如果你对图论相关知识一点也没有,那么建议您先去了解这些知识:https://acmer.blog.csdn.net/article/details/122310835,然后就可以快乐的学习最短路算法啦
视频中绘图软件:https://csacademy.com/app/graph_editor/
配套讲解视频:https://www.bilibili.com/video/BV1Fa411C7wX/
如果哪里讲的有问题欢迎在评论区指出,感谢支持!
Floyd算法算是最简单的算法,没有之一。适用于任何图
不管有向无向,边权正负,但是最短路必须存在。
基于动态规划的思想
O ( N 3 ) O(N^3) O(N3)
O ( N 2 ) O(N^2) O(N2)
常数小,容易实现,思路简单,能处理大部分图
复杂度较高、不能处理负环图
我们定义一个三维数组
f
[
k
]
[
u
]
[
v
]
f[k][u][v]
f[k][u][v]表示的是允许经过
[
1
,
k
]
[1,k]
[1,k]的点的
u
u
u到
v
v
v的最小距离,换句话说从
1
1
1到
k
k
k这些点可以作为
u
u
u到
v
v
v的中间节点,当然没也可以不经过,很显然我们如果要求解
u
u
u到
v
v
v的最小距离那么就是
f
[
n
]
[
u
]
[
v
]
f[n][u][v]
f[n][u][v](假设当前的图中有n个点的话),那么我们考虑怎么来维护这个关系呢,首先初始化来说,
f
[
0
]
[
u
]
[
v
]
f[0][u][v]
f[0][u][v]先初始化为INF,如果有边连接的话,那么我们取一个min就好,还有就是如果u和v相等的话应该初始化为0,那么我们就能推出这个状态是如何转移的:
f [ k ] [ u ] [ v ] = m i n ( f [ k − 1 ] [ u ] [ v ] , f [ k − 1 ] [ u ] [ k ] + f [ k − 1 ] [ k ] [ v ] ) f[k][u][v] = min(f[k-1][u][v],f[k-1][u][k] + f[k-1][k][v]) f[k][u][v]=min(f[k−1][u][v],f[k−1][u][k]+f[k−1][k][v])
我们对经过k点和不经过k点去一个min,那么我们的状态转移方程就构造好啦,下面给出代码
void Floyd(){
for(int k = 1;k <= n; ++k)
for(int i = 1;i <= n; ++i)
for(int j = 1;j <= n; ++j)
f[k][i][j] = min(f[k-1][i][j],f[k-1][i][k]+f[k-1][k][j]);
}
我们发现我们这个第一维的k其实最多能用到当前这一层以及上一层的状态,那么我们可以通过滚动数组优化将其去掉,那么新的代码即为:
void Floyd(){
for(int k = 1;k <= n; ++k)
for(int i = 1;i <= n; ++i)
for(int j = 1;j <= n; ++j)
f[i][j] = min(f[i][j],f[i][k]+f[k][j]);
}
关于第一维对结果无影响的证明:
我们注意到如果放在一个给定第一维
k二维数组中,f[x][k]与f[k][y]在某一行和某一列。而f[x][y]则是该行和该列的交叉点上的元素。现在我们需要证明将
f[k][x][y]直接在原地更改也不会更改它的结果:我们注意到f[k][x][y]的涵义是第一维为k-1这一行和这一列的所有元素的最小值,包含了f[k-1][x][y],那么我在原地进行更改也不会改变最小值的值,因为如果将该三维矩阵压缩为二维,则所求结果f[x][y]一开始即为原f[k-1][x][y]的值,最后依然会成为该行和该列的最小值。故可以压缩。
模板题:多源最短路
#include<bits/stdc++.h>
using namespace std;
const int N = 2e2+10;
const int INF = 0x3f3f3f3f;
int n,m,k;
int f[N][N];
void Floyd(){
for(int k = 1;k <= n; ++k)
for(int i = 1;i <= n; ++i)
for(int j = 1;j <= n; ++j)
f[i][j] = min(f[i][j],f[i][k]+f[k][j]);
}
int main()
{
cin>>n>>m>>k;
int u,v,w;
for(int i = 1;i <= n; ++i)
for(int j = 1;j <= n; ++j)
f[i][j] = i==j?0:INF;
for(int i = 1;i <= m; ++i){
cin>>u>>v>>w;
f[u][v] = min(f[u][v],w);
}
Floyd();
while(k--){
