Redis是大规模互联网应用常用的内存高速缓存数据库,它的读写速度非常快,据官方 Bench-mark的数据,它读的速度能到11万次/秒,写的速度是8.1万次/秒。
在很多应用场景中通常是获取前后相同或更新不频繁的数据,比如访问产品信息数据、网页数据。如果没有使用缓存,则访问每次需要重复请求数据库,这会导致大部分时间都耗费在数据库查询和方法调用上,因为数据库进行I/O操作非常耗费时间,这时就可以利用Spring Cache来解决。
Spring Cache是Spring提供的一整套缓存解决方案。它本身并不提供缓存实现,而是提供统 一的接口和代码规范、配置、注解等,以便整合各种Cache方案,使用户不用关心Cache的细节。
Spring支持“透明”地向应用程序添加缓存,将缓存应用于方法,在方法执行前检查缓存中是否有可用的数据。这样可以减少方法执行的次数,同时提高响应的速度。缓存的应用方式“透明”, 不会对调用者造成任何干扰。只要通过注解@EnableCaching启用了缓存支持,Spring Boot就会自动处理好缓存的基础配置。
Spring Cache作用在方法上。当调用一个缓存方法时,会把该方法参数和返回结果作为一个 “键值对”(key/value )存放在缓存中,下次用同样的参数来调用该方法时将不再执行该方法,而是直接从缓存中获取结果进行返回。所以在使用Spring Cache 时,要保证在缓存的方法和方法参数相同时返回相同的结果。
Spring Boot提供的声明式缓存(cache)注解,见表11-1。

图 11-1
标注在入口类上,用于开启缓存。
可以作用在类和方法上,以键值对的方式缓存类或方法的返回值。键可以有默认策略和自定义策略。
@Cacheable注解会先查询是否己经有缓存,如果己有则会使用缓存,如果没有则会执行方法并进行缓存。
@Cacheabfe 可以指定 3 个属性----- value、key 和 condition。
@Cacheable注解的使用方法见以下代码:
@Override
@Cacheable(value = "emp",key = "targetClass + methodName + #p0")
public List<Card> getCardList() {
return cardRepository.findAll();
}代码解释如下。
@CachePut标注的方法在执行前不检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,并将执行结果以键值对的形式存入指定的缓存中。和@Cacheable不同的是, @CachePut每次都会触发真实方法的调用,比如用户更新缓存数据。
需要注意的是,该注解的value和key必须与要更新的缓存相同,即与@Cacheable 相同。 具体见下面两段代码:
@Override
@CachePut(value = "usr",key = "targetClass + #p0")
public Book update(Book book) {
return null;
}
@Override
@Cacheable(value = "usr",key = "targetClass + #p0")
public Book save(Book book) {
return null;
}@CacheEvict用来标注需要清除缓存元素的方法或类。该注解用于触发缓存的清除操作。其属性有value、key、condition、allEntries 和 beforeInvocation。可以用这些属性来指定清除的条件。使用方法如下:
@Override
@Cacheable(value = "usr",key = "#p0.id")
public Book save(Book book) {
return null;
}
@Override
@CacheEvict(value = "usr",key = "#id")
public void delete(int id) {
}
@Override
@CacheEvict(value = "accountCache",allEntries = true)
public void deleteAll() {
}
@Override
@CacheEvict(value = "accountCache",beforeInvocation = true)
public void deleteAll() {
}注解@Caching用来组合多个注解标签,有3个属性:cacheable、put 和 evict,用于指定 @Cacheable、@CachePut 和 @CacheEvict。使用方法如下:
@Override
@Caching(cacheable = {@Cacheable(value = "usr",key = "#p0"),},
put = {@CachePut(value = "usr",key = "#p0"),},
evict = {@CacheEvict(value = "usr",key = "#p0"),})
public Book save(Book book) {
return null;
}本实例展示Spring Cache是如何使用简单缓存(SIMPLE方式)进行缓存管理的。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
<version>2.7.2</version>
</dependency>在application.yml文件中配置目标缓存管理器,支持Ehcache、Generic、Redis、 Jcache 等。这里使用 SIMPLE 方式 "spring: cache: type: SIMPLE”。
在入口类添加注解@EnableCaching,开启缓存功能。
@Service
public class BookServiceImpl implements BookService{
@Autowired
private BookDao bookDao;
@Override
public Book getById(Integer id) {
return bookDao.getById(id);
}
@Override
public void insert(Book book) {
bookDao.insert(book);
}
@Override
@CachePut(value = "usr",key = "targetClass + #p0")
public Book update(Book book) {
return null;
}
@Override
@Caching(cacheable = {@Cacheable(value = "usr",key = "#p0"),},
put = {@CachePut(value = "usr",key = "#p0"),},
evict = {@CacheEvict(value = "usr",key = "#p0"),})
public Book save(Book book) {
return null;
}
@Override
@CacheEvict(value = "usr",key = "#id")
public void delete(int id) {
}
@Override
@CacheEvict(value = "accountCache",allEntries = true)
public void deleteAll() {
}
