
本章内容
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串...
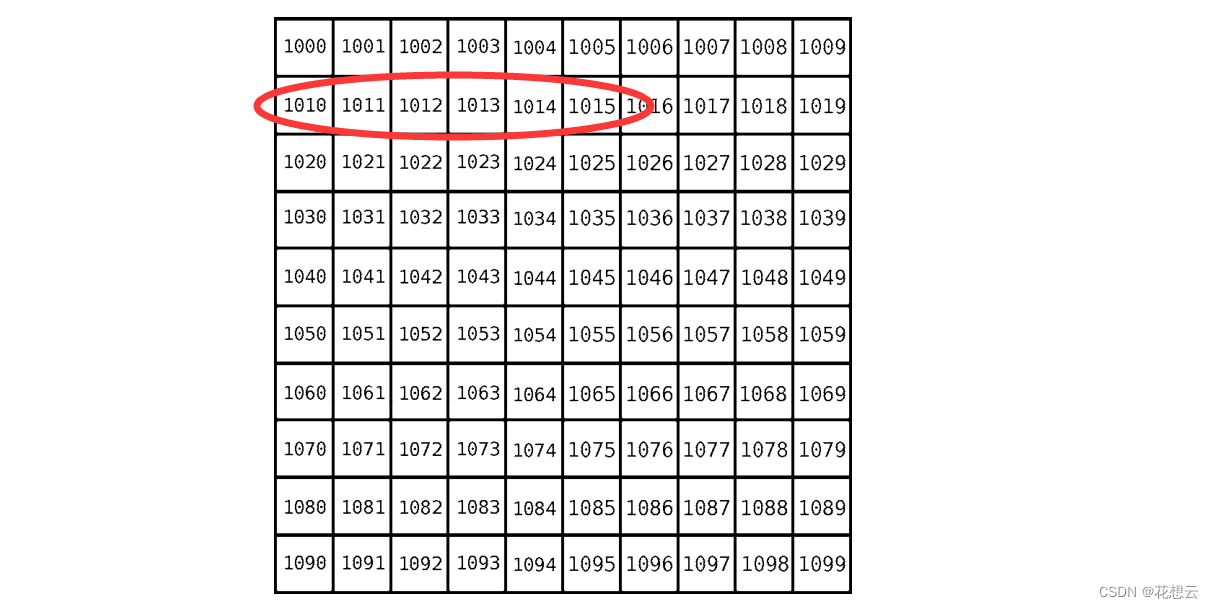
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。

顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表一般可以分为:
1.静态顺序表:使用定长数组存储元素。
2.动态顺序表:使用动态开辟的数组存储元素。
#define N 100
typedef int SLDataType;
//静态顺序表
typedef struct SeqList
{
SLDataType a[N];//定长数组
int size;//记录存储多少个有效数据
}SeqList;//初始化顺序表
void SLInit(SeqList* ps);
//静态顺序表的尾插
void SLPushBack(SeqList* ps,SLDataType data);
//静态顺序表的尾删
void SLPopBack(SeqList* ps);
//静态顺序表的头插
void SLPushFront(SeqList* ps,SLDataType data);
//静态顺序表的头删
void SLPopFront(SeqList* ps);
//pos位置插入数据
void SLInsert(SeqList* ps, int pos, SLDataType data);
//pos位置删除数据
void SLErase(SeqList* ps,int pos);
//查找数据
int SLFind(SeqList* ps, SLDataType data, int begin);
//判断数组是否已满
bool IsFull(SeqList* ps);
//打印存储的数据
void SLPrint(SeqList* ps);以下是函数接口的实现:
void SLInit(SeqList* ps)
{
assert(ps);
ps->size = 0;
}bool IsFull(SeqList* ps)
{
assert(ps);
if (ps->size == N)
{
return true;
}
else
{
return false;
}
}void SLPushBack(SeqList* ps,SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//插入数据
ps->a[ps->size] = data;
ps->size++;
}void SLPopBack(SeqList* ps)
{
assert(ps);
ps->size--;
}void SLPushFront(SeqList* ps, SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//挪动数据
for (int i = ps->size - 1; i >= 0; i--)
{
ps->a[i + 1] = ps->a[i];
}
//插入数据
ps->a[0] = data;
ps->size++;
}void SLPopFront(SeqList* ps)
{
assert(ps);
assert(ps->size > 0);
//挪动数据
for (int i = 0; i < ps->size-1; i++)
{
ps->a[i] = ps->a[i + 1];
}
ps->size--;
}void SLInsert(SeqList* ps, int pos, SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//挪动数据
for (int i = ps->size-1; i >= pos; i--)
{
ps->a[i + 1] = ps->a[i];
}
//插入数据
ps->a[pos] = data;
ps->size++;
}void SLErase(SeqList* ps, int pos)
{
assert(ps);
assert(ps->size > 0);
//挪动数据
for (int i = pos; i < ps->size - 1; i++)
{
ps->a[i] = ps->a[i + 1];
}
ps->size--;
}int SLFind(SeqList* ps, SLDataType data, int begin)
{
assert(ps);
assert(begin < ps->size);
for (int i = begin; i < ps->size; i++)
{
if (ps->a[i] == data)
{
return i;
}
}
return -1;
}void SLPrint(SeqList* ps)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}1.静态顺序表的局限性
静态顺序表只适用于确定知道需要存多少数据的场景。如果数据量未知,N的值太大,造成空间浪费;N的值太小,数据存储不下。
2.接口函数的参数为什么要用结构体指针?
