
? 作者:韩信子@ShowMeAI
? 数据分析实战系列:https://www.showmeai.tech/tutorials/40
? 本文地址:https://www.showmeai.tech/article-detail/389
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容
Pandas 是大家都非常熟悉的数据分析与处理工具库,对于结构化的业务数据,它能很方便地进行各种数据分析和数据操作。但我们的数据中,经常会存在对应时间的字段,很多业务数据也是时间序组织,很多时候我们不可避免地需要和时间序列数据打交道。其实 Pandas 中有非常好的时间序列处理方法,但是因为使用并不特别多,很多基础教程也会略过这一部分。
在本篇内容中,ShowMeAI对 Pandas 中处理时间的核心函数方法进行讲解。相信大家学习过后,会在处理时间序列型数据时,更得心应手。
数据分析与处理的完整知识技能,大家可以参考ShowMeAI制作的工具库速查表和教程进行学习和快速使用。
时间序列是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。简单说来,时间序列是随着时间的推移记录某些取值,比如说商店一年的销售额(按照月份从1月到12月)。
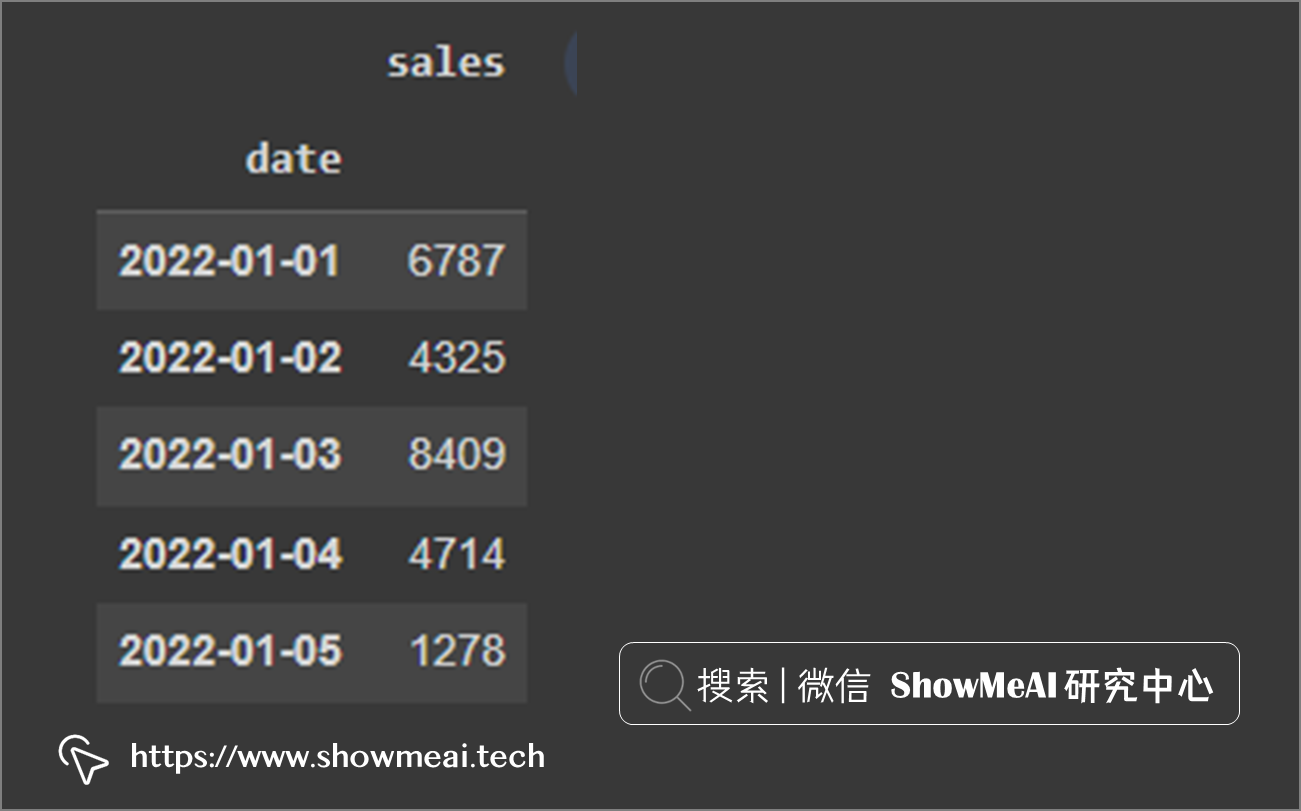
我们要了解的第一件事是如何在 Pandas 中创建一组日期。我们可以使用date_range()创建任意数量的日期,函数需要你提供起始时间、时间长度和时间间隔。
# 构建时长为7的时间序列
pd.date_range("2022-01-01", periods=7, freq='D')
# 输出
# DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04','2022-01-05', '2022-01-06', '2022-01-07'], dtype='datetime64[ns]', freq='D')
注意到上面的频率可用freq来设置:最常见的是'W'每周,'D'是每天,'M'是月末,'MS'是月开始。
下面我们创建一个包含日期和销售额的时间序列数据,并将日期设置为索引。
# 设置随机种子,可以复现
np.random.seed(12)
# 构建数据集
df = pd.DataFrame({
'date': pd.date_range("2022-01-01", periods=180, freq='D'),
'sales': np.random.randint(1000, 10000, size=180)})
# 设置索引
df = df.set_index('date')
注意,我们要方便地对时间序列进行处理,一个很重要的先序工作是将日期作为索引,我们前面已经完成这个工作了。
Pandas 中很重要的一个核心功能是resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
方法的格式是:
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',kind=None, loffset=None, limit=None, base=0)
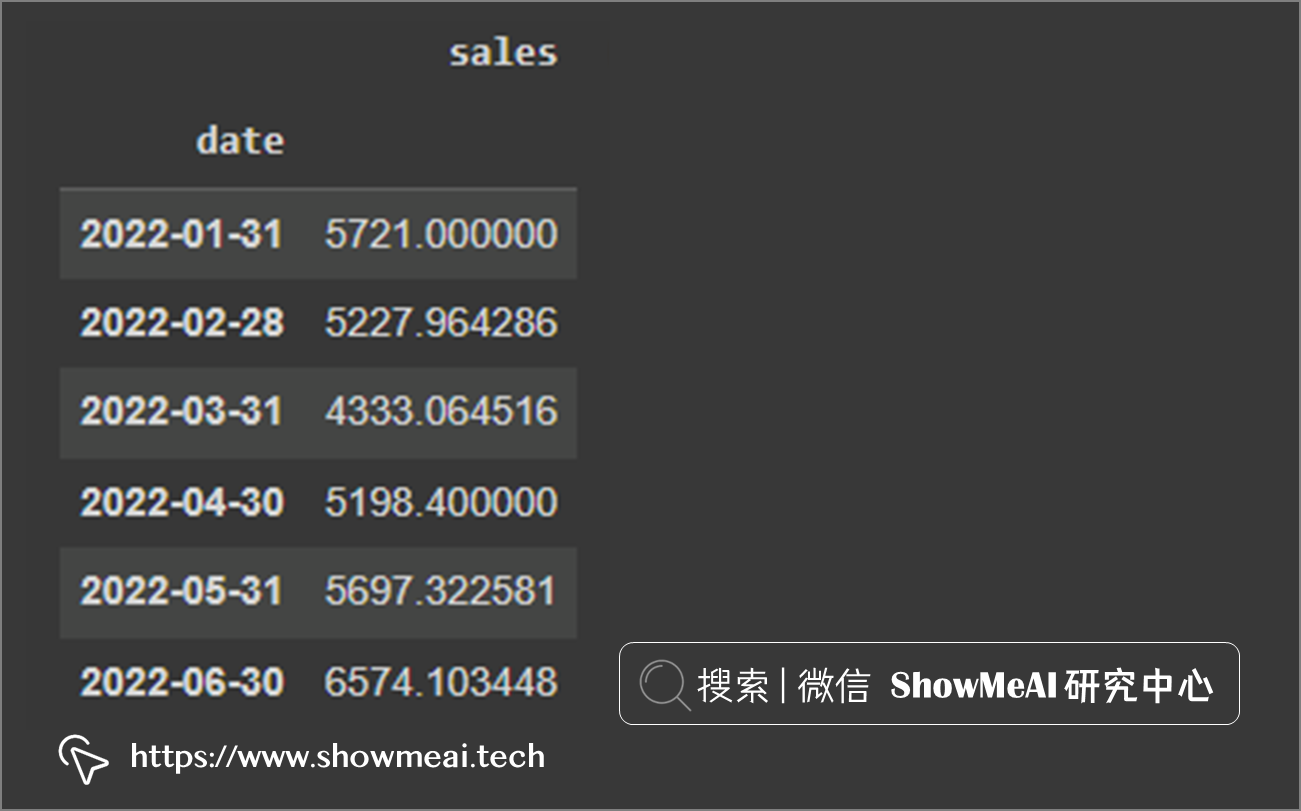
核心的参数rule是字符串,表示采样的频度。如下代码,在resample后接的mean是表示按照月度求平均。
# Resample by month end date
df.resample(rule= 'M').mean()
按月取平均值后,将索引设置为每月结束日期,结果如下。
我们也可以按每周销售额绘制汇总数据。
# 采样绘图
df.resample('W').mean().plot(figsize=(15,5), title='Avg Weekly Sales');
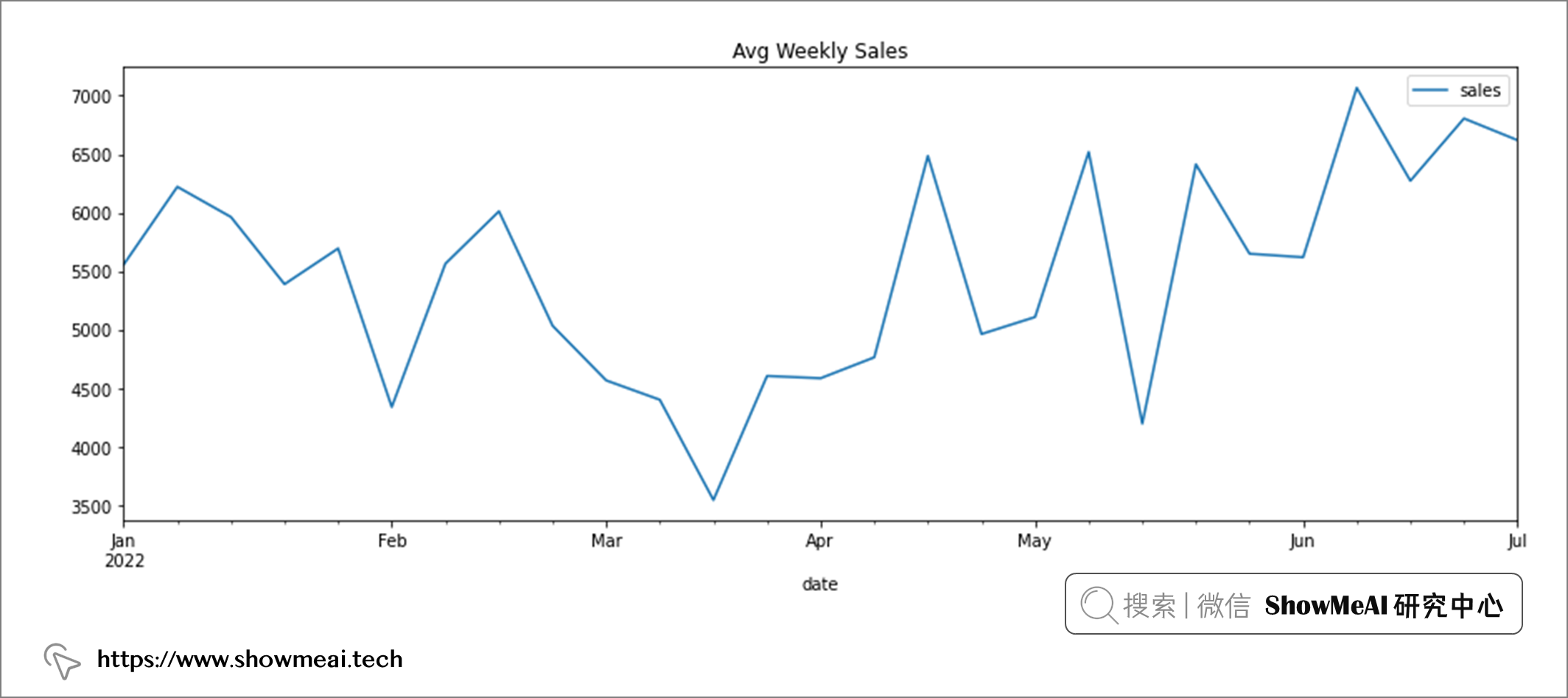
上图可以看出,销量在3月和4月之间的销售额有所下降,而在 6 月中旬达到顶峰。
Pandas 中的shift功能,可以让字段向上或向下平移数据。这个平移数据的功能很容易帮助我们得到前一天或者后一天的数据,可以通过设置shift的参数来完成上周或者下周数据的平移。
