摘要:最近笔主带着两位新入职的同事进行了公司新平台的压力测试,工具选择的当然是Loadrunner,小笔发现有很多刚入门Loadrunner的小白都会遇到很多相似的问题,但是这些问题并不能在各大搜索网站上得到完善的解决。因此,小笔选中了51testing这个流量给力认可度高的专业测试平台给各位loadrunner新手提拱一份参考,希望能够帮助到有需要的朋友。

在如今的大数据时代,软件、测试、自动化测试都在扮演者不可或缺的重要角色,我们开发一个平台要求的已经不仅仅是功能要正确,更要考虑的是随着访问量的增加给客户带来的压力体验。
OK,引文部分已经完成,下面我们一起走进Loadrunner的压力测试吧。
跟着小笔一起动手来完成此次的压力测试吧!一个完整的压力测试三部曲:
1.脚本录制->2. 场景设计->3. 结果分析
场景介绍:此处我们选择最具有代表意义的多用户并发登录系统,我们测试150个用户并发登录平台A的时候给系统增加的压力情况。
测试背景: Windows Server 2008+Loadrunner11+IE8
1.录制脚本(Virtual User Generator)
安装好Loadrunner后(安装比较容易,在此暂且省略),打开Virtual User Generator进行脚本录制,录制时相关设置:
Step 1、Catalog选择'Web(HTTP/HTML)',点击[Create] 按钮。
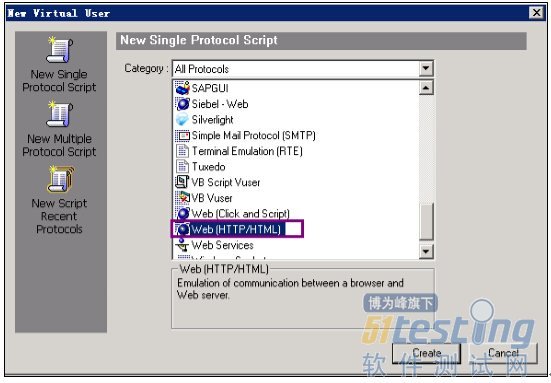
Step 2、[URL Address]的值输入需要测试系统的地址,点击[OK]按钮。
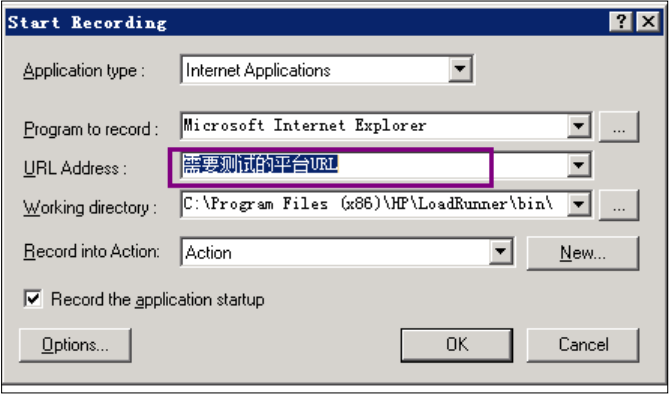
Step3、开始进行登录系统的脚本录制,一般情况下,我们在录制的过程中需要切分action,不同的操作放在相对应的action里,此处因为操作简单,我们暂且不去细分。
Step4、生成脚本

Step5、优化脚本:添加集合点,事务,思考时间。

事务:定义一个action的范围,以便对此action进行某种操作。比如对该action进行计时操作。
语句:lr_start_transaction("login");
集合点:正如字面意思,等待所有的事务集合到一起进行的操作,用来执行负载测试。要实现此操作,可以同步 Vuser 以便恰好在同一时刻执行任务。通过创建集合点,可以配置多个 Vuser 同时执行某个操作。当某个 Vuser 到达该集合点时,将进行等待,直到参与该集合的全部 Vuser 都到达。指定数量的 Vuser 均到达后,释放所有这些 Vuser。
语句:lr_rendezvous("login");
思考时间:思考时间即等待时间,是一种延迟操作,很好理解。
语句:lr_think_time(5);
2.场景设计(Controller)
Step1、打开 controller,添加上面优化好的脚本,设置场景模式。(此处命名为testLogin)设置场景如下:
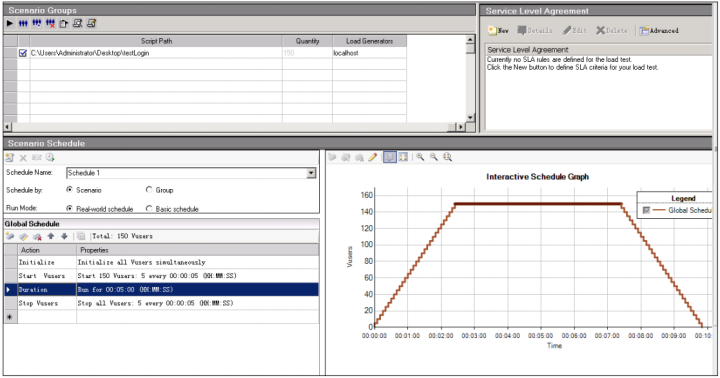
Step2、点击【Start Scenario】运行脚本,结果如下:
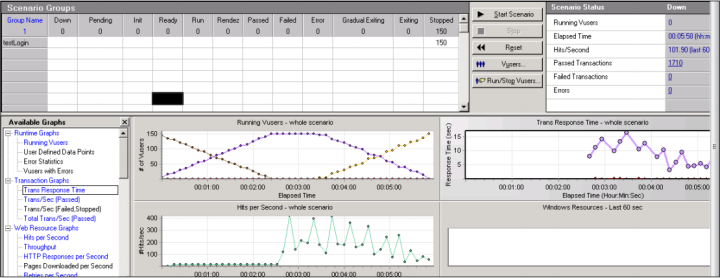
Step 3、点击紫色框中按钮,生成测试结果报告。
2.结果分析(Analysis)
Analysis 可以说是Loadrunner压力测试的重点和难点,所以对于新手而言 analysis不是测试的结束,而是开始。因此,对于各项测试结果我们要做出准确的理解和判断。在本次的实践中,我们做的是一个比较简单的场景,那么针对此场景的各项结果如下:
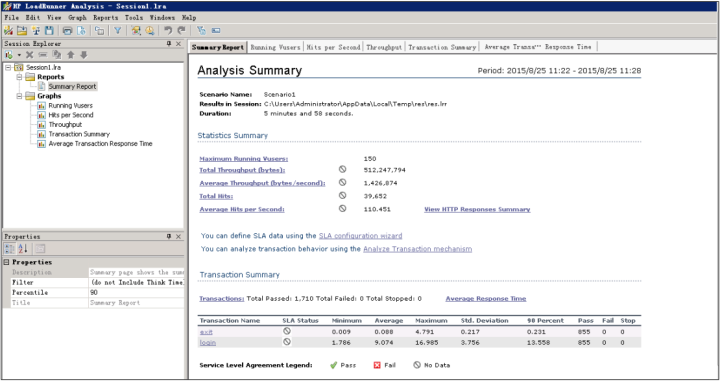
【测试报告分析摘要】,这里显示了实际测试过程中,总体的测试结果。我们可以选择更过的图来分析系统的负载情况。
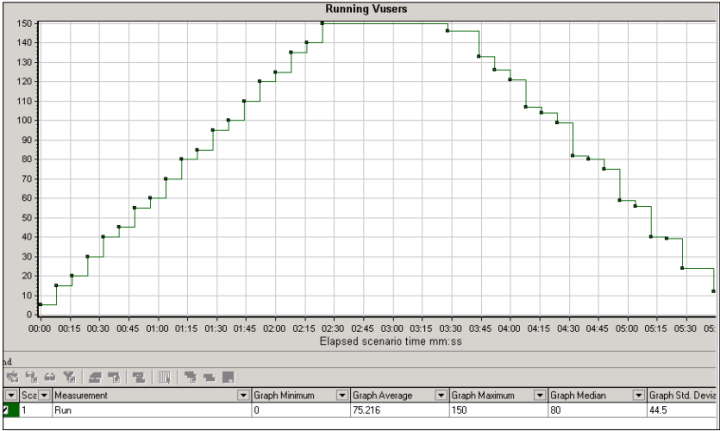
【Running Vuser】结果分析:Vuser是并发测试选取的虚拟用户,从下图中可以看出,Vuser是每5秒增加5个,在02:20秒的时候达到了顶峰值150,持续运行了一分钟后,逐渐退出系统。
【Hits per Second】结果分析:每秒提交的HTTP请求数量,在本场景中执行的时间比较短,因此结果不是很明显,建议大家此处可以放宽执行时间,这样得到的结果比较准确。
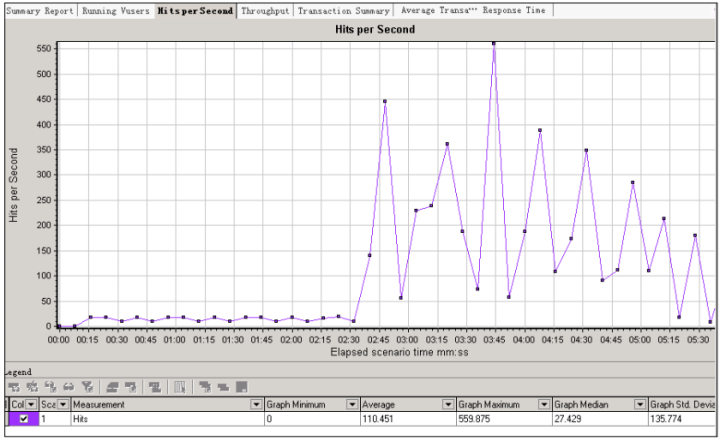
【Throughput】结果分析:吞吐量是指返回的应用层数据的值,吞吐量单位是以字节数为准,表示Vuser在任何给定的某一秒上从服务器获得的数据量。借助此图我们可以依据服务器吞吐量来评估Vuser产生的负载量。该数据越小说明系统的带宽依赖就越小,通过这个数据可以确定是不是网络出现了瓶颈。
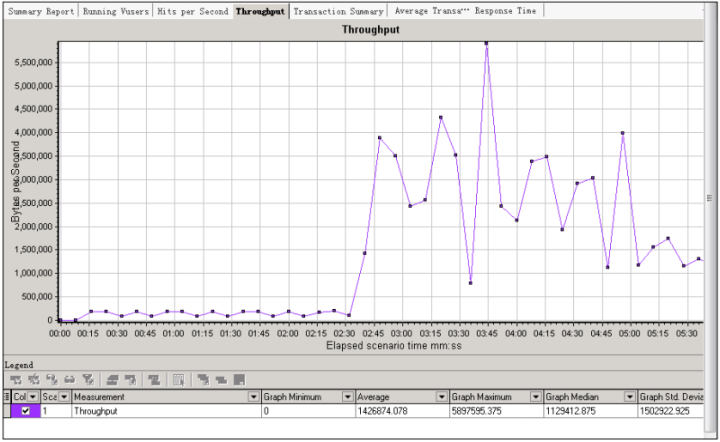
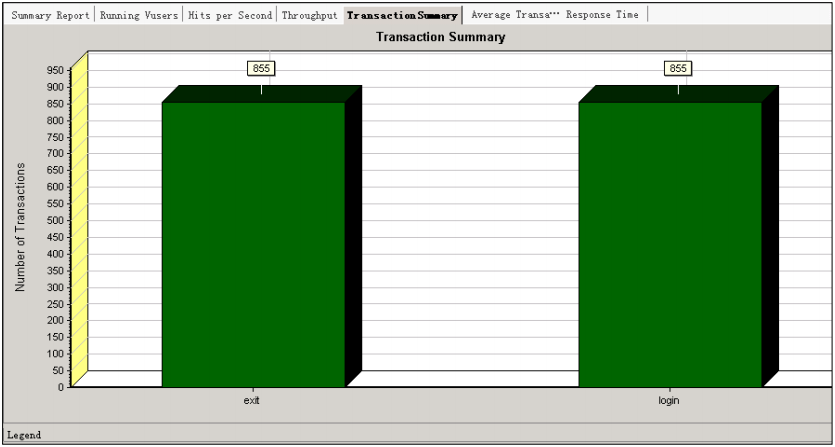
【Tansaction summary】结果分析:事务概要说明,统计执行的事务数量,比如在本次场景中,login和exist这两个事务的值都是855次。同事也监控了事务的Pass数和Fail数,了解负载的事务完成情况。通过的事务数越多,说明系统的处理能力越强;失败的事务数越小说明系统越可靠。这个比较容易理解,不多阐述。
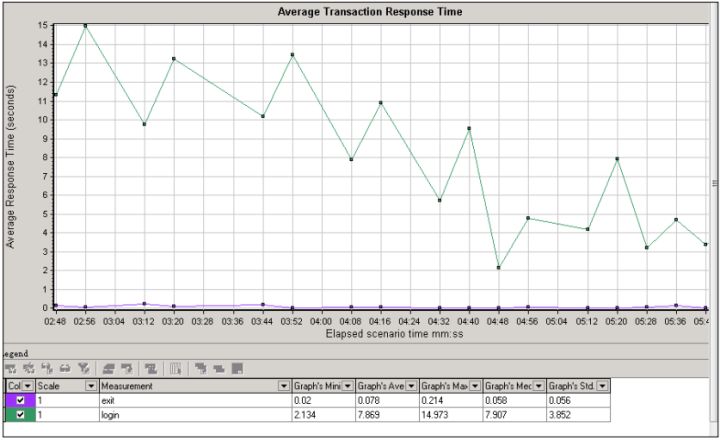
