
简单理解,就是在不前网页下,试图访问另外一个不同域名下的资源时,受到浏览器同源策略的限制,而无法正常获取数据的情况;
同源策略是浏览器出于安全考虑而制定的一种限制资源访问的规则,即协议、域名、端口都相同的两个资源地址属于同源任意一项不同就视为非同源;同源策略的限制就是浏览器要求只有相同的协议、域名、端口之下的资源可以互相访问,不符合同源策略要求的访问给予限制;
跨域场景举例:
URL | 说明 | 是否允许访问 |
http://www.fanfu.com/a.js http://www.fanfu.com/b.js | 同一协议、域名、端口 | 允许 |
http://www.fanfu.com:8080/a.js http://www.fanfu.com:8081/b.js | 同一协议、域名,不同端口 | 不允许 |
http://www.fanfu.com:8080/a.js http://www.fanfu2.com:8080/b.js | 同一协议、端口,不同域名 | 不允许 |
http://www.fanfu.com:8080/a.js https://www.fanfu.com:8080/b.js | 同一域名、端口,不同协议 | 不允许 |
http://www.fanfu.com:8080/a.js http://www.fanfu2.com:8081/b.js | 同一协议,不同域名、端口 | 不允许 |
http://www.fanfu.com:8080/a.js https://www.fanfu.com:8081/b.js | 同一域名,不同协议、端口 | 不允许 |
http://www.fanfu.com:8080/a.js https://www.fanfu2.com:8080/b.js | 同一端口,不同协议、域名 | 不允许 |
http://www.fanfu.com:8080/a.js https://www.fanfu2.com:8081/b.js | 协议、域名、端口都不同 | 不允许 |
跨域访问问题的出现,起因于浏览器的同源策略,然而事情的事相是跨域请求可以发出去,服务器端也可以收到请求并返回正常的结果,只是最终的响应结果被浏览器拦截了。如今是什么形形势了?前后端分离,分布式部署、微服务等如雨后春笋般出现了,都有跨域访问的需要,同源策略限制,似乎有点不合时宜。那么解决这个问题的思路是什么呢?
其实理解了什么是同源策略以及跨域问题出现的原因,解决思路也就再明显不过了。既然是前端发起请求后,后端收到请求也处理了请求并响应了结果,只是浏览器把结果给拦截了,那么最直接的想法就是在前端绕过同源策略限制,怎么绕过去呢?html中有三个标签img标签、link标签、script标签是允许跨域加载资源的,因此最早跨域问题的解决是利用script标签没有跨域限制的漏洞来实现,但是这种方法局限性太大了,仅支持get请求。
不能看着前端兄弟如此难受呀,后端兄弟申请出战!
后端其实也没有什么太好的办法,从原理上讲就是修改响应头,具体到Springboot项目中,实施起来是有三种方式可以选,分别是:
1、自定义org.springframework.web.filter.CorsFilter;
@Bean
public CorsFilter corsFilter(){
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedHeader("*");//允许跨域的请求头
corsConfiguration.addAllowedOrigin("*");//允许的域名,*表示所有,也可以是具体的域名
corsConfiguration.addAllowedMethod("*");//允许跨域的请求
corsConfiguration.setAllowCredentials(true);//允许跨域标志位
UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new UrlBasedCorsConfigurationSource();
urlBasedCorsConfigurationSource.registerCorsConfiguration("/**",corsConfiguration);//对哪些路径进行跨域设置,**表示所有
CorsFilter corsFilter = new CorsFilter(urlBasedCorsConfigurationSource);
return corsFilter;
}2、实现org.springframework.web.servlet.config.annotation.WebMvcConfigurer接口,重写addCorsMappings();
@Configuration
class CorsFilterConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")//对哪些路径进行跨域设置,**表示所有
.allowCredentials(true)//允许跨域标志位
.allowedHeaders("/*")//允许跨域的请求头
.allowedMethods("GET","POST","PUT","DELETE")//允许跨域的请求
.allowedOrigins("*");//允许的域名,*表示所有,也可以是具体的域名
}
}3、@CrossOrigin注解里有一些属性,也可以设置一些跨域配置参数;
@GetMapping("/students")
@CrossOrigin
public List<Student> studentList(Student param) {
List<Student> result = new ArrayList<>();
//列表查询业务逻辑
Student student = new Student();
student.setName("张三");
result.add(student);
student = new Student();
student.setName("李四");
result.add(student);
return result;
}1、启动两个Springboot示例,端口分别是8080和8081,是不是有人还不知道怎么使用idea同时启动两个实例?很简单!定义两个启动配置项,分别设置端口为8080和8081,这里设置的端口优先级比application.properties里的端口要高;
2、在resources下的static目录下,新建cross.html文件,打开http://localhost:8081/cross.html,不会出现跨域访问,因为协议、域名、端口都一样;打开http://localhost:8080/cross.html,就会出现跨域问题,因为http://localhost:8080/cross.html请求了http://localhost:8081/students的内容,端口不一样;
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script type="text/javascript" src="https://code.jquery.com/jquery-3.1.1.min.js"></script>
<script type="text/javascript" src="lib/require.js"></script>
</head>
<body>
<div id="testContent">
</div>
</body>
<script type="text/javascript">
$.ajax({
url: 'http://localhost:8081/students',
method: 'get',
success: function (res) {
console.log(res)
if (res) {
res.forEach(function (item, index, res) {
console.log(item.name)
$('#testContent').append('<p>' + item.name + '</p>')
})
}
}
})
</script>
</html>
@GetMapping("/students")
// @CrossOrigin
public List<Student> studentList(Student param) {
List<Student> result = new ArrayList<>();
//列表查询业务逻辑
Student student = new Student();
student.setName("张三");
result.add(student);
student = new Student();
student.setName("李四");
result.add(student);
return result;
}3、傅用上述的三种方法依次来验证,就可以从后端来解决跨域的问题;
换作以前,前后端还没有分家,后端兄弟这么做基本没什么问题,如今前后端分离,前端的能力的多元化,且日趋成熟,所谓前端早已不是传统意义上的前端,js程序不光可以运行在浏览器,还可以运行在后端服务器上,前端的问题还让后端的兄弟来解决,前端的兄弟们多少有点于心不忍,于是新的方法产生了:在前端构造起一个代理服务,页面上请求先到前端的代理服务上,再由代理服务转发到后端服务器上;
实现原理也很简单:同源策略是浏览器需要遵循的标准,而如果是服务器向服务器发送请求就不需要遵循同源策略了,这就变相绕过了浏览器的同源策略限制。
具体实施就是:1、在客服端构建一个代理服务,客户端的请求不直接请求后端接口,而是请求客户端构建的代理服务;
2、代理服务作为同源的代理服务端收到客户端的请求后,再以客户端的身份把请求转发到后端;
3、后端处理完请求返回响应结果,给了代理服务,代理服务再转给实际请求方;
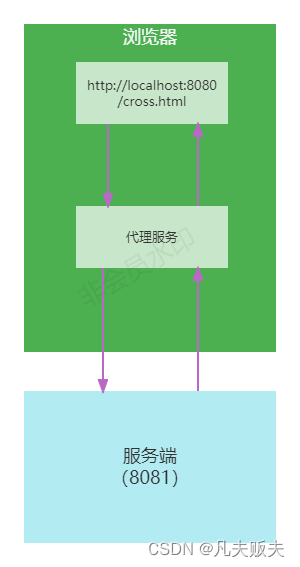
另外一个方法也是同样的原理,就是使用nginx反向代理实现跨域,这是最简单的方式,目前大多的实际业务场景中都是这种方式,只需要修改nginx的相关配置即可,支持所有的浏览器、支持session,不需要修改前后端的任何代码,并且也不会影响服务器性能。
既然使用nginx作为反向代理来解决跨域问题最为简单,为什么还要说后端怎么解决、前端怎么解决呢?不知道大家能不能理解,我认为过去的方法或许有些落后,但是还是有参考意义的,了解过去,知道现在,才能展望未来嘛,有句话说得挺好,日光之下并无新事。即便nginx今天是最简单的方式,谁又能保证到了明天的明天,现在的方式会依旧先进?
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
所以我开始关注ruby,很多东西看起来不错,但我对隐式return语句很反感。我理解默认情况下让所有内容返回self或nil但不是语句的最后一个值。对我来说,它看起来非常脆弱(尤其是)如果你正在使用一个不打算返回某些东西的方法(尤其是一个改变状态/破坏性方法的函数!),其他人可能最终依赖于一个返回对方法的目的并不重要,并且有很大的改变机会。隐式返回有什么意义?有没有办法让事情变得更简单?总是有返回以防止隐含返回被认为是好的做法吗?我是不是太担心这个了?附言当人们想要从方法中返回特定的东西时,他们是否经常使用隐式返回,这不是让你组中的其他人更容易破坏彼此的代码吗?当然,记录一切并给出
给定以下方法:defsome_method:valueend以下语句按我的预期工作:some_method||:other#=>:valuex=some_method||:other#=>:value但是下面语句的行为让我感到困惑:some_method=some_method||:other#=>:other它按预期创建了一个名为some_method的局部变量,随后对some_method的调用返回该局部变量的值。但为什么它分配:other而不是:value呢?我知道这可能不是一件明智的事情,并且可以看出它可能有多么模棱两可,但我认为应该在考虑作业之前评估作业的右侧...我已经在R
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我在我的Rails3示例应用程序上使用CarrierWave。我想验证远程位置上传,因此当用户提交无效URL(空白或非图像)时,我不会收到标准错误异常:CarrierWave::DownloadErrorinImageController#createtryingtodownloadafilewhichisnotservedoverHTTP这是我的模型:classPaintingtrue,:length=>{:minimum=>5,:maximum=>100}validates:image,:presence=>trueend这是我的Controller:classPaintingsC