文章目录

作为一个高可用集群软件,Keepalived提供了vrrp_script、notify_master、notify_backup等多个功能模块,通过这些模块也可以实现对集群资源的托管以及集群服务的监控。
在默认情况下,Keepalived可以实现对系统死机、网络异常及Keepalived本身进行监控。也就是说,当系统出现死机、网络出现故障或Keepalived进程异常时,Keepalived会进行主备节点的切换。
但这些还是不够的,因为集群中运行的服务也随时可能出现问题,所以,还需要对集群中运行服务的状态进行监控,当服务出现问题时也进行主备切换。作为一个优秀的高可用集群软件,Keepalived提供了一个vrrp_script模块专门用来对集群中服务资源进行监控。

这里我们要部署一套基于HTTPD的高可用集群系统。
# 全局配置
global_defs {
# 邮件通知信息
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
# 定义发件人
notification_email_from Alexandre.Cassen@firewall.loc
# SMTP服务器地址
smtp_server 192.168.200.1
smtp_connect_timeout 30
# 路由器标识,一般不用改,也可以写成每个主机自己的主机名
router_id LVS_DEVEL
# VRRP的ipv4和ipv6的广播地址,配置了VIP的网卡向这个地址广播来宣告自己的配置信息,下面是默认值
vrrp_mcast_group4 224.0.0.18
vrrp_mcast_group6 ff02::12
}
# 定义用于实例执行的脚本内容,比如可以在线降低优先级,用于强制切换 名称自定义
vrrp_script check_httpd {
script "killall -0 httpd"
interval 2
}
# 一个vrrp_instance就是定义一个虚拟路由器的,实例名称
vrrp_instance HA_1 {
# 定义初始状态,可以是MASTER或者BACKUP
state MASTER
# 工作接口,通告选举使用哪个接口进行
interface eth0
# 虚拟路由ID,如果是一组虚拟路由就定义一个ID,如果是多组就要定义多个,而且这个虚拟
# ID还是虚拟MAC最后一段地址的信息,取值范围0-255
virtual_router_id 80
# 使用哪个虚拟MAC地址
use_vmac XX:XX:XX:XX:XX
# 监控本机上的哪个网卡,网卡一旦故障则需要把VIP转移出去
track_interface {
eth0
ens33
}
# 如果你上面定义了MASTER,这里的优先级就需要定义的比其他的高
priority 100
# 通告频率,单位为秒
advert_int 2
# 通信认证机制,这里是明文认证还有一种是加密认证
authentication {
auth_type PASS
auth_pass qwaszx
}
# 设置虚拟VIP地址,一般就设置一个,在LVS中这个就是为LVS主机设置VIP的,这样你就不用自己手动设置了
virtual_ipaddress {
# IP/掩码 dev 配置在哪个网卡
192.168.66.80/24 dev eth0
}
# 工作模式,nopreempt表示工作在非抢占模式,默认是抢占模式 preempt
nopreempt|preempt
# 如果是抢占默认则可以设置等多久再抢占,默认5分钟
preempt delay 300
# 追踪脚本,通常用于去执行上面的vrrp_script定义的脚本内容
track_script {
check_httpd
}
# 三个指令,如果主机状态变成Master|Backup|Fault之后会去执行的通知脚本,脚本要自己写
notify_master "/etc/keepalived/master.sh "
notify_backup "/etc/keepalived/backup.sh"
notify_fault "/etc/keepalived/fault.sh"
}
其中,master.sh文件的内容如下。
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Master]" >> $LOGFILE
backup.sh文件的内容如下。
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Backup]" >> $LOGFILE
fault.sh文件的内容如下。
#!/bin/bash
LOGFILE=/var/log/keepalived-mysql-state.log
echo "[Fault]" >> $LOGFILE
这三个脚本的作用是监控Keepalived角色的切换过程,进一步理解notify参数的执行过程。
keepalived-backup节点上的keepalived.conf配置文件内容与keepalived-master节点上的基本相同,需要修改的地方有两个。
state MASTER”更改为“state BACKUP”。priority 100更改为一个较小的值,这里改为“priority 80”。将配置好的keepalived.conf文件及master.sh、backup.sh、fault.sh三个文件一起复制到keepalived-backup备用节点对应的路径下,然后在两个节点启动http服务,最后启动Keepalived服务。
首先在keepalived-master节点启动keepalived服务,执行如下操作。
[root@keepalived-master keepalived]# chkconfig --level 35 httpd on
[root@keepalived-master keepalived]# /etc/init.d/httpd start
[root@keepalived-master keepalived]# /etc/init.d/keepalived start
Keepalived正常运行后共启动了3个进程,其中一个进程是父进程,它负责监控其余两个子进程(分别是vrrp子进程和healthcheckers子进程)。然后观察keepalived-master上Keepalived的运行日志
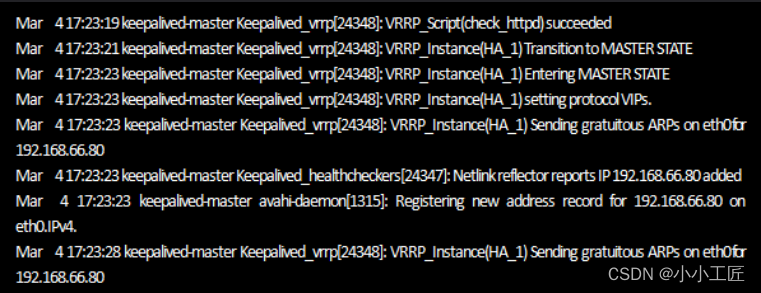
【keepalived-master上Keepalived的启动日志】
从日志可以看出
再查看/var/log/keepalived-mysql-state.log日志文件
tail -f /var/log/keepalived-mysql-state.log
[Master]
通过上面给出的三个脚本的内容可知,Keepalived在切换到Master角色后,执行了/etc/keepalived/master.sh这个脚本,从这里也可以看出notify_master的作用。
接着在备用节点keepalived-backup上也启动keepalived服务,执行如下操作。
[root@keepalived-backup keepalived]# chkconfig --level 35 httpd on
[root@keepalived-backup keepalived]# /etc/init.d/httpd start
[root@keepalived-backup keepalived]# /etc/init.d/keepalived start
然后观察keepalived-backup上Keepalived的运行日志。
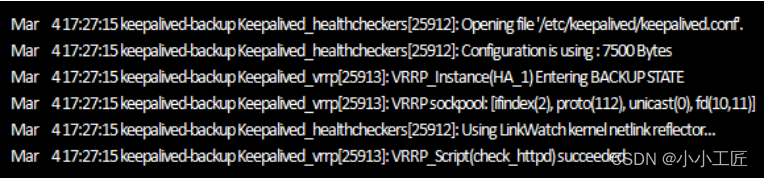
【keepalived-backup上Keepalived的启动日志】
从日志输出可以看出,
在备用节点查看/var/log/keepalived-mysql-state.log日志文件
tail -f /var/log/keepalived-mysql-state.log
[Backup]
由此可知,备用节点在切换到Backup状态后,执行了/etc/keepalived/backup.sh这个脚本。
下面开始测试Keepalived的故障切换(failover)功能。
首先在keepalived-master节点关闭httpd服务,然后看看Keepalived是如何实现故障切换的。
在keepalived-master节点关闭httpd服务后,紧接着查看Keepalived的运行日志

【keepalived-master节点在httpd服务故障后的日志状态】
从日志可以看出,
紧接着查看keepalived-backup节点上Keepalived的运行日志
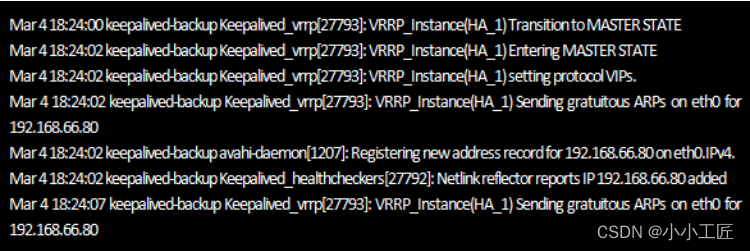
从日志可以看出,
Keepalived在发生故障时进行切换的速度是非常快的,只有几秒钟的时间,如果在切换过程中,持续ping虚拟IP地址,几乎没有延时等待时间。
由于设置了集群中的主、备节点角色,因此,主节点在恢复正常后会自动再次从备用节点夺取集群资源,这是常见高可用集群系统的运行原理。
下面继续演示故障恢复后Keepalived的切换过程。
首先在keepalived-master节点上启动httpd服务。
[root@keepalived-master ~]# /etc/init.d/httpd start
紧接着查看Keepalived运行日志
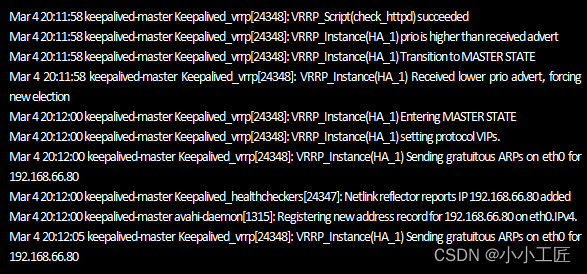
【keepalived-master节点httpd服务恢复后Keepalived的运行日志】
从日志可知,
继续查看keepalived-backup节点Keepalived的运行日志信息
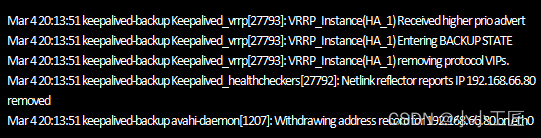
【keepalived-backup节点在keepalived-master节点故障恢复后的日志信息】
可以看出,
Keepalived的整个运行过程和切换过程,看似合理,但事实上并非如此。在一个高负载、高并发、追求稳定的业务系统中,执行一次主、备切换对业务系统的影响很大,因此,不到万不得已,尽量不要进行主、备角色的切换。
也就是说,在主节点发生故障后,必须要切换到备用节点,而在主节点恢复后,不希望再次切回主节点,直到备用节点发生故障时才进行切换,这就是不抢占功能,可以通过Keepalived的“nopreempt”选项来实现。

对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_