}上述代码可以看出,查找用户的方法使用了注解@Cacheable来开启缓存。修改和添加方法使用了注解@CachePut。它是先处理方法,然后把结果进行缓存的。要想删除数据,则需要使用注解@CacheEvict来清空缓存。
@EnableCaching
@Controller
public class BookController {
@Autowired
private BookService bookService;
int id = 0;
@RequestMapping("/book")
public String insert(){
Book book = new Book();
book.setUsername("拉行啊");
book.setPassword("123");
String jsonObject = JSON.toJSONString(book);
System.out.println(jsonObject);
book.setJson(jsonObject);
bookService.insert(book);
id = book.getId();
return book.toString();
}
@RequestMapping(value = "/get",method = RequestMethod.GET,produces = "application/json")
public Book get(){
Book book = new Book();
book.setUsername("拉行啊");
book.setPassword("123");
return book;
}
@RequestMapping(value = "/put")
public String put(@RequestParam("upload")MultipartFile file, RedirectAttributes redirectAttributes){
Date date = new Date();
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMdd");
String nyr = dateFormat.format(date);
if (file.getOriginalFilename().endsWith(".jpg")||file.getOriginalFilename().endsWith(".png")||
file.getOriginalFilename().endsWith(".git")){
try {
byte[] bytes = file.getBytes();
String s = nyr+Math.random()+file.getOriginalFilename();
Path path = Paths.get("./"+s);
Files.write(path, bytes);
return "success";
} catch (Throwable e) {
e.printStackTrace();
}
}else {
return "格式不支持";
}
return "error";
}
@RequestMapping(value = "/test")
public String test(Model model) throws Exception{
Book book = new Book();
book.setPassword("123");
model.addAttribute("book",book);
return "test";
}
}Spring Boot支持多种不同的缓存产品。在默认情况下使用的是简单缓存,不建议在正式环境中使用。我们可以配置一些更加强大的缓存,比如Ehcache。Ehcache是一种广泛使用的开源Java分布式缓存,它具有内存和磁盘存储、缓存加载器、缓存扩展、缓存异常处理、GZIP缓存、Servlet过滤器,以及支持REST和SOAP API等特点。
@Service
@CacheConfig(cacheNames = {"userCache"})
public class BookServiceImpl implements BookService{
@Autowired
private BookDao bookDao;
@Override
@Cacheable(value = "usr",key = "targetClass + #p0")
public Page<Book> findAll() {
return bookDao.findAll();
}
}Caffeine是使用Java 8对Guava缓存的重写版本。它基于LRU算法实现,支持多种缓存过期策略。要使用它,需要在pom.xml文件中增加Caffeine依赖,这样Spring Boot就会自动用 Caffeine替换默认的简单缓存。
增加Caffeine依赖的代码如下:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>然后配置参数,见以下代码:
spring:
cache:
type: caffeine
cache-names: myCaffeine
caffeine:
spec: maximumSize=1,expireAfterAccess=5s代码解释如下。
Cache可以和Redis一起用,Spring Boot支持把Cache存到Redis里。如果是单服务器, 则用Cache、Ehcache或Caffeine,性能更高也能满足需求。如果拥有服务器集群,则可以使用 Redis,这样性能更高。
Redis是目前使用最广泛的内存数据存储系统之一。它支持更丰富的数据结构,支持数据持久化、事务、HA (高可用High Available)双机集群系统、主从库。
Redis是key-value存储系统。它支持的value类型包括String、List、Set、Zset (有序集合)和Hash。这些数据类型都支持push/pop、add/remove,以及取交集、并集、差集或更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis支持各种不同方式的排序和算法。
Redis会周期性地把更新后的数据写入磁盘,或把修改操作写入追加的记录文件中(RDB和 AOF两种方式),并且在此基础上实现了 master-slave (主从)同步。机器重启后,能通过持久化数据自动重建内存。如果使用Redis作为Cache,则机器宕机后热点数据不会丢失。
丰富的数据结构加上Redis兼具缓存系统和数据库等特性,使得Redis拥有更加丰富的应用场景。
Redis可能会导致的问题:
Redis为什么快:
Memcached的协议简单,它基于Libevent的事件处理,内置内存存储方式。Memcached 的分布式不互相通信,即各个Memcached不会互相通信以共享信息,分布策略由客户端实现。它不会对数据进行持久化,重启Memcached、重启操作系统都会导致全部数据消失。
Memcached常见的应用场景一存储一些读取频繁但更新较少的数据,如静态网页、系统配置及规则数据、活跃用户的基本数据和个性化定制数据、实时统计信息等。
(1)关注度。
近年来,Redis越来越火热,人们对Redis的关注度越来越高;对 Memcached关注度比较平稳,且有下降的趋势。
(2)性能。
两者的性能都比较高。
(3)数据类型。
Memcached的数据结构单一。
Redis非常丰富。
(4)内存大小。
Redis在2.0版本后增加了自己的VM特性,突破物理内存的限制。
Memcached可以修改最大可用内存的大小来管理内存,采用LRU算法.
