Hadoop作为大数据的分布式计算框架,发展到今天已经建立起了很完善的生态,本文将一一介绍基于Hadoop生态的一系列框架和组件。
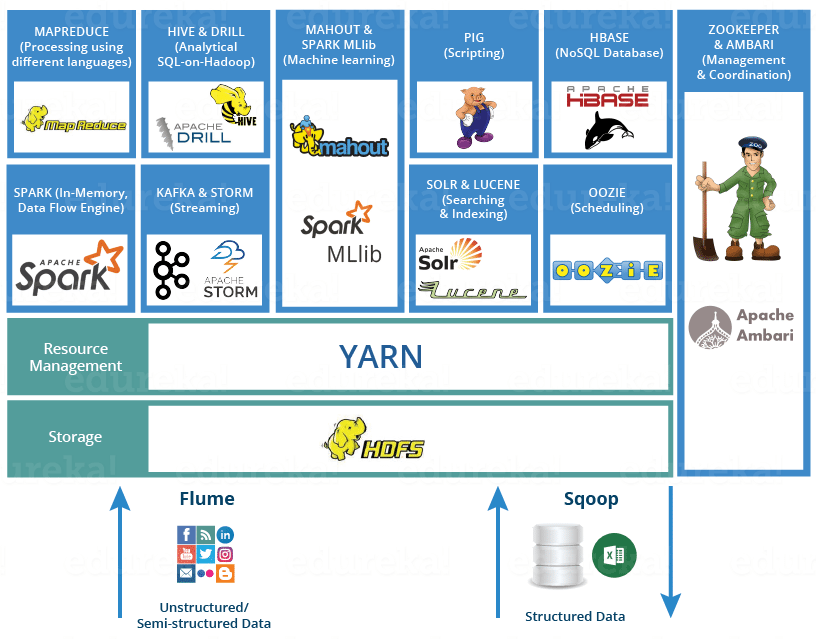

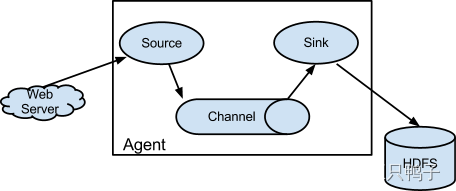
Sqoop 用户在Hadoop和各种关系型数据库直接高效的同步传输数据。
一图解释完。ps: 实现同样功能的还有阿里开源的datax

Hadoop 分布式文件系统,是Hadoop上层组件的核心存储系统,HBASE,Hive等都是基于HDFS的存储来构建的。

HDFS 也是Master/Slave的主/从架构模式。HDFS 集群由单个 NameNode 和多个DataNode组成,NameNode就是Master,DataNode就是Slave。
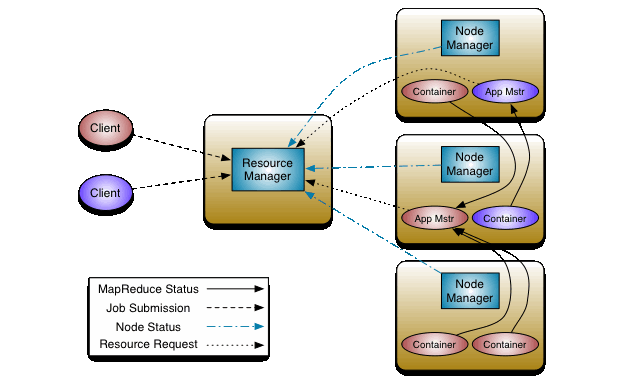
YARN是一个hadoop的资源管理器,负责管理资源和任务调度。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)
Spark是一个大规模计算引擎,在大数据领域的地位举足轻重。支持Scala、Java、R、Python、Sql 多种语言。
主要的组件有SparkCore、SparkSQL、Spark MLlib、Spark Streaming、GraphX
分布式消息队列,是目前消息队列里面的最强王者。
高吞吐量、高扩展性、高可用性,也支持数据持久化

主要流程:producer生产者发送消息到topic,topic被存放在不同的partition中,由消费组去消费topic里面的消息,一个消费组又由多个消费者组成,一条消息只能由消费组中中的一个消费者消费,避免了重复消费。
Mahout是Apache的机器学习库,目标是构建一个用于快速创建可扩展、高性能机器学习应用程序的环境。
主要提供了聚类,分类,协同过滤等开箱即用的算法库,也能方便快速实现自己的算法。
Apache Lucene 是完全用 Java 编写的高性能、功能齐全的全文检索引擎架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎。目的是为软件开发人员提供一个简单易用的工具包,以方便地在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Solr 和 ElasticSearch 都架构在 Lucene 之上,能让Lucene更方便的被调用。其倒排索引的设置,在快速检索上比传统的正排索引更加高效。
Oozie 是一个用于管理 Apache Hadoop 作业的工作流调度系统。
Oozie Workflow jobs 是由 actions 组成的有向无环图 (DAG)。
Oozie 协调器作业是由时间(频率)和数据可用性触发的周期性 Oozie 工作流作业。
Oozie 与 Hadoop 堆栈的其余部分集成,支持开箱即用的多种 Hadoop 作业(例如 Java map-reduce、Streaming map-reduce、Pig、Hive、Sqoop 和 Distcp)以及系统特定作业(例如Java 程序和 shell 脚本)。
Oozie 是一个可扩展、可靠和可扩展的系统。
还有另外一个优秀的调度框架 Azkaban
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
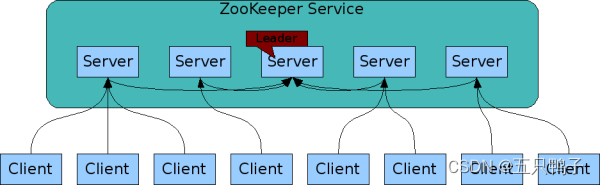
ZooKeeper service 之间互相通信,保证服务的高可用性和一致性。
客户端连接到单个 ZooKeeper 服务器。客户端维护一个 TCP 连接,通过它发送请求、获取响应、获取监视事件并发送心跳。如果与服务器的 TCP 连接中断,客户端将连接到其他的服务器。
zookeeper 数据结构
zookeeper 提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。
Apache Ambari 是一个用于配置、管理和监控 Apache Hadoop 集群的工具。由一组 RESTful API 和一个web界面组成。
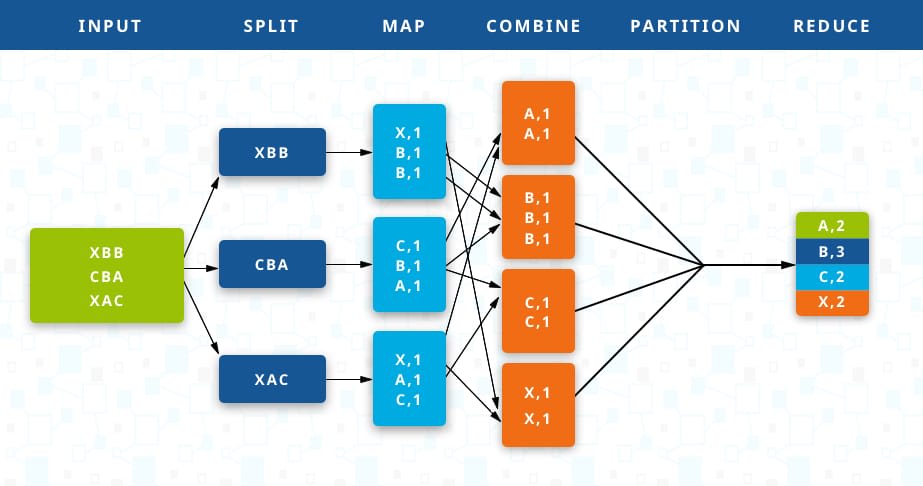
MapReduce是一种分布式计算模型,由Map和Reduce组成。 Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
执行的核心思想: 相同key的键值对为一组调用一次Reduce方法,方法内迭代这组数据进行计算。
MapReduce在大数据计算领域的地位举足轻重,可以使用很多廉价的机器达到惊人的算力。
图中是整个MapReduce的大致计算过程,详细介绍可看官网,后续我也会写一篇详细的介绍。
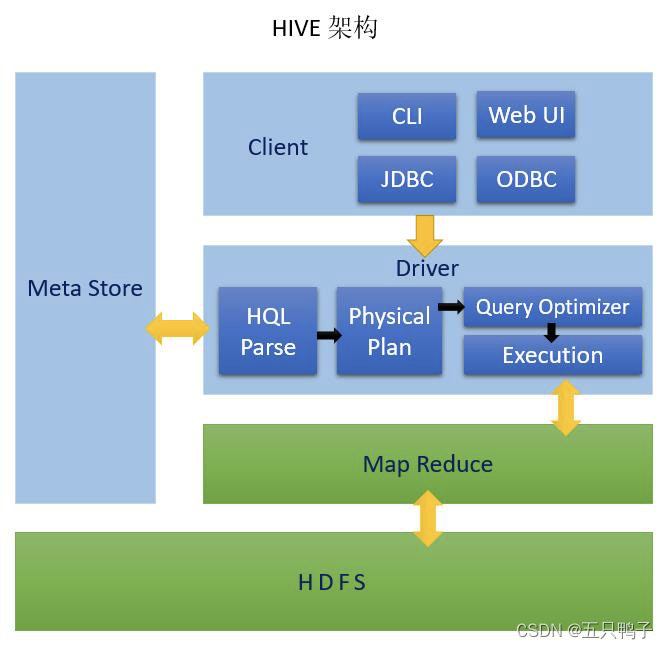
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。毫不夸张的说正是因为有了Hive的诞生,Hadoop才会被大面积推广和使用,并且经久不息。
核心本质:将HQL语句转换成MapReduce任务
Hive的主要优缺点
优点:
避免了开发人员去实现Map和Reduce的接口,大大降低了学习成本
HQL语法类似于SQL语法,简单、容易上手
缺点:
执行效率比较低 Hive生成的MapReduce任务,不够智能化,容易造成数据倾斜
Hive的架构
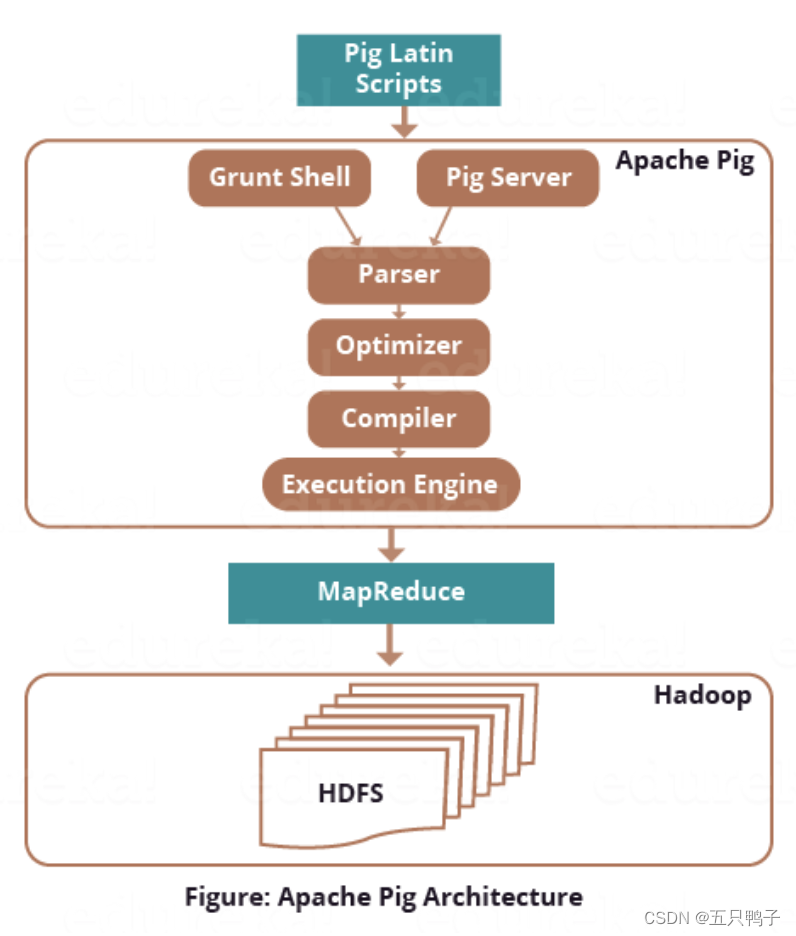
Pig和Hive类似,也是基于hadoop的封装计算,核心也是为了简化MapReduce的编程。不同的是Pig提供的语法更加类似于shell,所以导致两者的使用人群不一致。Hive更多的面向开发人员,而Pig更多的面向与运维人员。
HBase是一个分布式、可扩展的、列式存储的、支持大数据量的实时开源数据库。
HBase基于面列式存储,其中RowKey的设计,使得他能够提供快速的点查和范围查询,但是不支持复杂的SQL查询
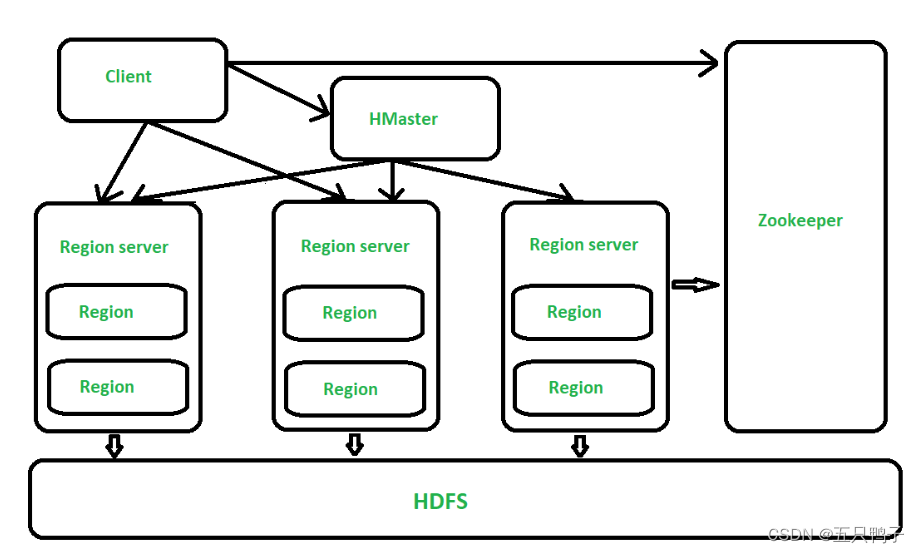
上图是HBASE的基础架构图。
HBASE的数据存储在HDFS上
Client:客户端,它提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
Zookeeper:存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
HRegionServer:它是处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
总结大致的流程就是:client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,HRegionServer读写数据后返回给client。
届于大数据技术革新太快,本文会不定时更新,如果感兴趣的话,可以关注下。
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和
我正在尝试找出一种方法来显示来自不在RAILS_ROOT下(在RedHat或Ubuntu环境中)的已安装文件系统的图像。我不想使用符号链接(symboliclink),因为这个应用程序实际上是通过Tomcat部署的,而当我关闭Tomcat时,Tomcat会尝试跟随符号链接(symboliclink)并删除挂载中的所有图像。由于这些文件的数量和大小,将图像放在public/images下也不是一种选择。我查看了send_file,但它只会显示一张图片。我需要在一个格式良好的页面中显示6个请求的图像。由于膨胀,我宁愿不使用Base64编码,但我不知道如何将图像数据与呈现的页面一起传递下去。