因为尾插、尾删与初始化需要改变结构的内容,若不用结构体指针,形参的改变无法影响实参,则导致无法完成任务;剩下的两个是为了统一与美观。
3.顺序表增删查改的时间复杂度
①顺序表的优势
顺序表的优势是尾插与尾删,为什么呢?
顺序表底层逻辑结构与数组相同,都是在内存上取一连串连续的空间来存储数据。既然这些空间是连续的,那么就意味着我们只需要记住这一连串空间的起始位置,若需要访问与起始位置只相差距离为5的位置时,我们只要在起始位置的地址上加5就可以一步到位。
 尾插与尾删最重要的一步就是如何找到尾巴。然而数组几乎可以一步做到这一点,我们知道数组的起始位置,而且用size记录着数组有效长度,那么找尾可以说是及其简单,一步到位。
尾插与尾删最重要的一步就是如何找到尾巴。然而数组几乎可以一步做到这一点,我们知道数组的起始位置,而且用size记录着数组有效长度,那么找尾可以说是及其简单,一步到位。
所以顺序表的尾插与尾删时间复杂度为O(1)。
②顺序表的劣势
与尾插尾删相比,顺序表最大的劣势就是头插与头删。
数组的空间开辟好之后,数组的起始位置已经固定了。我们不能想着将起始位置往前挪一格,然后留出来一个空位置进行插入;同样的也不能将起始位置往后挪一个就完成头删。
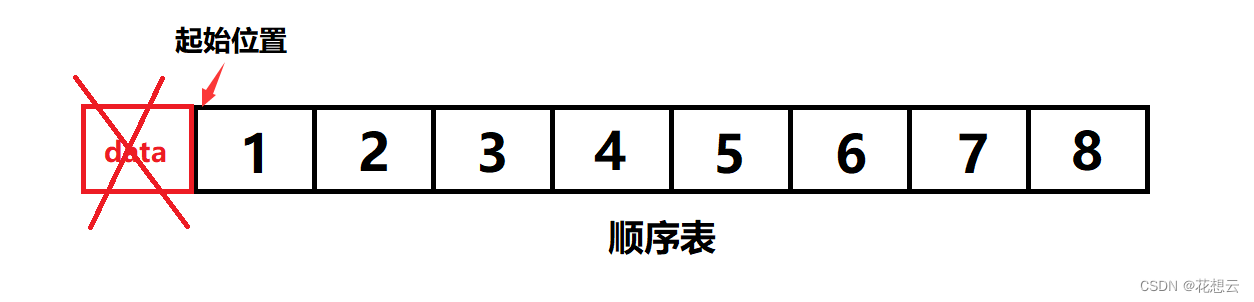
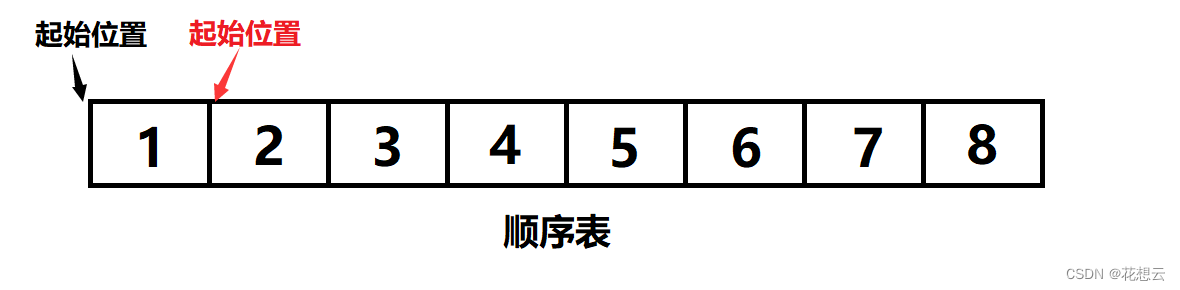
正确的头插与头删:
头插:从索引为0的位置开始,将所有数据向后平移一格,然后插入数据。
头删:从索引为1的位置开始,将所有数据向前平移一格,此时索引为0的位置的数据被索引为1的位置的数据覆盖掉了。
头插与头删关键的步骤是平移数据,因此头插与头删的时间复杂度为O(N)。
有关于数组更多详细的讲解,请参考这篇文章:
数据结构为何重要(数组)![]() http://t.csdn.cn/NB1Uw
http://t.csdn.cn/NB1Uw
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdbool.h>
#define N 5
typedef int SLDataType;
//静态顺序表
typedef struct SeqList
{
SLDataType a[N];//定长数组
int size;//记录存储多少个有效数据
}SeqList;
//初始化顺序表
void SLInit(SeqList* ps);
//静态顺序表的尾插
void SLPushBack(SeqList* ps,SLDataType data);
//静态顺序表的尾删
void SLPopBack(SeqList* ps);
//静态顺序表的头插
void SLPushFront(SeqList* ps,SLDataType data);
//静态顺序表的头删
void SLPopFront(SeqList* ps);
//pos位置插入数据
void SLInsert(SeqList* ps, int pos, SLDataType data);
//pos位置插入数据
void SLErase(SeqList* ps,int pos);
//查找数据
int SLFind(SeqList* ps, SLDataType data, int begin);
//判断数组是否已满
bool IsFull(SeqList* ps);
//打印存储的数据
void SLPrint(SeqList* ps);#define _CRT_SECURE_NO_DEPRECATE 1
#include"SeqList.h"
void SLInit(SeqList* ps)
{
assert(ps);
ps->size = 0;
}
void SLPushBack(SeqList* ps,SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//插入数据
ps->a[ps->size] = data;
ps->size++;
}
void SLPopBack(SeqList* ps)
{
assert(ps);
ps->size--;
}
void SLPushFront(SeqList* ps, SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//挪动数据
for (int i = ps->size - 1; i >= 0; i--)
{
ps->a[i + 1] = ps->a[i];
}
//插入数据
ps->a[0] = data;
ps->size++;
}
void SLPopFront(SeqList* ps)
{
assert(ps);
assert(ps->size > 0);
//挪动数据
for (int i = 0; i < ps->size-1; i++)
{
ps->a[i] = ps->a[i + 1];
}
ps->size--;
}
void SLInsert(SeqList* ps, int pos, SLDataType data)
{
assert(ps);
assert(!IsFull(ps));
//挪动数据
for (int i = ps->size-1; i >= pos; i--)
{
ps->a[i + 1] = ps->a[i];
}
//插入数据
ps->a[pos] = data;
ps->size++;
}
void SLErase(SeqList* ps, int pos)
{
assert(ps);
assert(ps->size > 0);
//挪动数据
for (int i = pos; i < ps->size - 1; i++)
{
ps->a[i] = ps->a[i + 1];
}
ps->size--;
}
int SLFind(SeqList* ps, SLDataType data, int begin)
{
assert(ps);
assert(begin < ps->size);
for (int i = begin; i < ps->size; i++)
{
if (ps->a[i] == data)
{
return i;
}
}
return -1;
}
void SLPrint(SeqList* ps)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
bool IsFull(SeqList* ps)
{
assert(ps);
if (ps->size == N)
{
return true;
}
else
{
return false;
}
}
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我试图在每次运行时以随机顺序将一个名称数组拆分为多个数组。我知道如何拆分它们:name_array=["bob","john","rob","nate","nelly","michael"]array=name_array.each_slice(2).to_a=>[["bob","john"],["rob","nate"],["nelly","michael"]]但是,如果我希望它每次都以随机顺序吐出它们怎么办? 最佳答案 在做同样的事情之前,打乱数组。(Array#shuffle)name_array.shuffle.each_s
我有两个数组。第一个数组包含排序顺序。第二个数组包含任意数量的元素。我的属性是保证第二个数组中的所有元素(按值)都在第一个数组中,而且我只处理数字。A=[1,3,4,4,4,5,2,1,1,1,3,3]Order=[3,1,2,4,5]当我对A进行排序时,我希望元素按照Order指定的顺序出现:[3,3,3,1,1,1,1,2,4,4,4,5]请注意,重复是公平的游戏。A中的元素不应更改,只能重新排序。我该怎么做? 最佳答案 >>source=[1,3,4,4,4,5,2,1,1,1,3,3]=>[1,3,4,4,4,5,2,1,1
我有一个散列:sample={bar:200,foo:100,baz:100}如何使用sort_order中的键顺序对sample进行排序:sort_order=[:foo,:bar,:baz,:qux,:quux]预期结果:sample#=>{foo:100,bar:200,baz:100}我能想到的就是new_hash={}sort_order.each{|k|new_hash[k]=sample[k]unlesssample[k].nil?}sample=new_hash必须有更好的方法。提示?不应该出现没有值的键,即键的数量保持不变,SortHashKeysbasedonord
我写了一个脚本,其中包含一些方法定义,没有类和一些公共(public)代码。其中一些方法执行一些非常耗时的shell程序。然而,这些shell程序只需要在第一次调用该方法时执行。现在在C中,我会在每个方法中声明一个静态变量,以确保这些程序只执行一次。我怎么能在Ruby中做到这一点? 最佳答案 ruby中有一个成语:x||=y。defsomething@something||=calculate_somethingendprivatedefcalculate_something#somelongprocessend但是如果您的“长时间
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su