【Average Transaction Response Time】- 事务响应时间结果分析:这里需要注意的一个问题是因为在Transaction Response Times里面是场景运行时记录的响应时间的最大值最小值与平均值,而Average Transaction Response Time 是按照采样率每隔几秒钟取一个值画出来的图,然后根据图来记录最大值最小值和平均值,在报告中也可以看到,Average Transaction Response Time中写的是图最大值、图小值和图平均值。如果将采样率设置小一些,这两个值就会比较接。所以,抽象率是关键。那么下图现实的结果可以看出,login这个action最大值是14.978,最小值是2.134,平均值是7.869;exist最小值是0.02,最大值0.214,平均值是0.078 。这些时间是可以接受的压力响应的时间。
本次测试过程中常见问题汇总:
之所以加上问题汇总是因为笔主觉得大家在做压力测试的时候,这类问题的出现率很高,所以,在此稍微总结一下。
问题1:averager esponse time响应时间过长?(与实际偏差甚大完全不合理)
解决方法:导致此问题的原因很多,但是我们可以从以下几类去分析:1、是否在脚本中添加了多长时间的思考时间。2、事务和集合点的先后顺序是否正确,正确的顺序是把集合点放在事务前面,反之则也会增加事务响应时间的值。3、网速问题,网速一般不会造成太大的偏大,但是不排除并发量很大的情况下造成的延误。
问题2:LoadRunner超时错误
解决方法:首先在运行环境中对超时进行设置,默认的超时时间可以设置长一些,再设置多次迭代运行,如果还有超时现象,需要在“Runtime Setting”>“Internet Protocol:Preferences”>“Advanced”区域中设置一个“winlnet replay instead of sockets”选项,再回放是否成功。
问题3:LoadRunner脚本中出现乱码
解决方法:重新录制脚本,在录制脚本前,打开录制选项配置对话框进行设置,在“Recording Options”的“Advanced”选项里先将“Surport Charset”选中,然后选中支持“UTF-8”的选项。
问题4:在录制过程中IE页面上,某些控件显示有问题,导致录制不了。
解决方法:一般情况下,将被测系统的URL加入到可信任站点即可解决此类问题。
问题5:Error -27796:Failed to connect to server‘XXXX’
这个问题可以说是经常遇到但是不易被解决的难题,我们大致可以这样去排查
(1)检查run time setting中的请求超时时间Preferences中点击Options‘HTTPrequest connect timeout’,‘HTTP-request receieve timeout’,‘Step download timeout’,查看其值是否为1000、1000、10000;run time setting设置完了后记住还需要在control组件的option的run time setting 中设置相应的参数;
