其实干 Java 开发,必然离不开一些计算,比如如果你现在工作是服务与银行,那么就会对金额这些计算非常敏感,所以就会经常用到 BigDecimal ,如果你入职的是其他行业的公司,可能用的就相对没这么多,今天了不起就来给大家分项一下那些不怎么常用,但是非常有用的方法。
关于 BigDecimal 的加减乘除,了不起在这里就不再一一的去给大家说了,毕竟这都是非常基础的内容,我们来说说需要大家掌握的有用的方法。
我们先来看一段代码:
BigDecimal b1= new BigDecimal(0.1);
System.out.println(b1);大家可以猜一下这个执行的结果会是什么内容呢?
结果是 0.1 么?如果不是 0.1 的话,那么执行输出的话,会出现什么内容,如果你知道,那么恭喜你,如果你不知道的话,那么就得认真学习一下拉。
结果显而易见,肯定不是 0.1 。
我们看看他的执行结果是什么内容,然后再来说,应该使用什么方式。
0.1000000000000000055511151231257827021181583404541015625当看到这个内容的,很多人恍然大悟,一眼就看出来,精度丢失了,所以导致了这种情况的发生,成这种问题的原因是 0.1 这个数字计算机是无法精确表示的,送给 BigDecimal 的时候就已经丢精度了.double类型 那么我们应该怎么去处理这个 double 类型的参数呢?
其实很简单,方式有两种,第一种:
BigDecimal bigDecimal = new BigDecimal("0.1");
System.out.println(bigDecimal);第二种:
BigDecimal bigDecimal1 = BigDecimal.valueOf(0.1);
System.out.println(bigDecimal1);实际上,在本质上,这两个方法并没有区别,因为。valueOf 在实现上,就是转成了一个字符串。
BigDecimal 当中的 valueOf 中是把浮点数转换成了字符串来构造的 BigDecimal,因此避免了问题。
源码如下:
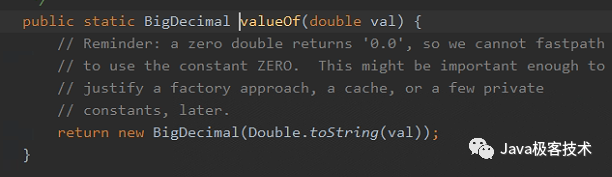
这个方法我们经常用到,用来比较 BigDecimal 的,在 BigDecimal 中使用 equals 可能会导致结果错误,BigDecimal 中提供了 compareTo 方法,在很多时候需要使用 compareTo 比较两个值。如下所示:
BigDecimal b1 = new BigDecimal("10.0");
BigDecimal b2 = new BigDecimal("10.00");
System.out.println(b1.equals(b2));
System.out.println(b1.compareTo(b2));我们肯定遇到过这种,用 compareTo 比较的时候,自己臆想的和代码执行的,肯定不一样,于是就有了自己实验的过程。
出现此种结果的原因是,equals不仅比较了值是否相等,还比较了精度是否相同。示例中,由于两个值的精度不同,所有结果也就不相同。而 compareTo 是只比较值的大小。返回的值为-1(小于),0(等于),1(大于)。
说到 List 绝对不陌生,甚至天天在用,List 转数组,应该怎么操作呢?
其实很简单,就是 toArray。
List<String> list = new ArrayList<>();
String[] strings = list.toArray(new String[list.size()]);两个方法,不带参数的 toArray 就是直接调用 Arrays.copyOf(elementData, size),将 List 中的元素对象的引用装在一个新的生成数组中。
带参数的则是会返回指定类型(必须为 List 元素类型的父类或本身)的数组对象,如果 a.length 小于 List 元素个数就直接调用 Arrays 的 copyOf() 方法进行拷贝并且返回新数组对象,新数组中也是装的 List 元素对象的引用,否则先调用System.arraycopy()将 List 元素对象的引用装在a数组中,如果a数组还有剩余的空间,则在 a[size] 放置一个 null,size 就是 list 中元素的个数,这个 null 值可以使得 toArray(T[] a) 方法调用者可以判断 null 后面已经没有 list 元素了.
其实在业务中,我们更多的都是直接使用第二个,第一个五参数的方法,很多时候都是作为测试来存在的。
其实了不起更想说的,还是 JDK8 中的一些肖操作,他会精简我们的代码,而且,逻辑也更加的清晰,为什么这么说,因为现在百分之八九十的公司都还是在使用 JDK8 ,升级版本的,还并不是那么的多,毕竟很少有公司会吧之前的项目随便更换某些必要的依赖的版本号,除非迫不得已。
其实这个方法,是真的不常用,因为我们用到的,很多都是 forEach ,或者 filter ,或者 map 这些都是我们比较常用的。
而 flatMap 相当于 map+flat,通过 map 把每一个元素替换为一个流,然后展开这个流。比如,我们要统计所有订单的总价格,可以有两种方式:
就是 Order 里面有一个 Detail 的信息,而这个 Order 是一个 List 而 Detail 也是一个 List,就比如下面
public class Order {
private String id;
private List<Detail> details;
}
public class Order {
private String productId;
private Double productPrice;
private Integer productQuantity;
}如果我们想要统计订单总价,如果 Order 表中已经存在了这个价格这块的内容了,那当然好,如果没有,那么就得去汇总详情了,不是么?
//求和使用flatMap
orders.stream().flatMap(order -> order.getDetails().stream()).mapToDouble(item -> item.getProductQuantity() * item.getProductPrice()).sum();
//求和使用flatMapToDouble
orders.stream().flatMapToDouble(order ->order.getDetails().stream().mapToDouble(item -> item.getProductQuantity() * item.getProductPrice())).sum();其实,了不起觉得,JDK8 中才是真的有很多了不起的内容,再比如我们统计list中的数据,已经不在需要自己去做for循环来进行比对了,而是直接通过方法来获取。
//获取最大
Integer id = userList.stream().map(User::getId).max(Integer::compareTo).get();
//获取最小
Integer id1 = userList.stream().map(User::getId).min(Integer::compareTo).get();
//获取id数量
long count = userList.stream().map(User::getId).count();
//总和
int sum = userList.stream().mapToInt(User::getId).sum();
//获取平均值
double d = userList.stream().mapToInt(User::getId).average().getAsDouble();分组统计
//分组统计
Map<String, Long> map = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.counting()));
//分组 Collectors.groupingBy(属性名)
Map<Integer, List<Person>> map = list.stream().collect(Collectors.groupingBy(Person::getAge));
//将名字全转换为大写
List<String> list = userList.stream().map(User::getName).map(String::toUpperCase).collect(Collectors.toList());
//获取忽略第一个并取前几条数据
List<User> list1 = userList.stream().skip(1).limit(2).collect(Collectors.toList());
//distinct() 去重;collect(Collectors.toList())。封装成集合
List<User> collect = userList.stream().distinct().collect(Collectors.toList());关于这些不常用,但是非常有用的内容,你学会了么?
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www