在下面的资源链接中下载MySQL软件压缩包(绿色版),这个版本是MySQL5.7.29的,本教程也只适用于这个绿色版的,如果下载的是安装包那就可能有些地方不一样了,具体哪不一样那咱也不太清楚,所以就需要另外搜索安装教程了咯,(温馨提示:如果下载的是安装包的朋友们安装时记得设置下编码格式为utf-8,否则插入中文会出问题)
这里用到的软件安装包(免安装)以及vcredist_x64.exe库等(附:MySQL中文手册)都放在了我的资源中可以自行下载
资源链接:
官网下载链接:
https://www.mysql.com/downloads/
解压到没有 中文 和 空格 的目录下, (安装路径不能有中文和空格哦)
配置环境变量:MySQL_HOME、path
计算机 右键--属性--高级系统设置--环境变量--系统变量--找到path编辑--新建
MySQL_HOME:D:\czbk\software\mysql-5.7.29-winx64
注意:路径配置到MySQL解压目录bin目录的上一级
path:%MySQL_HOME%\bin
将my.ini配置文件,放入到MySQL解压包下my.ini和bin目录同级
在解压包bin目录下打开dos窗口,注意:以管理员身份运行
win+r进入dos窗口
初始化服务(自动创建data文件夹)
mysqld --initialize-insecure --user=mysql
安装服务
mysqld -install
启动服务测试
net start mysql
设置账号密码为:root ,第一次安装时没有密码
mysqladmin -u root -p password "root"