cin>>u>>v;
if(f[u][v] > INF / 2) cout<<"impossible"<<endl;
else cout<<f[u][v]<<endl;
}
return 0;
}
B e l l m a n − F o r d Bellman-Ford Bellman−Ford 算法是一种基于松弛( r e l a x relax relax)操作的最短路算法,可以求出有负权的图的最短路,并可以对最短路不存在的情况进行判断。当然你可能没听过这个算法,但是应该听过另一个算法 S P F A SPFA SPFA 算法, S P F A SPFA SPFA算法其实就是加入了队列优化的 B e l l m a n − F o r d Bellman-Ford Bellman−Ford
O ( N M ) O(NM) O(NM)
邻接矩阵: O ( N 2 ) O(N^2) O(N2)
邻接表: O ( M ) O(M) O(M)
能够处理负权图、能处理边数限制的最短路
复杂度不太理想,很容易被卡
在介绍该算法前,先来介绍一下松弛操作,对于一个边 ( u , v ) (u,v) (u,v),松弛操作对应下面的式子: d i s [ v ] = m i n ( d i s [ v ] , d i s [ u ] + w ( u , v ) ) dis[v]=min(dis[v],dis[u]+w(u,v)) dis[v]=min(dis[v],dis[u]+w(u,v))。也就是我们将源点到v点的距离更新的一个操作
也就是开始可能源点 S S S到 v v v的路径为 S − > v S->v S−>v,如果说经过 u u u点后再到 v v v的权值比直接到v小那么我们就更新一下路径最小值,这就是松弛操作
Bellman算法要做的事就是对于图中所有的边,我们都进行一次松弛操作,那么完成这整个操作的复杂度大概在 O ( M ) O(M) O(M),然后我们就一直循环的进行这个操作,直到我们不能进行松弛操作为止,就说明我们的单源最短路以及全部求完,那么我们需要多少次这样的完整操作呢,在最短路存在的情况下,由于一次松弛操作会使最短路的边数至少+1 ,而最短路的边数最多为 N − 1 N-1 N−1 ,因此整个算法最多执行 N − 1 N-1 N−1轮松弛操作。故总时间复杂度为 O ( N M ) O (NM) O(NM)。
上面提到了我们在求最短路存在的情况最多执行 N − 1 N-1 N−1轮松弛操作,如果数据中出现了负环,那么我们在第N轮操作的时候也会更新
注意一点:
以 S S S点为源点跑 Bellman-Ford 算法时,如果没有给出存在负环的结果,只能说明从 S S S点出发不能抵达一个负环,而不能说明图上不存在负环。因为这个图可能是不连通的,那么对于不连通的图我们应该建一个虚点或者称之为超级源点,让这个点连向每一个其他的点并且权值为0,然后再来跑 b e l l m a n _ f o r d bellman\_ford bellman_ford
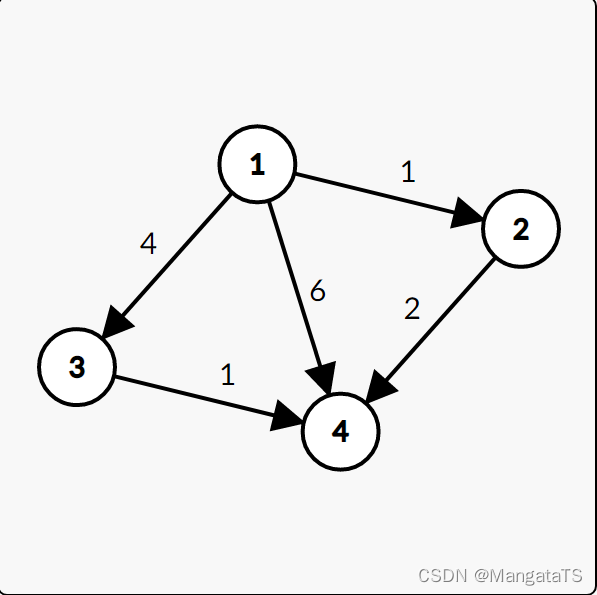
| 第x轮松弛操作 | 本轮松弛操作 |
|---|---|
| 1 | dis[2] =1,dis[3]=4,dis[4]=6 |
| 2 | dis[4]=3 |
| 3 | 无操作 |
模板题:https://ac.nowcoder.com/acm/contest/27274/E
#include<algorithm>
#include<cstring>
#include<iostream>
#include<cstdio>
#include<vector>
const int INF = 0x3f3f3f3f;
const int N = 10000+10;
using namespace std;
struct Node{
int u,v,w;
};
vector<Node> E;
int n,m,s,t;
int dis[N];
void bellman_ford(int s){
for(int i = 1;i <= n; ++i) dis[i] = INF;
dis[s] = 0;
for(int i = 1;i <= n; ++i)
for(int j = 0;j < 2 * m; ++j) {
int u = E[j].u,v = E[j].v,w = E[j].w;
if(dis[v] > dis[u] + w)
dis[v] = dis[u] + w;
}
}
int main()
{
cin>>n>>m>>s>>t;
int u,v,w;
for(int i = 1;i <= m; ++i) {
cin>>u>>v>>w;
E.push_back({u,v,w});
E.push_back({v,u,w});
}
bellman_ford(s);
if(dis[t] >= INF / 2) cout<<"-1"<<endl;
else cout<<dis[t]<<endl;
}
如果我们发现第 N N N轮操作也更新了那么说明存在负权回路
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
#define INF 0x3f3f3f3f
const int N = 2e6+10;
int n,m,q,k;
struct Edge{
int u,v,w;
}E[N];
int dis[N];
bool bellman_ford(){
for(int i = 1;i <= n; ++i)
for(int j = 0;j < m; ++j) {
int u = E[j].u,v = E[j].v,w=E[j].w;
if(dis[v] > dis[u] + w){
dis[v] = dis[u] + w;
if(i == n)
return true;
}
}
return false;
}
int main()
{
cin>>n>>m;
for(int i = 0;i < m; ++i) {
int u,v,w;
cin>>u>>v>>w;
E[i]={u,v,w};
}
bool k = bellman_ford();
if(k) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
return 0;
}
关于SPFA,它死了
理想复杂度为 O ( K M ) O(KM) O(KM),这里的 K K K可以看作一个常数
最坏为 O ( N M ) O(NM) O(NM)但是一般情况下是跑不到这么多(除非出题人卡SPFA)
邻接表: O ( M ) O(M) O(M)
邻接矩阵: O ( N 2 ) O(N^2) O(N2)
好写、效率挺快(一般来说即不被卡的话),能处理几乎所有类型的图
容易被网格菊花图卡成傻b
其实 S P F A SPFA SPFA算法就是 b l l m a n _ f o r d bllman\_ford bllman_ford算法加上了队列优化,我们在上面的 b e l l m a n _ f o r d bellman\_ford bellman_ford算法能知道我们实际上是将每一个边都松弛了 N − 1 N-1 N−1次,实际上我们没必要松弛每一个点,因为有些点实际上是不用松弛太多或者说不用松弛的,那么我们希望去掉一些无用的松弛操作,这个时候我们用队列来维护哪些点可能会需要松弛操作,这样就能只访问必要的边了。同样的由于SPFA是队列优化的 b e l l m a n _ f o r d bellman\_ford bellman_ford那么同样能处理负权回路的图
tips:
虽然在大多数情况下 S P F A SPFA SPFA 跑得很快,但其最坏情况下的时间复杂度为 O ( N M ) O(NM) O(NM),将其卡到这个复杂度也是不难的,所以考试时要谨慎使用(在没有负权边时最好使用 D i j k s t r a Dijkstra Dijkstra 算法,在有负权边且题目中的图没有特殊性质时,若 S P F A SPFA SPFA 是标算的一部分,题目不应当给出 B e l l m a n − F o r d Bellman-Ford Bellman−Ford 算法无法通过的数据范围)。
用dis数组记录源点到有向图上任意一点距离,其中源点到自身距离为0,到其他点距离为INF。将源点入队,并重复以下步骤:
我们会发现SPFA的这个过程就和BFS是类似的,如果图是随机生成的,时间复杂度为 O(KM) (K可以认为是个常数,m为边数,n为点数)但是实际上SPFA的算法复杂度是 O(NM) ,可以构造出卡SPFA的数据,让SPFA超时。所以使用 S P F A SPFA SPFA前一定要三思
| 不在队列的元素 | 在队列的元素 | 当前松弛操作 |
|---|---|---|
| { 2 , 3 , 4 } \{2,3,4 \} {2,3,4} | { 1 } \{ 1\} {1} | d i s [ 3 ] = 4 , d i s [ 2 ] = 2 , d i s [ 4 ] = 6 dis[3]=4,dis[2]=2,dis[4]=6 dis[3]=4,dis[2]=2,dis[4]=6 |
| { 1 } \{1 \} {1} | { 2 , 3 , 4 } \{2,3,4 \} {2,3,4} | dis[4]=3 |
| { 1 , 2 } \{1,2 \} {1,2} | { 3 , 4 } \{3,4 \} {3,4} | 无操作 |
| { 1 , 2 , 3 } \{1,2,3 \} {1,2,3} | { 4 } \{4 \} {4} | 无操作 |
| { 1 , 2 , 3 , 4 } \{1,2,3,4 \} {1,2,3,4} | { ∅ } \{\varnothing \} {∅} | 无操作 |
