本章是系列文章的第七章,终于来到了鼎鼎大名的SSA,SSA是编译器领域最伟大的发明之一,也是影响最广的发明。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
对下面的c代码保存成7.1.cc:
1 int max(int a, int b) {
2 int ans = a;
3 if (b > a) {
4 ans = b;
5 }
6 return ans;
7 }
直接用clang生成bc → dot → svg,最终svg的结果如下:
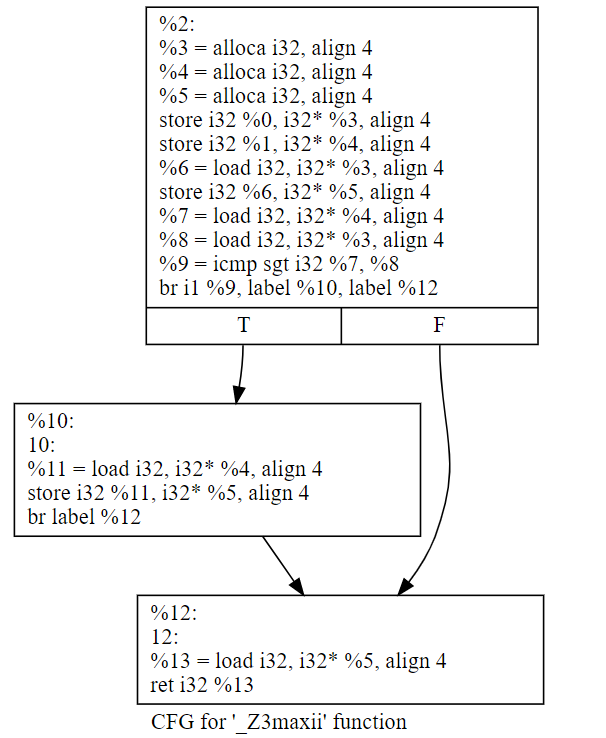
如果经过一轮opt的优化“opt -mem2reg 7.1.ll -o 7.1.1.bc”之后的结果,就变成了这样(注意,需要删除ll里面的optnone属性,否则opt不会生效):
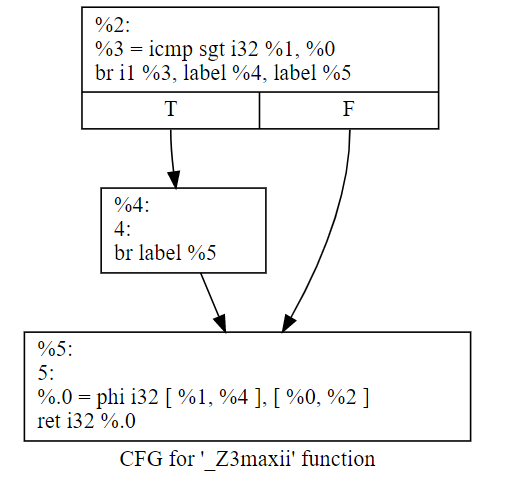
除了我们本来准备跑的mem2reg的pass外,优化前后最后一个BB里是不是还多了一个phi函数?
静态单赋值,字面意思是对静态的变量只有一次赋值点。这是现在所有编译器都广泛使用的属性,也是编译器历史上最具有突破性意义的属性,简化了各种分析和优化的过程。
1991年SSA的奠基论文被引用打到2800+次,这还是截止2019年的数据,这个引用次数每年还在增加。
几乎每本讲编译器的书都会说到SSA。google学术上用SSA能搜到5000+个结果。
每年来自全世界的编译器专家,都会在SSA研讨会上庆祝一次SSA的诞生。
和静态单赋值对应的是动态单赋值,也就是程序执行过程中,每个变量只能赋值一次。和动态单赋值不同,静态单赋值,只要求每个变量的赋值程序点只能有一个,这个程序点可以出现在循环内部(这意味着动态执行过程中这个程序点会多次执行)。
如果一个程序没有任何分叉,则称这个程序是线性代码。
例如下面的代码:
1 double baskhara(double a, double b, double c) {
2 double delta = b * b - 4 * a * c;
3 double sqrDelta = sqrt(delta);
4 double root = (b + sqrDelta) / 2 * a;
5 return root;
6 }
其实它本身就是符合SSA定义的(每个变量只定义一次),但一般经过opt转换之后的代码是这样:
1 define double @baskhara(double %a, double %b, double %c) {
2 %1 = fmul double %b, %b
3 %2 = fmul double 4.000000e+00, %a
4 %3 = fmul double %2, %c
5 %4 = fsub double %1, %3
6 %5 = call double @sqrt(double %4)
7 %6 = fadd double %b, %5
8 %7 = fdiv double %6, 2.000000e+00
9 %8 = fmul double %7, %a
10 ret double %8
11 }
线性代码转换成SSA范式的的算法比较直接:
1 for each variable a:
2 Count[a] = 0
3 Stack[a] = [0]
4 rename_basic_block(B) =
5 for each instruction S in block B:
6 for each use of a variable x in S:
7 i = top(Stack[x])
8 replace the use of x with xi
9 for each variable a that S defines
10 count[a] = Count[a] + 1
11 i = Count[a]
12 push i onto Stack[a]
13 replace definition of a with ai
例如,下面的c代码:
1 a = x + y;
2 b = a - 1;
3 a = y + b;
4 b = 4 * x;
5 a = a + b;
经过SSA转换之后会变成这样:
1 a1 = x0 + y0;
2 b1 = a1 - 1;
3 a2 = y0 + b1;
4 b2 = 4 * x0;
5 a3 = a2 + b2;
前面说了线性代码的SSA转换过程,那非线性代码应该怎么处理呢?
例如下面的控制流图,SSA转换之后L5处使用的b是哪一个b?:
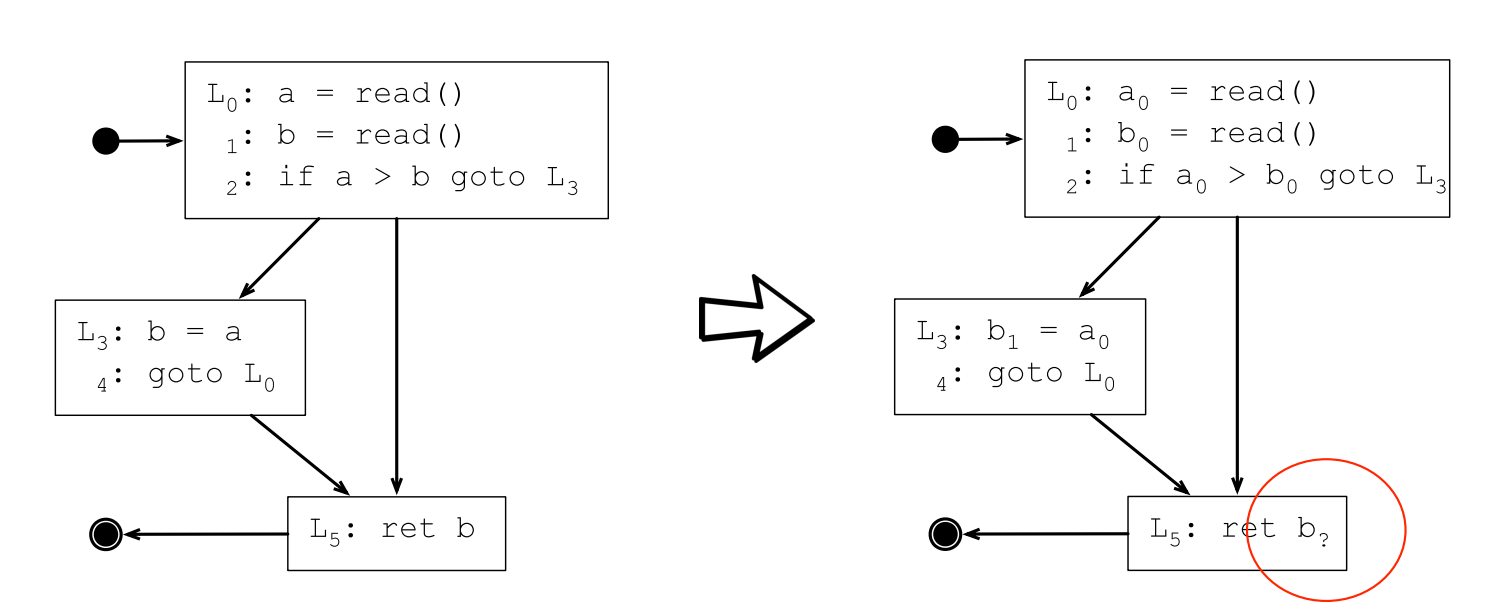
答案是要看情况,如果控制流图上从L4执行到L5,则L5处的b应该是b1;如果是从L2执行到L5,则L5处的b应该是b0。
为了处理这种情况,需要引入phi函数(φ),φ函数会根据路径做选择,根据进入φ函数的路径选择不同的定义。
插入φ函数之后的SSA转换结果如下:
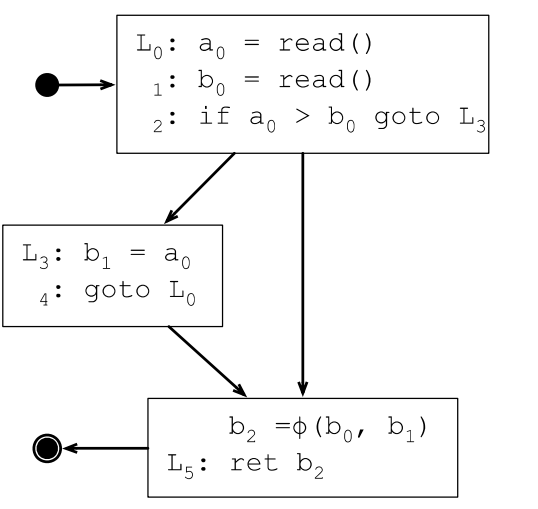
φ函数会插入到每个基本块的最开始地方,对N个变量生成N个φ函数,φ函数的参数个数取决于执行到该基本块的直接前驱有几个。
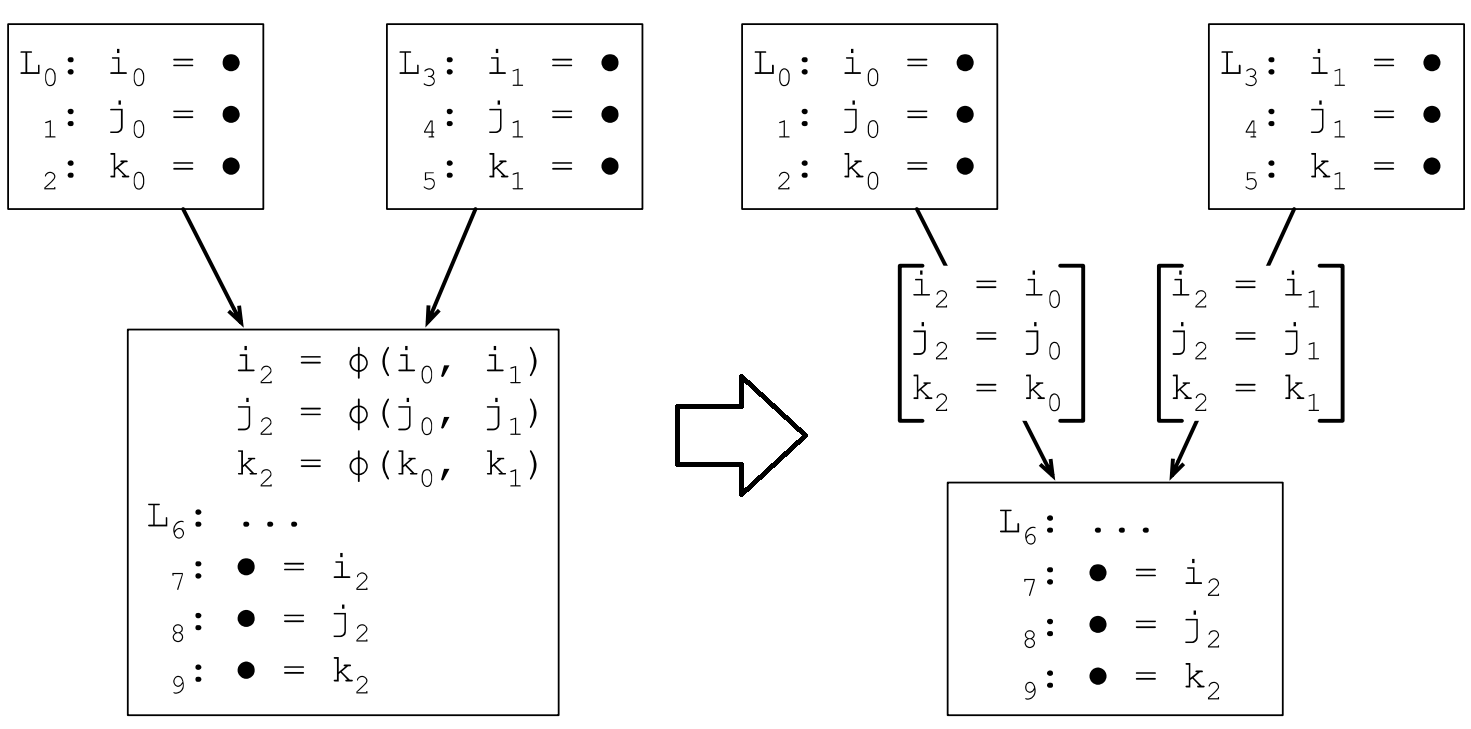
如果一条边的起始点BB有多个直接后继BB,终止点的BB有多个前驱BB,则称为该边为临界边。
在临界边上插入一个空的BB(这个BB只有一个简单的goto语句),来解决临界边的上的φ函数自动注入问题。
在一个有根的有向图中,d支配n的意思是所有从根节点到n的路径都通过d。
在严格SSA范式(严格的意思是所有变量都是在使用前初始化)程序中,每个变量的定义都支配它的使用:
在基本块n中,如果x是φ函数的第i个参数,则x的定义支配n的第3个前驱。
在一个使用x的不存在φ函数的基本块n中,x的定义支配基本块n。
一个节点x严格支配节点w,当且仅当x支配w,并且x≠w。
节点x的支配前沿是所有具有下面属性的节点w的集合:x支配w的前驱,但不严格支配w。
支配前沿策略:如果节点x函数变量a的定义,那么x的支配前沿中的任意节点z都需要一个a的φ函数。
支配前沿迭代:因为φ函数本身会产生一个定义,所以需要循环执行支配前沿策略,直到没有节点需要额外增加φ函数。
定理:迭代支配前沿策略和迭代路径覆盖策略生成同样的φ函数集合。
DF[n] = DFlocal[n] ∪ { DFup[c] | c ∈ children[n] }
Where:
DFlocal[n]: 不被n严格支配(SSA的1989年版本要求的是严格支配,但1991年版本优化成直接支配,前一篇在ACM会议上,后一篇在ACM期刊上,Cytron果然是混职级的高手![]() )的n的后继节点
)的n的后继节点
DFup[c]: c的支配前沿集合中不被n严格支配的节点
children[n]: 支配树中n的子结点集合
转换成算法之后的伪代码如下:
1 computeDF[n]:
2 S = {}
3 for each node y in succ[n]
4 if idom(y) ≠ n
5 S = S ∪ {y}
6 for each child c of n in the dom-tree
7 computeDF[c]
8 for each w ∈ DF[c]
9 if n does not dom w, or n = w
10 S = S ∪ {w}
11 DF[n] = S
插入的算法描述如下:
1 place-phi-functions:
2 for each node n:
3 for each variable a ∈ Aorig[n]:
4 defsites[a] = defsites[a] ∪ [n]
5 for each variable a:
6 W = defsites[a]
7 while W ≠ empty list
8 remove some node n from W
9 for each y in DF[n]:
10 if a ∉ Aphi[y]
11 insert-phi(y, a)
12 Aphi[y] = Aphi[y] ∪ {a}
13 if a ∉ Aorig[y]
14 W = W ∪ {y}
15
16 insert-phi(y, a):
17 insert the statement a = ϕ(a, a, …, a)
18 at the top of block y, where the
19 phi-function has as many arguments
20 as y has predecessors
21 Where:
22 Aorig[n]: the set of variables defined at node "n"
23 Aphi[y]: the set of variables that have phi-functions at node "y"
1 rename(n):
2 rename-basic-block(n)
3 for each successor Y of n, where n is the j-th predecessor of Y:
4 for each phi-function f in Y, where the operand of f is ‘a’
5 i = top(Stack[a])
6 replace j-th operand with ai
7 for each child X of n:
8 rename(X)
9 for each instruction S ∈ n:
10 for each variable v that S defines:
11 pop Stack[v]rename-basic-block的定义参照之前的,这里只是增加了一些场景。
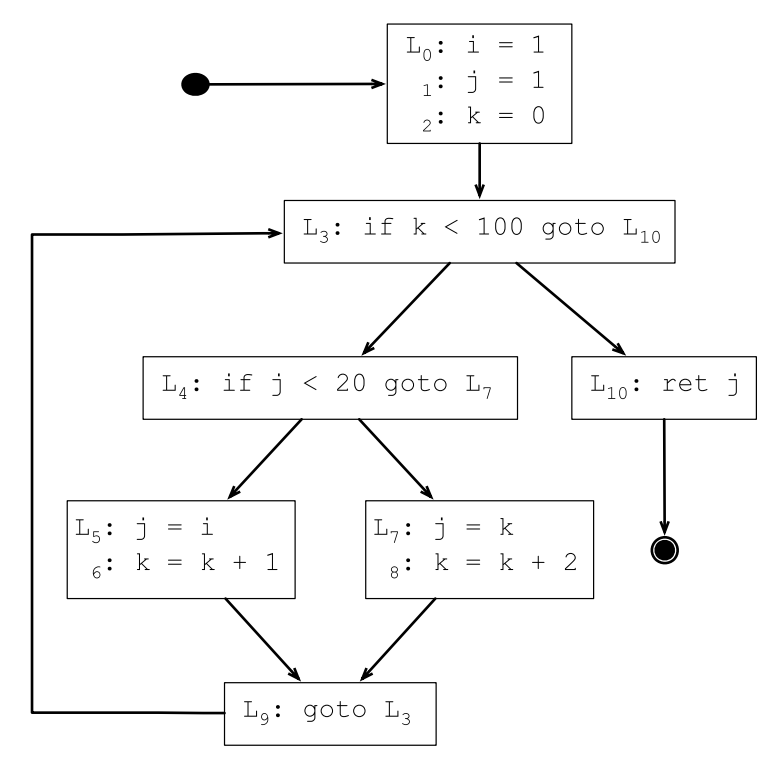
1 i = 1
2 j = 1
3 k = 0
4 while k < 100
5 if j < 20
6 j = i
7 k = k + 1
8 else
9 j = k
10 k = k + 2
11 return j
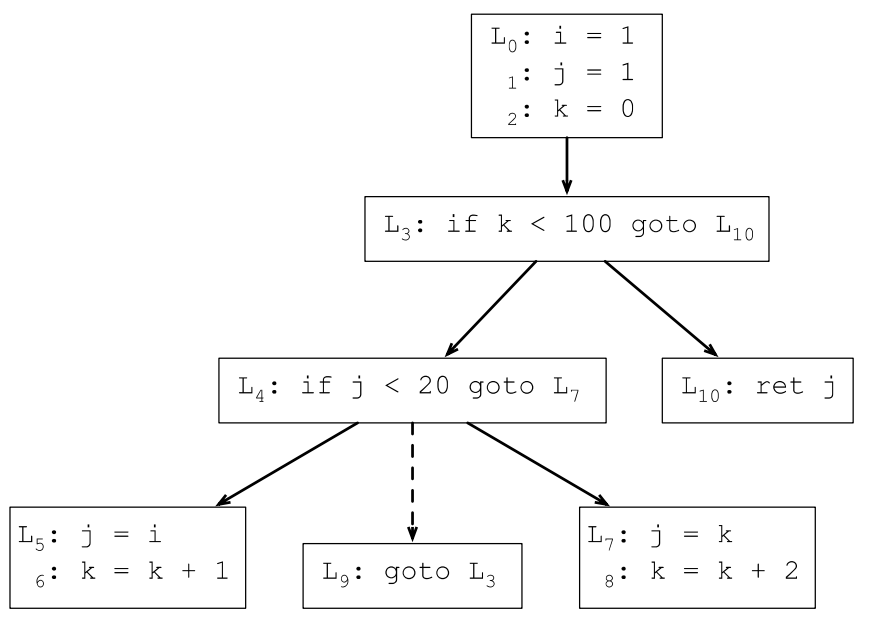
一般从支配树的叶子节点开始计算,第一轮计算所有叶子节点:
DF(7) = {9}, DF(9) = {3}, DF(5) = {9}, DF(10) = {}
第二轮去掉支配树的所有叶子节点,计算第二轮叶子节点的支配前沿:
DF(4) = {3}
第三轮删掉叶子节点,并计算当前叶子节点的支配前沿:
DF(3) = {3}
第四轮删掉叶子节点,并计算当前叶子节点的支配前沿:
DF(0) = {}
上一节求出来的DF集合其实只有2个元素,所以只需要在L3和L9的基本块开始处插入φ函数,存在多种定义的变量只有j和k,所以下面在L3和L9插入j和k的φ函数:
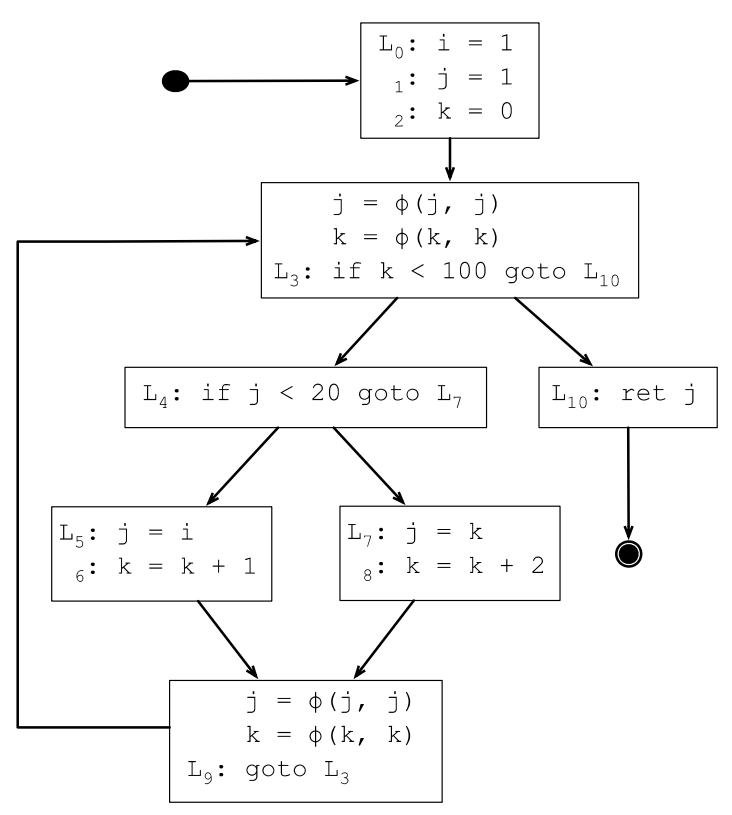
是否存在只有一个前驱的φ函数?如果只有一个前驱,那说明变量只有一个定义,自然就不需要φ函数。
是否存在参数多余2个的φ函数?如果前驱个数大于2,自然就会出现参数多余2的φ函数。
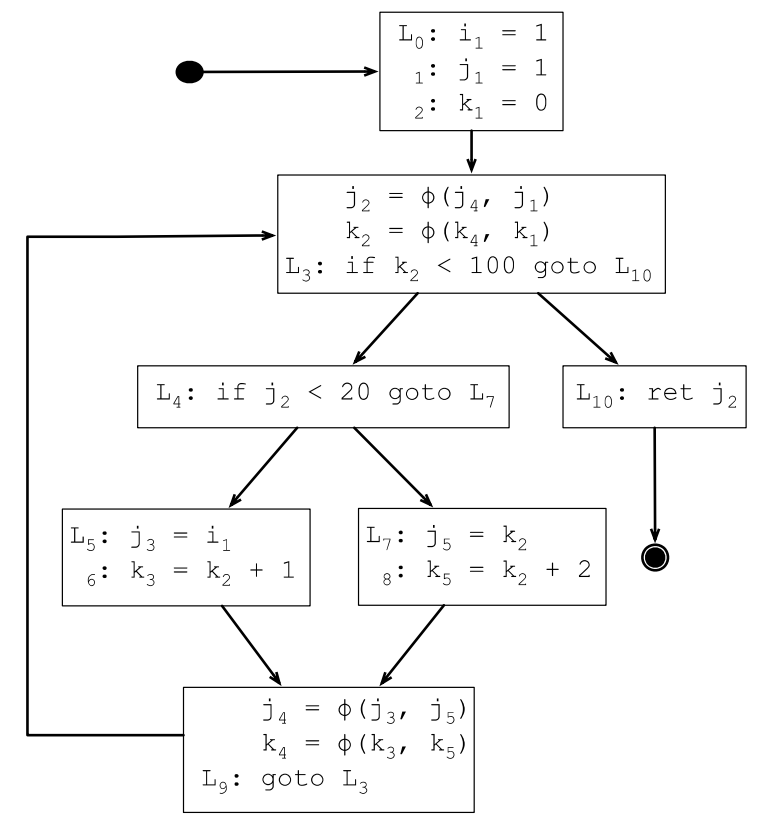
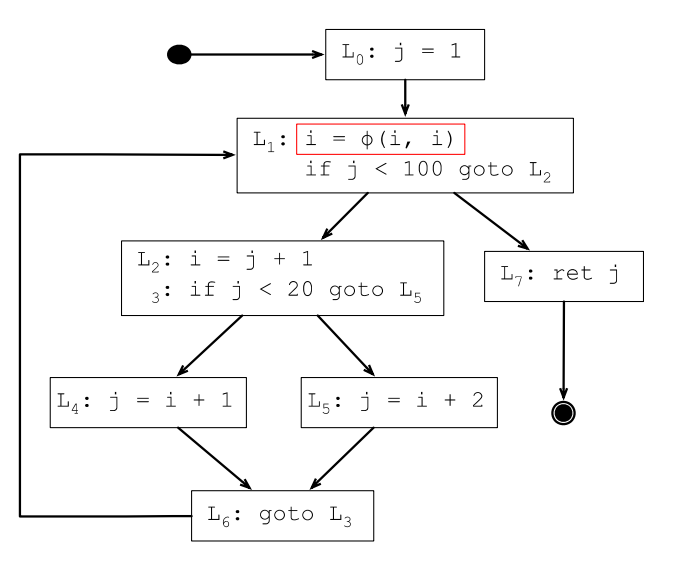
上面生成的SSA范式,从SSA的定义上看虽然已经是最简的了,但可能存在一些用不上的变量定义,砍掉这些冗余的定义是生命周期检查的工作,经过生命周期检查,仅在变量i还处在生命周期范围内的程序点才需要插入i的φ函数。
下面L1处的i的定义后面没机会使用了,所以L1处的φ函数插入是不必要的:
SSA范式可以用来简化各种基于数据流的分析。SSA范式之前,数据流分析的某个变量的定义是一个集合,SSA范式转换之后这些变量都变成了唯一定义;而且由于每个变量只有一次定义,相当于说每个变量都可以转换成常量(循环内定义的变量除外,每次循环迭代,变量都会被重新定义)。
如果一个变量定义了,没有使用,并且该定义的语句也没有其他副作用,可以将该变量定义的语句删除。(SSA之前变量是否被使用的含义就要复杂多了,因为会有多个版本的变量定义)
给每个SSA转换之后的每个变量保存一个计数器,初始化为0。遍历一遍代码,每次使用就将计数器加一,遍历完如果某个变量的使用计数器为0,则可以删除变量的定义语句。
因为每个变量的定义都只有一个定义,所以在变量定义时就能判断变量是常量,还是真的变量。如果变量的定义依赖某个外部输入,则它不是常量。如果变量的定义依赖的是一个常量,或者依赖的变量是一个常量,则常量可以一直传播下去,所有类似的变量都能转换成常量。直到明确所有变量都是依赖某个外部输入。
如果碰到φ函数怎么办?因为φ函数会给变量的赋值增加多种可能性,所以变量的定义变成了一个集合,只有当集合中所有定义都是常量的情况下,才能将该变量转换成常量。
下面是llvm的常量传播的实现:

新的生命周期分析算法如下:
1 For each statement S in the program:
2 IN[S] = OUT[S] = {}
3 For each variable v in the program:
4 For each statement S that uses v:
5 live(S, v)
6 live(S, v):
7 IN[S] = IN[S] ∪ {v}
8 For each P in pred(S):
9 OUT[P] = OUT[P] ∪ {v}
10 if P does not define v
11 live(P, v)
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源