登录数据库,开始操作
mysql -u root -p root
MySQL启动和关闭指令
mysql启动指令:net start mysql
mysql关闭指令:net stop mysql
问题1: 不是内部或外部命令 不能执行
原因:
1、你要使用管理员身份打开CMD
2、命令输入错误
问题2:由于找不到MSVCR120.dll,无法执行代码,重新安装程序可能会解决此问题
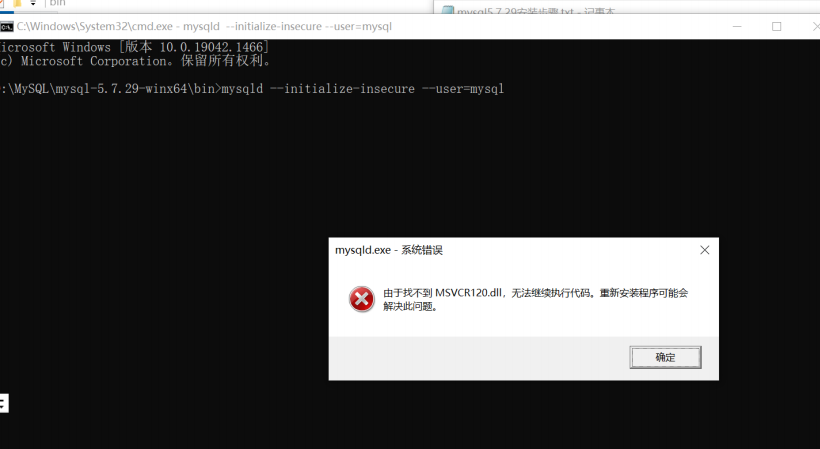
安装时出现上面的提示,就是系统缺失类库,需要安装vcredist_x64.exe
安装完成之后,继续剩下的步骤即可,(这是一个C++库,上面的我的资源分享中有,可以自行下载)
问题3:如图错误提示
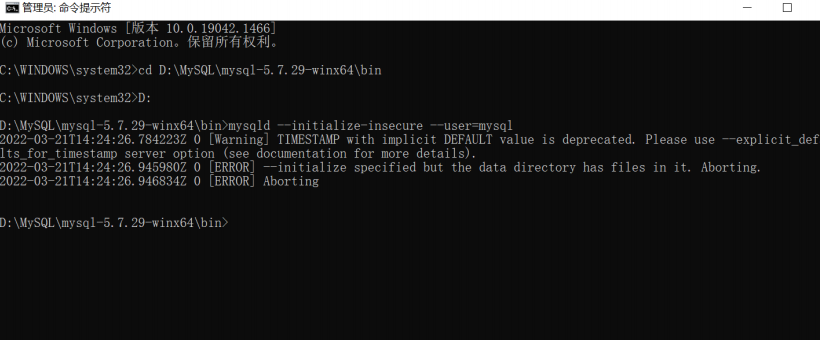
原因:
mysqld初始化data目录的命令已经执行过了,生成了data目录在安装包下
解决:
方式1.删除data目录 重新执行mysqld初始化命令
方式2:继续执行剩下的安装步骤即可` mysqld --initialize-insecure --user=mysql`
卸载需要注意的地方
去360/软件管家或者控制面板卸载(删除之前先找到下面这两个文件夹)一定要删除这两个文件夹(数据库安装路径和数据存放路径,这两个文件夹在配置文件里面my.ini)

卸载解压安装的mysql
关闭服务 net stop mysql
删除服务即可 sc delete mysql
删除配置的MySQL环境变量
删除解压后mysql文件夹
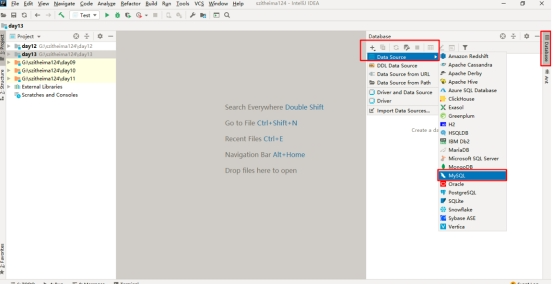
创建MySQL数据库链接,点击左上角的+之后选择DataSource(选择数据源)之后选择创建MySQL数据源.
导入MySQL驱动JAR包,找到左边列表Drivers下的MySQL
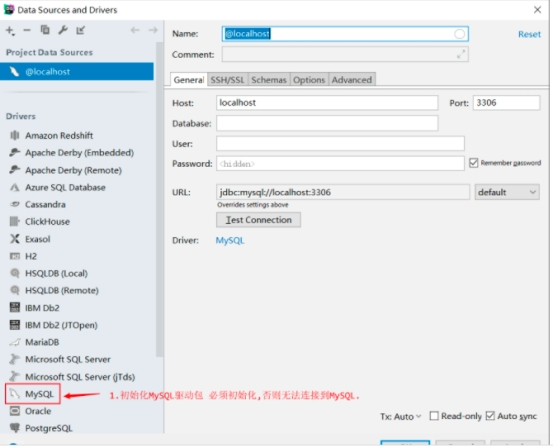
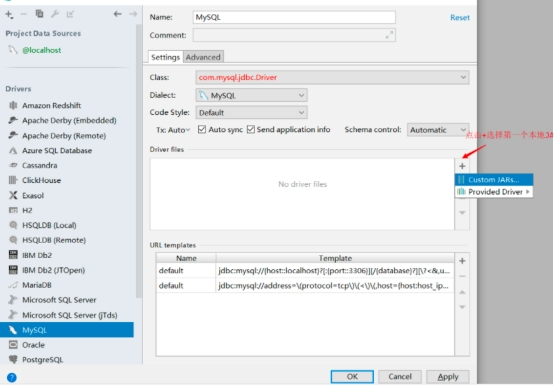
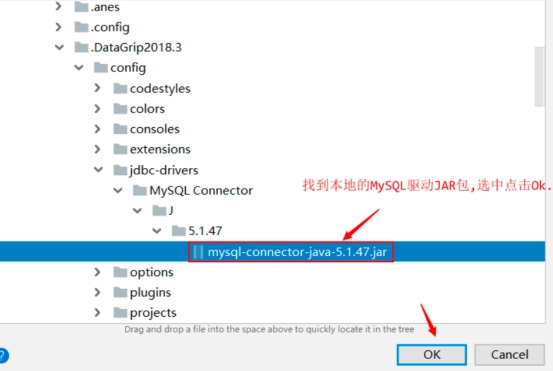
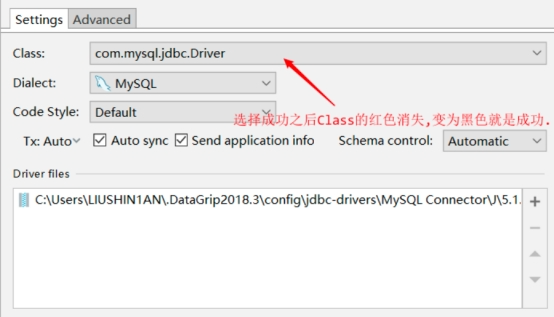
回到刚开始链接信息定义的位置继续输入MySQL服务器的相关信息
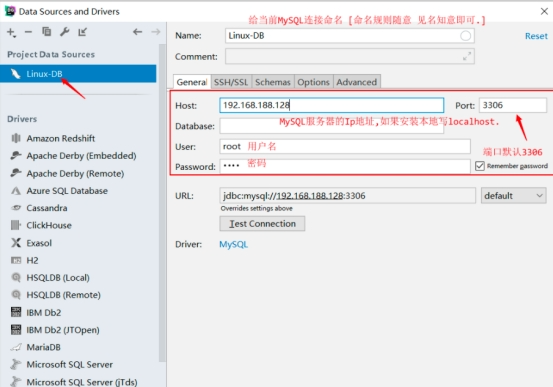
如果没有问题点击Test Connection,如果现实Success即可成功
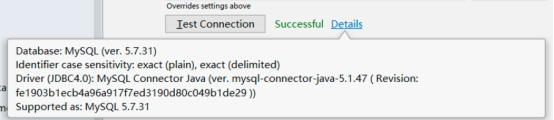
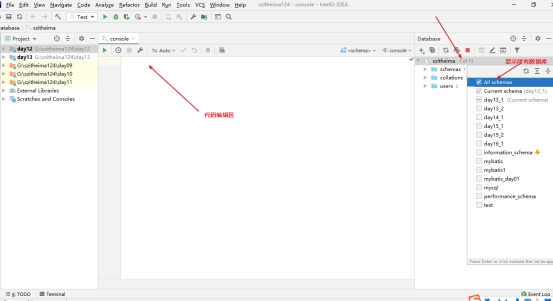
连接界面部分说明 显示所有数据库方式/SQL语句编辑区/数据库选择
试MySQL数据库的SQL语句执行能力,通过快捷键Ctrl + Enter即可执行被淡紫色框选中的SQL语句会在下面弹出执行结果信息
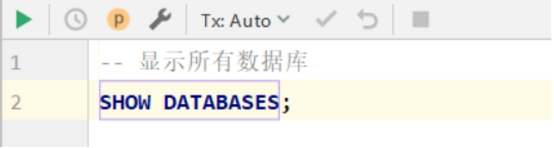
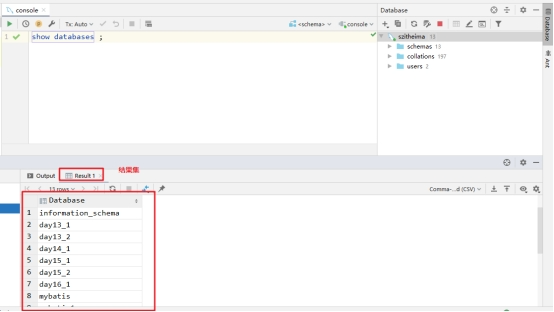
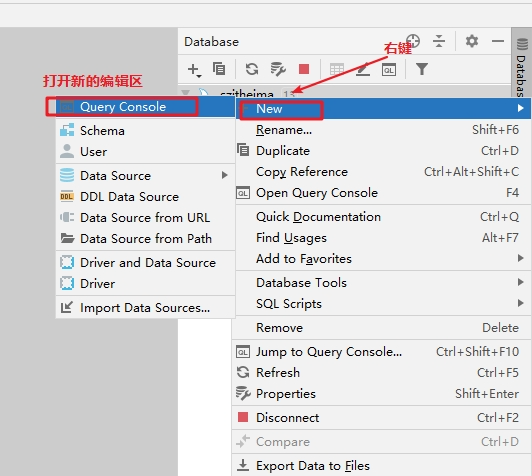
到这个地方基本就可以对数据库进行操作了.
-- 注释
-- ------------------------------------DDL语句操作数据库--------------------------
-- 创建数据库: create database 数据库名 [character set 字符编码][collate 校对规则];-- []表示可选
-- 需求: 创建名称为day14_1的数据库,默认编码为utf8
create database day14_1;
-- 需求: 创建名称为day14_2的数据库,指定编码为gbk
create database day14_2 character set gbk;
-- 查看所有数据库: show databases;
-- 查看数据库结构: show create database 数据库名;
-- 需求:查询所有的数据库
show databases ;
-- 需求: 查看day14_1数据库的定义结构
show create database day14_1;
-- 需求: 查看day14_2数据库的定义结构
show create database day14_2;
# 修改数据库: alter database 数据库名 character set 字符编码;
# 注意:1.数据库名不能修改 2.只能修改数据库的编码,是utf8,不是utf-8
-- 需求:把day14_2数据库的编码修改为utf8
alter database day14_2 character set utf8;
show create database day14_2;
# 删除数据库: drop database 数据库名;
# 需求: 删除day14_2数据库
drop database day14_2;
# 其他操作:
# 切换数据库: use 数据库名;
# 查看正在使用的数据库: select database();
use test;
select database();
use day14_1;
select database();
# --------------------------------DDL语句操作表----------------------------
# 创建表的语法:
# create table 表名(字段名 字段类型 字段约束,....);
# 子类类型: int,bigint,boolean,double/char(长度)/varchar(长度),date,datetime
# 创建一张用户表表(含有id字段,用户名字段,密码字段. id为主键自动增长)
create table users(
id int primary key auto_increment,
username varchar(40) not null,
password varchar(40)
);
# 查看所有的表: show tables;
# 查看表的定义结构: desc 表名;
-- 练习:查看day14_1数据库中所有的表
show tables ;
-- 练习:查看day14_1数据库中users表的结构
desc users;
# 修改表:
# #### 语法
# - 增加一列: `alter table 表名 add 字段名 字段类型 [字段约束];`
# - 修改列的类型约束:`alter table 表名 modify 字段名 字段类型 字段约束;`
# - 修改列的名称:`alter table 表名 change 旧列名 新列名 字段类型 字段约束;`
# - 删除一列: `alter table 表名 drop 字段名;`
# - 修改表名: `rename table 旧表名 to 新表名;`
# #### 练习
create table student(
id int primary key auto_increment,
name varchar(40) not null ,
sex varchar(30)
);
# - 给学生表增加一个grade字段
alter table student add grade varchar(30);
desc student;
# - 给学生表的sex字段改成字符串类型
alter table student modify sex char(2);
# - 给学生表的grade字段修改成class字段
alter table student change grade class varchar(30);
desc student;
# - 把class字段删除
alter table student drop class;
# - 把学生表修改成老师表(了解)
rename table student to teacher;
# 语法: `drop table 表名;`
-- 练习: 删除teacher表
drop table teacher;
# ------------------------------DML操作数据-------------------------------
# 准备数据:
create table product(
pid int primary key auto_increment, -- 只有设置了auto_increment id列才可以赋值为null
pname varchar(40) not null,
price double,
num int
);
# 新增记录:
# 插入指定列: insert into 表名(列名,列名,...) values(值,值,...);
# 练习: 指定pname,price列插入记录
insert into product(pname,price) values('Mac',9000);
# -- 注意:
# -- 字段名与值的类型、个数、顺序要一一对应。
# -- 值不要超出列定义的长度。
# -- 插入的日期和字符串,使用引号括起来(单双引号)。
# -- 插入特定的列:没有赋值的列,系统自动赋为null(前提是当前列没有设置not null 约束,否则会报错)
# 插入所有列: insert into 表名 values(值,值,...);
# 注意:默认所有列插入,values里面必须给表中每一个字段赋值,一般主键给一个null
-- 练习: 指定所有列插入记录
insert into product values(null,'iPhone',6000,2);
insert into product value(null,'iPhone',6000,2);
# 批量插入记录
insert into product values(null,'苹果电脑',18000.0,10);
insert into product values(null,'华为5G手机',30000,20);
insert into product values(null,'小米手机',1800,30);
insert into product values(null,'iPhonex',8000,10);
insert into product values(null,'苹果电脑',8000,100);
insert into product values(null,'iPhone7',6000,200);
insert into product values(null,'iPhone6s',4000,1000);
insert into product values(null,'iPhone6',3500,100);
insert into product values(null,'iPhone5s',3000,100);
insert into product values(null,'方便面',4.5,1000);
insert into product values(null,'咖啡',11,200);
insert into product values(null,'矿泉水',3,500);
insert into product values(null,'苹果电脑',18000.0,10),
(null,'华为5G手机',30000,20),
(null,'小米手机',1800,30),
(null,'iPhonex',8000,10),
(null,'苹果电脑',8000,100),
(null,'iPhone7',6000,200),
(null,'iPhone6s',4000,1000),
(null,'iPhone6',3500,100),
(null,'iPhone5s',3000,100),
(null,'方便面',4.5,1000),
(null,'咖啡',11,200),
(null,'矿泉水',3,500);
insert into product values(null,'苹果电脑',8000,3);
# - 语法: `update 表名 set 字段名=值,字段名=值,... where 条件; `
# - 练习
# - 将所有商品的价格修改为5000元
update product set price = 6000;
# - 将商品名是Mac的价格修改为18000元
update product set price = 18000 where pname = 'Mac';
# - 将商品名是Mac的价格修改为17000,数量修改为5
update product set price = 17000,num=5 where pname = 'Mac';
# - 将商品名是方便面的商品的价格在原有基础上增加2元
update product set price = price + 2 where pname = '方便面';
# 语法
# 方式一: `delete from 表名 where 条件;`
# 方式二: `truncate table 表名;`
# - 练习
# - 删除表中名称为’Mac’的记录
delete from product where pname='Mac';
# - 删除价格小于6001的商品记录
delete from product where price < 6001;
# - 删除表中的所有记录
delete from product;
truncate table product;
# ------------------------------DQL语句操作记录------------------------------
# 查询所有: select * from 表名;
-- 练习:查询product表中所有的信息
select * from product;
# 指定字段查询: select 字段名,字段名,... from 表名
-- 练习:查询product表中pname,price字段的值
select pname,price from product;
# 去重查询:select distinct 字段名 from 表名
-- 练习:去重查询pname字段的值
select distinct pname from product;
-- 注意:去重查询distinct前面不能有其他字段名
# select price,distinct pname from product;-- 报错
# 取别名查询:select 字段名 as 别名,字段名 as 别名 from 表名 as 别名
-- 练习:对pname,price取别名查询
select pname as 商品名称,price as 商品价格 from product as p;
select pname 商品名称,price 商品价格 from product p;
# 列运算查询(+,-,*,/等): select 列运算 from 表名;
-- 练习: 查询每件商品的总金额
select price*num from product;
# - 基本条件查询: select ... from 表名 where 条件;
# 条件: 比较运算符: `> >= < <= = <>`
-- 练习: 查询price大于4000的商品信息
select * from product where price > 4000;
# 条件: between...and... 范围
-- 练习: 查询price在4000到8000之间的商品信息
select * from product where price between 4000 and 8000;
# 条件: in(值,值,...) 范围
-- 练习: 查询pid为1,3,5,7,9,11,13的商品信息
select * from product where pid in(1,3,5,7,9,11,13);
# like模糊
# _ : 匹配一个字符
# %: 匹配0个到多个字符(大于等于0个)
-- 练习: 查询商品名称为iPh开头的所有商品信息
select * from product where pname like 'iPh%';
-- 练习: 查询商品名称含有手机的所有商品信息
select * from product where pname like '%手机%';
-- 练习: 查询商品名称为iPh开头,然后iPh后面有4位的所有商品信息
select * from product where pname like 'iPh____';
# 条件: 逻辑运算符: and,or,not
-- 练习: 查询price在4000到8000之间的商品信息
select * from product where price >= 4000 and price <= 8000;