(5)可用性。
Redis依赖客户端来实现分布式读写,在主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制。Redis不支持自动分片(sharding)。如果要实现分片功能,则需要依赖程序设定一致的散列(hash)机制。
Memcached采用成熟的hash或环状的算法,来解决单点故障引起的抖动问题,其本身没有数据冗余机制。
(6)持久化。
Redis依赖快照、AOF进行持久化。但AOF在增强可靠性的同时,对性能也有所影响。
Memcached不支持持久化,通常用来做缓存,以提升性能。
(7)value数据大小。
Redis的value的最大限制是1GB。
Memcached只能保存1MB以内的数据。
(8)数据一致性(事务支持)。
Memcached在并发场景下用CAS保证一致性。
Redis对事务支持比较弱,只能保证事务中的每个操作连续执行。
(9)应用场景。
Redis:适合数据量较少、性能操作和运算要求高的场景。
Memcached:适合提升性能的场景。适合读多与少,如果数据量比较大,则可以采用分片的方式来解决。
Redis特别适合将方法的运行结果放入缓存,以便后续在请求方法时直接去缓存中读取。对执行耗时,且结果不频繁变动的SQL查询的支持极好。
在高并发的情况下,应尽暈避免请求直接访问数据库,这时可以使用Redis进行缓冲操作,让请求先访问Redis。
电商网站(APP)商品的浏览量、视频网站(APP)视频的播放数等数据都会被统计,以便用于运营或产品分析。为了保证数据实时生效,每次浏览都得+1,这会导致非常高的并发量。这时可以用Redis提供的incr命令来实现计数器功能,这一切在内存中操作,所以性能非常好,非常适用于这些计数场景。
可以利用Redis提供的有序集合数据类,实现各种复杂的排行榜应用。如京东、淘宝的销量榜单,商品按时间、销量排行等。
在集群模式下,一般都会搭建以Redis等内存数据库为中心的Session (会活)服务,它不再由容器管理,而是由Session服务及内存数据库管理。
使用Redis提供的散列、集合等数据结构,可以很方便地实现网站(APP)中的点赞、踩、关注共同好友等社交场景的基本功能。
Redis可以通过LPUSH在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无须查询最新的列表,直接根据ID查找対应的内容即可。
Redis有5种数据类型,见表11-2。
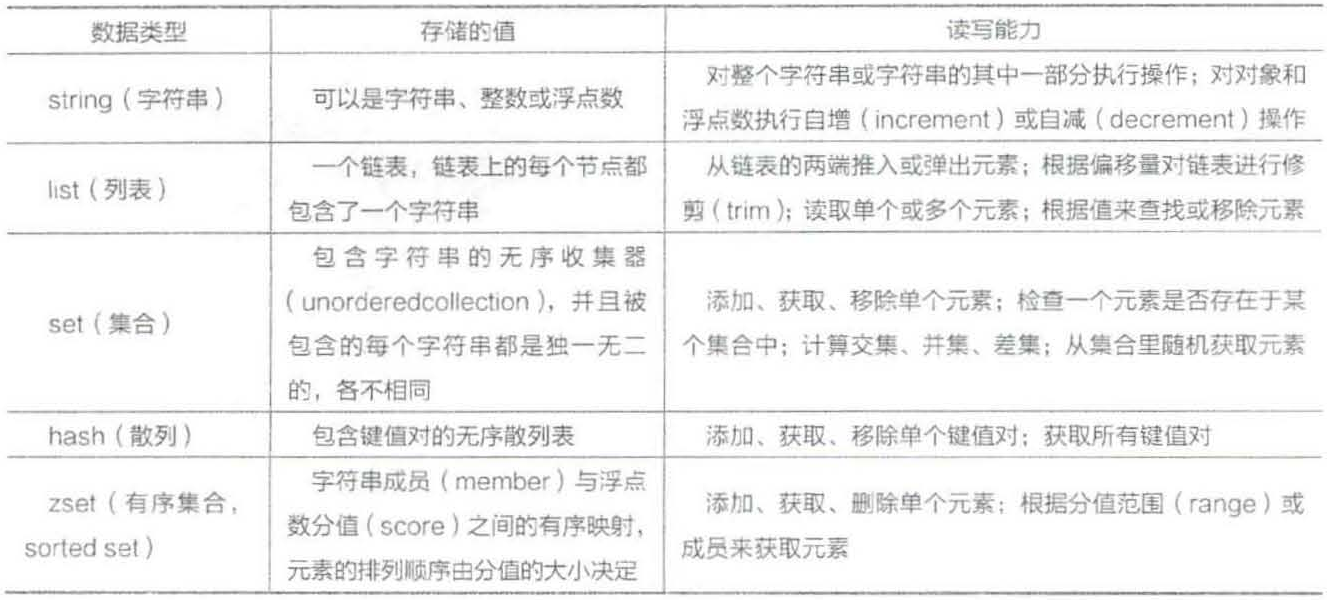
表 11-2
Redis字符串可以包含任意类型的数据、字符、整数、浮点数等。
一个字符串类型的值的容量有512MB,代表能存储最大512MB的内容。
可以使用INCR (DECR、INCRBY)命令来把字符串当作原子计敬器使用。
使用APPEND命令在字符串后添加内容。
应用场景:计数器。
Redis列表是简单的字符串列表,按照插入顺序排序。可以通过LPUSH、RPUSH命令添加一个元素到列表的头部或尾部。
一个列表最多可以包含以”232-1“(4294967295)个元素。
应用场景:取最新N个数据的操作、消息队列、删除与过滤、实时分析正在发生的情况,数据统计与防止垃圾邮件(结合Set )。
Redis集合是一个无序的、不允许相同成员存在的字符串合集。
支持一些服务器端的命令从现有的集合出发去进行集合运算,如合并(并集:union)、求交(交集intersection)、差集,找出不同元素的操作(共同好友、二度好友)。
应用场景:Unique操作,可以获取某段时间内所有数据“排重值”,比如用于共同好友、二度好友、统计独立IP、好友推荐等。
Redis hash是字符串字段和字符串值之间的映射,主要用来表示对象,也能够存储许多元素。
应用场景:存储、读取、修改用户属性。
Redis有序集合和Redis集合类似,是不包含相同字符串的合集。每个有序集合的成员都关联着一个评分,这个评分用于把有序集合中的成员按最低分到最高分排列(排行榜应用,取TOP N 操作)。
使用有序集合,可以非常快捷地完成添加、删除和更新元素的操作。元素是在插入时就排好序 的,所以很快地通过评分(score )或位次(position )获得一个范围的元素。
应用场景:排行榜应用、取TOP N、需要精准设定过期时间的应用(时间戳作为Score)、带有权重的元素(游戏用户得分排行榜)、过期项目处理、按照时间排序等。
Spring封装了 RedisTemplate来操作Redis,它支持所有的Redis原生的API,在 RedisTemplate中定义了对5种数据结构的操作方法。
下面通过实例来理解和应用这些方法。这里需要特别注意的是,运行上述方法后要对数据进行清空操作,否则多次运行会导致数据重复操作。
字符串(string )是Redis最基本的类型。string的一个“key”对应一个"value”,即key-value 键值对。string是二进制安全的,可以存储任何数据(比如图片或序列化的对象)。值最大能存储512MB的数据。一般用于一些复杂的计数功能的缓存。RedisTemplate提供以下操作string的方法。
(1)set void set(K key, V value);get V get(Object key)
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("hello", "world");
redisTemplate.opsForValue().set("staing","somewhere");
Object s = redisTemplate.opsForValue().get("hello");
Object s2 = redisTemplate.opsForValue().get("staing");
System.out.println(s);
System.out.println(s2);
}
}(2)set void set(K key, V value, long timeout, TimeUnit unit)
以下代码设置3 s失效。3 s之内查询有结果,3 s之后查询则返回为null。具体用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void String(){
redisTemplate.opsForValue().set("hello", "world",3, TimeUnit.SECONDS);
try {
Object s = redisTemplate.opsForValue().get("hello");
System.out.println(s);
Thread.currentThread().sleep(2000);
s = redisTemplate.opsForValue().get("hello");
System.out.println(s);
Thread.currentThread().sleep(2000);
s = redisTemplate.opsForValue().get("hello");
System.out.println(s);
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}TimeUnit是java.util.concurrent包下面的一个类,表示给定单元粒度的时间段,常用的颗粒度有:
(3)set void set(K key, V value, long offset)
给定key所存储的字符串值,从偏移量 offset开始。具体用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForValue().set("key", "hello world",6);
System.out.println(redisTemplate.opsForValue().get("key"));
}
}运行测试,输出如下结果:
hello
(4)getAndSet V getAndSet(K key, V value)
设置键的字符串值,并返回其旧值。具体用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForValue().set("hello", "world");
System.out.println(redisTemplate.opsForValue().getAndSet("hello", "hey"));
System.out.println(redisTemplate.opsForValue().get("hello"));
}
}运行测试,输出如下结果:
world
hey
(5)append Integer append(K key, String value)
如果key已经存在,并且是一个字符串,则该命令将该值追加到字符串的末尾。如果key不存在,则它将被创建并设置为空字符串,因此append在这种特殊情况下类似于set。用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Test
void test() {
redisTemplate.opsForValue().append("hello", "hello");
System.out.println(redisTemplate.opsForValue().get("hello"));
redisTemplate.opsForValue().append("hello", "world");
System.out.println(redisTemplate.opsForValue().get("hello"));
}
}运行测试,输出如下结果:
hello
helloworld
这里一定要注意反序列化配置,否则会报借。
(6)size Long size(K key)
返回key所对应的value值的长度,见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForValue().set("key", "1");
System.out.println(redisTemplate.opsForValue().size("key"));
}
}运行测试,输岀如下结果:
3
Redis hash (散列)是一个string类型的field和value的映射表,hash特别适合用于存储对象。value中存放的是结构化的对象.利用这种数据结构,可以方便地操作其中的某个字段。比如在“单点登录”时,可以用这种数据结构存储用户信息。以Cookield作为key,设置30分钟为缓存过期时间,能很好地模拟出类似Session的效果。
(1)void putAII(H key, Map<? extends HK, ? extends HV> m)
用m中提供的多个散列字段设置到key对应的散列表中,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("key1", "value1");
map.put("key2", "value2");
redisTemplate.opsForHash().putAll("HASH",map);
System.out.println(redisTemplate.opsForHash().entries("HASH"));
}
}运行测试,输出如下结果:
{key1=value1, key2=value2}
(2)void put(H key, HK hashKey, HV value)
设置hashKey的值,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().entries("redis"));
}
}运行测试,输出如下结果:
{name=li, sex=male}
(3)List<HV> values(H key)
根据密钥获取整个散列存储的值,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().values("redis"));
}
}运行测试,输出如下结果:
[li, male]
(4)Map<HK, HV> entries(H key)
根据密钥获取整个散列存储,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().entries("redis"));
}
}运行测试,输出如下结果:
{name=li, sex=male}
(5)Long delete(H key, Object... hashKeys)
删除给定的hashKeys,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().delete("redis","name"));
System.out.println(redisTemplate.opsForHash().entries("redis"));
}
}运行测试,输出如下结果:
1
{sex=male}
(6)Boolean hasKey(H key, Object hashKey)
确定hashKey是否存在,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().hasKey("redis","name"));
System.out.println(redisTemplate.opsForHash().hasKey("redis","sex"));
}
}运行测试,输出如下结果:
true
true
(7)HV get(H key, Object hashKey)
从键中的散列获取给定hashKey的值,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().get("redis","name"));
}
}运行测试,输出如下结果:
li
(8)Set<HK> keys(H key)
获取key所对应的key的值,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().keys("redis"));
}
}运行测试,输出如下结果:
[sex, name]
(9)Long size(H key)
获取key所对应的散列表的大小个数,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForHash().put("redis","name","li");
redisTemplate.opsForHash().put("redis","sex","male");
System.out.println(redisTemplate.opsForHash().size("redis"));
}
}运行测试,输出如下结果:
2
Redis列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边) 或尾部(右边)。
使用list数据结构,可以做简单的消息队列的功能。还可以利用Irange命令,做基于Redis的分页功能,性能极佳。而使用SQL语句做分页功能往往效果扱差。
(1)Long leftPushAII(K key, V... values)
leftPushAII表示把一个数组插入列表中,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[] {"1","2","3"};
redisTemplate.opsForList().leftPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}运行测试,输岀如下结果:
[3,2,1]
(2)Long size(K key)
返回存储在键中的列表的长度。如果键不存在,则将其解释为空列表,并返回0。如果key存储的值不是列表,则返回错误。用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[] {"1","2","3"};
redisTemplate.opsForList().leftPushAll("list",strings);
System.out.println(redisTemplate.opsForList().size("list"));
}
}运行测试,输岀如下结果:
6
(3)Long leftPush(K key, V value)
将所有指定的值插入在键的列表的头部,如果键不存在,则在执行推送操作之前将其创建为空列表(从左边插入)。用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForList().leftPush("list","1");
System.out.println(redisTemplate.opsForList().size("list"));
redisTemplate.opsForList().leftPush("list","2");
System.out.println(redisTemplate.opsForList().size("list"));
redisTemplate.opsForList().leftPush("list","3");
System.out.println(redisTemplate.opsForList().size("list"));
}
}(4)Long rightPush(K key, V value)
将所有指定的值插入存储在键的列表的头部。如果键不存在,则在执行推送操作之前将其创建为空列表(从右边插入)。用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForList().rightPush("list","1");
System.out.println(redisTemplate.opsForList().size("list"));
redisTemplate.opsForList().rightPush("list","2");
System.out.println(redisTemplate.opsForList().size("list"));
redisTemplate.opsForList().rightPush("list","3");
System.out.println(redisTemplate.opsForList().size("list"));
}
}(5)Long rightPushAII(K key, V... values)
通过rightPushAII方法向最右边批量添加元素,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}(6)void set(K key, long index, V value)
在列表中index的位置设置value,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
redisTemplate.opsForList().set("list",1,"值");
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}运行测试,输出如下结果:
[1, 2, 3]
[1, 值, 3]
(7)Long remove(K key, long count, Object value)
从存储在键中的列表,删除给定“count”值的元素的第1个计数事件。其中,参数count的 含义如下。
以下代码用于删除列表中第一次出现的值。
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
redisTemplate.opsForList().remove("list",1,"2");
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}运行测试,输出如下结果:
[1, 2, 3]
[1, 3]
(8)V index(K key, long index)
根据下标获取列表中的值(下标从0幵始),用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
System.out.println(redisTemplate.opsForList().index("list",2));
}
}运行测试,输出如下结果:
[1, 2, 3]
3
(9)V leftPop(K key)
弹出最左边的元素,弹出之后该值在列表中将不复存在,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
System.out.println(redisTemplate.opsForList().leftPop("list"));
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}运行测试,输出如下结果:
[1, 2, 3]
1
[2, 3]
(10)V rightPop(K key)
弹出最右边的元素,弹出之后该值任列表中将不复存在,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"1", "2", "3"};
redisTemplate.opsForList().rightPushAll("list",strings);
System.out.println(redisTemplate.opsForList().range("list",0,-1));
System.out.println(redisTemplate.opsForList().rightPop("list"));
System.out.println(redisTemplate.opsForList().range("list",0,-1));
}
}运行测试,输出如下结果:
[1, 2, 3]
3
[1, 2]
set是存放不重复值的集合。利用set可以做全局去重的功能。还可以进行交集、并集、差集等 操作,也可用来实现计算共同喜好、全部的喜好、自己独有的喜好等功能。
Redis的set是string类型的无序集合,通过散列表实现。
(1)Long add(K key, .. values)
在无序集合中添加元素,返回添加个数,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set1",strings));
System.out.println(redisTemplate.opsForSet().add("set1","1","2","3"));
}
}运行测试,输出如下结果:
2
3
(2)Long remove(K key, Object... values)
移除集合中一个或多个成员,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set1",strings));
System.out.println(redisTemplate.opsForSet().remove("set1",strings));
}
}运行测试,输出如下结果:
2
0
(3)V pop(K key)
移除并返回集合中的一个随机元素,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set1",strings));
System.out.println(redisTemplate.opsForSet().pop("set1"));
System.out.println(redisTemplate.opsForSet().members("set1"));
}
}运行测试,输出如下结果:
2
str2
[str1]
(4)Boolean move(K key, V value, K destKey)
将member元素移动,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set1",strings));
redisTemplate.opsForSet().move("set1","str1","set1tostr1");
System.out.println(redisTemplate.opsForSet().members("set1"));
System.out.println(redisTemplate.opsForSet().members("set1tostr1"));
}
}运行测试,输出如下结果:
2
[str2]
[str1]
(5)Long size(K key)
获取无序集合的大小长度,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set",strings));
System.out.println(redisTemplate.opsForSet().size("set"));
}
}运行测试,输出如下结果:
2
2
(6)Set<V> members(K key)
返回集合中的所有成员,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set",strings));
System.out.println(redisTemplate.opsForSet().members("set"));
}
}运行测试,输出如下结果:
2
[str1,str2]
(7)Cursor<V> scan(K key, ScanOptions options)
遍历Set,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
String[] strings = new String[]{"str1", "str2"};
System.out.println(redisTemplate.opsForSet().add("set",strings));
Cursor<Object> cursor = redisTemplate.opsForSet().scan("set", ScanOptions.NONE);
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
}运行测试,输岀如下结果:
2
str2
str1
zset (sorted set,有序集合)也是string类型元素的集合,且不允许重复的成员。每个元素都会关联一个double类型的分数。可以通过分数将该集合中的成员从小到大进行排序。
zset的成员是唯一的,但权重参数分数(score)却可以重复。集合中的元素能够按score进行排列。它可以用来做排行榜应用、取TOP N 延时任务、范围查找等。
(1)Long add(K key, Set<TypedTuple<V>>tuples)
新增一个有序集合,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",9.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",9.9);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
}
}运行测试,输出如下结果:
1
[zset-1, zset-2]
(2)Boolean add(K key, V value, double score)
新增一个有序集合,如果存在则返回false,如果不存在则返回true,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
System.out.println(redisTemplate.opsForZSet().add("zset","zset-1",1.0));
System.out.println(redisTemplate.opsForZSet().add("zset","zset-1",1.0));
}
}运行测试,输出如下结果:
true
false
(3)Long remove(K key, Object... values)
从有序集合中移除一个或多个元素,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
System.out.println(redisTemplate.opsForZSet().add("zset","zset-1",1.0));
System.out.println(redisTemplate.opsForZSet().add("zset","zset-2",1.0));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
System.out.println(redisTemplate.opsForZSet().remove("zset","zset-2"));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
}
}运行测试,输出如下结果:
true
true
[zset-1, zset-2]
1
[zset-1]
(4)Long rank(K key, Object o)
返回有序集中指定成员的排名,按分数值递增排列,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
System.out.println(redisTemplate.opsForZSet().add("zset","zset-1",1.0));
System.out.println(redisTemplate.opsForZSet().add("zset","zset-2",1.0));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
System.out.println(redisTemplate.opsForZSet().remove("rank","zset-1"));
}
}运行测试,输出如下结果:
true
true
[zset-1, zset-2]
0
(5)Set<V> range(K key, long start, long end)
通过索引区间返回有序集合指定区间内的成员,按分数值递增排列,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",9.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",8.1);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
}
}运行测试,输出如下结果:
0
[zset-2, zset-1]
(6)Long count(K key, double min, double max)
通过分数返回有序集合指定区间内的成员个数,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",3.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",4.1);
ZSetOperations.TypedTuple<Object> objectTypedTuple3 = new DefaultTypedTuple<>("zset-3",5.7);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().rangeByScore("zset",0,9));
System.out.println(redisTemplate.opsForZSet().count("zset",0,5));
}
}运行测试,输出如下结果:
1
[zset-1, zset-2, zset-3]
2
(7)Long size(K key)
获取有序集合的成员数,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",3.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",4.1);
ZSetOperations.TypedTuple<Object> objectTypedTuple3 = new DefaultTypedTuple<>("zset-3",5.7);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().size("zset"));
}
}运行测试,输出如下结果:
0
3
(8)Double score(K key, Object o)
获取指定成员的score值,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",3.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",4.1);
ZSetOperations.TypedTuple<Object> objectTypedTuple3 = new DefaultTypedTuple<>("zset-3",5.7);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().score("zset","zset-1"));
}
}运行测试,输出如下结果:
0
3.6
(9)Long removeRange(K key, long start, long end)
移除指定索引位置的成员,有序集成员按分数值递增排列,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",3.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",4.1);
ZSetOperations.TypedTuple<Object> objectTypedTuple3 = new DefaultTypedTuple<>("zset-3",2.7);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
System.out.println(redisTemplate.opsForZSet().removeRange("zset",1,2));
System.out.println(redisTemplate.opsForZSet().range("zset",0,-1));
}
}运行测试,输岀如下结果:
2
[zset-3, zset-1, zset-2]
2
[zset-3]
(10)Cursor<TypedTuple<V>>scan(K key, ScanOptions options)
遍历zset,用法见以下代码:
@SpringBootTest
class RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test() {
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-1",3.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-2",5.1);
ZSetOperations.TypedTuple<Object> objectTypedTuple3 = new DefaultTypedTuple<>("zset-3",2.7);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
System.out.println(redisTemplate.opsForZSet().add("zset",tuples));
Cursor<ZSetOperations.TypedTuple<Object>> cursor = redisTemplate.opsForZSet().scan("zset",ScanOptions.NONE);
while (cursor.hasNext()) {
ZSetOperations.TypedTuple<Object> item = cursor.next();
System.out.println(item.getValue()+":"+item.getScore());
}
}
}运行测试,输出如下结果:
2
zset-3:2.7
zset-1:3.6
zset-2:5.1
除使用opsForXXX方法外,还可以使用Execute方法。opsForXXX方法的底层,是通过调用Execute方法来实现的。psForXXX方法实际上是封装了 Execute方法,定义了序列化,以便使用起来更简单便捷。
StringRedisTemplate继承于RedisTemplate,两者的数据是不相通的。
StnngRedisTemplate默认采用的是string的序列化策略,RedisTemplate默认采用的是 JDK的序列化策略。
原始问题Letd(n)bedefinedasthesumofproperdivisorsofn(numberslessthannwhichdivideevenlyinton).Ifd(a)=bandd(b)=a,whereab,thenaandbareanamicablepairandeachofaandbarecalledamicablenumbers.Forexample,theproperdivisorsof220are1,2,4,5,10,11,20,22,44,55and110;therefored(220)=284.Theproperdivisorsof284are1,2,
2022年10月21日星期五【数据指标】加密货币总市值:$0.95万亿BTC市值占比:38.51%恐慌贪婪指数:23极度恐慌 【今日快讯】1、【政讯】1.1.1、美联储布拉德:市场预期美联储11月会加息75个基点1.1.2、美联储哈克:将维持加息一段时间1.2、美国10年期国债收益率触及4.197%,为2008年6月以来最高1.3、法国数字转型部长:政府将专注于DeFi和Web31.4、巴西ATM机将于11月3日起支持USDT1.5、美众议院副议长将于11月初加入a16zCrypto担任政府事务主管1.6、香港数字资产托管机构FirstDigitalTrust首席执行官:香港仍是安全
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统
一、Elasticsearch简介实际业务场景中,多端的查询功能都有很大的优化空间。常见的处理方式有:建索引、建物化视图简化查询逻辑、DB层之上建立缓存、分页…然而随着业务数据量的不断增多,总有那么一张表或一个业务,是无法通过常规的处理方式来缩短查询时间的。在查询功能优化上,作为开发人员应该站在公司的角度,本着优化客户体验的目的去寻找解决方案。本人有幸做过Tomcat整合solr,今天一起研究一下当前比较火热的Elasticsearch搜索引擎。Elasticsearch是一个非常强大的搜索引擎。它目前被广泛地使用于各个IT公司。Elasticsearch是由Elastic公司创建。它的代码位
✅作者简介:热爱国学的Java后端开发者,修心和技术同步精进。🍎个人主页:乐趣国学的博客🍊个人信条:不迁怒,不贰过。小知识,大智慧。💞当前专栏:Java案例分享专栏✨特色专栏:国学周更-心性养成之路🥭本文内容:Java——“21点”扑克游戏系统(变量+循环)更多内容点击👇 Java——对象和类案例代码详解目录⛳️一、项目需求⛳️二、代码实现⛳️三、效果展示⛳️一、项目需求 编写“21点”的扑克游戏(每个需求用一个测试类来完成测试) 需求一:计算机随机地向用户发5张牌,如果牌的总点数小於或等於21点,则用户赢;超过21点则计算机赢。 注意类的没有参数的
场景在SpringBoot项目中需要对接三方系统,对接协议是TCP,需实现一个TCP客户端接收服务端发送的数据并按照16进制进行解析数据,然后对数据进行过滤,将指定类型的数据通过mybatis存储进mysql数据库中。并且当tcp服务端断连时,tcp客户端能定时检测并发起重连。全流程效果 注:博客:霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主实现1、SpringBoot+Netty实现TCP客户端本篇参考如下博客,在如下博客基础上进行修改Springboot+Netty搭建基于TCP协议的客户端(二):https://www.cnblogs.com/haolb
一、SpringBoot是什么SpringBoot是依赖于Spring的,比起Spring,除了拥有Spring的全部功能以外,SpringBoot无需繁琐的Xml配置,这取决于它自身强大的自动装配功能;并且自身已嵌入Tomcat、Jetty等web容器,集成了SpringMvc,使得SpringBoot可以直接运行,不需要额外的容器,提供了一些大型项目中常见的非功能性特性,如嵌入式服务器、安全、指标,健康检测、外部配置等,其实Spring大家都知道,Boot是启动的意思。所以,SpringBoot其实就是一个启动Spring项目的一个工具而已,总而言之,SpringBoot是一个服务于框架的