除了队列优化(SPFA)之外,Bellman-Ford 还有其他形式的优化,这些优化在部分图上效果明显,但在某些特殊图上,最坏复杂度可能达到指数级。
既然有了优化,那么就会有相应的卡的方法,具体请看这一篇回答:https://www.zhihu.com/question/292283275/answer/484871888
模板题:https://ac.nowcoder.com/acm/contest/27274/E
#include<algorithm>
#include<cstring>
#include<iostream>
#include<cstdio>
#include<vector>
#include<queue>
const int INF = 0x3f3f3f3f;
const int N = 10000+10;
using namespace std;
struct Node{
int v,w;
};
vector<Node> E[N];
int n,m,s,t;
int dis[N];
bool vis[N];
void SPFA(int s){
for(int i = 1;i <= n; ++i)
vis[i] = false,dis[i] = INF;
queue<int> que;
que.push(s);
dis[s] = 0,vis[s] = true;
while(!que.empty()){
int t = que.front();
que.pop();
vis[t] = false;
for(int i = 0,l = E[t].size();i < l; ++i) {
int j = E[t][i].v;
int k = E[t][i].w;
if(dis[j] > dis[t] + k){
dis[j] = dis[t] + k;
if(!vis[j]){
vis[j] = true;
que.push(j);
}
}
}
}
}
int main()
{
cin>>n>>m>>s>>t;
int u,v,w;
for(int i = 1;i <= m; ++i) {
cin>>u>>v>>w;
E[u].push_back({v,w});
E[v].push_back({u,w});
}
SPFA(s);
if(dis[t] >= INF / 2) cout<<"-1"<<endl;
else cout<<dis[t]<<endl;
}
#include<iostream>
#include<algorithm>
#include<cstdio>
#include<queue>
#include<vector>
using namespace std;
#define PII pair<int,int>
const int N = 2e6+10;
int n,m,q;
vector<PII> E[N];
int dis[N],cnt[N];
bool vis[N];
void spfa(){
queue<int> que;
for(int i = 1;i <= n; ++i) que.push(i),vis[i] = true;
while(!que.empty()){
int t = que.front();
que.pop();
vis[t] = false;//表明t这个点已经离开这个队列了
for(int i = 0,l = E[t].size();i < l; ++i) {
int j = E[t][i].first,k = E[t][i].second;
if(dis[j] > dis[t] + k) {
dis[j] = dis[t] + k;
cnt[j] = cnt[t] + 1;
if(cnt[j] >= n) {//找到负权边
cout<<"Yes"<<endl;
return;
}
if(!vis[j])//将j这个点重新加入队列
que.push(j),vis[j] = true;
}
}
}
cout<<"No"<<endl;
}
int main()
{
cin>>n>>m;
int u,v,w;
for(int i = 0;i < m; ++i) {
cin>>u>>v>>w;
E[u].push_back({v,w});
}
spfa();
return 0;
}
关于 S P F A SPFA SPFA判断正环的可以参考这一题:https://blog.csdn.net/m0_46201544/article/details/123011318
d i j k s t r a dijkstra dijkstra是一种单源最短路径算法,时间复杂度上限为 O ( n 2 ) O(n^2) O(n2) (朴素),在实际应用中较为稳定 ; 加上堆优化之后更是具有 O ( ( n + m ) log 2 n ) O((n+m)\log_{2}n) O((n+m)log2n) 的时间复杂度,在稠密图中有不俗的表现.
D i j k s t r a ( / ˈ d i k s t r ɑ / 或 / ˈ d ɛ i k s t r ɑ / ) Dijkstra(/ˈdikstrɑ/或/ˈdɛikstrɑ/) Dijkstra(/ˈdikstrɑ/或/ˈdɛikstrɑ/)算法由荷兰计算机科学家 E . W . D i j k s t r a E. W. Dijkstra E.W.Dijkstra 于 1956 1956 1956 年发现, 1959 1959 1959 年公开发表。是一种求解 非负权图 上单源最短路径的算法。
贪心思想
O ( N 2 ) O(N^2) O(N2)
O ( M ) O(M) O(M)
O ( N 2 ) O(N^2) O(N2)
O ( ( n + m ) log 2 n ) O((n+m)\log_{2}n) O((n+m)log2n)
朴素 D i j k s t r a Dijkstra Dijkstra和堆优化的 D i j k s t r a Dijkstra Dijkstra基本上能解决所有的正权图最短路问题,时间复杂度不会受到限制
不能处理负权图,如果需要处理负权图请移步 S P F A SPFA SPFA
但是在某些特定的含有负边的图DJ也是对的例如:
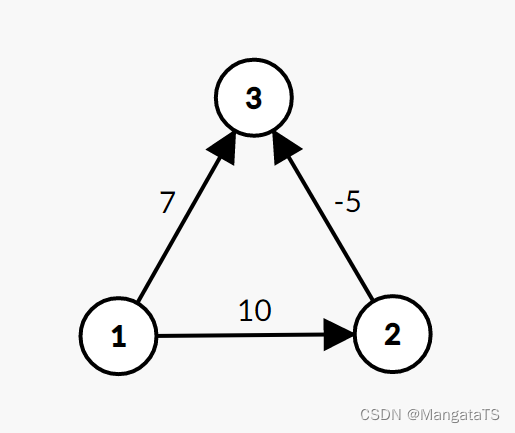
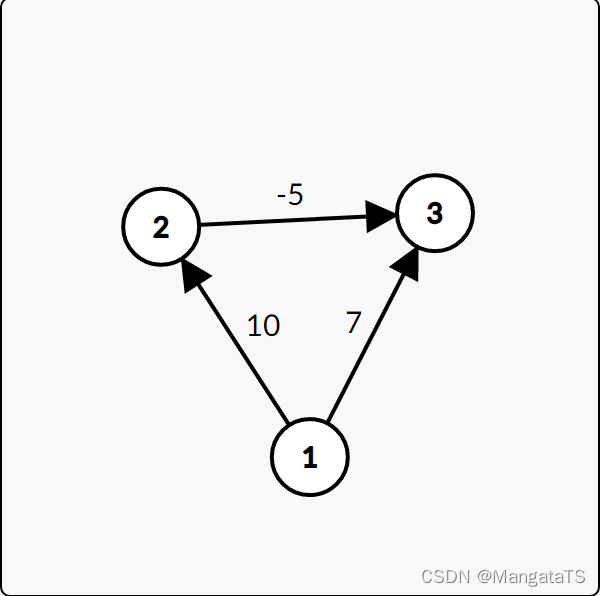
但是我们稍加变换,迪杰斯特拉就不能处理了:
D i j k s t r a Dijkstra Dijkstra的核心思想其实就是贪心思想,每次寻找一个临近点的dis值最小的点,然后我们再来对该点进行松弛操作
将结点分成两个集合:已确定最短路长度的点集(记为 S S S集合)的和未确定最短路长度的点集(记为 T T T集合)。一开始所有的点都属于 T T T集合。
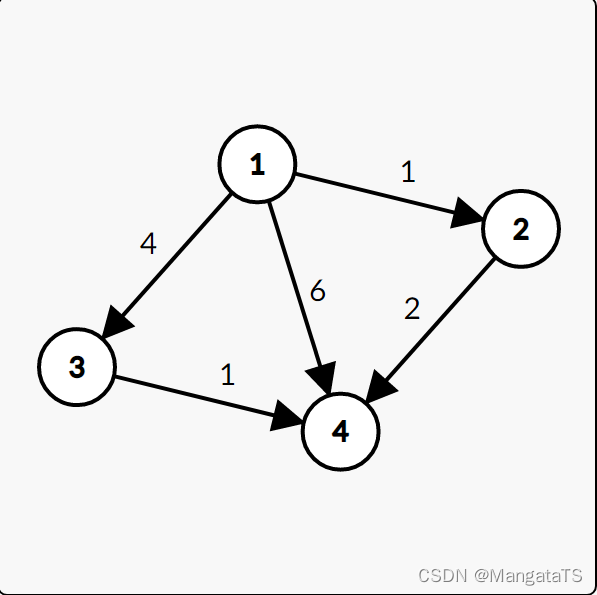
| T集合元素 | S集合元素 | 当前松弛操作 |
|---|---|---|
| { 2 , 3 , 4 } \{2,3,4\} {2,3,4} | { 1 } \{1 \} {1} | dis[1] = 0,dis[2]=1,dis[3]=4,dis[4]=6 |
| { 3 , 4 } \{3,4 \} {3,4} | { 1 , 2 } \{1,2\} {1,2} | dis[4] = 3 |
| { 3 } \{ 3\} {3} | { 1 , 2 , 4 } \{1,2,4\} {1,2,4} | 无 |
| ∅ \varnothing ∅ | { 1 , 2 , 3 , 4 } \{1,2,3,4\} {1,2,3,4} | 无 |
那么最终我们的dis值就变成了:
d i s [ 1 ] = 0 d i s [ 2 ] = 1 d i s [ 3 ] = 4 d i s [ 4 ] = 3 dis[1] = 0 \\ dis[2] = 1 \\ dis[3] = 4 \\ dis[4] = 3 dis[1]=0dis[2]=1dis[3]=4dis[4]=3
我们发现,对于寻找 d i s dis dis值最小的点的操作,我们通过不同的方式维护的话那么算法的整体复杂度就会不同
注意的是:在稠密图中通过暴力方式维护效率更好, O ( N 2 ) O(N^2) O(N2),在稀疏图中通过堆优化的方式维护效率更高, O ( ( n + m ) log 2 n ) O((n+m)\log_{2}n) O((n+m)log2n)
d i j k s t r a dijkstra dijkstra 为什么是正确的呢?,当我们存储的所有的边都是正权边时,整个图的最小值不可能再被其他节点更新,所以我们在T集合中寻找dis最小值其实就是再选择全局最小值,也就是贪心的思想
下面用数学归纳法证明,在 所有边权值非负 的前提下,Dijkstra 算法的正确性。
简单来说,我们要证明的,就是在执行 1 操作时,取出的结点 u u u最短路均已经被确定,即满足 D ( u ) = d i s ( u ) D(u)=dis(u) D(u)=dis(u) 。
初始的时候 S = ∅ S=\varnothing S=∅ ,假设成立,接下来使用反证法。
设 u u u点为算法中第一个在加入 S S S集合时不满足 D ( u ) = d i s ( u ) D(u)=dis(u) D(u)=dis(u)的点。因为 s s s点一定满足 D ( u ) = d i s ( u ) = 0 D(u)=dis(u)=0 D(u)=dis(u)=0,且它一定是第一个加入 S S S集合的点,因此将 u u u加入 S S S集合前 S ! = ∅ S != \varnothing S!=∅,如果不存在 s s s到 u u u的路径,则 D ( u ) = d i s ( u ) = + ∞ D(u)=dis(u)=+∞ D(u)=dis(u)=+∞ ,与假设矛盾。
于是一定存在路径 s − > x − > y − > u s->x->y->u s−>x−>y−>u,其中y为 s − > u s->u s−>u路径上第一个属于 T T T集合的点,而 x x x为 y y y的前驱节点(显然x∈S)。需要注意的是,可能存在 s = x s=x s=x或者 y = u y=u y=u的情况,即 s − > x s->x s−>x或者 y − > u y->u y−>u是一个不存在的路径
因为在 u u u结点之前加入的结点都满足 D ( u ) = d i s ( u ) D(u)=dis(u) D(u)=dis(u),所以在 x x x点加入到 S S S集合时,有 D ( u ) = d i s ( u ) D(u)=dis(u) D(u)=dis(u),此时边 ( x , y ) (x,y) (x,y)会被松弛,从而可以证明,将 u u u加入到 S S S时,一定有 D ( y ) = d i s ( y ) D(y)=dis(y) D(y)=dis(y)。
下面证明 D ( u ) = d i s ( u ) D(u)=dis(u) D(u)=dis(u)成立。在路径 s − > x − > y − > u s->x->y->u s−>x−>y−>u中,因为图上所有边边权非负,因此 D ( y ) < = D ( u ) D(y)<= D(u) D(y)<=D(u)。从而 d i s ( y ) < = D ( y ) < = D ( u ) < = d i s ( u ) dis(y)<=D(y)<=D(u)<=dis(u) dis(y)<=D(y)<=D(u)<=dis(u)。但是因为 u u u结点在2 过程中被取出 T T T集合时, y y y结点还没有被取出 T T T集合,因此此时有 d i s ( u ) < = d i s ( y ) dis(u)<=dis(y) dis(u)<=dis(y),从而得到 d i s ( y ) = D ( y ) = D ( u ) = d i s ( u ) dis(y)=D(y)=D(u)=dis(u) dis(y)=D(y)=D(u)=dis(u),这与 D ( u ) ! = d i s ( u ) D(u)!=dis(u) D(u)!=dis(u)的假设矛盾,故假设不成立。
因此我们证明了,2 操作每次取出的点,其最短路均已经被确定。命题得证。
模板题:https://ac.nowcoder.com/acm/contest/27274/E
#include<cstdio>
#include<algorithm>
#include<vector>
#include<iostream>
#include<cstring>
using namespace std;
#define INF 0x3f3f3f3f
const int N = 1e3+10;
int f[N][N],n,m,dis[N];
bool vis[N];
void DJ(int s){
for(int i = 1;i <= n; ++i) dis[i] = INF,vis[i] = false;
dis[s] = 0;
for(int i = 1;i <= n; ++i) {
int t = -1;
for(int j = 1;j <= n; ++j)
if(!vis[j] && (t == -1 || dis[j] < dis[t])) t = j;
if(t == -1) return;
vis[t] = true;
for(int j = 1;j <= n; ++j)
if(dis[j] > dis[t] + f[t][j])
dis[j] = dis[t] + f[t][j];
}
}
int main()
{
int s,t;
cin>>n>>m>>s>>t;
int u,v,w;
memset(f,0x3f,sizeof f);
for(int i = 1;i <= m; ++i){
cin>>u>>v>>w;
f[v][u] = f[u][v] = min(f[u][v],w);
}
DJ(s);
if(dis[t] == INF) cout<<"-1"<<endl;
else cout<<dis[t]<<endl;
return 0;
}
#include<cstdio>
#include<algorithm>
#include<vector>
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
#define endl "\n"
#define PII pair<int,int>
#define INF 0x3f3f3f3f
const int N = 2e6+10;
int dis[N],n,m;
bool vis[N];
vector<PII> E[N];
void DJ(int s){
for(int i = 1;i <= n; ++i) dis[i] = INF,vis[i] = false;
priority_queue<PII,vector<PII>,greater<PII> > que;
que.push({0,s});
dis[s] = 0;
while(!que.empty()){
int t = que.top().second;
que.pop();
if(vis[t]) continue;
vis[t] = true;
for(int i = 0,l = E[t].size();i < l; ++i) {
int j = E[t][i].first,w = E[t][i].second;
if(dis[j] > dis[t] + w){
dis[j] = dis[t] + w,que.push({dis[j],j});
}
}
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int s,t;
cin>>n>>m>>s>>t;
int u,v,w;
for(int i = 1;i <= m; ++i){
cin>>u>>v>>w;
E[u].push_back({v,w});
E[v].push_back({u,w});
}
DJ(s);
if(dis[t] == INF) cout<<"-1"<<endl;
else cout<<dis[t]<<endl;
return 0;
}
#include<cstdio>
#include<cstring>
#include<queue>//
using namespace std;
const int N=2e5+5;//数据范围
struct edge{//存储边
int u,v,w,next;//u为起点,v为终点,w为权值,next为前继
};
edge e[N];
int head[N],dis[N],n,m,s,cnt;//head为链中最上面的,dis表示当前答案,n为点数,m为边数,s为起点,cnt记录当前边的数量
bool vis[N];//vis表示这个点有没有走过
struct node{
int w,to;//w表示累加的权值,to表示到的地方
bool operator <(const node &x)const{//重载“<”号
return w>x.w;
}
};
priority_queue<node>q;//优先队列(堆优化)
void add(int u,int v,int w){
++cnt;//增加边的数量
e[cnt].u=u;//存起点
e[cnt].v=v;//存终点
e[cnt].w=w;//存权值
e[cnt].next=head[u];//存前继
head[u]=cnt;//更新链最上面的序号
}//链式前向星(加边)
void Dijkstra(){
memset(dis,0x3f3f3f3f,sizeof(dis));//初始化,为dis数组附一个极大值,方便后面的计算
dis[s]=0;//起点到自己距离为0
q.push(node{0,s});//压入队列
while(!q.empty()){//队列不为空
node x=q.top();//取出队列第一个元素
q.pop();//弹出
int u=x.to;//求出起点
if(vis[u]) continue;//已去过就不去了
vis[u]=true;//标记已去过
for(int i=head[u];i;i=e[i].next){
int v=e[i].v;//枚举终点
if(dis[v]>dis[u]+e[i].w){//若中转后更优,就转
dis[v]=dis[u]+e[i].w;//更新
q.push(node{dis[v],v});//压入队列
}
}
}
}
int main(){
int u,v,w = 1;
s = 1;
scanf("%d%d",&n,&m);//输入
for(int i=1;i<=m;++i){
scanf("%d%d",&u,&v);
add(u,v,w);
add(v,u,w);
}
Dijkstra();//DJ
printf("%d\n",dis[n]);//输出1-n的最短路
return 0;
}
我们可以定义一个 p r e pre pre数组,然后 p r e [ i ] pre[i] pre[i]记录的是上一个位置是哪一个节点,当然初始的时候我们全部初始化为 − 1 -1 −1,然后每次松弛操作的时候就更新一下上一个节点的位置,你有没有发现这就是链式前向星,然后最后打印的时候要么递归打印,那么手动写栈打印,这个方法不只是适用于Dijkstra,而且也适用于其他最短路算法,如 S P F A SPFA SPFA、 b e l l m a n _ f o r d bellman\_ford bellman_ford、 F l o y d Floyd Floyd等等
那么简单描述一下打印函数
void print(int t){
for(int i = t;~i;i=pre[i]){
cout<<i;
if(i != s) cout<<" -> ";
}
}
其实我们在松弛操作的时候就能记录or更新从源点到当前点的路径条数,模板题可以参见下面的:最短路计数
待补充
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我正在尝试计算由二进制形式的1和0的P数表示的数字的数量。如果P=2,则表示的数字为0011、1100、0110、0101、1001、1010,所以计数为6。我试过:[0,0,1,1].permutation.to_a.uniq但这不是大数的最佳解决方案(P可以什么可能是最好的排列技术,或者我们是否有任何直接的数学来做到这一点? 最佳答案 Numberofpermutationcanbecalculatedusingfactorial.a=[0,0,1,1](1..a.size).inject(:*)#=>4!=>24要计算重复项,