# 原始数据的一份拷贝
df_shift = df.copy()
# 平移一天
df_shift['next_day_sales'] = df_shift.sales.shift(-1)
# 平移一周
df_shift['next_week_sales'] = df_shift.sales.shift(-7)
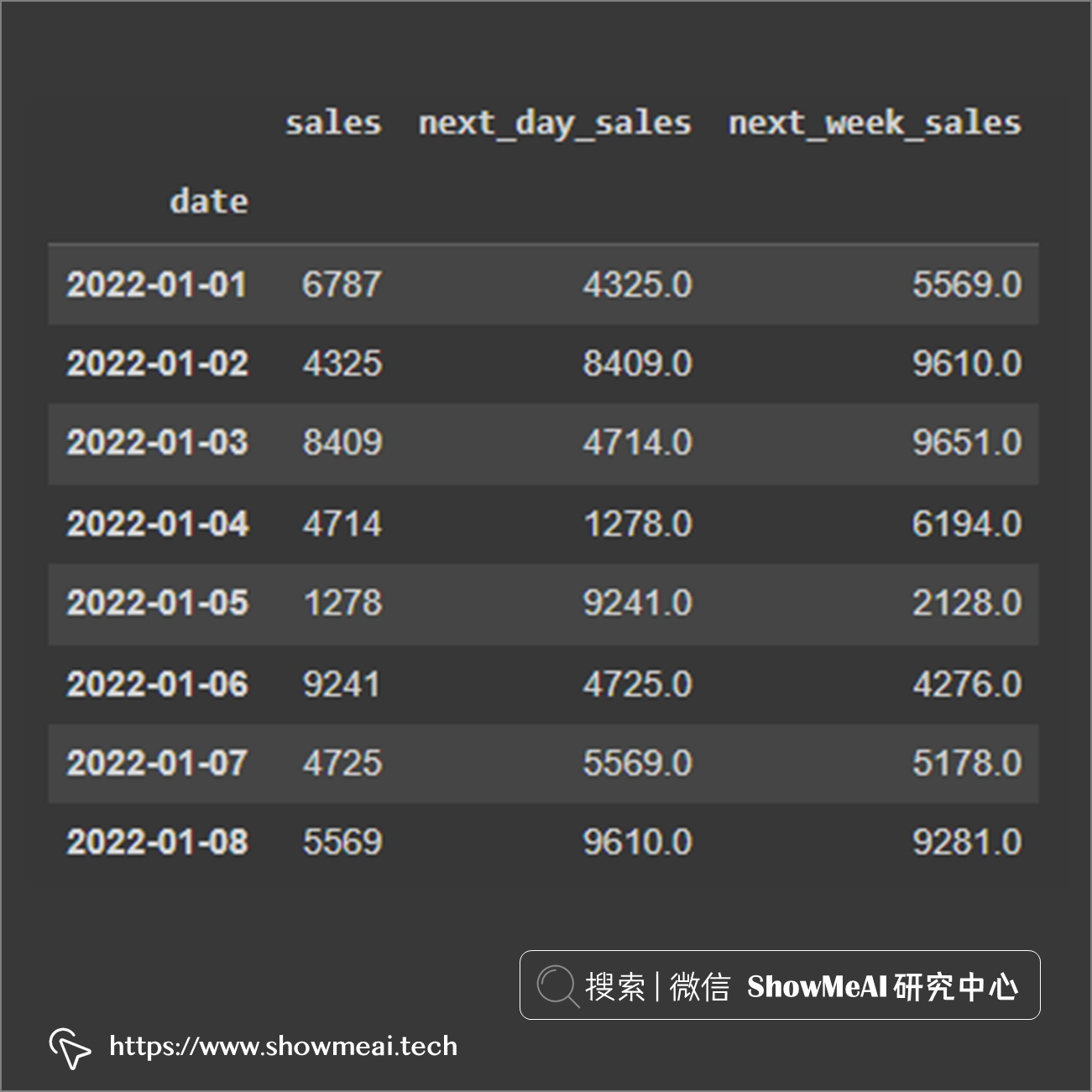
在时间序列问题中,我们经常要完成同比和环比数据,通过shift后的数据做差就很容易得到。
# 计算差值
df_shift['one_week_net'] = df_shift.sales - df_shift.sales.shift(-7)
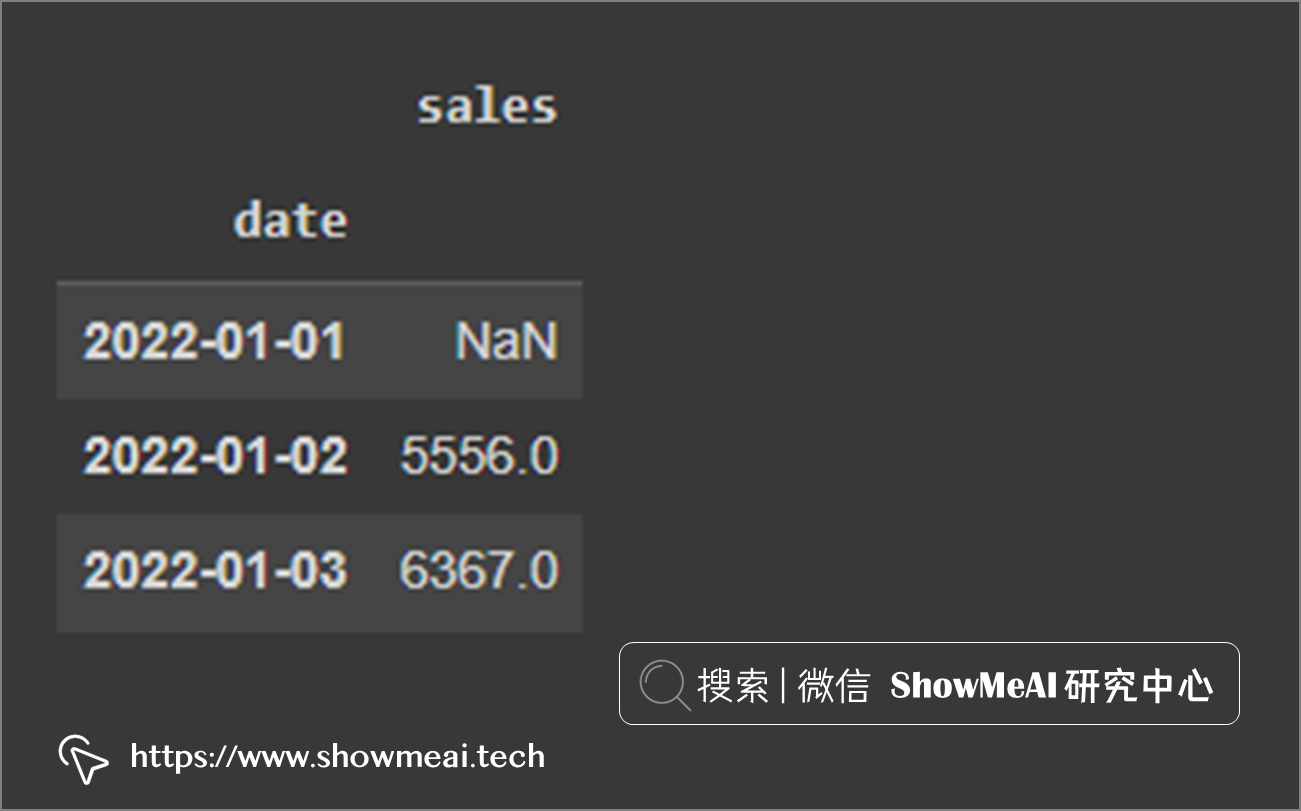
下一个核心功能是rolling滑动平均,它是做交易的朋友非常常用到的一个功能,rolling函数创建一个窗口来聚合数据。
# 长度为2天的窗口,求滑动平均
df.rolling(2).mean()
在下图中,我们可以看到第一个值是NaN,因为再往前没有数据了。对第2个点,它对数据集的前2行计算平均: (6787 + 4325)/2 = 5556。
滚动平均值非常适合表征趋势,滑动窗口越大,得到的结果曲线越平滑,最常用的是7天平均。