(2)Browser Emulation中的Download non-HTML resources选项去掉,点击OK即可如果还不能解决的话,继续尝试第3种方法
(3)设置runt time setting中的internet protocol-preferences中的advaced区域有一个winlnet replay instead of sockets选项,选项后再回放就成功了。如果实在不行的话就试试重启大法吧,因为有些问题的确可能是因为工具问题,网络问题,机子问题等等。
总结:用Loadrunner进行压力测试难免会遇到各种问题,细心排查总能一一解决,所以笔者想对刚刚踏入这一行业的朋友说,不急不燥认真去思考,问题总能被解决。希望此篇文章对大家有所帮助,任何问题都可以留言喔。
最后:
可以到我的个人号:atstudy-js,可以免费领取一份10G软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!其中包括了有基础知识、Linux必备、Mysql数据库、抓包工具、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试等。
这些测试资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
一边学习thisRailscast我从Rack中看到了以下源代码:defself.middleware@middleware||=beginm=Hash.new{|h,k|h[k]=[]}m["deployment"].concat[[Rack::ContentLength],[Rack::Chunked],logging_middleware]m["development"].concatm["deployment"]+[[Rack::ShowExceptions],[Rack::Lint]]mendend我的问题是关于第三行。什么是传递block{|h,k|h[k]=[]}到Has
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
三分钟集成Tap防沉迷SDK(Unity版)一、SDK介绍基于国家对上线所有游戏必须增加防沉迷功能的政策下,TapTap推出防沉迷SDK,供游戏开发者进行接入;允许未成年用户在周五、六、日以及法定节假日晚上8:00-9:00进行游戏,防沉谜时间段进入游戏会弹窗进行提示!开发环境要求:Unity2019.4或更高版本iOS10或更高版本Android5.0(APIlevel21)或更高版本🔗Unity集成Demo参考链接🔗UnityTapSDK功能体验APK下载链接二、集成前准备1.创建应用进入开发者后台,按照提示开始创建应用;2.开通服务在使用TDS实名认证和防沉迷服务之前,需要在上面创建的应