😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。💛💛💛本文摘要💛💛💛
本次博客我们介绍一下关于文档扫描识别项目的全部过程
文章目录
我们在日常生活或者办公中,可能都使用过万能扫描王这个软件,或者qq中的照片文字扫描功能,然后直接利用扒下来的文档直接复制粘贴直接使用,那么他这个原理是什么呢?又是怎么用OpenCV来实现的呢。我们这次博客就来全面介绍一下这个整体流程。并进行真实案例操作。
我们要完成对于文档图片的扫描工作。大致流程主要步骤分为以下几个步骤。

1. 图像边缘检测。
2. 获取轮廓信息。
3. 透视变换,经过旋转、平移等操作对文档图片进行处理。
4. OCR识别图片当中每一个字符。
首先我们要对两个文件进行处理,我们先来看一下预处理的图片什么样子。



我们这里以一个英文的文件,一个自己用中文的一首诗来去做这个项目。因为怕其他东西干扰边缘,于是自己画了个框把边缘圈起来了。
首先我们还是要导入第三方库,然后获取参数。
import numpy as np
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True,
help = "Path to the image to be scanned")
args = vars(ap.parse_args())
这里我们一定要会这种导入参数的形式,非常方便,后期设置参数也非常方便,指定路径就完全OK了。
这里我们只需要指定一个传入参数,原始图像就OK了。
然后我们使用DEBUG操作一步一步进行操作,首先我们对图像进行一个resize操作。
image = cv2.imread(args["image"])
ratio = image.shape[0] / 500.0
orig = image.copy()
image = resize(orig, height = 500)
首先我们读取image数据,然后对图像进行一个求比例的操作。后期会用得到,再对图像进行resize操作时候,我们会把图像的h和w设置成同一比例。这里我们对image进行了resize函数操作,那么resize函数是什么呢?我们继续看。
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
上方我们传入resize函数的参数是orig, height = 500,那么orig是原始图像的copy,因为取轮廓是不可逆的,所以我们用copy去做,这里我们提取到图像的h和w,因为我们设置了height所以直接跳到if width is None,比例r=height/float(h),为了把width设置成和height同比例,所以进行了dim = (int(w * r), height),完成之后呢,就把dim传入到cv2.resize(image,dim,interpolation=inter),这里就把图像进行了同比例的resize操作。完成之后呢我们继续DEBUG继续看。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(gray, 75, 200)
对图像进行了形态学处理,分别是颜色空间转换,也就是彩色BGR转灰度,然后,进行了一次高斯滤波操作,可以让原图像模糊,目的就是为了去除噪音,最后计算出边缘信息,阈值设置为75到200。
cv2.imshow("Image", image)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
cv2.destroyAllWindows()
展示一下处理之后的结果。
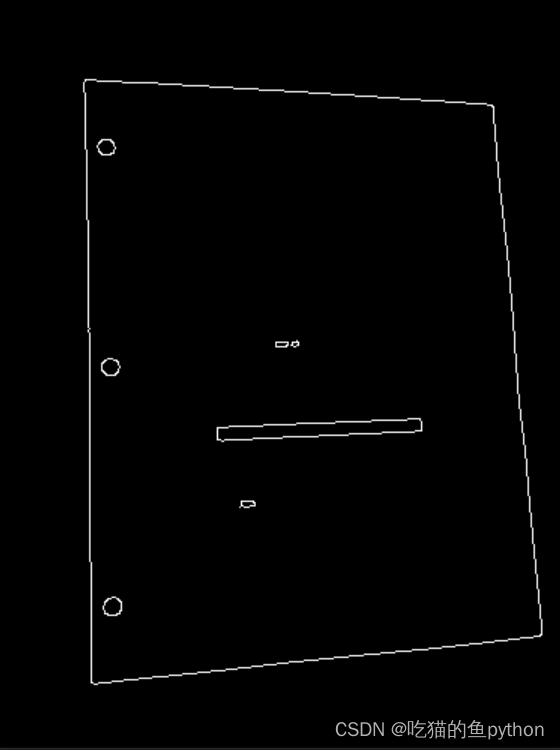


这就是边缘检测之后的结果了,但是边缘检测之后的结果是一个点一个点的,所以我们要进行轮廓的提取。然后我们要进行一个轮廓的提取,我们要对图像中最外面的轮廓进行提取,因为我们要提取文档。
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5]
这里我们首先进行了一个轮廓的提取,里面的参数cv2.RETR_LIST表示检测的轮廓不建立等级关系,cv2.CHAIN_APPROX_SIMPLE这里表示只简单的进行提取轮廓,用四个点来展示轮廓。因为这里返回了两个参数,老版本的CV返回的三个参数,但是我们只要轮廓参数就好了。所以设置索引为0,得到轮廓后呢,我们把轮廓按照面积大小进行了排序,由大到小,并且只取前五个。
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break
# 展示结果
print("STEP 2: 获取轮廓")
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow("Outline", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
这里cv2.arcLength表示计算轮廓的周长。cv2.approxPolyDP主要功能是把一个连续光滑曲线折线化,其中0.02 * peri表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数。当轮廓是四个点的时候就拿出来,然后我们进行一个显示。得到的结果是:



接下来就是一个最主要的一个部分,就是透视变换,也就是说我们想把后面的背景全部去掉,也就是想把我们轮廓检测出来的这一块拿出来单独成一个图像,然后方便我们去OCR文字识别。
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
我们直接跳进four_point_transform函数中。
def four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
首先利用order_points获取坐标。我们可以看到首先设定了rect这个0矩阵,用来传我们的坐标点,按顺序找到对应坐标0123分别是 左上,右上,右下,左下
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
这里pts.sum(axis = 1)就是把横纵坐标进行一个相加的操作,那么最小的肯定就是左上的点,最大的肯定就是右下。
np.diff(pts, axis = 1)是求diff=y-x, 那么最小的是右上,最大的是左下。这样我们就把轮廓的四个点拿出来了。返回去我们继续看,(tl, tr, br, bl) = rect这里拿到了这四个点。widthA和widthB分别计算矩形上下的边长分别是多少,我们需要选择一个相对更大的,来把整个文件图片框住。heightA和heightB就是对于竖直的两个边进行了判断。然后定义一个转换后的坐标值。然后需要计算一个如何将当前图像转换到定义好的图像,需要计算一个转换矩阵M,然后我们通过使用原始矩阵*M就可以得到处理后的结果了。
然后对于经过透视变换的图进行形态学处理。并且展示结果。
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', ref)
print("STEP 3: 变换")
cv2.imshow("Original", resize(orig, height = 650))
cv2.imshow("Scanned", resize(ref, height = 650))
cv2.waitKey(0)

这里我们就把整个轮廓给抠出来了,接下来就是识别的操作。
首先我们先要对OCR文件进行下载:下载地址
用到的是最后一个。或者pip install pytesseract。
导入第三方库
from PIL import Image
import pytesseract
import cv2
import os
image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename),lang='chi_sim')
print(text)
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
这里就是一些形态学处理,其中包括转灰度,然后进行中值滤波或者二值。最后通过pytesseract.image_to_string(Image.open(filename),lang='chi_sim'),进行输出识别内容。最后一个参数指定语言的。然后显示出来把图像。

这里可能我写的这个不太规范,我们再找另外一个图测试一下。用了自己的身份证图做了一下,最终得到的结果是:

这里由于隐私进行了遮挡,但是事实证明,这样确实准确率要高很多很多。但是整体来说识别准确度并不特别高,后期我们会继续优化这个程序,期待后续更新吧。

🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