# 滑动平均绘图
df.sales.plot(figsize=(25,8), legend=True, linestyle='--', color='darkgray')
df.rolling(window=7).sales.mean().plot(legend=True, label='7 day average', linewidth=2)
df.rolling(30).sales.mean().plot(legend=True, label='30 day average', linewidth=3)
df.rolling(100).sales.mean().plot(legend=True, label='100 day average', linewidth=4)
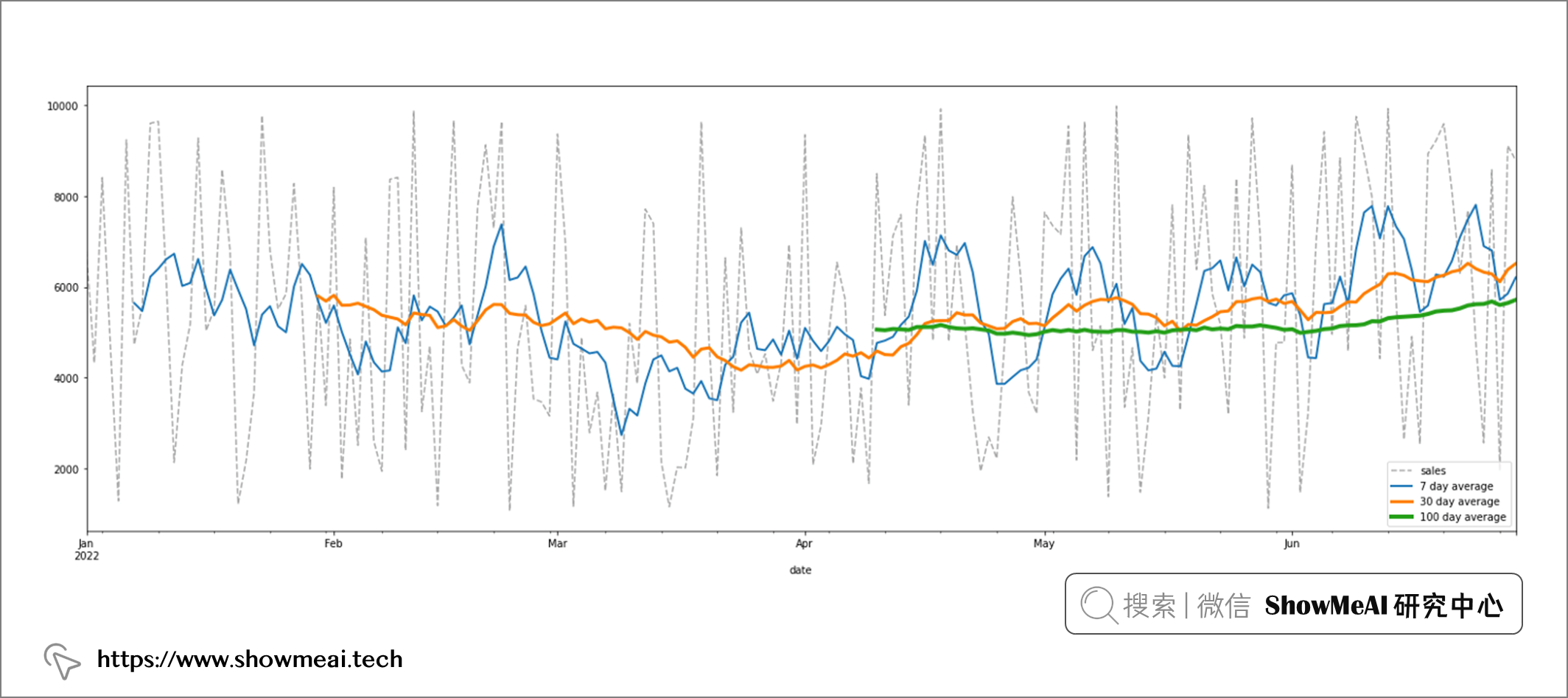
Pandas在时间序列处理和分析中也非常有效,ShowMeAI在本篇内容中介绍的3个核心函数,是最常用的时间序列分析功能:
resample:将数据从每日频率转换为其他时间频率。shift:字段上下平移数据以进行比较或计算。rolling:创建滑动平均值,查看趋势。我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
在我的一些Controller中,我有一个before_filter检查用户是否登录?用于CRUD操作。application.rbdeflogged_in?unlesscurrent_userredirect_toroot_pathendendprivatedefcurrent_user_sessionreturn@current_user_sessionifdefined?(@current_user_session)@current_user_session=UserSession.findenddefcurrent_userreturn@current_userifdefine
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
require'pp'p*1..10这会打印出1-10。为什么这么简洁?您还可以用它做什么? 最佳答案 它是“splat”运算符。它可用于分解数组和范围并在赋值期间收集值。这里收集赋值中的值:a,*b=1,2,3,4=>a=1b=[2,3,4]在此示例中,内部数组([3,4])中的值被分解并收集到包含数组中:a=[1,2,*[3,4]]=>a=[1,2,3,4]您可以定义将参数收集到数组中的函数:deffoo(*args)pargsendfoo(1,2,"three",4)=>[1,2,"three",4]
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va