🎉博客首页:痛而不言笑而不语的浅伤
📢欢迎关注🥳点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
🔮本文由痛而不言笑而不语的浅伤原创,CSDN首发!
🌋系列专栏:《学习经验》
🧿首发时间:2022年5月10日
❤:热爱Java学习,期待一起交流!
🙏🏻作者水平有限,如果发现错误,求告知,多谢!
🥰有问题可以私信交流!!!
目录
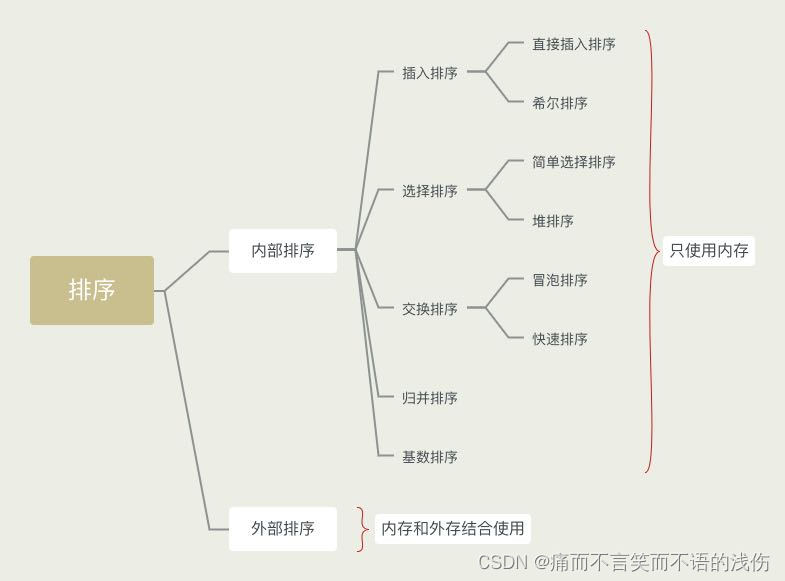
分为5大类:
1.插入排序(直接插入排序、希尔排序)。
2.交换排序(冒泡排序、快速排序)。
3.选择排序(直接选择排序、堆排序)。
4.归并排序。
5.分配排序(箱排序、基数排序)。
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。

1.数据的规模;
2.数据的类型;
3.数据已有的顺序。
一般来说,当数据规模较小时,应选择直接插入排序或冒泡排序。任何排序算法在数据量小时基本体现不出来差距。考虑数据的类型,比如如果全部是正整数,那么考虑使用桶排序为最优。考虑数据已有顺序,快排是一种不稳定的排序(当然可以改进),对于大部分排好的数据,快排会浪费大量不必要的步骤。数据量极小,而起已经基本排好序,冒泡是最佳选择。我们说快排好,是指大量随机数据下,快排效果最理想。而不是所有情况。
1.直接插入排序。
2.希尔插入排序。
说明
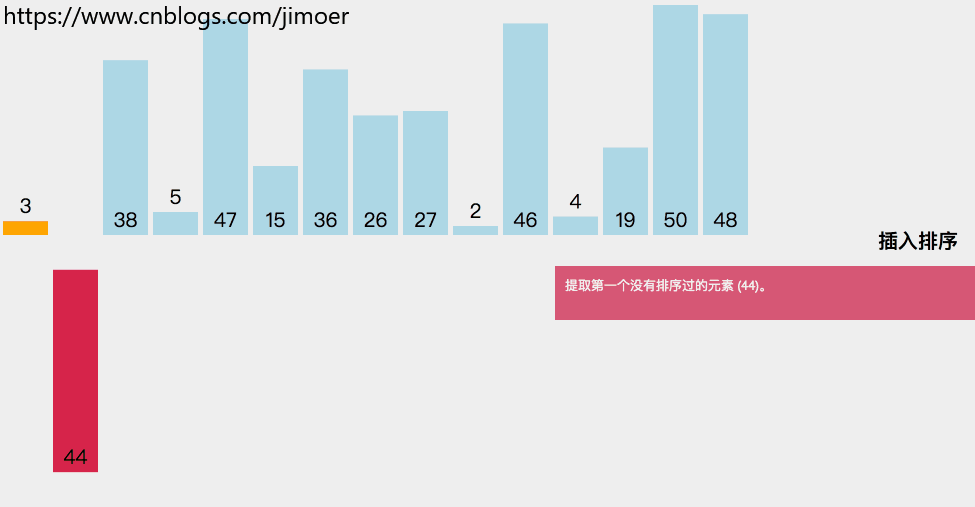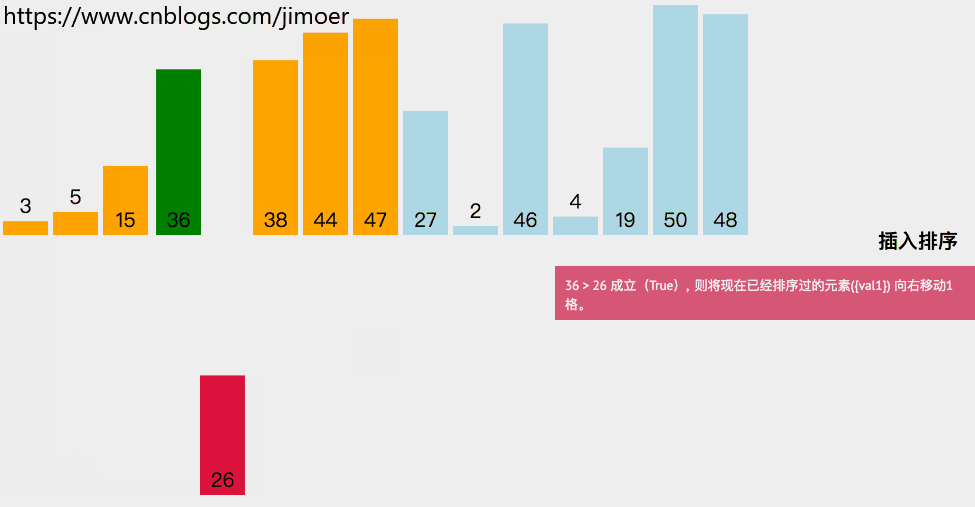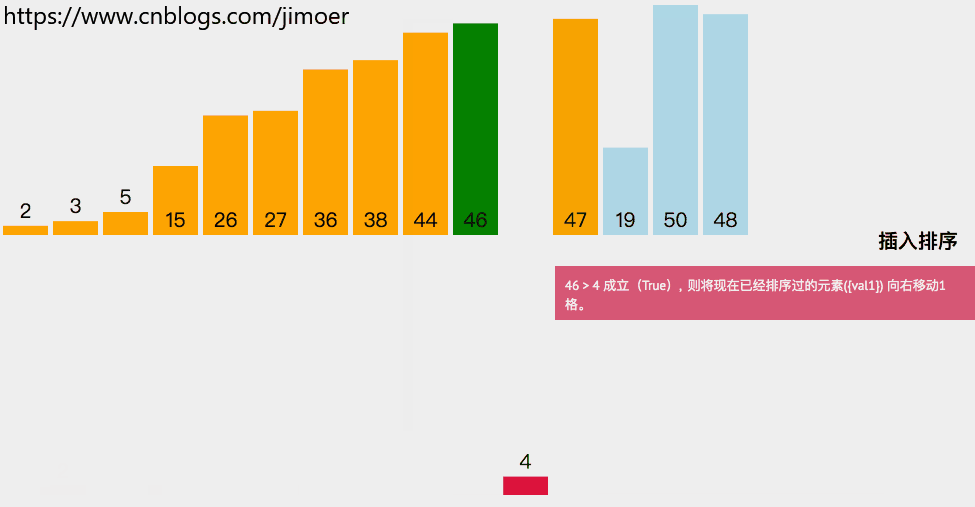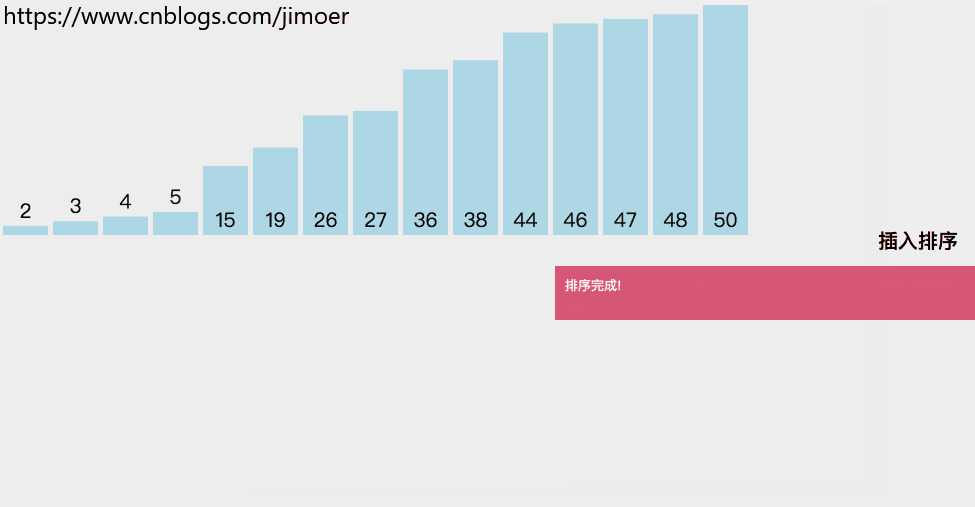
将一个记录插入到已经排序好的有序表中。
1.sorted数组的第0个位置没有放数据。
2.从sorted第二个数据开始处理。
如果该数据比它前面的数据要小,说明该数据要往前面移动。
用法
a.首先将该数据备份放到sorted的第0位置当哨兵。
b.然后将该数据前面那个数据后移。
c.然后往前搜索,找插入位置。
d.找到插入位置之后讲第0位置的那个数据插入对应位置。
O(n*n),当待排记录序列为正序时,时间复杂度提高至O(n)。
实例:

1.先将整个待排记录序列分割成若干个子序列分别进行直接插入排序。
2.待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
实例:

插入排序Java代码:
public class InsertionSort{
//插入排序:直接插入排序,希尔排序
public void straightInsertionSort(double[]sorted){
int sortedLen=sorted.length;
for(intj=2;j<sortedLen;j++){
if(sorted[i]<sorted[j-1]){
sorted[0]=sorted[i];//先保存一下后面的那个
sorted[i]=sortedj-1];//前面的那个后移。
int insertPos=0;
for(int k=j-2;k>=0;k--){
if(sorted[k]>sorted[0]){
sorted[k+1]=sorted[k];
}else{
insertPos=k+1;
break;
}
}
sorted[insertPos]=sorted[0];
}
}
}
public void shellInertionSort(double[] sorted, int inc){
int sortedLen=sorted.length;
for(intj=inc+1:j<sortedLen;j++){
if(sorted[i]<sorted[j-inc]){
sorted[0]=sorted[i];//先保存一下后面的那个
int insertPosj;
for(int k=j-inc;k>=0;k-=inc){
if(sorted[k]>sorted[0]){
sorted[k+inc]=sorted[k];//数据结构课本上这个地方没有给出判读出错:
if(k-inc<=0){
insertPos=k;
}
}else{
insertPos=k+inc;
break;
}
}
sorted[insertPos]=sorted[0];
}
}
}
public void shellInsertionSort(double[] sorted){
int[]incs={7,5,3,1};
int num=incs.length;
int inc=0;
for(int j=0;j<num;j++){
inc= incs[j];
shellInertionSort(sorted,inc);
}
}
public static void main(String[]args){
Random random=new Random(6);
int arraysize=21;
double[]sorted=new double[arraysize];
System.out.print("Before Sort:");
for(int j=1;j<arraysize;j++){
sorted[i]=(int)(random.nextDouble()*100);
System.out.print((int)sorted[j]+"");
}
System.out.println();
InsertionSort sorter=new InsertionSort();
// sorter.straightInsertionSort(sorted);
sorter.shellInsertionSort(sorted);
System.out.print("After Sort:");
for(intj=1;j<sorted.length;j++){
System.out.print((int)sorted[j]+"");
}
System.out.println();
}
}
1.冒泡排序。
2.快速排序。
该算法是专门针对已部分排序的数据进行排序的一种排序算法。如果在你的数据清单中只有一两个数据是乱序的话,用这种算法就是最快的排序算法。如果你的数据清单中的数据是随机排列的,那么这种方法就成了最慢的算法了。因此在使用这种算法之前一定要慎重。这种算法的核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。

通过一趟排序,将待排序记录分割成独立的两个部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。具体做法是:使用两个指针lowhigh,初值分别设置为序列的头,和序列的尾,设置pivotkey为第一个记录,首先从high开始向前搜索第一个小于pivotkey的记录和pivotkey所在位置进行交换,然后从low开始向后搜索第一个大于pivotkey的记录和此时pivotkey所在位置进行交换,重复知道low=high了为止。

冒泡排序Java代码:
public class bubbleSort {
public bubbleSortO(){
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
int temp=0;
for(int i=0;i<a.length-1;i++){
for(int j=0;j<a.length-1-i;j++){
if(a[i]>a[j+1]){
temp=a[i];
a[i]=a[j+1];
a[j+1]=temp;
}
}
}
for(int i=0;i<a.length;i++){
System.out.println(a[i]);
}
}
}快速排序Java代码:
public class quickSort {
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
public quickSortO{ quick(a);
for(int i=0;i<a.length;i++){
System.outprintln(a[i]);
}
public int getMiddle(int list int low int high){
int tmp=list[low];//数组的第一个作为中轴
while(low<high) {
while(low<high &&list[high]>=tmp){
high--;
}
list[low]=list[high];//比中轴小的记录移到低端
while(low<high&&list[low]<=tmp){
low++;
}
list[high]=list[low];//比中轴大的记录移到高端
list[low]=tmp;//中轴记录到尾 return low;//返回中轴的位置
}
public void _quickSort(int[]list, int low int high){
if(low<high){
int middle=getMiddle(listlowhigh);//将list数组进行一分为二
quickSort(list,lowmiddle-1);//对低字表进行递归排序
quickSort(list,middle+1high);//对高字表进行递归排序
}
}
public void quick(int[] a2){
if(a2.length>0){//查看数组是否为空
quickSort(a2,0,a2.length-1);
}
}
}
1.直接选择排序。
2.堆排序
第i次选取到arrayLength-1中间最小的值放在i位置。

首先,数组里面用层次遍历的顺序放一棵完全二叉树。从最后一个非终端结点往前面调整,直到到达根结点,这个时候除根节点以外的所有非终端节点都已经满足堆得条件了,于是需要调整根节点使得整个树满足堆得条件,于是从根节点开始,沿着它的儿子们往下面走(最大堆沿着最大的儿子走,最小堆沿着最小的儿子走)。主程序里面,首先从最后一个非终端节点开始调整到根也调整完,形成一个heap,然后将heap的根放到后面去(即:每次的树大小会变化,但是root都是在1的位置,以方便计算儿子们的index,所以如果需要升序排序,则要逐步大顶堆。因为根节点被一个个放在后面去了,降序排序则要建立小顶堆。
实例:
初始序列:46,79,56,38,40,84
建堆:

交换从堆中踢出最大数

剩余结点再建堆,再踢出最大数

依次类推:最后堆中剩余的最后两个结点交换踢出一个,排序完成。
代码中的问题:有时候第2个和第3个顺序不对(原因还没搞明白到底代码哪里有错)
选择排序Java代码:
public class selectSort {
public selectSort(){
int a[]={1,54,6,3,78,34,12,45};
int position=0;
for(int i=0;i<a.length;i++){
int j=i+1;
position=i;
int temp=a[i];
for(;j<a.length;j++){
if(a[i]<temp){
temp=a[i];
position=j;
}
}
a[position]=a[i];
a[i]=temp;
}
for(int i=0;i<a.length;i++) {
System.outprintln(a[1]);
}
}
}堆排序代码:
importjava.util.Arrays;
public class HeapSort {
int a[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};
public HeapSort(){
heapSort(a);
}
public void heapSort(int[]a{
System.outprintln("开始排序");
int arraylength=a.length;//循环建堆
for(int i=0;i<arrayLength-1;i++){
//建堆
buildMaxHeap(a,arrayLength-1-i);
//交换堆顶和最后一个元素
swap(a,0,arrayLength-1-i);
System.outprintln(Arrays.toString(a));
}
}
private void swap(int[] data, int i,int j){
// TODO Auto-generated method stub
int tmp=data[i];
data[i]=data[i];
data[j]=tmp;
}
//对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(int] data,int lastIndex){
//TODO Auto-generated method stub
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//K保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//如果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}else{
break;
}
}
}
}将两个或两个以上的有序表组合成一个新的有序表。归并排序要使用一个辅助数组,大小跟原数组相同,递归做法。每次将目标序列分解成两个序列,分别排序两个子序列之后,再将两个排序好的子序列merge到一起。

归并排序Java代码:
public class MergeSort {
private double[]bridge;//辅助数组
public void sort(double[] obj){
if(obj==null){
throw new NullPointerException("The param can not be null!");
}
bridge=new double[obj.length];//初始化中间数组
mergeSort(obj,,obj.length-1);//归并排序
bridge =null;
}
private void mergeSort(double[] obj,int left,int right){
if(left<right){
int center=(left+right)/2; mergeSort(obj,left,center);
mergeSort(obj,center+1,right) merge(obj,left,center, right);
}
}
private void merge(double[] obj,int left,int center, int right){
intmid=center+1;
int third=left;
int tmp=left;
while(left<=center && mid<=right){
//从两个数组中取出小的放入中间数组
if(obj[left]-obj[mid]<=10e-6){
bridge[third++]=obj[left++];
} else{
bridge[third++]=obj[mid++];
}
}
//剩余部分依次置入中间数组
while(mid<=right){
bridge[third++]=obj[mid++];
}
while(left<=center){
bridge[third++]=obj[left++];
}
/将中间数组的内容拷贝回原数组
copy(obj, tmp, right);
}
private void copy(double[]obj,int left, int right){
while (left <= right){
obj[left] = bridge[left];
left++;
}
}
public static void main(String[] args){
Random random=new Random(6);
int arraysize=10;
double[] sorted=new double[arraysize];
System.outprint("Before Sort:");
for(intj=0;j<arraysize;j++) {
sorted[i]=(int)(random.nextDouble()*100);
System.outprint((int)sorted[i]+"");
}
System.outprintln();
MergeSort sorter=new MergeSort();
sorter.sort(sorted);
System.out.print("After Sort:");
for (intj=0;j<sorted.length;j++){
System.out.print((int) sorted[i]+"");
}
System.outprintln();
}
}使用10个辅助队列,假设最大数的数字位数为 x,则一共做x次,从个位数开始往前,以第i位数字的大小为依据,将数据放进辅助队列,搞定之后回收。下次再以高一位开始的数字位为依据。

以Vector作辅助队列,基数排序的Java代码:
public class RadixSort {
private int keyNum=-1;
private Vector<Vector<Double>> util;
public void distribute(double []sorted,int nth){
if(nth<=keyNum && nth>0){
util=new Vector<Vector<Double>>();
for(intj=0;j<10;j++){
Vector <Double>temp=new Vector<Double>();
util.add(temp);
}
for(int j=0;j<sorted.length;j++){
int index=getNthDigit(sorted[i],nth);
util.get(index).add(sorted[j]);
}
}
}
public int getNthDigit(double num,int nth){
String nn=Integer.toString((int)num);
int len=nn.length();
if(len>=nth){
return CharactergetNumericValue(nncharAt(len nth));
}else{
return 0;
}
}
public void collect(double[]sorted){
int k=0;
for(int j=0;j<10;j++){
int len=util.get(j).size();
if(len>0){
for(int i=0;i<len;i++){
sorted[k++]=utilget(i).get(i);
}
}
}
util=null;
}
public int getKeyNum(double[] sorted){
double max=Double.MIN VALUE:;
for(int j=0;j<sorted.length;j++){
if(sorted[j]>max){
max=sorted [j];
}
}
return Integer.toString((int)max).length();
}
public void radixSort(double[] sorted){
if(keyNum==-1){
keyNum= getKeyNum(sorted);
}
for(int i=1;i<=keyNum;i++){
distribute(sorted,i);
collect(sorted);
}
}
public static void main(String[]args){
Random random=new Random(6);
int arraysize=21;
double[]sorted=new double[arraysize] ;
System.outprint("Before Sort:");
for(intj=0;j<arraysize;j++){
sorted[j]=(int)(random.nextDouble()* 100);
System.outprint((int)sorted[j]+"");
}
System.out.println();
RadixSort sorter=new RadixSort();
sorterradixSort(sorted);
System.out.print("After Sort:")
for(intj=0;j<sorted.length;j++){
System.outprint((int)sorted[j]+" ");
}
System.out.println();
}
}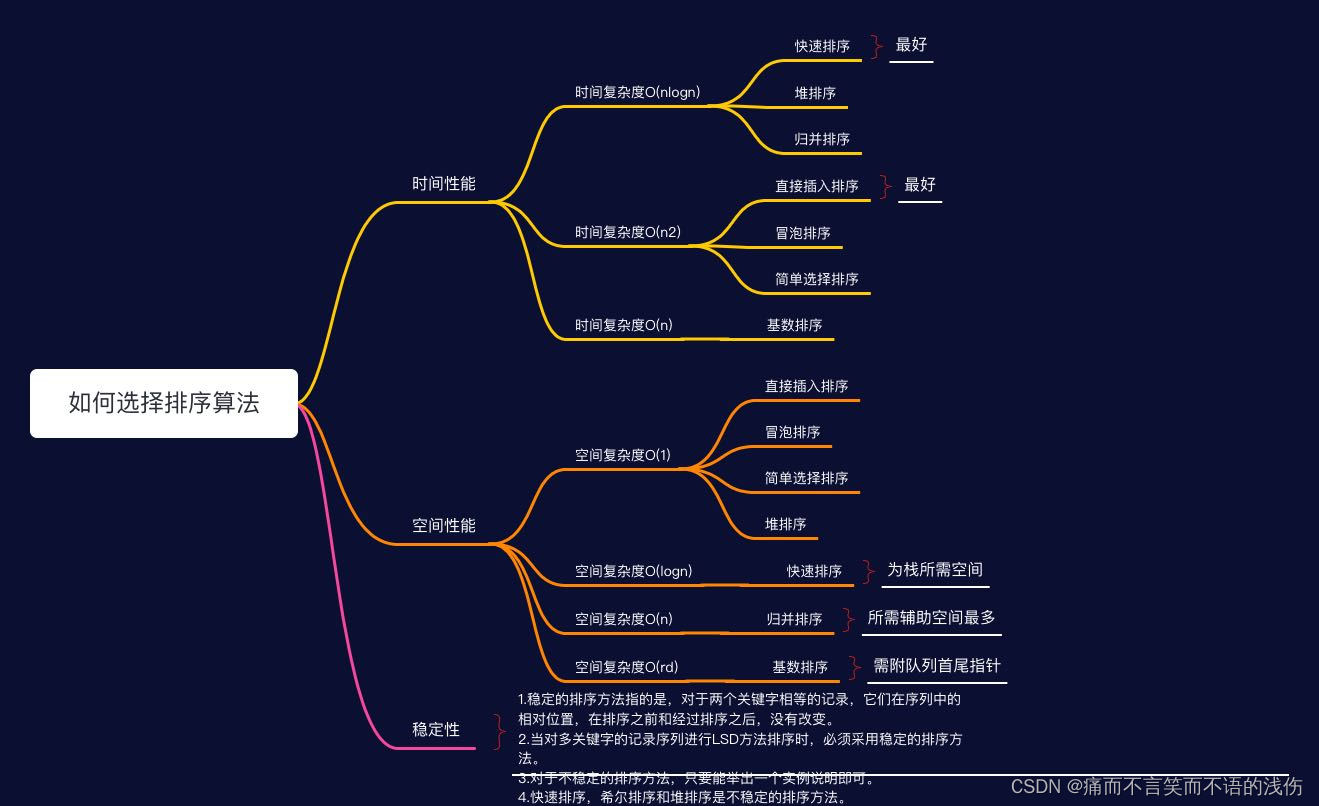
1.时间复杂度为O(nlogn)的方法有:快速排序、堆排序和归并排序,其中以快速排序为最好;
2.时间复杂度为O(n2)的有:直接插入排序、冒泡排序和简单选择排序,其中以直接插入为最好,特别是对那些对关键字近似有序的记录序列尤为如此;
3.时间复杂度为O(n)的排序方法只有,基数排序。
当待排记录序列按关键字顺序有序时,直接插入排序和起泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能蜕化为O(n2),因此是应该尽量避免的情况。简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
(指的是排序过程中所需的辅助空间大小):
1.所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1);
2.快速排序为O(logn),为栈所需的辅助空间;
3.归并排序所需辅助空间最多,其空间复杂度为O(n );
4.链式基数排序需附设队列首尾指针,则空间复杂度为O(rd)。
1.稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。
2.当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。
3.对于不稳定的排序方法,只要能举出一个实例说明即可。
4.快速排序,希尔排序和堆排序是不稳定的排序方法。
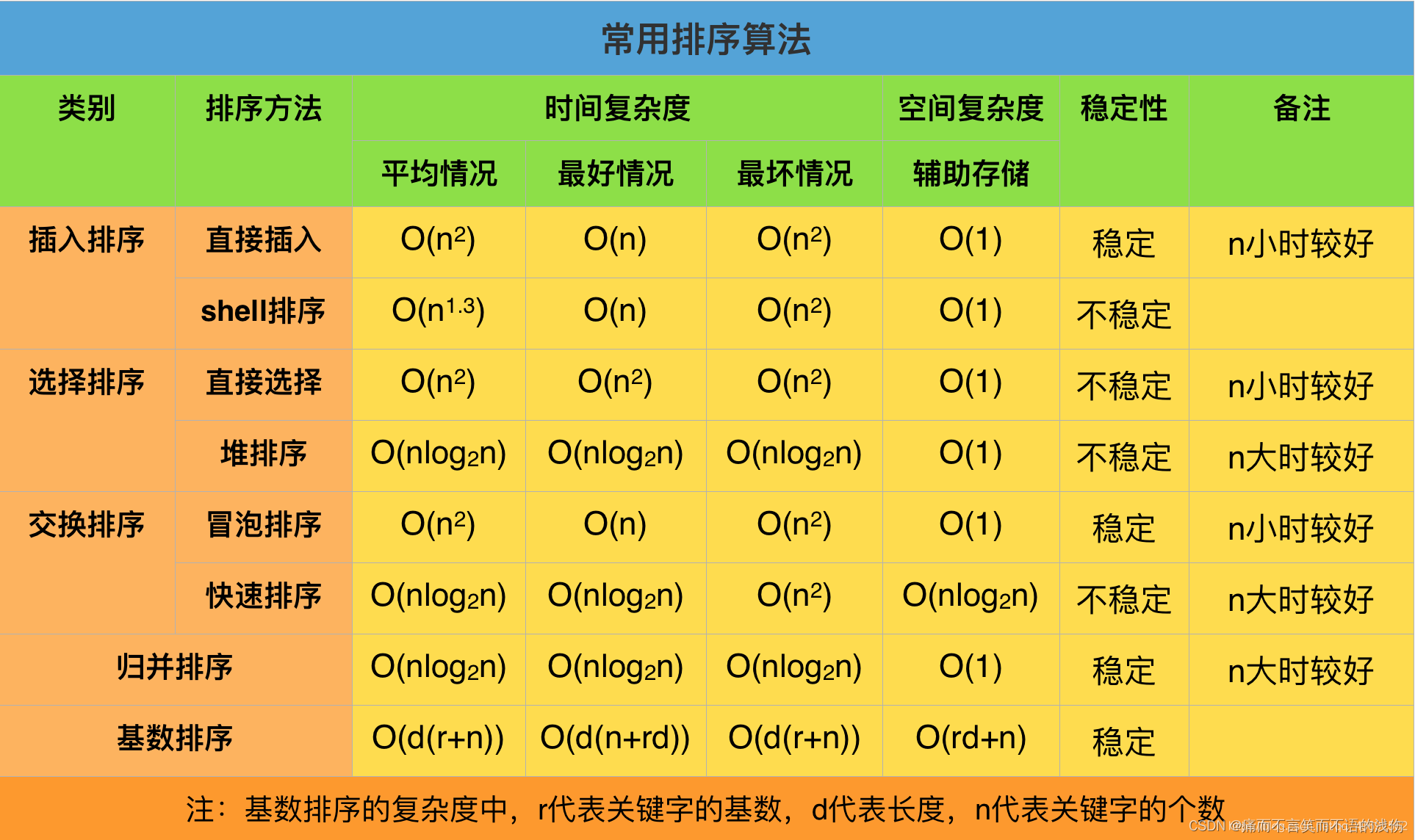
最后,大家重点要掌握每个排序算法的使用方法、还有如何选择,在什么样的情况下用什么的排序算法,以达到效率最好,使用后最优化代码。
好啦!今天的练习就到这里。看吧这么努力的你又学到了很多,新的一天加油鸭!!!
【完】
你的点赞是对我最大的鼓励。
你的收藏是对我文章的认可。
你的关注是对我创作的动力。

我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.