-- 练习: 查询price大于4000或者小于1000之间的商品信息
select * from product where price > 4000 or price < 1000;
-- 练习: 查询pid不为1,3,5,7,9,11,13的商品信息
select * from product where pid not in(1,3,5,7,9,11,13);
# # 创建学生表(有sid,学生姓名,学生性别,学生年龄,分数列,其中sid为主键自动增长)
CREATE TABLE student(
sid INT PRIMARY KEY auto_increment,
sname VARCHAR(40),
sex VARCHAR(10),
age INT,
score DOUBLE
);
INSERT INTO student VALUES(null,'zs','男',18,98.5);
INSERT INTO student VALUES(null,'ls','女',18,96.5);
INSERT INTO student VALUES(null,'ww','男',15,50.5);
INSERT INTO student VALUES(null,'zl','女',20,98.5);
INSERT INTO student VALUES(null,'tq','男',18,60.5);
INSERT INTO student VALUES(null,'wb','男',38,98.5);
INSERT INTO student VALUES(null,'小丽','男',18,100);
INSERT INTO student VALUES(null,'小红','女',28,28);
INSERT INTO student VALUES(null,'小强','男',21,95);
# 方式一: select ... from 表名 order by 字段名 [asc|desc];
# 方式二: select ... from 表名 order by 字段名 [asc|desc],字段名 [asc|desc];
# 注意:asc:升序,desc:降序,不指定默认是升序
# 练习
# 1. 练习: 以分数降序查询所有的学生
select * from student order by score desc ;
# 2. 练习: 以分数降序查询所有的学生, 如果分数一致,再以age降序
select * from student order by score desc,age desc ;
# 语法: SELECT 聚合函数(列名) FROM 表名;
# 注意: 聚合函数会忽略空值NULL
-- 练习:求出学生表里面的最高分数
select max(score) from student;
-- 练习:求出学生表里面的最低分数
select min(score) from student;
-- 练习:求出学生表里面的分数的总和
select sum(score) from student;-- 726
-- 练习:求出学生表里面的平均分
select avg(score) from student;-- 80.66666666666667
-- 练习:统计学生的总人数
select count(score) from student;-- 9
-- 修改: 把sname为wb的score修改为null
update student set score = null where sname = 'wb';
-- 练习:统计学生的总人数
select count(score) from student;-- 8
select count(*) from student;-- 9
-- 练习:求出学生表里面的分数的总和
select sum(score) from student;-- 627.5
-- 练习:求出学生表里面的平均分
select avg(score) from student;-- 78.4375-----错了,真正的平均分应该是69.7222222222
# ifnull(参数1,参数2)
# 如果不想忽略空值null,就使用ifnull(参数1,参数2)函数,进行判断
# 如果参数1为null,就取参数2的值,如果参数1不为null,就取参数1的值
select avg(ifnull(score,0)) from student;-- 69.72222222222223
# 语法: select ... from 表名 [where 条件] [group by 分组字段] [having 条件]
# 练习:
# 1. 练习:根据性别分组,统计男生的总人数和女生的总人数
select * from student group by sex;
# 注意事项
# **单独分组 没有意义,因为 返回每一组的第一条记录**
# **分组的目的一般为了做统计使用, 所以经常和聚合函数一起使用**
select count(*) from student group by sex;
# **分组查询如果不查询出分组字段的值,就无法得知结果属于那组**
select sex,count(*) from student group by sex;
# 2. 练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
select sex,count(*) from student group by sex having count(*) > 5;
select sex,count(*) from student where sid in(1,2,3,4,5,6,7) group by sex having count(*) >= 5;
# select ... from 表名 limit a,b;
# a:从哪里开始查询, 从0开始计数 ,省略a不写,默认就是从0开始
# b:查询的数量【固定的,自定义的】
# 练习:
-- 练习: 查询sid为1到4--->第1页
select * from student limit 0,4;
-- 练习: 查询sid为5到8--->第2页
select * from student limit 4,4;
-- 练习: 查询sid为9到12--->第3页
select * from student limit 8,4;
# 规律:
# select * from student limit (页码-1)*每页显示的条数,每页显示的条数;
create database 数据名;
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje