这是一个去年的案例,正值疫情期间,我刚刚从机场出来,因为48小时核酸的问题,我被迫从上海绕道去南京。飞机落地后打开手机就看到一个网友给我在微信上的留言,是一个客户的系统有点问题。
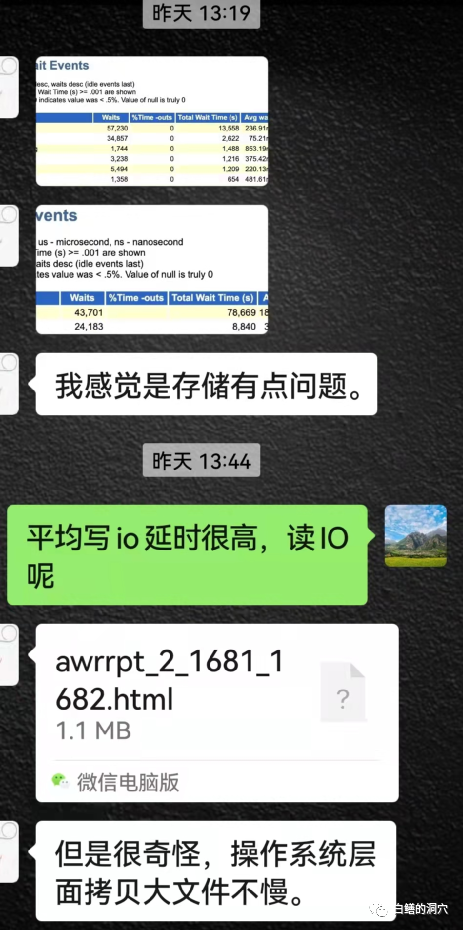
客户那边反馈是系统有点慢,维保服务厂商搞不定找到他了。他上去看了看,发现除了活跃会话数多了一些,和平时差别并不大,做了AWR报告才发现似乎系统的IO有问题,因为log file parallel write和db file parallel write都比较差,不过db file sequential read等读IO的指标好像还是正常的。从发来的AWR的ADDM信息看,似乎也抓不到什么有用的信息。
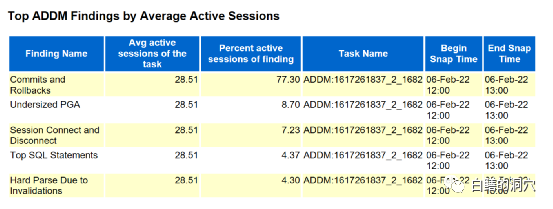
19C的自动诊断也发现了活跃会话数的问题,不过定位的结论不是很准确,发现了提交与回滚较多,SGA配置问题,会话存在短链接以及因为invaliation导致的硬解析比较多这几个问题。
很多经验不足的DBA往往会根据数据库ADDM等自动诊断的结论去分析问题,而一个稍微有些经验的DBA很容易从下面的Load profile中的信息就把这些问题排除掉了。
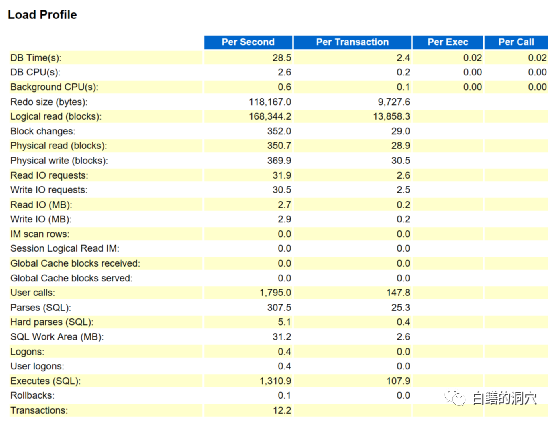
因为每秒12.2个提交,0.1个rollback,1300+的执行,5.1的硬解析,无论如何都是谈不上多的,甚至每秒31M+的读写IO,也算不得大IO。ADDM的智能化诊断实际上只是针对time model的一个解读,从中找出TOP n的因素而已,对于实际问题的定位往往是不准确的。
不过这个案例并不复杂,在飞机滑行的这几分钟里,我已经初步定位了问题。虽然在廊桥那里耽搁了几分钟,十几分钟后,坐上网约车后,我就给和朋友通了电话,把我的分析结果告诉了他。

我的初步判断是,如果客户存在存储同步复制,那么问题应该出在同步复制的链路上了,应该是有一条复制链路不稳定,导致写IO延时很大,而读IO因为不涉及远程复制链路的问题,因此没有受到影响。
实际上此类问题如果你以前遇到过,那么还是很快会找到诊断方向的,如果你没有遇到过,就比较难于定位问题了。因为对于此类问题有较丰富的经验,因此我可以在几分钟内就完成问题的定位。这个经验不仅仅是读IO是好的,写IO是不好的这么简单。
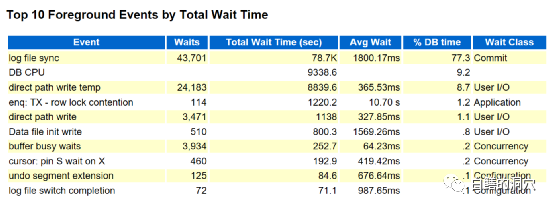
从TOP 10 前台等待事件上看,日志同步,直接路径写,BBW,cursor: pin S wait on X等的等待事件平均延时都很高,而以往常见的db file sequential read等都已经在TOP 10里消失了。这还不足以定位为存储存在问题。在如此小的负载下出现此类问题,还有好几种可能性,比如最为典型的numa导致的问题,没有使用hugepage导致的问题,共享池导致的问题等,都可能出现类似的现象。因此需要首先排除掉这样的问题,才能做出较为准确的定位。
这种分析对于遇到过此类问题的专家来说十分简单,而对于没有遇到过问题的人来说,可能会一筹莫展,主要原因是里面涉及了十分复杂的逻辑。
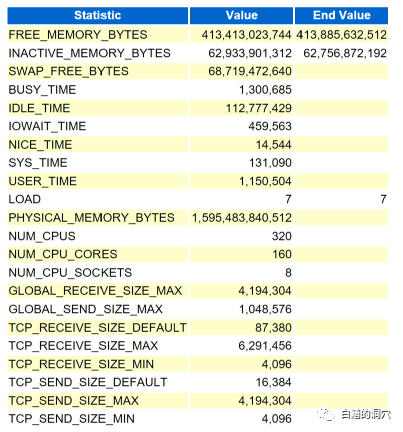
我们首先要通过user_time和sys_time的比例关系等OS层面的情况来排除NUMA以及HUGEPAGE引起的问题。其次要通过详细的前台进程等待事件中关于共享池的事件的平均等待延时来排除共享池导致的问题。
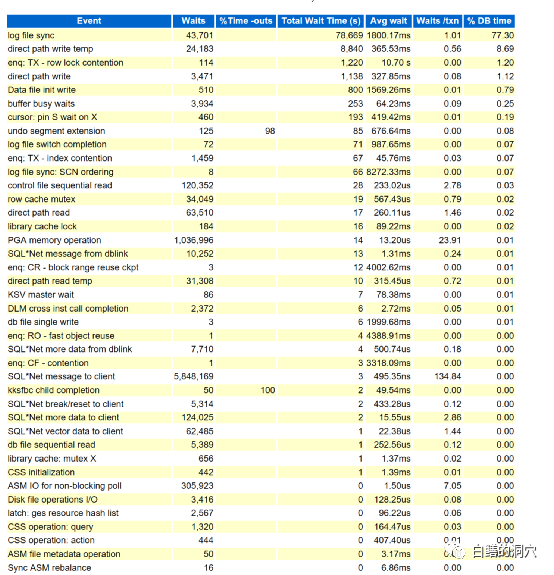
这个排除工作相对会比较麻烦,因为IO延时的异常反过来也会影响共享池的相关指标,需要多看几个,综合来考虑才能做出正确的判断。
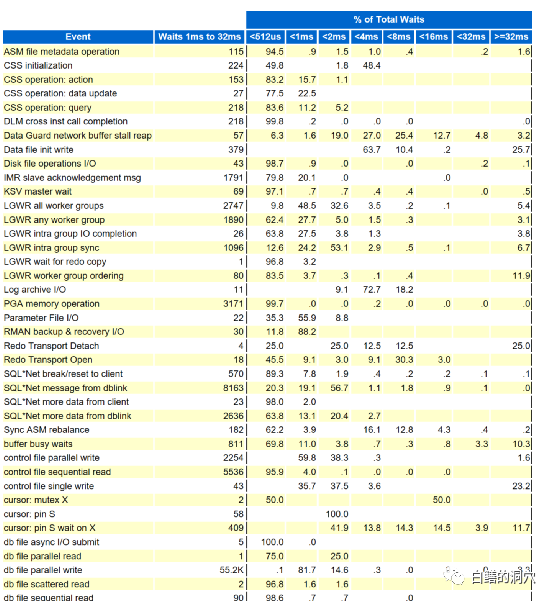
从柱状图中,我们可以看出db file parallel write的大多数IO都小于2ms,不过还是有3.3%的IO是异常的,而且是大于32毫秒的。
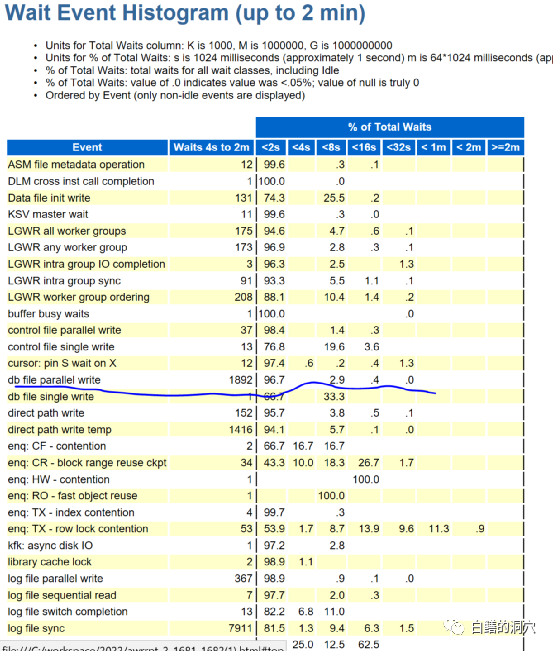
再仔细看一下就会发现,这3.3%的IO都是大于4秒钟延时的,如果分析到这里,存储复制链路存在抖动的结论成立的可能性就超过8成了。正是因为这个原因,我才能在几分钟内做出那个判断。和朋友通过电话40分钟后,这个判断被确认了。
似乎大家看完这个案例觉得并不复杂,只要有过这样的经验,下回就能够分析这个问题了。确实是的,遇到过类似问题的DBA下回你遇到这个问题的时候就多了一条诊断路径,这就是运维经验的积累。做到这一点还不够,因为对于水平高的DBA,看了我今天的文章后,下回遇到类似问题就可以进行分析了。而对于大多数人来说,下回遇到此类问题也不一定就能处理的好。这种运维经验需要固化下来,形成自动化诊断分析的模型,才能更好的积累。
说实在的,这类十分复杂的问题,使用深度学习构建模型是最好的,因为这上千个指标里面的复杂的关系,可能专家也不一定都能够总结和分析的清楚。不过理论上的最好实际上不一定能够实现。此类问题,我最近的5/6年里也不过遇到过四五次,没有足够的样本,深度学习也好,人工智能也好,都无法构建出模型出来。
此类小概率发生的问题的知识积累还有另外一种方法,那就是依靠专家根据有限的样本去进行抽象分析,构建出知识图谱,并通过知识图谱来勾画出一个故障模型了。
如果我们对数据库的内部原理有了充分的了解后,这种抽象就变得可行了。虽然抽象出来的故障模型的精确性可能还无法一下子达到很高的水准,不过一个故障模型刚刚开始构建的时候达到70-80%的准确性还是可以达到的,随着在实际生产环境中的磨合,通过调参或者添加关系等方式,还可以进一步优化模型。
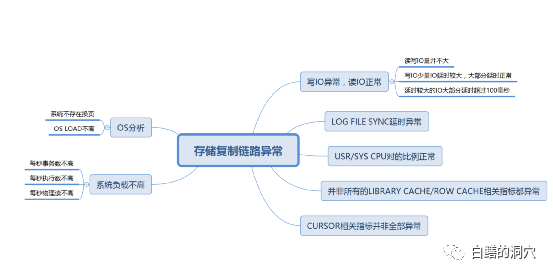
这个故障模型的简图,有兴趣的朋友可以研究研究,这些因素是不是能够定义这个故障了。这些分析,人脑去分析,也就几分钟就可以完成的。而要让这个模型变成自动化模型,还是需要继续花点心思的。

在企业的运维自动化系统中,如果能够把梳理抽象的结果变成自动化发现的模型,那么下回类似问题出现的时候,哪怕分析过此类问题的专家不在现场,稍微有点经验的DBA也能够很快发现问题,并根据系统的提示正确地进行问题分析了。这种故障模型或者运维经验的积累,可以让运维知识真正成为企业IT部门的核心资产。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss