里收购Flink背后的公司,并开源自己在Flink技术路线上潜心打造的Blink回馈社区,以超百万行代码的贡献在Runtime、SQL、PyFlink、ML等多个维度大幅提升了Flink的表现,随后开始主导推进Flink的版本发布,携手中国开发者力量开启全球化社区建设之旅。同年阿里云推出全球统一的Flink企业版平台Ververica
Platform,持续在开源产品化方面发力。
在中国开发者力量的大力驱动下,Flink从2020年开始已成为全球范围内大数据实时计算业界的事实标准。如今只要想到实时流计算,基本上都会选择Apache
Flink。其应用也从早期的互联网行业逐步扩展到政务、金融、制造、零售、交通出行、传媒、游戏、科技等更多行业。短短数年间,Flink完成了一个开源项目从技术领先到生态领先的蜕变之旅!从使用者到主导者,阿里引领Flink社区快速演进众所周知,开源社区是开源生态发展壮大的根基。中国不缺开发者,但长期以来在开源软件领域的形象是世界开源大国,而不是开源强国,其中最显著的标志是缺乏拥有主导权的开源社区,无法定义和掌控核心项目的走向。近些年在政策及市场需求的驱动下,领先企业纷纷迈出了构建具有主导权的开源社区的步伐。阿里之于Flink社区,正是其中的典型。熟悉阿里业务的都知道,大数据实时计算可谓是阿里最显著的标签之一。比如每年双11我们看到天猫交易大屏幕上显示的那些跳动的实时成交数字,就是实时流计算的结果。那些瞬息变化的数字,需要汇总各个地方的海量报表、数据库等数据,在毫秒级别的时间延迟内进行计算,并将计算结果汇总为单一的视图呈现。此外诸如实时广告、推荐、欺诈检测、服务质量监控等等,背后都有实时流计算的身影。所以早在2015年阿里就开始调研Flink,并于2016年在双11搜索推荐场景中首次使用,随后利用Flink实现了搜索推荐和在线学习全链路实时化。2017年,Flink成为阿里集团内实时计算的标准解决方案。2018年,阿里将Flink上云,开启阿里云上基于Flink的商业化产品供给,以更好地为中小企业服务。同年,阿里将Flink的标杆大会Flink
Forward引入中国并连续举办,让广大中国开发者与这个大数据领域的顶级技术大会零距离接触,加速了Flink社区在中国的渗透。然后是关键的2019年,阿里收购Flink背后的公司,并开源自己在Flink技术路线上潜心打造的Blink回馈社区,以超百万行代码的贡献在Runtime、SQL、PyFlink、ML等多个维度大幅提升了Flink的表现,随后开始主导推进Flink的版本发布,携手中国开发者力量开启全球化社区建设之旅。同年阿里云推出全球统一的Flink企业版平台Ververica
Platform,持续在开源产品化方面发力。 2020年,阿里将“压箱底”的Blink内核也合并到Flink内核中,同时发起Apache
Flink中文社区,全面支持开源社区的全球化发展。当年双11,Flink包揽了阿里集团内部所有的全链路实时化解决方案,规模达到百万级CPU
Core,实时数据处理峰值创下40亿条记录/秒的新纪录。自那时起,随着阿里云的产品和内部服务都基于开源的Flink内核来实现,AWS、Cloudera等云计算和大数据厂商均将Flink内置为标准的云产品,Flink成为事实上的全球实时计算标准!数据显示,截至目前阿里与Ververica共同主导了211个FLIP,贡献了Flink
70%以上的核心改进;累计培养了近70位Flink核心贡献者
(含项目管理委员会PMC成员和活跃贡献者committer),占比超70%;连续举办了4届FFA大会 (Flink Forward
Asia)及各种开发者活动,大力推广Flink生态;通过阿里云上的Flink云产品和Flink企业版平台Ververica
Platform,推动了Flink在各行各业的规模落地……可以说在方方面面都发挥了关键推手的作用。
2020年,阿里将“压箱底”的Blink内核也合并到Flink内核中,同时发起Apache
Flink中文社区,全面支持开源社区的全球化发展。当年双11,Flink包揽了阿里集团内部所有的全链路实时化解决方案,规模达到百万级CPU
Core,实时数据处理峰值创下40亿条记录/秒的新纪录。自那时起,随着阿里云的产品和内部服务都基于开源的Flink内核来实现,AWS、Cloudera等云计算和大数据厂商均将Flink内置为标准的云产品,Flink成为事实上的全球实时计算标准!数据显示,截至目前阿里与Ververica共同主导了211个FLIP,贡献了Flink
70%以上的核心改进;累计培养了近70位Flink核心贡献者
(含项目管理委员会PMC成员和活跃贡献者committer),占比超70%;连续举办了4届FFA大会 (Flink Forward
Asia)及各种开发者活动,大力推广Flink生态;通过阿里云上的Flink云产品和Flink企业版平台Ververica
Platform,推动了Flink在各行各业的规模落地……可以说在方方面面都发挥了关键推手的作用。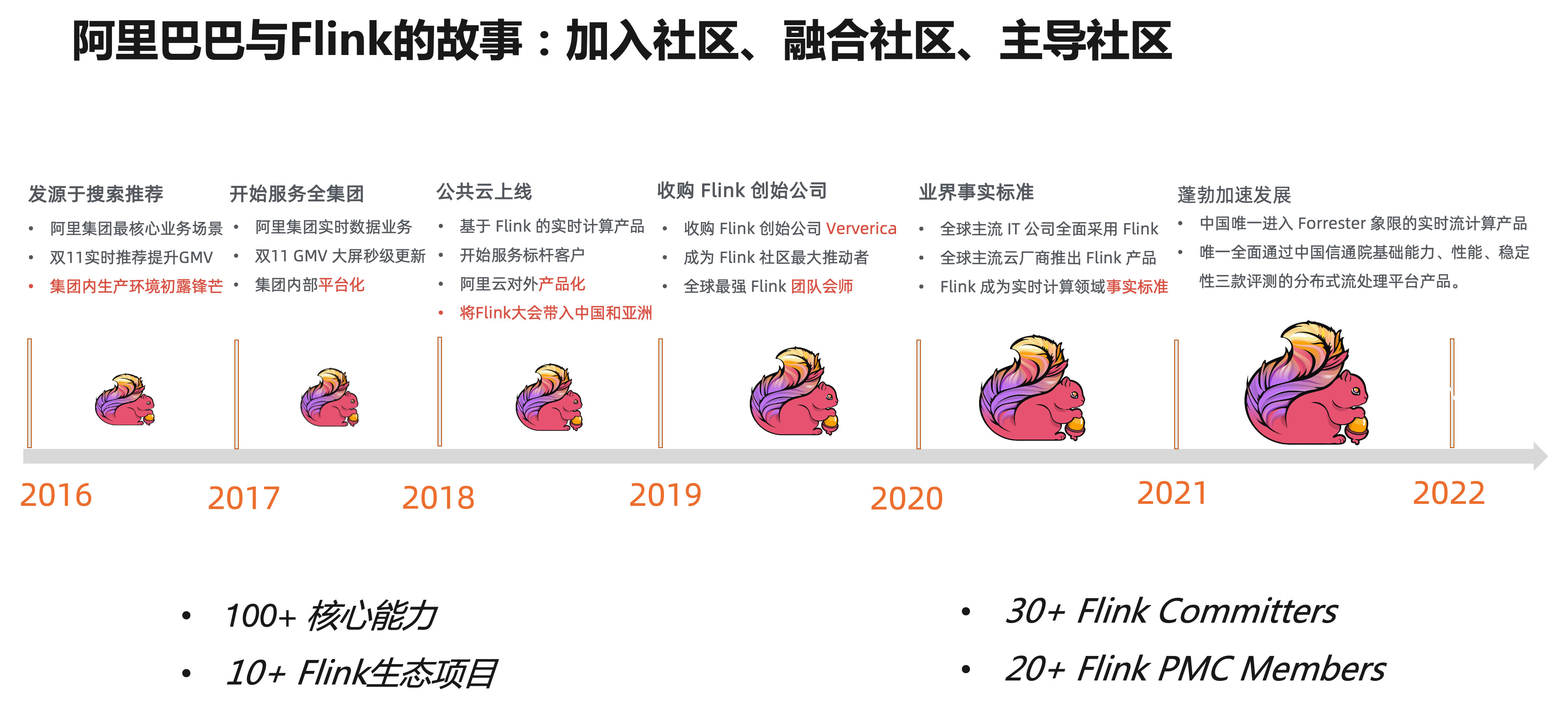 至此,阿里从使用开源、贡献开源到主导开源,蹚出了一条构建具有主导权的开源社区的成功路径,向世界证明了中国的技术、人才和应用生态不仅可以和世界开源社区接轨,而且还能引领全球化开源社区的快速演进、蓬勃发展。向“流式数仓”演进,加速“流批一体”时代到来当然必须意识到,开源世界的技术更迭是无比迅捷的。从Hadoop、Hive到Storm再到Spark、Flink,从批处理到流计算再到“流批一体”,技术架构与市场需求总是在做双向选择,稍不留神就有可能被“后浪”拍死在沙滩上。总体来看,如今无论是批处理还是流计算出生的技术架构,都在将流批一体作为努力方向,力争以一套引擎同时满足实时和离线计算需求。有鉴于此,阿里在2019年将Blink代码贡献给Flink后,便着手从1.9版本开始主导推动Flink流批一体融合,包括在API层面实现SQL与DataStream的流批统一,用户只需写一份代码即可运行在流模式或是批模式;在架构层面实现一个作业同时处理有限数据集和无限数据集,并且同时对接流式存储和批式存储,一套代码处理两套数据源;在运行层面做到一套调度框架同时适用于流和批的作业……在阿里巴巴开源委员会副主席、阿里云开源大数据平台负责人、Flink中文社区发起人王峰看来,下一阶段Flink社区新的机会点是继续提升一体化的体验,解决存储层割裂的问题,来实现一套实时数据链路。通过Flink流批一体的SQL和流批一体的存储,构建一套真正一体化体验的流式数仓
(Streaming Warehouse)。
至此,阿里从使用开源、贡献开源到主导开源,蹚出了一条构建具有主导权的开源社区的成功路径,向世界证明了中国的技术、人才和应用生态不仅可以和世界开源社区接轨,而且还能引领全球化开源社区的快速演进、蓬勃发展。向“流式数仓”演进,加速“流批一体”时代到来当然必须意识到,开源世界的技术更迭是无比迅捷的。从Hadoop、Hive到Storm再到Spark、Flink,从批处理到流计算再到“流批一体”,技术架构与市场需求总是在做双向选择,稍不留神就有可能被“后浪”拍死在沙滩上。总体来看,如今无论是批处理还是流计算出生的技术架构,都在将流批一体作为努力方向,力争以一套引擎同时满足实时和离线计算需求。有鉴于此,阿里在2019年将Blink代码贡献给Flink后,便着手从1.9版本开始主导推动Flink流批一体融合,包括在API层面实现SQL与DataStream的流批统一,用户只需写一份代码即可运行在流模式或是批模式;在架构层面实现一个作业同时处理有限数据集和无限数据集,并且同时对接流式存储和批式存储,一套代码处理两套数据源;在运行层面做到一套调度框架同时适用于流和批的作业……在阿里巴巴开源委员会副主席、阿里云开源大数据平台负责人、Flink中文社区发起人王峰看来,下一阶段Flink社区新的机会点是继续提升一体化的体验,解决存储层割裂的问题,来实现一套实时数据链路。通过Flink流批一体的SQL和流批一体的存储,构建一套真正一体化体验的流式数仓
(Streaming Warehouse)。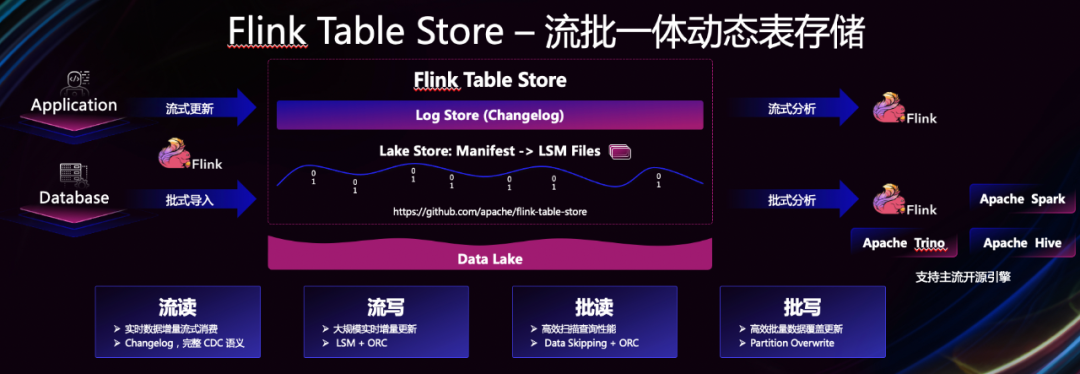 而实现流式数仓的关键在于打造生产可用的流批一体存储,同时支持高效的流读、流写、批读、批写,让数仓的数据流动起来。为此阿里在2022年发起Flink
Table Store
(现已更名为Paimon)项目,旨在实现流批一体的存储能力,推动Flink从流式计算走向流式数仓,使得用户在整个全链路的开发过程中都可以拥有全增量一体化的开发体验,以及统一的数据存储和管理体系,实现“终极”的流批一体。毋庸讳言,以流式数仓为代表的流批一体时代一旦到来,将不仅意味着业务开发效率和计算性能的进步,也会让计算集群的资源利用率得到进一步提升。毕竟,批和流一套引擎,运行在一套资源底座上,不仅会节省开发和运维成本,同时也会大幅节省计算所耗的资源成本——这在算力昂贵的数智经济时代别提有多重要。阿里引领下的Flink社区以此为演进目标,足见背后的雄心壮志。小结:“中国开发群体走向哪里,哪里就有可能成为制高点。”中国科学院院士王怀民在2022开放原子开源峰会上指出,“中国开发者在世界开源领域所扮演的角色,正在从项目主要参与者演变为一些具有代表性的开源项目的发起者和主导者。”从Flink这个阿里代表性的开源实践案例看,这一论断正在被现实验证,崛起的中国开发者推动了Flink的狂飙,正在全球开源舞台扮演更重要的角色!深究这一切发生的底层逻辑,正如开篇所说,商业巨头主导是推动开源项目生态繁荣的关键。当云与开源在新的计算时代互相吸引,浪潮之巅的云巨头有能力也有责任构建具有主导权的开源社区,将先进的开源技术以更低的门槛推向更广阔的市场。事实也表明,领先的云厂商正在成为开源的引领者,以云+开源构筑数字世界的根基,支撑各行各业开发者拥抱云与开源,加速迈向数智未来。
而实现流式数仓的关键在于打造生产可用的流批一体存储,同时支持高效的流读、流写、批读、批写,让数仓的数据流动起来。为此阿里在2022年发起Flink
Table Store
(现已更名为Paimon)项目,旨在实现流批一体的存储能力,推动Flink从流式计算走向流式数仓,使得用户在整个全链路的开发过程中都可以拥有全增量一体化的开发体验,以及统一的数据存储和管理体系,实现“终极”的流批一体。毋庸讳言,以流式数仓为代表的流批一体时代一旦到来,将不仅意味着业务开发效率和计算性能的进步,也会让计算集群的资源利用率得到进一步提升。毕竟,批和流一套引擎,运行在一套资源底座上,不仅会节省开发和运维成本,同时也会大幅节省计算所耗的资源成本——这在算力昂贵的数智经济时代别提有多重要。阿里引领下的Flink社区以此为演进目标,足见背后的雄心壮志。小结:“中国开发群体走向哪里,哪里就有可能成为制高点。”中国科学院院士王怀民在2022开放原子开源峰会上指出,“中国开发者在世界开源领域所扮演的角色,正在从项目主要参与者演变为一些具有代表性的开源项目的发起者和主导者。”从Flink这个阿里代表性的开源实践案例看,这一论断正在被现实验证,崛起的中国开发者推动了Flink的狂飙,正在全球开源舞台扮演更重要的角色!深究这一切发生的底层逻辑,正如开篇所说,商业巨头主导是推动开源项目生态繁荣的关键。当云与开源在新的计算时代互相吸引,浪潮之巅的云巨头有能力也有责任构建具有主导权的开源社区,将先进的开源技术以更低的门槛推向更广阔的市场。事实也表明,领先的云厂商正在成为开源的引领者,以云+开源构筑数字世界的根基,支撑各行各业开发者拥抱云与开源,加速迈向数智未来。 我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl